一、背景
网络领域的新词发现(挖掘)是一个非常重要的nlp课题。在处理文本对象时,非常关键的问题在于"切词"这个环节,几乎所有的后续结果都依赖第一步的切词。因此切词的准确性在很大程度上影响着后续的处理,切词结果的不同,也就影响了特征的提取,跟数据挖掘一样,特征提取的好坏特别重要,不论用什么算法,特征好数据好结果才会好。
目前很多的切词模块可以处理大部分的通用语料,然而有两类文本集仍然处理的不是很好,就是:
(1)网络文档
(2)领域文档
这两类文本的特点在于包含大量新词,一般词典的涵盖程度比较低。对于领域文档,各领域的专家可以人工构建知识本体,拓展已有词库的不健全。
二、判断新词的核心指标
(1)成词标准1:词语的内部凝聚程度要足够高(凝聚度要高)
凝聚程度用以衡量相邻字组合成词语的程度,可以用点间互信息衡量(pointwise mutual information)。
当 x, y 相互独立时,x 跟 y 不相关,则 p(x , y) = p(x)*p(y), PMI = 0。PMI值越大,成词概率越大。
eg:在 5000 万字的样本中, "知" 出现了 150 万次, "乎" 出现了 4 万次。那 "知" 出现的概率为 0.03, "乎" 出现的概率为 0.0008。如果两个字符出现是个独立事件的话,"知"、"乎" 一起出现的期望概率是 0.03 * 0.0008 = 2.4e-05。如果实际上 "知乎" 出现了 3 万次, 则实际上"知"、"乎" 一起出现的概率是 6e-03, 是期望概率的 250 倍。也就是说两个字越相关,点间互信息越大。
(2)成词标准2:词语的左右邻字要足够丰富(自由度要高)
如果一个字符组合可以成词,它应当出现在丰富的语境中,也就是说,拥有丰富的左右邻字。当前文本片段的上文和下文可搭配词语越丰富,则其上文信息熵(左信息熵)和下文信息熵(右信息熵)越大。
p(w) 表示的是事件 w出现的概率,在新词挖掘的时候就是一个词出现的概率。
eg:
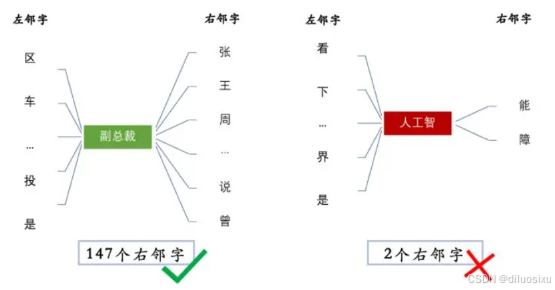
在文本中出现6000+次的"副总裁 " 和"人工智 " ,字符组合的左熵都在6左右,但"副总裁 "的右邻字包括 { 张,王,说, ...... } 等147个词,而"人工智 "的右邻字只有 { 能,障 } 两种,显然"人工智"不能称作一个词。
考虑这么一句话"吃葡萄不吐葡萄皮不吃葡萄倒吐葡萄皮","葡萄"一词出现了4次,其中左邻字分别为 {吃, 吐, 吃, 吐} ,右邻字分别为 {不, 皮, 倒, 皮} 。根据公式,"葡萄"一词的左邻字的信息熵为 -- (1/2) · log(1/2) -- (1/2) · log(1/2) ≈ 0.693 ,它的右邻字的信息熵则为 -- (1/2) · log(1/2) -- (1/4) · log(1/4) -- (1/4) · log(1/4) ≈ 1.04 。可见,在这个句子中,"葡萄"一词的右邻字更加丰富一些。
一般,我们取左右信息熵中的最小值。
三、新词挖掘步骤
新词挖掘可以分为三个步骤:
-
生成候选词:基于N-gram(n-gram:假设当前词出现的概率仅仅与前面的 n-1 个单词相关)统计,获取出现频率较高的短语作为候选项;
-
对候选项进行多维度特征统计(词频、凝聚程度、自由度等);
-
将多维度特征进行综合评估,排序,取top-K
四、新词应用价值
1、提高分词准确率
2、内容安全场景,欺诈词库扩充