哈希表(散列表)
出现的原因
在顺序表中查找时,需要从表头开始,依次遍历比较ai与key的值是否相等,直到相等才返回索引i;在有序表中查找时,我们经常使用的是二分查找,通过比较key与ai的大小来折半查找,直到相等时才返回索引i。最终通过索引找到我们要找的元素。
但是,这两种方法的效率都依赖于查找中比较的次数。我们有一种想法,能不能不经过比较,而是直接通过关键字key一次得到所要的结果呢?这时,就有了散列表查找。
数据结构模型
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。
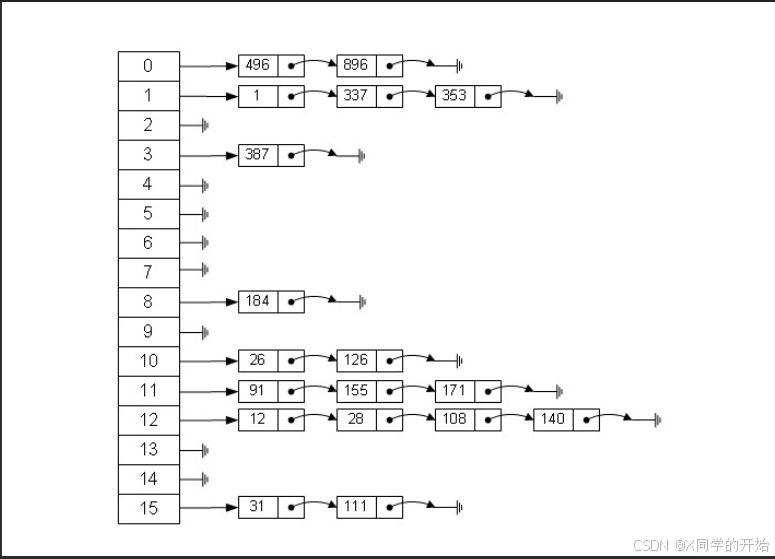
代码实现
- HashTable
java
package org.example.data.structure.hashtable;
import java.util.Objects;
/**
* @author xzy
* @since 2024/9/15 11:03
*/
public class HashTable {
private LinkedList[] linkedLists;
public HashTable() {
linkedLists = new LinkedList[8];
for (int i = 0; i < linkedLists.length; i++) {
linkedLists[i] = new LinkedList();
}
}
public HashTable(int size) {
if (size < 0) {
throw new RuntimeException("未知异常");
}
linkedLists = new LinkedList[size];
for (int i = 0; i < linkedLists.length; i++) {
linkedLists[i] = new LinkedList();
}
}
public void add(Person person) {
int i = hash(person.getId());
LinkedList linkedList = linkedLists[i];
PersonNode node = new PersonNode();
node.setData(person);
linkedList.add(node);
}
public void delete(int id) {
int i = hash(id);
LinkedList linkedList = linkedLists[i];
linkedList.delete(id);
}
public void update(Person person) {
int i = hash(person.getId());
LinkedList linkedList = linkedLists[i];
linkedList.update(person);
}
public Person getById(int id) {
int i = hash(id);
LinkedList linkedList = linkedLists[i];
return linkedList.getById(id);
}
public Person[] list() {
Person[] personArr = new Person[linkedLists.length * 10];
int i = 0;
for (LinkedList linkedList : linkedLists) {
Person[] list = linkedList.list();
if (Objects.nonNull(list)) {
for (Person person : list) {
if (Objects.nonNull(person)) {
personArr[i] = person;
i++;
}
}
}
}
return personArr;
}
private int hash(int id) {
// 计算落到哪个链表中
return id % linkedLists.length;
}
}- 链表实现
java
package org.example.data.structure.hashtable;
import java.util.Objects;
/**
* @author xzy
* @since 2024/9/15 10:04
*/
public class LinkedList {
private PersonNode head;
public void add(PersonNode node) {
if (Objects.isNull(head)) {
// 链表未初始化
head = node;
return;
}
// 获取最后一个节点
PersonNode tempNode = head;
while (Objects.nonNull(tempNode.getNext())) {
tempNode = tempNode.getNext();
}
tempNode.setNext(node);
}
public void delete(int id) {
if (Objects.isNull(head)) {
System.out.println("链表为空, 忽略删除操作");
return;
}
// 先判断是否只有一个节点
if (Objects.isNull(head.getNext())) {
if (head.getData().getId() == id) {
head = null;
}
} else {
PersonNode tempNode = head;
// 遍历节点
while (true) {
PersonNode next = tempNode.getNext();
if (Objects.isNull(next)) {
System.out.println("未找到对应的节点进行删除");
break;
} else {
if (next.getData().getId() == id) {
tempNode.setNext(next.getNext());
break;
} else {
tempNode = next;
}
}
}
}
}
public void update(Person person) {
if (Objects.isNull(head)) {
System.out.println("链表为空, 不处理");
return;
}
PersonNode tempNode = head;
while (true) {
if (Objects.isNull(tempNode)) {
System.out.println("未找对需要更新的数据, 不处理");
break;
}
if (tempNode.getData().getId() == person.getId()) {
Person data = tempNode.getData();
data.setName(person.getName());
tempNode.setData(data);
break;
} else {
tempNode = tempNode.getNext();
}
}
}
public Person getById(int id) {
PersonNode tempNode = head;
while (true) {
if (Objects.isNull(tempNode)) {
System.out.println("未找对需要更新的数据, 不处理");
return null;
}
if (tempNode.getData().getId() == id) {
return tempNode.getData();
} else {
tempNode = tempNode.getNext();
}
}
}
public Person[] list() {
if (Objects.isNull(head)) {
return new Person[0];
}
Person[] personArr = new Person[10];
int i = 0;
PersonNode tempNode = head;
while (true) {
if (Objects.nonNull(tempNode)) {
personArr[i] = tempNode.getData();
i++;
tempNode = tempNode.getNext();
} else {
break;
}
}
return personArr;
}
}后续优化
- 未解决哈希冲突(主要是因为hash()实现过于简单)
- 链表中未实现有序(可在插入时,在单链表中先排序再插入)