OpenCV
OpenCV简介
首先我们来了解一下,OpenCV是什么?
OpenCV 是计算机视觉中经典的专用库,其支持多语言、跨平台,功能强大。
OpenCV现在支持与计算 机视觉和机器学习有关的多种算法,并且正在日益扩展。
OpenCV支持多种编程语言,例如C++、Python、Java等,并且可在Windows、Linux、OS X、Android和iOS等不同平台上使用。基于CUDA和OpenCL的高速GPU操作的接口也正在积极开发 中。
OpenCV-Python是用于OpenCV的Python API,结合了OpenCV C++ API和Python语言的最佳特 性,旨在解决计算机视觉问题的Python专用库。
OpenCV-Python 为OpenCV提供了Python接口,使得使用者在Python中能够调用C/C++,在保证易读性和运行效 率的前提下,实现所需的功能。
而Python因为它的简单 性和代码可读性。它使程序员可以用较少的代码行表达想法,而不会降低可读性。 与C/C++之类的语言相比,Python速度较慢。也就是说,可以使用C/C++轻松扩展Python,这使 我们能够用C/C++编写计算密集型代码并创建可用作Python模块的Python包装器。这给我们带来 了两个好处:首先,代码与原始C/C++代码一样快(因为它是在后台运行的实际C++代码),其 次,在Python中比C/C++编写代码更容易。OpenCV-Python是原始OpenCV C++实现的Python包 装器。
安装OpenCV-Python
安装OpenCV可以有几种方案,比如使用预编译的二进制文件安装,或者从源代码自行编译,但那些方法都太麻烦了,而且我们只是使用这个库,又不是要研究这个库的算法实现,所以我们这里选择最简单的安装方式。
大家用来编程的电脑都是什么系统的呀? 应该大部分都是Windows吧。如果是mac或其它系统问题也不大,安装方法是差不多的。
之前说到了,OpenCV是一个计算机视觉库,既然是库,所以就可以使用import 命令,很方便的导入后进行使用。但它是第三方库,所以需要先安装才能使用。
在Pycharm中,在最底部的这一排的按钮中,找到终端(Terminal),点击后可以看到光标在闪烁
了,这里可以输入安装命令
pip install opencv-python
如果在安装的时候,出现黄色的提示,要你先更新pip版本,安装它的提示做,把pip版本更新到最新后,再次运行安装OpenCV的命令就行。
由于有"墙"的原因,安装可能会慢或者不成功,多试两次,还不行就可以找个梯子科学上网,或者找老师答疑。
命令执行完后,怎么判断是否成功安装了呢?
创建一个python文件,在文件里写下 :
import cv2 as cv
print(cv.version.opencv_version)
运行如果不报错,看到输出了类似下面的内容就是成功了
4.5.2.52`
`进程已结束,退出代码为 0
这里我们是把OpenCv库的版本号给显示出来了,我当前用的版本是4.5版本,后面的是小版本号,不用管。
使用OpenCV
使用OpenCV非常简单,它就是一个库嘛,导入之后再调用方法就可以使用对应的功能了。这里的所谓方法,就是库里面定义好的函数,它里面封装了一些功能。
在当前阶段,我们不需要知道它是具体是怎么实现那些功能的,只要知道它能做什么就行了。这是一个学习的策略技巧,不要想着什么事都要去搞清楚原理,要牢牢锁定你的目标,抛弃掉细枝末节,始终以达成目标为导向。待你学到一定程度的时候,自然有机会再去了解更深入的细节。
刚才在安装完python后,其实我们在无形中,已经简单的使用过OpenCV了。
import cv2 as cv
print(cv.version.opencv_version)
导入库和调用模块,其实就是这么简单方便。
使用OpenCV肯定不只是查看一个版本号,接下来我们进入实战。
文件路径
首先来了解一下什么叫文件路径
文件的路径表示用户在磁盘上寻找文件时,所历经的文件夹线路。
我们可以看下Windows中文件目录是什么样的。我们打开我的电脑C盘,Windows文件夹-addins文件夹,我们来看看
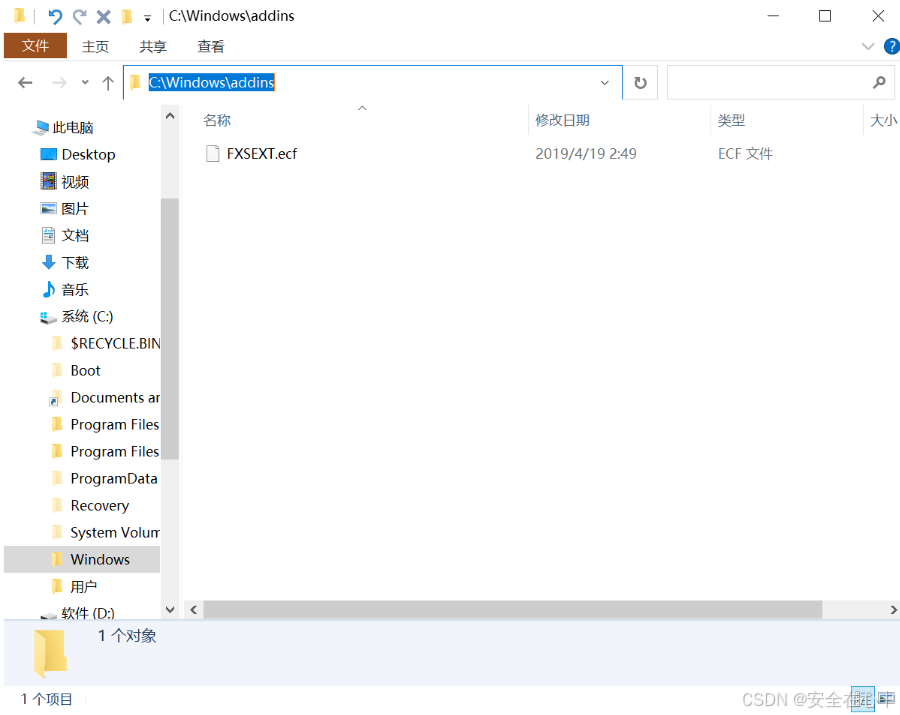
我们从上面的标题或是点击地址栏可以看到,当前文件的所在的目录是C:\Windows\addins, 我们
右键文件-属性-安全,可以看到文件的路径是 C:\Windows\addins\FXSEXT.ecf
这个其实是标准的DOS路径,有以下三部分组成:
卷号或驱动器号,后跟卷分隔符 ( : )。
目录名称。 目录分隔符用来分隔嵌套目录层次结构中的子目录。
可选的文件名。 目录分隔符用来分隔文件路径和文件名。
文件路径在python的写法
路径分为绝对路径和相对路径。
绝对路径就是文件的真正存在的路径,是指从硬盘的根目录(盘符)开始,进行一级级目录指向文件。
相对路径就是以当前文件为基准进行一级级目录指向被引用的资源文件。
比如刚才所说的C:\Windows\addins\FXSEXT.ecf 就是文件的绝对路径。
绝对路径有三种使用方法:
反斜杠 '\':由于反斜杠 '\' 要用作转义符, 所以如果要使用反斜杠表示路径,则必须使用双反斜
杠。
'C:\\Users\\Administrator\\Desktop\\image\\cork.jpg'
原始字符串r":可以使用原始字符串+单反斜杠"的方式表示路径
r'C:\Users\Administrator\Desktop\image\cork.jpg'
斜杠/:为了避免转义符 " 和 原始字符串的麻烦,可以直接用 斜杠",python中是承认"用于路径分割符号的。
`'C:/Users/Administrator/Desktop/image/cork.jpg'`
相对路径
./Images 表示当前目录下的 Images文件夹
../Images 表示当前目录的上一层目录下的Images文件夹
/Images 表示,项目根目录
如果我们要读取当前工作目录下的图片,我们就有两种方式来获取了。
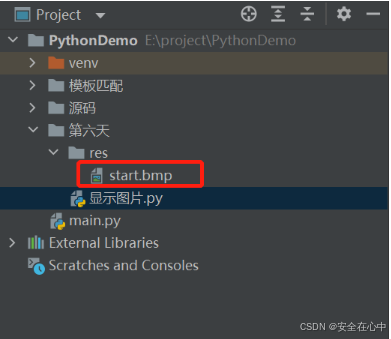
绝对路径的方式:r'E:\project\PythonDemo\第六天\res\start.bmp'
相对路径的方式:'./res/start.bmp'
如果是在当前目录调用同目录下的文件时,相对路径还可以忽略掉./, 写成 'res/start.bmp', 效果是一样的。
这里还需要注意一个很重要的点:opencv读取含有中文路径的文件时,会返回空,但是程序不会报错。所以路径最好使用字母,数字,下划线,避免一些莫名奇妙的问题。
项目工程路径
当我们要使用到当前编码文件所在的目录我们该怎么办呢。
有种和你直接的方法是,工程目录中选中文件,右键- Open In - Explorer,就能打开文件所在的目录了。
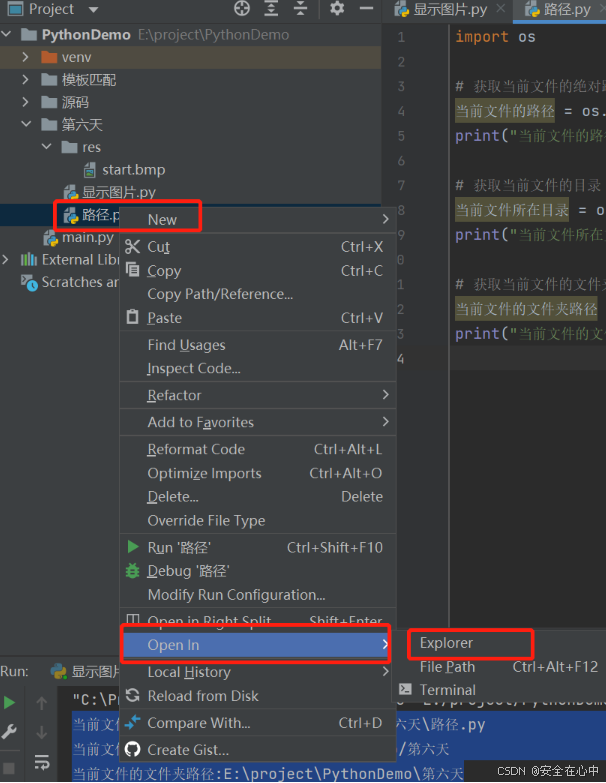
这样操作好像有点麻烦,我们是否可以直接使用代码来获取文件所在的目录呢?答案时可以的!
这里我们就需要使用到os模块,以及os中的两个方法了:
os.path.abspath(文件) 用于获取当前文件的绝对路径
os.path.dirname(文件) 用户获取当前文件的目录
python
import os
# 获取当前文件的绝对路径
当前文件的路径 = os.path.abspath(__file__)
print("当前文件的路径:{}".format(当前文件的路径))
# 获取当前文件的目录
当前文件所在文件夹 = os.path.dirname(__file__)
print("当前文件所在文件夹:{}".format(当前文件所在文件夹))
# 获取当前文件的文件夹路径
当前文件的文件夹路径 = os.path.dirname(当前文件的路径)
print("当前文件的文件夹路径:{}".format(当前文件的文件夹路径))结果:
当前文件的路径:E:\project\PythonDemo\第六天\路径.py
当前文件所在文件夹:E:/project/PythonDemo/第六天
当前文件的文件夹路径:E:\project\PythonDemo\第六天
这里我们发现 【当前文件所在文件夹】与【当前文件的文件夹路径】是一样的,只是斜杆的方式不一样。但是平时一般用第三种方式获取文件的文件夹路径,因为反斜杆更通用。
读取图像
读取图像就是从电脑的硬盘中加载之前已经保存好的图片,支持各种格式的,像bmp、jpg、png等
读取图像的函数是
cv.imread()
这个函数的完整写法是
图片对象 = cv.imread(图片路径,读取方式)
函数有2个参数:
第一个参数是图片的路径,如果文件是在项目工程下,传入相对路径就可以了,如果不在项目工程下那就要传入完整的绝对路径。这是一个必传参数。
第二个参数是图像读取方式,传入1就是按彩色模式读取,传入0就是按灰色模式读取。这是可选参数不写的话,默认是按彩色模式读取。
函数的返回值是这个图片对象,后续可以对这个图片对象进行各种操作。
import cv2 as cv
#相对路径
图片对象 = cv.imread('res/start.bmp')
print(图片对象)
#绝对路径
图片对象 = cv.imread('E:/截图.bmp')
print(图片对象)
如果打印来看的话,就是数字组成的矩阵。
这里特别要注意一点:即使图像路径错误,它也不会引发任何错误,但是 print img 会给出 None.
显示图像
接下来学习怎么把读取进来的图片显示出来。
读取图像的函数是
cv.imshow()
这个函数的完整写法是
cv.imshow(窗口标题,图片对象)
第一个参数是显示图片时用什么标题,为了在多张图片显示时,好有个区分。一般用图片名来表示中文会显示乱码。这是必填参数。
第二个参数是图片对象,就是刚才读取后的图片对象,也是必填参数。
运行代码看到窗口一闪而过了,所以还得设置一个等待状态,一直显示这张图像,直到按下一个键后再关闭窗口。
import cv2 as cv
图片对象 = cv.imread('res/start.bmp')
cv.imshow('img', 图片对象)
cv.waitKey(0)
cv.destroyAllWindows()
加载不同分辨率的图片,窗口自动适合图像尺寸,把图片完整显示出来。
保存图像
在截图后或者对图像处理后,很多时候需要把图像保存下来,OpenCV保存图像的函数是
cv.imwrite()
这个函数的完整写法是
cv.imwrite(图片路径和图片名称,图片对象)
第一个参数是图片文件的路径,如果文件是在项目工程下,传入相对路径就可以了,如果不在项目工程下,那就要传入完整的绝对路径。图片名称里,必须还要包含后缀名,后缀名决定了这个图像是以什么格式保存。这是一个必传参数。
第二个参数是图像对象。这也是必传参数。
python
import win32gui
import win32ui
import win32con
import numpy as np
import 获取句柄激活 as 窗口
import cv2 as cv
def 桌面截图(hwnd):
desktop = win32gui.GetDesktopWindow()
dc = win32gui.GetWindowDC(desktop)
mfc_dc = win32ui.CreateDCFromHandle(dc)
save_dc = mfc_dc.CreateCompatibleDC()
save_bit_map = win32ui.CreateBitmap()
left, top, right, bottom = win32gui.GetWindowRect(hwnd)
w, h = right - left, bottom - top
save_bit_map.CreateCompatibleBitmap(mfc_dc, w, h)
save_dc.SelectObject(save_bit_map)
save_dc.BitBlt((0, 0), (w, h), mfc_dc, (left, top), win32con.SRCCOPY)
signed_ints_array = save_bit_map.GetBitmapBits(True)
im_opencv = np.frombuffer(signed_ints_array, dtype='uint8')
im_opencv.shape = (h, w, 4)
save_dc.DeleteDC()
win32gui.DeleteObject(save_bit_map.GetHandle())
win32gui.ReleaseDC(hwnd, dc)
# Convert to BGR format
im_opencv = im_opencv[:, :, :3]
return im_opencv
def 获取模拟器图像():
句柄 = 窗口.激活模拟器窗口()
return 桌面截图(句柄)
if __name__ == '__main__':
图像 = 获取模拟器图像()
cv.imshow("img", 图像)
cv.imwrite('D:\\test.bmp', 图像)
cv.waitKey(0)
cv.destroyAllWindows()图像基础
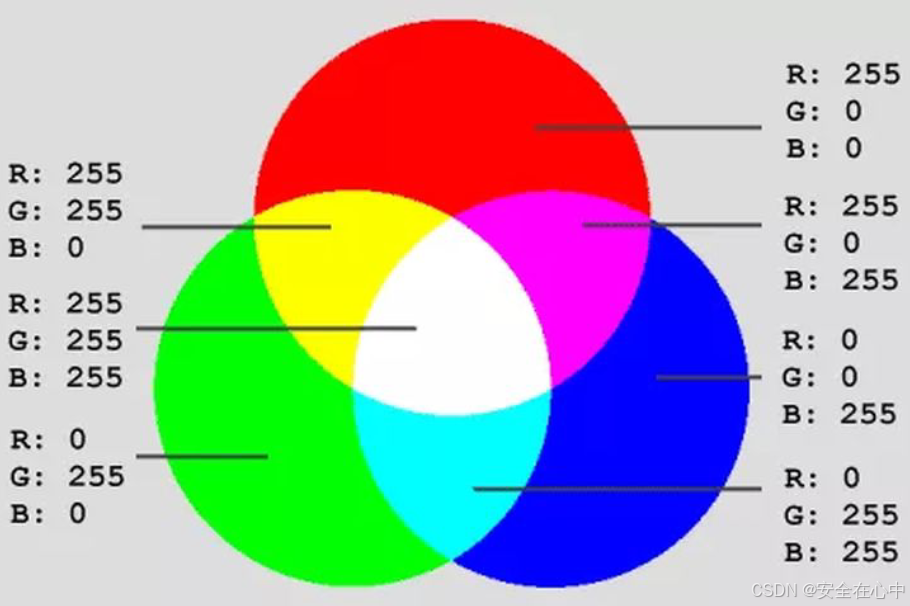
计算机中的RGB
在计算机中我们用红、绿、蓝来表示RGB三原色,各颜色通道的具体取值范围为,红色的RGB值为(255,0,0),绿色的RGB值为(0,255,0)和黄色的RGB值为(0,0,255),如下图所示:
计算机图像像素存储
刚刚我们了解了计算机中颜色的取值,那么具体的图像是如何实际存储在计算机上的呢?下面老师就带领同学们来学习一下计算机保存图像的两种流行格式- 灰度 和 RGB 格式。
灰度图像
举个栗子,下面展示了一个图像,我们看不到彩色的点,因为图像是由黑色、白色和灰色组成的,我们称之为灰度图像,也可以叫做黑白图像。

现在,我们对上面的图像进行放大并且仔细观察,你会发现图像变得失真,并且你会在该图像上看到一些小方框。

在计算机中,这些一个个的小方框就叫做像素(Pixels)。我们经常使用的图像维度是H x W。这实际上是什么意思?这意味着图像的尺寸就是图像的高度(height)和宽度(width)上的像素的数量。
比如,我们举例的图像高度为24像素,宽度为16像素。因此我们说该图像尺寸是24 x 16。我们在计算机上看到的所有图像,都是以数字的形式存储在计算机中,我们继续看下图。

上图中的每一个像素都用一个数值来表示,而这些数字称为像素值。这些像素值表示像素的强度。
!!!重点:对于灰度或黑白图像,我们的像素值范围是0到255。
接近零的较小数字表示较深的阴影,而接近255的较大数字表示较浅或白色的阴影。
在计算机中的每个图像都以这种形式保存,我们可以称它为一个数字矩阵,该数字矩阵也称为通道
(Channel)。

现在我们来猜猜这个矩阵的形状?答案是:它和图像的高度和宽度上的像素值数量相同。也就是说上面矩阵的形状是24 x 16。
重点: 让我们快速总结一下到目前为止我们已经学到的要点:
图像以数字矩阵的形式存储在计算机中,其中这些数字称为像素值。
这些像素值代表每个像素的强度。
0代表黑色,255代表白色。数字矩阵称为通道,对于灰度图像,我们只有一个通道。
彩色图像
我们了解了灰度图像是如何存储在计算机中,接下来让我们学习了解一下更深度一点的知识,彩色图像又是如何存储在计算机当中的呢,它和灰度图像有哪些相同点和不同点呢?老师带大家一起来看看,下面是一张狗狗的彩色图像。

彩色图像由许多的颜色组成,几乎所有颜色都可以从三种原色(红色,绿色和蓝色)合成。老师的理解是:每个彩色图像都是由这三种颜色(或称为3个通道 红色、绿色和蓝色)叠加混合组成的,看下图。

这就意味着在彩色图像中,矩阵的数量或通道的数量将会比灰度图像要多。霸夫老师举个简单的例
子,我们有3个矩阵:1个用于红色的矩阵,称为红色通道。
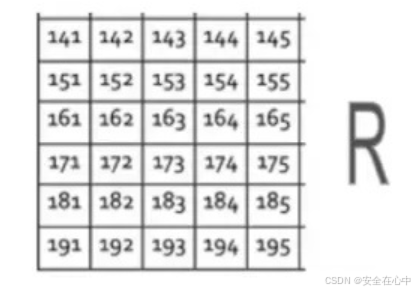
另一个绿色的称为绿色通道。
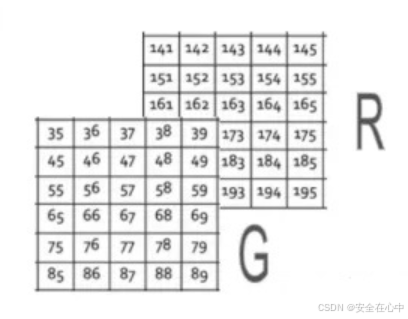
最后是蓝色的矩阵,也称为蓝色通道。
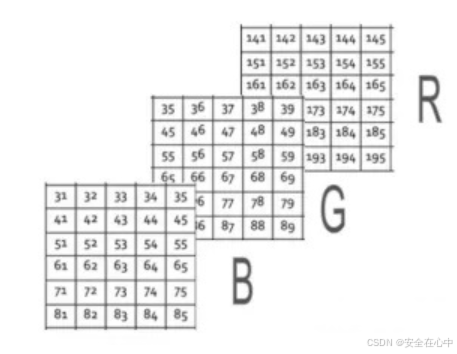
这些矩阵(通道)里面的坐标位置对应图像像素点,矩阵(通道)里面的值(0到255)代表像素的强度,你可以说是红色,绿色和蓝色色彩的强度。最后,所有这些矩阵(通道)都将叠加在一起,这样,当图像的形状加载到计算机中时,它会在二维矩阵上面再加上一个维度,我们说彩色图像在计算机中以三维矩阵来进行存储:
H × W × 3
其中 H 是整个高度上的像素数,W 是整个宽度上的像素数,3表示颜色通道数,在这种情况下,我们有3个通道R,G和B。我们上面的示例中,彩色图像的形状将是 6 x 5 x 3,因为我们在高度上有6个像素,在宽度上有5个像素,并且存在3个通道,了解了颜色通道,接下来我们来学习H(高度)、W(宽度)的具体内容。
图像坐标系
在使用OpenCV的时候,其实经常会用到对图像像素的操作。取单个像素,取部分像素(ROI操作),这些OpenCV都给我们提供了接口,但是一定要注意像素的坐标(横坐标和纵坐标),行和列之间到底是什么关系?什么时候又该用坐标,什么时候又该用行列?下面我将会细细道来。
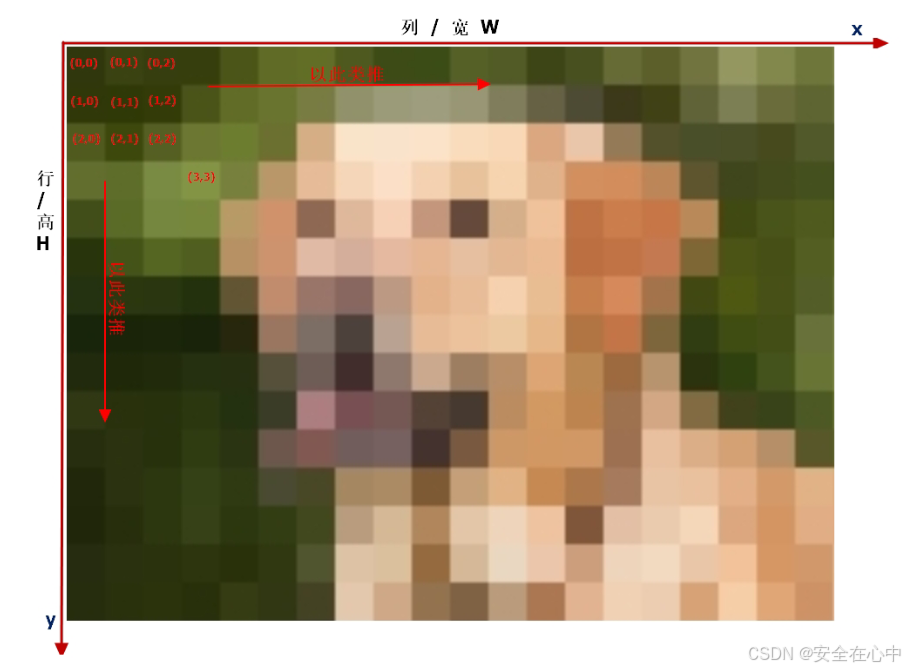
行列
行和列一般使用在矩阵中,属于矩阵中的概念,也就是OpenCV-Python中的numpy的Array(二维
数组)对象。如下图:
宽和高
宽和高是图像中的概念,内行人说矩阵,外行人是看图像的。一副图像的宽和高是相对的,看当前的方向。一般来说,宽对应像素矩阵的列,高对应像素矩阵的行。
x 和 y
其实我们在学习初中平面几何的时候,最常使用的坐标就是x和y,我们会默认的将x认为是横坐标,y认为是纵坐标。我们有这样先入为主的概念,其实,这个只是使用习惯的问题。我们也可以用y去代表横坐标,x去代表纵坐标,所以从本质上来说,x和y是没有任何物理意义的。如果按照x是横坐标,y是纵坐标的习惯去看,结合到图像中的坐标系一般是以左上角为原点,x轴向右,y轴向下,则x对应的范围是[0,col),y对应的范围是 [0,row)。即x对应列,y对应行。
获取图像属性
刚刚我们学习了图像的坐标系,了解了行列、宽高和像素坐标位置,那么我们怎么去获取图像的这些信息呢?接下来老师就来教大家怎么去获取一个图像的相关属性,包括行数,列数和通道数,图像数据类型,像素数等。
首先,在获取图像属性之前,我们需要加载图像,取得图像对象,通过图像对象的属性和函数我们就可以方便的查看图像的相关属性值了。今天的课程霸夫老师会以下面的示例图像(宽1080、高853的彩色图像)来带领大家学习使用OpenCV。

第一步、使用OpenCV加载图像
import cv2 as cv
注意 cv.imread() 默认加载的是彩色图像
图像文件名字 -- 不能包含中文字符
xxl_001.jpg 图像尺寸 (宽1080、高853)
img = cv.imread("xxl_001.jpg")
行、列和通道数
使用OpenCV获取图像的行数,列数和通道数非常的简单,使用前面的图像对象,通过 img.shape 就可以轻松获取到图像的行数、列数和通道数量。
彩色图像
print( img.shape )
输出
(853, 1080, 3)
它返回行,列和通道数的元组(如果图像是彩色的)
注意 如果图像是灰度的,则返回的元组仅包含行数和列数,因此这是检查加载的图像是灰度还是彩色的好方法。
图像像素总数
图像像素总数就是说图像有多少个像素点,也就是图像的行列乘积,我们可以通过img.size来获取,我们使用如下代码来进行测试和查看。
输出 图像像素总数
print( img.size )
输出
2763720
同学们思考一下这个 2763720 是怎么得出来的呢?答案其实很简单:就是 853*1080*3,三个乘数对应着行、列和通道总数。
图像灰度化
前面我们已经了解了灰度图像的概念,灰度图像就是黑白图像,每个像素点都是由黑白色组成,黑白色有不同的亮度,在计算机中用0到 255 来显示。那么问题来了,我们怎么使用0penCV让一个彩色图像装换成灰度图像呢?方法非常的简单,霸夫老师来给大家演示一下。
python
import cv2 as cv
# 注意 cv.imread() 默认加载的是彩色图像
# 图像文件名字 -- 不能包含中文字符
img = cv.imread("xxl_001.jpg")
# 第二种方法
# 将彩色图像转换成灰度图像 使用cvtColor 函数,
# 第一个参数img 图像对象,第二个参数cv.COLOR_BGR2GRAY, 返回的对象就是灰度图像了
img2 = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
cv.imshow("img", img)
cv.imshow("img2", img2)
cv.waitKey(0)
cv.destroyA11windows()这里需要注意一点,使用 cv.cvtColor 函数并不是直接将 img,图像改成了灰度图像,而是相当于拷贝了一个img 副本再转换成灰度图像,是一个新的图像对象。
效果如下图:
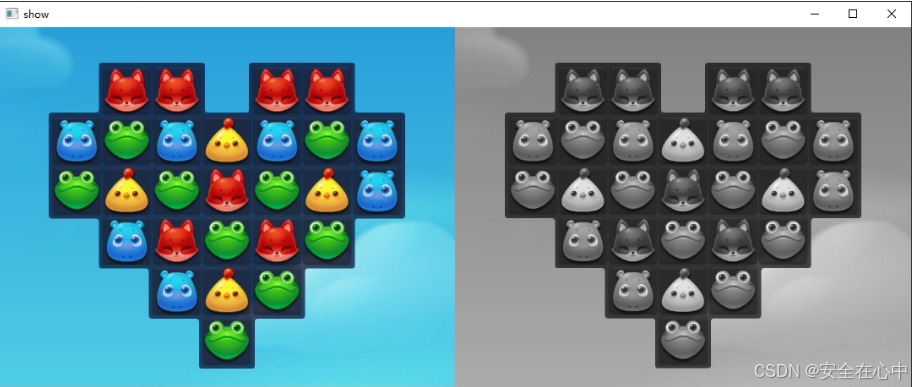
图像二值化
什么是图像二值化
图像二值化可以简单理解成,就是把图像转换成黑白两种颜色(一般用于提取图像特征),二值化图像:只有两种颜色,黑和白,255白色,0黑色。
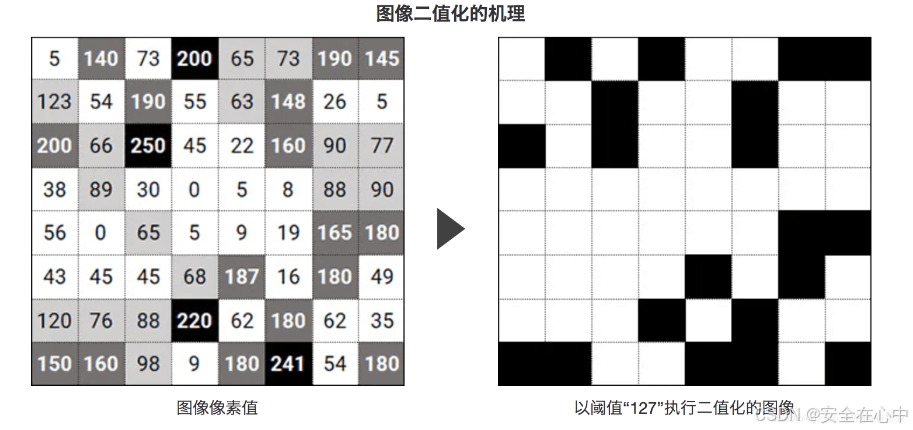
结合前面学习的彩色图像和灰度图像,一起来做个对比。
彩色图像:三个通道0-255,0-255,0-255,所以可以有2^24位空间
灰度图像:一个通道0-255,所以有256种颜色
二值图像:只有两种颜色,黑和白,255白色,0黑色
二值化图像有什么作用
二值化图像一般用来提取图像特征,也就是为了将感兴趣的目标和背景分离,我们可以理解为图象二值化是后续图象处理技术的基础。
图像的二值化是最简单的图像处理技术,它一般都跟具体算法联系在一起,很多算法的输入需要是二值数据。比如我们要提取消消乐游戏界面的可操作区域,就需要将操作区域和背景进行分离。比如要把图像文字转换为PDF文字,PDF上只能是黑白两种颜色。
图像二值化可以看作是聚类,可以看作是分类......这些其实不重要,重要的是它快。它最明显的意义就是简化后期的处理,提高处理的速度。
OpenCV将图像二值化
第一步、转成灰度图像(一般在图像二值化前,需要对图像进行灰度处理)
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
第二步、对灰度图像进行二值化
图像二值化函数函数 cv2.threshold(src, thresh, maxval, type)
用法示例
ret, img=cv2.threshold(img, 127, 255, cv2.THRESH_BINARY)
我们来学习了解-下OpenCv二值化函数的参数作用以及返回类型。
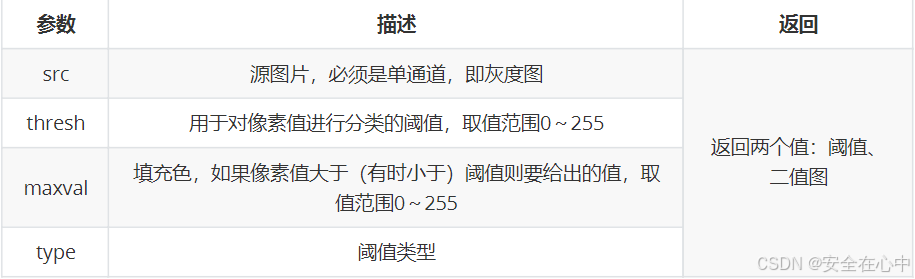
type 阈值类型表:
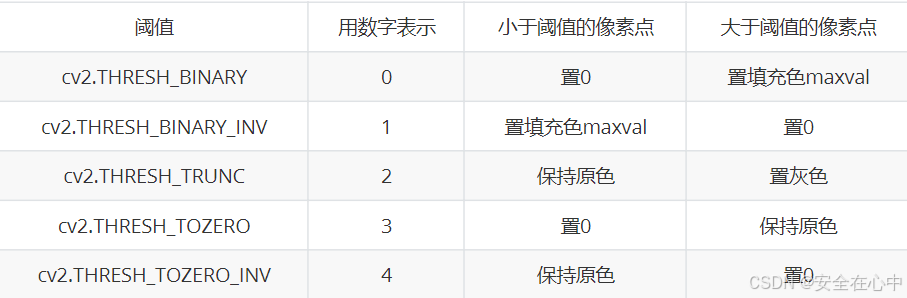
上代码看效果:
python
import cv2 as cv
from cv.cv工具 import ManyImages
# 注意 cv.imread() 默认加载的是彩色图像
# 图像文件名字 -- 不能包含中文字符
img = cv.imread("xxl_001.jpg")
# 使用cvtColor 函数将图像灰度化
img2 = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# 将灰度图像二值化
ret, img3 = cv.threshold(img2, 127, 255, cv.THRESH_BINARY)
cv.imshow("img", img)
cv.imshow("img2", img2)
cv.imshow("img3", img3)
cv.waitKey(0)
cv.destroyAllWindows()
图像匹配
什么是图像匹配
图像匹配,就是从一个图像中找出想要的小图像,打个比方:就好比拿着老师的头像寸照,然后去师的大学毕业照里面一个个的头像对照然后将老师找出来。
图像匹配包含模板匹配和特征匹配,模板匹配是一种最原始、最基本的模式识别方法;特征匹配相对模板匹配要复杂很多,这里先不做深入讲解。我们重点来学习了解模板匹配。
模板匹配是在一幅图像中寻找一个特定目标的方法之一,这种方法的原理非常简单,遍历图像中的每一个可能的位置,比较各处与模板是否"相似",当相似度足够高时,就认为找到了我们的目标。OpenCV给我们提供一个函数cv.matchTemplate(), 它将模板图像滑动到输入图像上,然后在模板图像下比较模板和输入图像的拼图。 OpenCV中实现了几种比较方法。它返回一个灰度图像,其中每个像素表示该像素的邻域与模板匹配的程度。
接下来我们用实例来展示OpenCV模板匹配的使用方法。
使用OpenCV模板匹配
单对象模板匹配
python
import cv2 as cv
# 读取图像
img = cv.imread("xxl_001.jpg")
gray_img = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# 读取需要检测的图像
img_template = cv.imread("bird.jpg")
# 一定记得转换成灰度图像
img_template_gray = cv.cvtColor(img_template, cv.COLOR_BGR2GRAY)
# 得到图像的高和宽
h, w = img_template_gray.shape
# 模板匹配操作
res = cv.matchTemplate(gray_img, img_template_gray, cv.TM_CCOEFF_NORMED)
# 得到最大和最小值得位置
min_val, max_val, min_loc, max_loc = cv.minMaxLoc(res)
# 如果方法是TM_SQDIFF或TM_SQDIFF_NORMED,则取最小值,其它则去最大值
# 左上角的位置 如果是TM_SQDIFF或TM_SQDIFF_NORMED top_left = min_loc
top_left = max_loc
# 右下角的位置
bottom_right = (top_left[0] + w, top_left[1] + h)
# 在原图上画上矩形
cv.rectangle(img, top_left, bottom_right, (0, 0, 255), 2)
cv.rectangle(gray_img, top_left, bottom_right, (255, 255, 255), 2)
# 显示原图和处理后的图像
cv.imshow("temp", img_template)
cv.imshow("img", img)
cv.imshow("gray_img", gray_img)
cv.waitKey(0)
cv.destroyAllWindows()这个代码段用于进行模板匹配,主要用于在一张图像中找到另一张图像的最佳匹配位置。以下是代码的分析:
```python
import cv2 as cv
读取图像
img = cv.imread("xxl_001.jpg")
gray_img = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
```
- 读取名为 `"xxl_001.jpg"` 的图像,并将其转换为灰度图像 `gray_img`,这是为了简化后续的模板匹配操作。
```python
读取需要检测的图像
img_template = cv.imread("bird.jpg")
一定记得转换成灰度图像
img_template_gray = cv.cvtColor(img_template, cv.COLOR_BGR2GRAY)
```
- 读取模板图像 `"bird.jpg"` 并将其转换为灰度图像 `img_template_gray`。
```python
得到图像的高和宽
h, w = img_template_gray.shape
```
- 获取模板图像的高度 `h` 和宽度 `w`。
```python
模板匹配操作
res = cv.matchTemplate(gray_img, img_template_gray, cv.TM_CCOEFF_NORMED)
```
- 使用 `cv.matchTemplate` 函数在灰度图像 `gray_img` 中进行模板匹配,`cv.TM_CCOEFF_NORMED` 是模板匹配的方法,用于计算模板与图像的相关系数。
```python
得到最大和最小值得位置
min_val, max_val, min_loc, max_loc = cv.minMaxLoc(res)
```
- 获取匹配结果 `res` 的最小值和最大值以及它们的位置。
```python
如果方法是TM_SQDIFF或TM_SQDIFF_NORMED,则取最小值,其它则去最大值
左上角的位置 如果是TM_SQDIFF或TM_SQDIFF_NORMED top_left = min_loc
top_left = max_loc
```
- 确定匹配结果的左上角位置 `top_left`。对于 `cv.TM_CCOEFF_NORMED`,取最大值的位置;对于其他方法如 `TM_SQDIFF`,则取最小值的位置。
```python
右下角的位置
bottom_right = (top_left0 + w, top_left1 + h)
```
- 计算匹配区域的右下角位置 `bottom_right`。
```python
在原图上画上矩形
cv.rectangle(img, top_left, bottom_right, (0, 0, 255), 2)
cv.rectangle(gray_img, top_left, bottom_right, (255, 255, 255), 2)
```
- 在原图 `img` 和灰度图 `gray_img` 上绘制矩形框,以标记模板的匹配位置。矩形的颜色分别为红色和白色,线宽为 2 像素。
```python
显示原图和处理后的图像
cv.imshow("temp", img_template)
cv.imshow("img", img)
cv.imshow("gray_img", gray_img)
cv.waitKey(0)
cv.destroyAllWindows()
```
- 显示模板图像、原图和处理后的灰度图像,等待按键后关闭所有窗口。
整体上,这段代码用于在给定的图像中找到模板图像的位置,并将其用矩形框标记出来。


多对象模板匹配
同学们有没有发现,其实小鸟在大图中多次出现,我们只显示了第一次出现的位置(查找方向从左到右,由上到下进行)。那么如果要搜索出图像中所有的小鸟,该怎么实现呢,同样也很简单,同样用上面的匹配函数,对结果使用阈值来找出所有匹配结果。
python
import cv2 as cv
import numpy as np
# 读取图像
img = cv.imread("xxl_001.jpg")
gray_img = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# 读取需要检测的图像
img_template = cv.imread("bird.jpg")
# 一定记得转换成灰度图像
img_template_gray = cv.cvtColor(img_template, cv.COLOR_BGR2GRAY)
# 得到图像的高和宽
h, w = img_template_gray.shape
res = cv.matchTemplate(gray_img, img_template_gray, cv.TM_CCOEFF_NORMED)
# 相似度 0到1 , 1表示完全相同
threshold = 0.9
loc = np.where(res >= threshold)
for pt in zip(*loc[::-1]):
# 标注匹配到的位置,并画上矩形
cv.rectangle(img, pt, (pt[0] + w, pt[1] + h), (0, 0, 255), 1)
cv.rectangle(gray_img, pt, (pt[0] + w, pt[1] + h), (255, 255, 255), 1)
# 显示原图和处理后的图像
cv.imshow("img", img)
cv.imshow("gray_img", gray_img)
cv.waitKey(0)
cv.destroyAllWindows()这段代码用于在图像中找到所有与模板匹配度高于设定阈值的位置,并在这些位置上绘制矩形框。逐行分析如下:
```python
res = cv.matchTemplate(gray_img, img_template_gray, cv.TM_CCOEFF_NORMED)
```
- 使用 `cv.matchTemplate` 计算模板匹配结果 `res`,方法为 `cv.TM_CCOEFF_NORMED`,返回的 `res` 是一个包含匹配度的矩阵,值在0到1之间。
```python
threshold = 0.9
```
- 设置匹配度阈值 `threshold` 为 0.9,表示只考虑匹配度高于 0.9 的匹配结果。
```python
loc = np.where(res >= threshold)
```
- 使用 `np.where` 查找所有匹配度大于等于阈值的位置,`loc` 是一个包含所有符合条件的坐标的元组。
```python
for pt in zip(*loc::-1):
```
- 遍历 `loc` 中的每一个坐标点 `pt`,`zip(*loc::-1)` 用于将坐标反转,并将其合并为 `(x, y)` 形式的点。
```python
cv.rectangle(img, pt, (pt0 + w, pt1 + h), (0, 0, 255), 1)
cv.rectangle(gray_img, pt, (pt0 + w, pt1 + h), (255, 255, 255), 1)
```
- 在原图 `img` 和灰度图 `gray_img` 上绘制矩形框标记匹配位置。矩形框在原图上为红色 (0, 0, 255),线宽为1像素;在灰度图上为白色 (255, 255, 255),线宽也为1像素。

图像切割
在做自动化脚本的时候,有时我们只关心图像的某些关键的部分区域,这时候就可以把这些关键区域的图像单独裁剪出来,进行处理或计算、识别。
在前面的学习列表的时候,我们学习了对列表里的数据进行切片,同理也可以对图像进行切割处理,因为图像在OpenCV里面图像也就是一个列表。
这里我们来温习一下列表的切片,列表切片用一个冒号隔开两个索引值,左边是开始位置,右边是结束位置。这里要注意的一点是:结束位置上的元素是不包含的(如上面例子中,"yellow"的索引值是4,我们写的是list0:3,便不能将其包含进来)。
python
list = ['red', 'green', 'blue', 'yellow', 'white', 'black']
print(list[:3])
print(list[3:])
print(list[:])以上示例输出结果:
'red', 'green', 'blue'
'yellow', 'white', 'black'
'red', 'green', 'blue', 'yellow', 'white', 'black'
如果省略了开始位置,Pvthon会从0这个位置开始。同样道理,如果要得到从指定索引值到列表未尾的所有元素,把结束位置也省去即可。如果啥都没有,只有一个冒号,Pvthon将返回整个列表的拷贝。
那图像切片也是一样的道理,只是它不只是切一行,而是要切多行,对图像像素矩阵进行多行的切今得到的结果就是图像的切割。
代码写法非常的简单,如下:
小图像 = 大图像上边:下边, 左边:右边
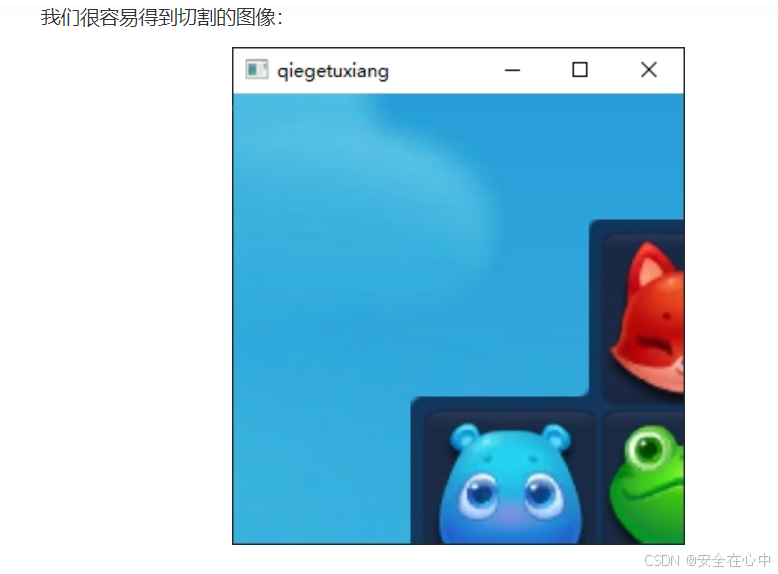
接下来,我们用实际案例来看看,如何写出图像切割的代码:
import cv2 as cv
注意 cv.imread() 默认加载的是彩色图像
图像文件名字 -- 不能包含中文字符
完整图像 = cv.imread("xxl_001.jpg")
这里我们来切完整图像的左上角 宽、高 都为 300 的区域。
区域图像 = 完整图像0:300, 0:300
cv.imshow("qiegetuxiang", 区域图像)
cv.waitKey(0)
cv.destroyAllWindows()
图像轮廓
什么是图像轮廓?
轮廓可以简单地解释为连接具有相同颜色或强度的所有连续点(沿边界)的曲线。轮廓是用于形 状分析以及对象检测和识别的有用工具。
为了获得更高的准确性,请使用二值化图像。因此,在找到轮廓之前,请应用阈值或canny边缘检测。
在OpenCV中,找到轮廓就像从黑色背景中找到白色物体。因此请记住,要找到的对象应该是 白色,背景应该是黑色。
我们通过前面的图像二值化可以轻松实现:
import cv2 as cv
注意 cv.imread() 默认加载的是彩色图像
图像文件名字 -- 不能包含中文字符
img = cv.imread("xxl_001.jpg")
使用cvtColor 函数将图像灰度化
img2 = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
将灰度图像二值化
ret, img3 = cv.threshold(img2, 127, 255, cv.THRESH_BINARY_INV)
cv.imshow("erzhihua", img3)
cv.waitKey(0)
cv.destroyAllWindows()
可以如下得到二值化图像:

查找轮廓
二值化图像已经有了,那我们如何查找到图像的轮廓呢,这里我们就可以调用cv.findContours来进行轮廓查找了。我们直接上实例代码看下:
import cv2 as cv
img = cv.imread("xxl_001.jpg")
imgray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
ret, thresh = cv.threshold(imgray, 127, 255, 0)
contours, hierarchy = cv.findContours(thresh, cv.RETR_TREE,
cv.CHAIN_APPROX_SIMPLE)
"""
这行代码 `contours, hierarchy = cv.findContours(thresh, cv.RETR_TREE, cv.CHAIN_APPROX_SIMPLE)` 用于检测图像中的轮廓。具体解释如下:
`thresh` 是输入的二值图像,其中轮廓会被检测。
`cv.RETR_TREE` 指定了轮廓检索模式,这里是获取所有轮廓及其层级结构。
`cv.CHAIN_APPROX_SIMPLE` 是轮廓逼近方法,减少轮廓点的数量,仅保留必要的点。
返回值:
`contours` 是一个列表,每个元素是一个轮廓,轮廓本身是点的数组。
`hierarchy` 是轮廓的层级信息,用于描述轮廓之间的嵌套关系。
"""
cv.findContours()函数中有三个参数,
第一个是源图像;
第二个是轮廓检索模式, cv.RETR_TREE是提取所有轮廓,并且重构嵌套轮廓的全部层次结构;
第三个是轮廓逼近方法。输出等高线和层次结构。轮廓是图像中所有轮廓的Python列表。
每个单独的轮廓是一个(x,y) 坐标的Numpy数组的边界点的对象。
注意 稍后我们将详细讨论第二和第三个参数以及有关层次结构。在此之前,代码示例中赋予它 们的值将适用于所有图像。
返回的contours是图像所有轮廓的列表, hierarchy是相应轮廓之间的关系
之前提到轮廓是一个连接具有相同颜色或强度的所有连续点(沿边界)的曲线 ,曲线又可以认为是很多连续的点连接在一起组成。那在程序中轮廓到底是什么样子存储的呢,我们可以打印出来看看。上源码:
import cv2 as cv
im = cv.imread('xxl_001.jpg')
imgray = cv.cvtColor(im, cv.COLOR_BGR2GRAY)
ret, thresh = cv.threshold(imgray, 127, 255, 0)
contours, hierarchy = cv.findContours(thresh, cv.RETR_TREE,
cv.CHAIN_APPROX_SIMPLE)
i = 1
for cnt in contours:
print('轮廓信息%s:\n' % i, cnt)
i += 1
结果:
轮廓信息1:
\[\[ 0 0\]
\[ 0 852\]
\[1079 852\]
\[1079 0\]\]
轮廓信息2:
\[\[238 83\]
\[485 83\]
\[486 84\]
\[487 84\]
...以下忽略
这里可以看到程序中是使用数值矩阵来存储轮廓信息的,大家只需要了解下就可以了。
绘制轮廓
要绘制轮廓,请使用cv.drawContours函数。只要有边界点,它也可以用来绘制任何形状。
函数的第一个参数是源图像,
第二个参数是应该作为Python列表传递的轮廓:
第三个参数是轮廓的索 引(在绘制单个轮廓时有用。要绘制所有轮廓,请传递-1),其余参数是颜色,厚度等等
在图像中绘制所有轮廓:
cv.drawcontours(img,contours,-1,(0,255,0),3)
绘制单个轮廓,如第四个轮廓:
cv.drawcontours(img,contours,3,(0,255,0),3)
但是在大多数情况下,以下方法会很有用:
cnt = contours4
cv.drawcontours(img,cnt,0,(0,255,0),3)
注意 最后两种方法相似,但是实战中,您会发现最后一种更有用。
绘制轮廓实例代码
import numpy as np
import cv2 as cv
img = cv.imread('xxl_001.jpg')
imgray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
ret, thresh = cv.threshold(imgray, 127, 255, 0)
contours, hierarchy = cv.findContours(thresh, cv.RETR_TREE,
cv.CHAIN_APPROX_SIMPLE)
cv.drawContours(img, contours, -1, (255, 255, 255), 3)
cv.imshow('lunkuo', img)
cv.waitKey(0)
cv.destroyAllWindows()
让我们逐条分析这段代码:```python
import numpy as np
import cv2 as cv
```
- 导入 `numpy` 库并将其命名为 `np`,导入 `cv2` 库并将其命名为 `cv`。`numpy` 通常用于处理数组,而 `cv2` 是 OpenCV 的库,用于计算机视觉操作。
```python
img = cv.imread('xxl_001.jpg')
```
- 读取名为 `'xxl_001.jpg'` 的图像文件,并将其存储在 `img` 变量中。路径 `'xxl_001.jpg'` 是相对路径或绝对路径,取决于文件的存储位置。
```python
imgray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
```
- 将彩色图像 `img` 转换为灰度图像 `imgray`。`cv.COLOR_BGR2GRAY` 是一个转换代码,用于从 BGR(蓝绿红)色彩空间转换到灰度色彩空间。
```python
ret, thresh = cv.threshold(imgray, 127, 255, 0)
```
- 对灰度图像 `imgray` 应用阈值处理,生成二值图像 `thresh`。`127` 是阈值,`255` 是最大值,`0` 表示使用默认的阈值方法(通常是简单阈值)。返回的 `ret` 是实际使用的阈值值,但在此代码中未使用。
```python
contours, hierarchy = cv.findContours(thresh, cv.RETR_TREE, cv.CHAIN_APPROX_SIMPLE)
```
- 从二值图像 `thresh` 中查找轮廓。`cv.RETR_TREE` 表示提取轮廓并重建轮廓的树形结构(包括父子关系),`cv.CHAIN_APPROX_SIMPLE` 表示使用简单的轮廓近似方法来压缩轮廓的边界。
```python
cv.drawContours(img, contours, -1, (255, 255, 255), 3)
```
- 在原图像 `img` 上绘制所有轮廓。`-1` 表示绘制所有轮廓,`(255, 255, 255)` 指定轮廓颜色为白色(RGB值),`3` 是轮廓的线宽。
```python
cv.imshow('lunkuo', img)
```
- 在一个名为 `'lunkuo'` 的窗口中显示图像 `img`,该窗口将展示绘制了轮廓的图像。
```python
cv.waitKey(0)
```
- 等待用户按下任意键,以便继续执行程序。`0` 表示无限等待,直到按键事件发生。
```python
cv.destroyAllWindows()
```
- 关闭所有 OpenCV 创建的窗口。
这个代码的整体功能是读取一张图像,将其转换为灰度图像,然后进行阈值处理,提取并绘制轮廓,并显示带有轮廓的图像。
执行代码我们可以得到如下效果
注意,在灰色图像中绘制不了彩色线条

轮廓面积
轮廓区域的面积大小计算就要利用函数cv.contourArea()了,我们只需要传入轮廓值就能很方便得到这个轮廓的面积了。
面积 = cv.contourArea(单个轮廓)
我们看下示例代码:
import cv2 as cv
im = cv.imread('xxl_001.jpg')
imgray = cv.cvtColor(im, cv.COLOR_BGR2GRAY)
ret, thresh = cv.threshold(imgray, 127, 255, 0)
contours, hierarchy = cv.findContours(thresh, cv.RETR_TREE,
cv.CHAIN_APPROX_SIMPLE)
for cnt in contours:
计算轮廓面积
area = cv.contourArea(cnt)
print(area)
我们运行下看看就能看到所有轮廓的面积了
919308.0
403914.5
371.0
2402.5
2.0
4.0
7.0
12.5
246.5
252.5
0.0
364.5
5805.5
51.5
153.5
#... 余下省略
轮廓边框
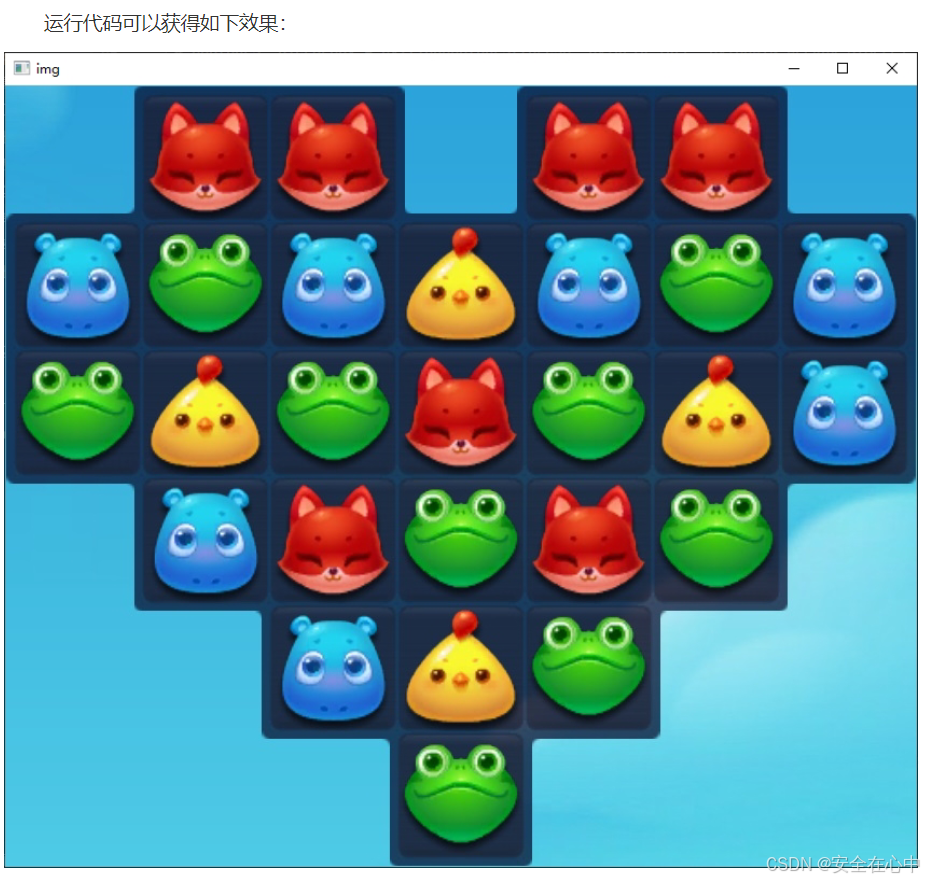
轮廓很准确的描绘出了图像中物体的边界,它可能是由多个点连起来的,但我们截取和操作的图像是方形的,所以我们要掌握一个函数,使得截取小图像时,刚好只裁剪出这个物体。
OpenCV里提供了一个外接边框的函数 boundingRect()
x,y,w,h = cv.boundingRect(cnt)
传入参数 cnt 是指 之前查找出来的所有轮廓里的某一个
返回值 x边框的横坐标
返回值y边框的纵坐标
返回值 w边框的宽度
返回值 h边框的高度
实例代码
import cv2 as cv
img = cv.imread('xxl_001.jpg')
imgray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
ret, thresh = cv.threshold(imgray, 127, 255, 0)
contours, hierarchy = cv.findContours(thresh, cv.RETR_TREE, cv.CHAIN_APPROX_SIMPLE)
for cnt in contours:
计算轮廓面积
area = cv.contourArea(cnt)
x, y, w, h = cv.boundingRect(cnt)
切割出轮廓面积大于指定大小的轮廓
if area > 6400:
按轮廓切割 = imgy:y + h, x:x + w
cv.imshow('img', 按轮廓切割)
cv.waitKey(0)
cv.destroyAllWindows()
以下是代码逐条翻译及解释:
- `import cv2 as cv`
导入 OpenCV 库,并用 `cv` 作为别名。
- `img = cv.imread(r"C:\Users\77653\Desktop\b0a2a77afe4a7cbde339024b962cd27.jpg")`
读取指定路径的图像,并存储在 `img` 变量中。
- `imgray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)`
将彩色图像 `img` 转换为灰度图像 `imgray`。
- `ret, thresh = cv.threshold(imgray, 127, 255, 0)`
对灰度图像 `imgray` 应用阈值处理,生成二值图像 `thresh`。阈值设置为 127,最大值为 255。
- `contours, hierarchy = cv.findContours(thresh, cv.RETR_TREE, cv.CHAIN_APPROX_SIMPLE)`
查找二值图像 `thresh` 中的所有轮廓,并返回轮廓列表 `contours` 和轮廓的层级结构 `hierarchy`。
- `for cnt in contours:`
遍历所有检测到的轮廓。
- `area = cv.contourArea(cnt)`
计算当前轮廓 `cnt` 的面积。
- `x, y, w, h = cv.boundingRect(cnt)`
计算当前轮廓的边界矩形的坐标 `(x, y)` 和尺寸 `(w, h)`。
- `if area > 6400:`
如果轮廓的面积大于 6400,则执行以下操作。
- `按轮廓切割 = imgy:y + h, x:x + w`
从原图像 `img` 中裁剪出轮廓区域,保存为 `按轮廓切割`。
- `cv.imshow('img', 按轮廓切割)`
显示裁剪后的图像 `按轮廓切割`,窗口名为 `'img'`。
- `cv.waitKey(0)`
等待用户按下任意键以关闭窗口。
- `cv.destroyAllWindows()`
关闭所有 OpenCV 创建的窗口。
这里我们简单的截取出了游戏的可操作区域,后面老师还将进一步给大家讲解如何提取符合筛选条件的轮廓。
课程总结
今天的课程中霸夫老师带领同学们对OpenCV进行了进一步的学习和使用,讲解了计算机的图像相关基础知识,图像坐标系,图像灰度化,图像二值化,使用OpenCV进行图像匹配、图像切割,还尝试了对图像进行轮廓处理,今天课程操作性强,知识内容丰富,希望同学们能在课后多多练习,加强理解。
课后习题
1、(单选题)下面哪种写法能让路径字符串不被转义?
A、c'C:\rmb\tmp\100.jpg '
B、t'C:\rmb\tmp\100.jpg '
C、r'C:\rmb\tmp\100.jpg '
D、a'C:\rmb\tmp\100.jpg '
2、(单选题)有一张宽320像素、高640像素的彩色图像 "test.jpg",使用 img = cv.imread('test.jpg')
加载后,执行 print( img.shape ) ,下面哪个结果是正确的?
A、(3, 320, 640 )
B、(320, 640, 3)
C、(640, 320, 3)
D、(320, 640)
3、(多选题)二值化图像有两种值,请在下面答案中找出来。
A、256
B、255
C、0
D、127
4、(单选题)在Python-OpenCV中下面哪个函数可以用来查找图像轮廓?
A、cv.findContours(参数...)
B、cv.threshold(参数...)
C、cv.boundingRect(参数...)
D、cv.matchTemplate(参数...)