AI和AGI
AI(人工智能- Artificial Intelligence**):** 先说说AI,这个大家可能都不陌生。AI,就是人工智能,它涵盖了各种技术和领域,目的是让计算机模仿、延伸甚至超越人类智能。想象一下,你的智能手机、智能家居设备,这些都是AI技术的应用。
AGI(通用人工智能): 然后我们来看AGI,即Artificial General Intelligence,中文叫通用人工智能。这可比一般的AI高级多了。AGI的目标是创造一个能像人类一样思考、学习、执行多种任务的系统。
Token
什么Token
在大语言模型领域,Token 通常用来表示文本数据中的一个单元。在不同的语境下,一个 token 可能代表一个字一个词,或者是一个句子。在英文中,一个 token 通常是一个词或者是标点符号。在一些汉语处理系统中,一个token 可能是一个字,也可能是一个词。Token 是处理和理解文本数据的基本单元。
误区
很多同学把 token 理解为中文语义里的"字节",对于这种理解,只能说从类比关系上有一定的相似度,因为"字节"是计算机存储和处理数据的基本单元,而"token" 则是语言模型处理文本信息的基本单元。
但是token并不是 "字节"
"Token"在语言模型中的作用比"字节"在计算机中的作用更加复杂和多元。在大语言模型中,"token"不仅代表文本数据中的一个单位,而且每个"token"都可能携带了丰富的语义信息。比如,在处理一句话时,"token"可能表示一个字,一个词,甚至一个短语,这些都可以被认为是语言的基本单元。同时,每个"token"在模型中都有一个对应的向量表示,这个向量包含了该"token"的语义信息、句法信息等
如何计算使用了多少Token
在下图可以看到实时生成的 tokens 消耗和对应字符数量(基于 GPT3)
如果我们想要直观的査看 GPT 是如何切分 token 的话,我们可以打开 :https://platform.openai.com/tokenizer
在这里值得注意的是,英文的 token 占用相对于中文是非常少的,这也是为什么很多中文长 prompt 会被建议翻译成英文设定,中文输出的原因。
Tokens(开发者食用)
作为开发者,我们会把发送给大模型的数据的容量叫做tokens,比如:我们之间会交流说这次发送了多少tokens给大模型,会不会tokens太大,导致爆token。这个token的最大值在大模型的接口文档中会有说明。
推荐
https://waytoagi.feishu.cn/wiki/KcjiwpIsOiZsY9kBl5Hc5NSanZf
Prompt
什么是Prompt
简单点说:我们询问ai的问题就是prompt的一部分。作为开发者,在开发应用时,很大一部分是在优化prompt,我们在使用大模型时,prompt起很大的作用。
prompt有哪些组成
我理解:
prompt = 问题的背景 + 与问题相关的供AI参考的数据 + 我们对问题的要求/我们希望ai做的事情
例如:

当然prompt还会包含很多其他的内容,比如自定义的知识库,并且有很多prompt优化的方法。但是上述三个基本是必须要包含的内容。
AI的回答是不可控的,ChatGPT是单词接龙,通过概率论判断下一个接龙的单词是什么,所以我们的prompt可以更好的约束ChatGPT 下一个接龙的单词,所以一个好的prompt,才能更好的使用大模型的生成、推理能力。
多模态
什么是多模态
多模态大模型
能够同时处理和理解多种类型的数据,如文本、图像、音频和视频。它通过联合建模Language、Vision、Audio等不同模态的信息,使模型能够从更原始的视觉、声音、空间等开始理解世界,而不仅仅是通过文字这一中间表示。这种能力使得多模态模型在处理复杂场景时更为有效,例如,它不仅能处理文本信息,还能处理文本与图像、语音等复合场景。
单模态大模型:
专注于处理单一类型的数据,如纯文本或纯图像。这类模型在特定领域内表现优异,如文本生成、图像识别等,但当面对需要跨模态理解的场景时,其能力受限。
:::info
总结:简单点说,单模态只处理一种类型的数据,但是多模态可以同时处理多种类型的数据。
:::
多模态前景:
随着技术的发展,多模态大模型经历了从传统单模态模型到通用单模态,再到通用多模态的发展过程。当前的多模态大模型通常以LLM(Large Language Model)为核心,具备多种模态输入和输出的能力,这在某种程度上预示了AGI(Artificial General Intelligence)的曙光。
RAG
什么是RAG?
"RAG"(Retrieval-Augmented Generation)是一个自然语言处理(NLP)技术,主要用于提高语言模型的效果和准确性。它结合了两种主要的NLP方法:检索(Retrieval)和生成(Generation)。
**检索(Retrieval):**这一部分的工作是从大量的文本数据中检索出与输入问题最相关的信息。它通常使用一个检索系统,比如基于BERT的模型,来在大规模的文档集合(例如维基百科)中寻找与输入相关的文段。
**生成(Generation):**生成部分则使用类似GPT的语言模型,它会根据检索到的信息来生成响应或回答。这个过程涉及理解检索到的内容,并在此基础上生成连贯、相关且信息丰富的文本。
RAG模型的关键在于它结合了这两种方法的优点:检索系统能提供具体、相关的事实和数据,而生成模型则能够灵活地构建回答,并融入更广泛的语境和信息。这种结合使得RAG模型在处理复杂的查询和生成信息丰富的回答方面非常有效。这种技术在问答系统、对话系统和其他需要理解和生成自然语言的应用中非常有用。
LangChain实现RAG原理

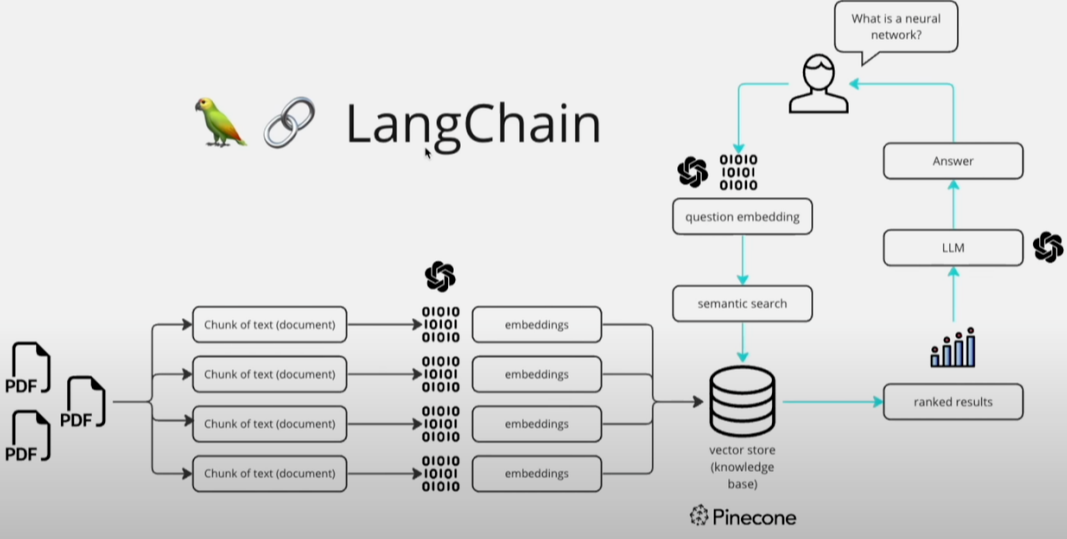
一文看懂RAG:大语言模型落地应用的未来
https://mp.weixin.qq.com/s/0mzAzXzRtxjuphvt9aGdQA
优点
RAG可以用更低的成本的增强大模型的能力,比Fine-Tuning 成本更低,并且收获比微调更好的效果
Agent
未完待续。。。