ELK是什么?
首先说说什么是ELK
ELK 是一个开源的日志管理和分析平台,由三个主要组件组成:
- Elasticsearch:一个分布式搜索和分析引擎,能够快速存储、搜索和分析大量数据。它是 ELK 堆栈的核心,负责数据的索引和查询。
- Logstash:一个数据处理管道,可以从多种来源收集数据,进行处理和转换,然后将数据发送到 Elasticsearch。Logstash 支持多种输入、过滤和输出插件,使其非常灵活。
- Kibana:一个数据可视化工具,允许用户通过图形界面查看和分析存储在 Elasticsearch 中的数据。用户可以创建仪表板、图表和其他可视化效果,以便更好地理解数据。
ELK 堆栈通常用于日志管理、监控和数据分析,广泛应用于 IT 运维、安全分析和业务智能等领域。通过 ELK,用户可以实时收集、分析和可视化数据,从而快速发现和解决问题。
用白话说:L用来将写的日志文件传输到E中,E可以理解为一个高性能的数据库,支持存储数据和查询,K用来将E中的数据用可视化页面展示出来。
这三个工具都是单独 存在的,只是经常将它们组合在称为ELK,所以说如果有其他的工具可以代替其中一个,即可以代替使用,比如说ELK中的L,它功能很多,但是占用内存太多了,轻量级的filebeat 就可以适用大多数情况,其简化了部署和配置过程,还通过SSL/TLS支持确保了数据传输的安全性,减少了对系统资源的占用。通过filebeat可以收集多种不同格式的数据,并转换成es可以分辨的格式(如json)存入es中指定的索引中,之后就可以用过kibana查看es中收到的数据。
E中的索引:是一个逻辑命名空间,包含一组相关的文档,类似于传统关系型数据库中的数据库。
ES中的文档:是 Elasticsearch 中存储的基本数据单元,表示一条记录或一项数据,类似于数据库中的一行。
字段(Field):文档由若干字段组成,每个字段有一个字段名和字段值,字段值可以是多种类型,如字符串、数字、日期等。
具体实现
前言
以下步骤是用的aliyun的linux服务器,只要你用的是linux服务器就大差不差都能使用ip地址为:121.196.217.190
在代码中如果有使用到ip地址的请记得把 ip 地址替换!
还有如果用的是服务器的话,记得要把端口开放,不然外部浏览器是进不去容器使用的端口,这里要用到的端口是9200、9300、5601,还有防火墙问题朋友请自行解决。
安装的时候最好统一版本,否则会出现很多问题,我这里使用的版本都是7.12.1版本,拉取镜像的时候统一加上该版本号。
Docker 搭建ELK之前最好熟悉docker的相关指令:比如容器卷使用 docker run -d -v myvolume:/data myimage、强制删除容器: docker rm -f 容器id、创建网络: docker network create elk、进入容器docker exec -it es /bin/bash等等。
在后面的步骤中我也会简短的介绍这些命令的作用,还是看不懂的可以无脑复制粘贴,或者去gpt再详细搜一下命令的作用。
为了方便所有容器的挂载,先创建如下目录 /usr/local/elk,再执行mkdir /usr/local/elk/{elasticsearch,kibana} 创建2个对应的目录,所以以下操作如无特别说明,均在 /usr/local/elk下执行。
为了容器间的通信,需要先用 docker 创建一个网络:
cobol
docker network create --subnet=192.168.0.0/16 elk至于为什么网络用的是192.168.0.0/16 朋友们可以自己去搜一下。略:其实没什么特殊要求,你想的话也可以改,
一、Docker 安装 ElasticSearch
1、拉取镜像
cobol
docker pull elasticsearch:7.12.12、检查是否拉取成功 运行后看到自己的镜像排列其中即拉取成功
cobol
docker images3、运行容器,并将容器内部的配置文件复制一份到容器外。
cmd
# 运行 elasticsearch
docker run -d --name es --net elk -P -e "discovery.type=single-node" elasticsearch:7.12.1docker run:Docker CLI 的命令,用于创建并启动一个新的容器。-d:表示以 detached 模式运行容器,即在后台运行。--name es:为容器指定一个名称,这里名称为es。--net elk:指定容器要加入的网络,这里使用的是名为elk的网络。-P:将容器的端口映射到宿主机的随机端口上。这使得可以从宿主机访问容器的端口。-e "discovery.type=single-node":设置环境变量discovery.type为single-node。这是 Elasticsearch 的配置,表示以单节点模式运行,不需要集群模式的发现过程。elasticsearch:7.12.1:指定要使用的镜像名称和标签,这里使用的是elasticsearch镜像的7.12.1版本。
cmd
# 进入容器查看配置文件路径
docker exec -it es /bin/bash
cd configdocker exec:Docker CLI 的命令,用于在运行中的容器内执行命令。-it:这两个参数组合在一起,-i表示交互式(interactive),-t表示分配一个伪终端(pseudo-TTY)。它们使得你可以与容器内运行的命令进行交互。es:指定要执行命令的容器的名称或 ID。在这个例子中,容器名称是es。/bin/bash:这是要在容器内执行的命令,即启动 Bash shell。
4、容器化配置
在 config 中使用ls命令可以看到 elasticsearch.yml 配置文件,再执行 pwd 命令可以看到当前目录为: /usr/share/elasticsearch/config,后用命令exit退出容器,开始执行文件的拷贝:
cmd
# 将容器内的配置文件拷贝到 /usr/local/elk/elasticsearch/ 中
docker cp es:/usr/share/elasticsearch/config/elasticsearch.yml elasticsearch/
# 修改文件权限
chmod 666 elasticsearch/elasticsearch.yml
# 在elasticsearch 目录下再创建data目录,同时修改权限
mkdir elasticsearch/data
chmod -R 777 elasticsearch/data这里进行修改文件权限只是为了在进行挂载后,在外部修改配置文件,容器内部的配置文件也会更改。
5、重新运行容器并挂载刚才创建的文件
cmd
# 先删除旧的容器
docker rm -f es
# 运行新的容器
docker run -d --name es \
--net elk \
-p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
--privileged=true \
-v $PWD/elasticsearch/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v $PWD/elasticsearch/data/:/usr/share/elasticsearch/data \
elasticsearch:7.12.1-v $PWD/elasticsearch/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml:
- 将宿主机当前目录下的
elasticsearch/elasticsearch.yml文件挂载到容器的 Elasticsearch 配置目录中,用于自定义 Elasticsearch 配置。
-v $PWD/elasticsearch/data/:/usr/share/elasticsearch/data:
- 将宿主机当前目录下的
elasticsearch/data/目录挂载到容器的 Elasticsearch 数据目录中,用于持久化存储 Elasticsearch 数据。
此时使用 docker ps 即可查看已经运行的容器有哪些,此时使用curl 121.196.217.190:9200 或者直接去浏览器输入121.196.217.190:9200查看elasticsearch有没有启动成功,下面就是成功的样子。

到此为止容器elasticsearch安装完成,之后因为data已经挂载了,在data下可以查看容器内的数据。在宿主机修改也会同步到容器内部。
6、es认证
进入到vi elasticsearch/elasticsearch.yml 进行操作添加配置进入vim操作后,摁下 i进入插入模式将以下内容添加进去。
cmd
http.cors.enabled: true
http.cors.allow-origin: "*"
xpack.security.enabled: true
xpack.security.audit.enabled: true
xpack.license.self_generated.type: basic
xpack.security.transport.ssl.enabled: true添加好使用命令esc + : + wq!后摁下enter就修改配置好了,可以使用cat elasticsearch/elasticsearch.yml 进行查看。
之后重启es 使用命令docker restart es
此时进入到es容器中docker exec -it es /bin/bash 进入到bin文件夹中cd bin
运行以下命令
cmd
./elasticsearch-setup-passwords interactive之后就可以让你输入密码了,建议都输入成一样的,比如abcdef,
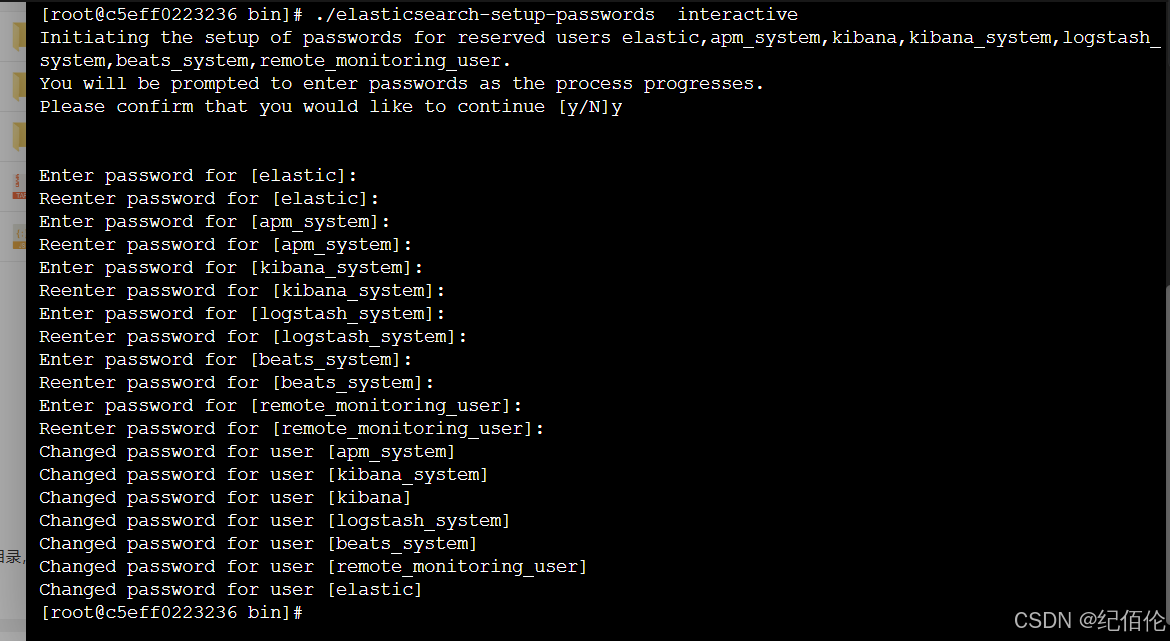
之后可以换个浏览器(怕当前浏览器有缓存)再输入121.196.217.190:9200 发现有弹窗让你输入账号密码,说明es认证成功了,
账号默认是elastic 密码就是刚才自己输入的那个

二、Docker 安装 Kibana
1、拉取镜像
cobol
docker pull kibana:7.12.12、检查是否拉取成功 运行后看到自己的镜像排列其中即拉取成功
cobol
docker images3、启动
cmd
# 启动 kibana 容器并连接同一网络elk
docker run -d --name kibana --net elk -P -e "ELASTICSEARCH_HOSTS=http://es:9200" -e "I18N_LOCALE=zh-CN" kibana:7.12.1-e "ELASTICSEARCH_HOSTS=http://es:9200" 表示连接刚才启动的 elasticsearch 容器,因为在同一网络(elk)中,地址可直接填 容器名+端口,即 es:9200, 也可以填 http://121.196.217.190:9200,即 http://ip:端口
4、拷贝文件
cmd
docker cp kibana:/usr/share/kibana/config/kibana.yml kibana/
chmod 666 kibana/kibana.yml之后打开配置文件修改内容
修改es的地址为自己的ip,添加账号密码和添加i18n.locale: zh-CN将kibana改为汉化版本。
注意:账号密码都要用""包围 比如"elastic"/"abcdef"
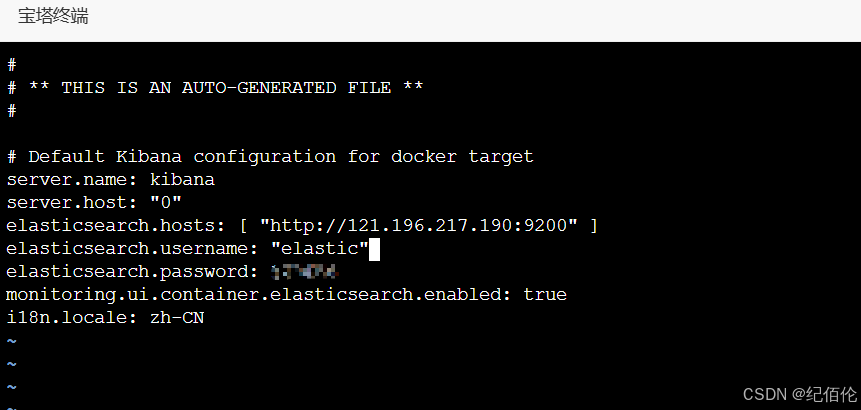
这样有了配置文件,在启动容器时就不用通过 -e 指定环境变量了。
5、重新开个容器
cmd
#删除原来未挂载的容器
docker rm -f kibana
# 启动容器并挂载
docker run -d --name kibana \
-p 5601:5601 \
-v $PWD/kibana/kibana.yml:/usr/share/kibana/config/kibana.yml \
--net elk \
--privileged=true \
kibana:7.12.1等待两秒后浏览器输入看是否成功http://121.196.217.190:5601 打开 kibana 控制台,就能看到可视化页面了,如果失败了可以使用: docker logs kibana 查看容器日志看是否运行有误等。
至此:ELK中的EK已经完成!
最后就看L了,这里就直接配置一个filebeat
三、配置filebeat
filebeat不用docker下载了,可以直接使用wget下载
cmd
# 进入elk文件夹后
# 下载
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.8.1-linux-x86_64.tar.gz
# 解压文件
tar -zxvf filebeat-8.8.1-linux-x86_64.tar.gz
# 重命名
mv filebeat-8.8.1-linux-x86_64 filebeatelk在宝塔中的简单部署和使用_宝塔 elasticsearch-CSDN博客
可以先看看这个博主的后半段。