在当今的数据驱动环境中,掌握使用 Apache Spark 和 Deequ 对大型数据集进行分析对于任何处理数据分析、SEO 优化或需要深入研究数字内容的类似领域的专业人士来说都至关重要。
Apache Spark 提供处理大量数据所需的计算能力,而 Deequ 提供质量保证层,为所谓的"数据单元测试"设定基准。这种组合可确保业务用户对其数据的完整性充满信心,以便进行分析和报告。
您是否曾经在维护大型数据集的质量方面遇到过挑战,或者发现难以确保分析中使用的数据属性的可靠性?如果是这样,将 Deequ 与 Spark 集成可能是您正在寻找的解决方案。本文旨在指导您完成从安装到实际应用的整个过程,重点是改进您的工作流程和结果。通过探索 Deequ 和 Spark 的功能和优势,您将学习如何在数据项目中有效地应用这些工具,确保您的数据集不仅满足而且超过质量标准。让我们深入研究这些技术如何改变您的数据分析和质量控制方法。
使用 Apache Spark 和 Deequ 进行数据分析简介
深入了解您的数据集在数据分析中至关重要,这就是 Apache Spark 和 Deequ 的亮点。Apache Spark 以其快速处理大型数据集而闻名,这使得这个著名的工具对于数据分析是必不可少的。它的架构擅长有效地处理大量数据,这对于数据剖析至关重要。
Deequ 通过专注于数据质量来补充 Spark。这种协同作用为数据剖析提供了强大的解决方案,允许识别和纠正缺失值或不一致等问题,这些问题对于准确分析至关重要。
究竟是什么让 Deequ 成为确保数据质量的宝贵资产?Deequ 的核心是实现"数据单元测试",如果您具有软件开发背景,这个概念听起来可能很熟悉。但是,这些测试不适用于代码;它们是为了您的数据。它们允许您设置特定的质量基准,您的数据集在被视为可靠的分析或报告之前必须满足这些基准。
假设您正在处理客户数据。使用 Deequ,您可以轻松设置检查以确保每条客户记录都是完整的,电子邮件地址遵循有效的格式,或者不存在重复的条目。这种审查水平使 Deequ 与众不同------它将数据质量从一个概念转化为可衡量、可实现的目标。
Deequ 与 Apache Spark 的集成利用 Spark 的可扩展数据处理框架,在庞大的数据集中有效地应用这些质量检查。这种组合不仅仅是标记问题;它提供指导更正过程的可操作见解。例如,如果 Deequ 在数据集中检测到大量不完整的记录,您可以调查原因(无论是数据收集中的缺陷还是数据输入中的错误)并进行纠正,从而提高数据的整体质量。
下面是一个高级图表(来源:AWS),说明了 Deequ 库在 Apache Spark 生态系统中的使用情况:
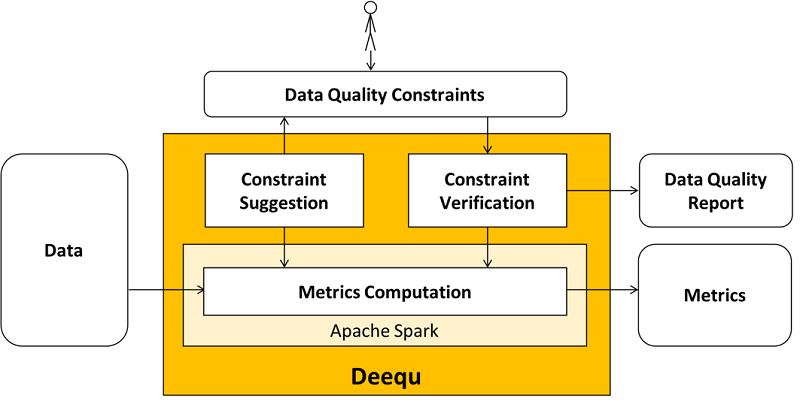
设置 Apache Spark 和 Deequ 以进行数据分析
要开始使用 Apache Spark 和 Deequ 进行数据分析,设置您的环境至关重要。确保已安装 Java 和 Scala,因为它们是运行 Spark 的先决条件,您可以通过 Spark 的官方文档进行验证。
对于在 Spark 上运行的 Deequ,请将库添加到您的构建管理器中。如果您使用的是 Maven,则只需将 Deequ 依赖项添加到 pom.xml 文件中即可。对于 SBT,请将其包含在 build.sbt 文件中,并确保它与 Spark 版本匹配。
Python 用户,您不会被排除在外。PyDeequ 是将 Deequ 的功能集成到 Python 环境中的首选。使用以下命令通过 pip 安装它:
1
pip install pydeequ install pydeequ安装后,进行快速测试以确保一切顺利:
1
import pydeequ pydeequ2
3
<span style="color:#aa5500"># Simple test to verify installation</span>4
print(pydeequ.__version__)(pydeequ.__version__)此快速测试将打印已安装的 PyDeequ 版本,确认您的设置已准备好运行。通过这些步骤,您的系统现在可以使用 Spark 和 Deeq 执行强大的数据质量检查,为即将到来的项目中的深入数据分析铺平了道路。
使用 Deequ 分析数据的实用指南
使用 Apache Spark 和 Deequ 准备好环境后,您就可以参与数据分析的实际方面了。让我们专注于 Deequ 为数据分析提供的一些关键指标------完整性、唯一性和相关性。
首先是完整性;此指标通过验证数据中是否存在 null 值来确保数据完整性。唯一性识别并消除重复记录,确保数据独特性。最后,Correlation 量化了两个变量之间的关系,从而提供了对数据依赖关系的见解。
假设您有一个来自 IMDb 的数据集,其结构如下:
1
root2
|-- tconst: string (nullable = true)|-- tconst: string (nullable = true)3
|-- titleType: string (nullable = true)|-- titleType: string (nullable = true)4
|-- primaryTitle: string (nullable = true)|-- primaryTitle: string (nullable = true)5
|-- originalTitle: string (nullable = true)|-- originalTitle: string (nullable = true)6
|-- isAdult: integer (nullable = true)|-- isAdult: integer (nullable = true)7
|-- startYear: string (nullable = true)|-- startYear: string (nullable = true)8
|-- endYear: string (nullable = true)|-- endYear: string (nullable = true)9
|-- runtimeMinutes: string (nullable = true)|-- runtimeMinutes: string (nullable = true)10
|-- genres: string (nullable = true)|-- genres: string (nullable = true)11
|-- averageRating: double (nullable = true)|-- averageRating: double (nullable = true)12
|-- numVotes: integer (nullable = true)|-- numVotes: integer (nullable = true)我们将使用以下 Scala 脚本来分析数据集。此脚本将应用各种 Deequ 分析器来计算指标,例如数据集的大小、列的完整性和标识符的唯一性。'averageRating'``'tconst'
1
import com.amazon.deequ.analyzers._ com.amazon.deequ.analyzers._2
import com.amazon.deequ.AnalysisRunner com.amazon.deequ.AnalysisRunner3
import org.apache.spark.sql.SparkSession org.apache.spark.sql.SparkSession4
5
val spark = SparkSession.builder() spark = SparkSession.builder()6
.appName("Deequ Profiling Example")appName("Deequ Profiling Example")7
.getOrCreate()getOrCreate()8
9
val data = spark.read.format("csv").option("header", "true").load("path_to_imdb_dataset.csv") data = spark.read.format("csv").option("header", "true").load("path_to_imdb_dataset.csv")10
11
val runAnalyzer: AnalyzerContext = { AnalysisRunner runAnalyzer: AnalyzerContext = { AnalysisRunner12
.onData(data)onData(data)13
.addAnalyzer(Size())addAnalyzer(Size())14
.addAnalyzer(Completeness("averageRating"))addAnalyzer(Completeness("averageRating"))15
.addAnalyzer(Uniqueness("tconst"))addAnalyzer(Uniqueness("tconst"))16
.addAnalyzer(Mean("averageRating"))addAnalyzer(Mean("averageRating"))17
.addAnalyzer(StandardDeviation("averageRating"))addAnalyzer(StandardDeviation("averageRating"))18
.addAnalyzer(Compliance("top rating", "averageRating >= 7.0"))addAnalyzer(Compliance("top rating", "averageRating >= 7.0"))19
.addAnalyzer(Correlation("numVotes", "averageRating"))addAnalyzer(Correlation("numVotes", "averageRating"))20
.addAnalyzer(Distinctness("tconst"))addAnalyzer(Distinctness("tconst"))21
.addAnalyzer(Maximum("averageRating"))addAnalyzer(Maximum("averageRating"))22
.addAnalyzer(Minimum("averageRating"))addAnalyzer(Minimum("averageRating"))23
.run()run()24
}25
26
val metricsResult = successMetricsAsDataFrame(spark, runAnalyzer) metricsResult = successMetricsAsDataFrame(spark, runAnalyzer)27
metricsResult.show(false).show(false)执行此脚本会提供 DataFrame 输出,该输出揭示了有关我们数据的几个见解:
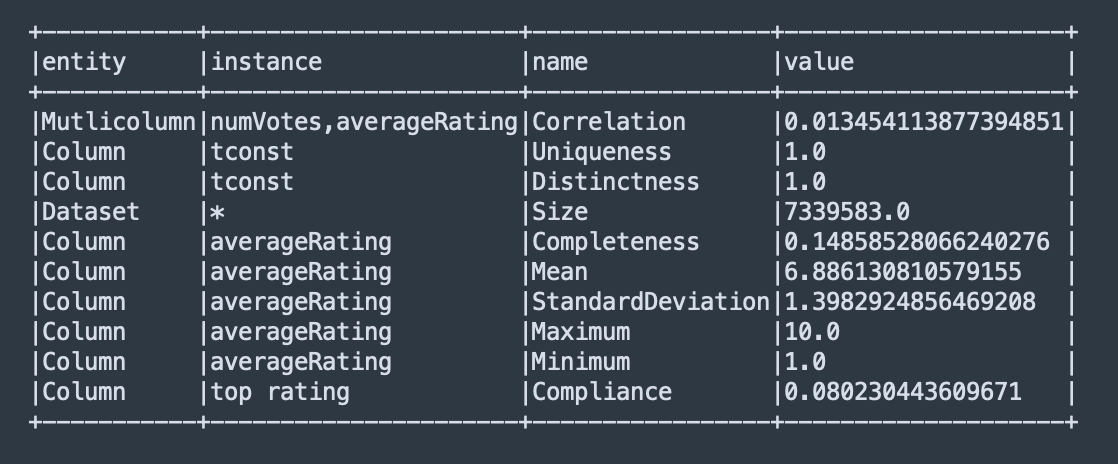
从输出中,我们观察到:
- 数据集有 7,339,583 行。
- 列的完全非重复性和 1.0 的唯一性表示列中的每个值都是唯一的。
tconst - 跨度从最小 1 到最大 10,平均为 6.88,标准差为 1.39,突出了数据的评级变化。
averageRating - 该列的完整性得分为 0.148 表明,只有大约 15% 的数据集记录具有指定的平均评级。
averageRating - 通过 Pearson 相关系数(为 0.01)分析两者之间的关系,表明这两个变量之间没有相关性,符合预期。
numVotes``averageRating
这些指标使我们能够获得洞察力,以浏览您的数据集的复杂性,从而支持数据管理中的明智决策和战略规划。
用于数据质量保证的高级应用程序和策略
数据质量保证是一个持续的过程,对于任何数据驱动的运营都至关重要。使用 Deequ 等工具,您可以实施不仅可以检测问题,还可以防止问题的策略。通过对增量数据加载进行数据分析,我们可以检测异常并随着时间的推移保持一致性。例如,利用 Deeq 的 AnalysisRunner,我们可以观察历史趋势并设置检查以捕获与预期模式的偏差。
例如,如果您的 ETL 作业的通常输出约为 700 万条记录,则此计数的突然增加或减少可能是潜在问题的明显迹象。调查此类偏差至关重要,因为它们可能表明数据提取或加载过程存在问题。利用 Deeq 的 Check 功能,您可以验证是否符合预定义的条件,例如预期的记录计数,以自动标记这些问题。
属性唯一性对于数据完整性至关重要,也需要时刻保持警惕。想象一下,发现客户 ID 属性的唯一性得分发生了变化,该属性应该是坚定不移的唯一性。此异常可能表示重复记录或数据泄露。通过使用 Deeq 的唯一性指标进行分析及时检测将帮助您维护数据的可信度。
历史一致性是质量保证的另一个支柱。如果历史上在 1 到 10 之间波动的列突然显示超出此范围的值,这就会引发问题。这是数据输入错误还是用户行为的实际转变?使用 Deequ 进行分析可以帮助您辨别差异并采取适当的措施。可以将其配置为跟踪 的历史分布并提醒您任何异常情况。'averageRating'``AnalysisRunner``'averageRating'
使用 Deequ 的聚合指标进行异常检测的业务用例
考虑一个业务使用案例,其中某个进程正在爬取网站页面,并且它需要一种机制来识别爬网过程是否按预期工作。为了在此过程中进行异常检测,我们可以使用 Deequ 库来识别特定时间间隔的记录计数,并将其用于高级异常检测技术。例如,抓取是指在 9500 个月内每天在网站上识别 10500 到 2 个页面。在这种情况下,如果抓取范围高于或低于此范围,我们可能希望向团队发出警报。下图显示了网站上看到的页面的每日计算记录计数。

使用基本统计技术,如变化率(记录每天都在变化),可以看到变化总是在零附近振荡,如下图所示。

下图显示了变化率的正态分布,根据钟形曲线的形状,很明显,该数据点的预期变化约为 0%,标准差为 2.63%。
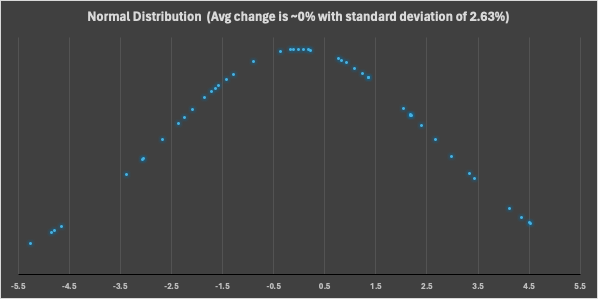
这表明,对于此网站,页面添加/删除的范围约为 -5.26% 到 +5.25%,置信度为 90%。根据此指标,可以在页面记录计数上设置规则,以便在更改范围未遵循此准则时引发警报。
这是对数据使用统计方法来识别聚合数字异常的基本示例。根据历史数据可用性和季节性等因素,可以使用 Holt-Winters Forecasting 等方法进行有效的异常检测。
Apache Spark 和 Deequ 的融合形成了一个强大的组合,可帮助您提升数据集的完整性和可靠性。通过上面演示的实际应用程序和策略,我们看到了 Deequ 如何不仅识别而且防止异常,从而确保您珍贵数据的一致性和准确性。
因此,如果您想释放数据的全部潜力,我建议您利用 Spark 和 Deequ 的强大功能。使用此工具集,您将保护数据质量并显著增强您的决策流程,并且您的数据驱动型见解将既强大又可靠。