什么是 Redis?
Redis 是一种基于内存的数据库,所有的数据读写操作都在内存中完成,因此读写速度非常快。它被广泛应用于缓存、消息队列、分布式锁等场景。
Redis 提供了多种数据类型来支持不同的业务需求,如 String、Hash、List、Set、Zset、Bitmaps、HyperLogLog、GEO、Stream 等。Redis 对这些数据类型的操作都是原子的------因为Redis是单线程架构,一条命令的执行是由单个线程完成,不会出现并发竞争的问题。

除了基本的数据存储功能,Redis 还支持事务、持久化、Lua 脚本、多种集群方案(包括主从复制模式、哨兵模式和分片集群模式)、发布/订阅模式、内存驱逐机制以及过期删除机制等一些高级特性,进一步增强了其功能和应用场景的多样性。
Redis 和 Memcached 有什么区别?
很多人常建议用Redis做缓存,但是Memcached同样是基于内存的非关系型数据库,为什么Redis的使用场景更多呢?

要回答这个问题,我们需要搞清楚Redis和Memcached的区别。Redis与Memcached主要有以下区别:
1. 支持的数据类型
- Redis不仅仅支持简单的String键值对存储,还提供了Hash、List、Set、Zset等多种复杂的数据结构,可以满足更复杂的数据存储场景需求。
- Memcached主要是简单的键值对存储。
2. 持久化
- Redis支持数据持久化,可以将数据保存到磁盘,从而保证数据在Redis发生故障后能够恢复。
- Memcached通常不具备数据持久化功能,数据只存在于内存中。服务器重启后数据会丢失。
3. 内存管理
- Redis具有更加灵活的内存管理策略和机制,可以配置和优化内存使用方式,以适应不同的应用场景,这一点在后面会详细的介绍。
- Memcached在内存管理方面比较简单。
4. 性能特点:
- 在一些特定场景下,Memcached可能在简单的键值对操作中展现出极高的性能。
- Redis在综合性能、功能多样性方面具有优势。
5. 应用场景
- Memcached比较适合缓存比较简单的数据。
- Redis可以应用在更广泛的场景,比如缓存,消息队列,分布式锁等等。
可以看出,当只需快速缓存简单的键值对时,Memcached 可能是更好的选择;而在需要处理复杂数据结构且存在持久化需求的情况下,Redis 则更为合适。在实际应用中,应该根据具体的需求和场景来选择合适的缓存方案。
Redis 支持的数据类型
Redis 提供了丰富多样的数据类型,其中常见的五种类型包括:String、Hash、List、Set 和 Zset。注意这里说的数据类型指的是value的类型,因为key的类型永远只有String这一种类型。
在后续版本中,Redis 还新增了四种数据类型:BitMap(2.2 版本)、HyperLogLog(2.8 版本)、GEO(3.2 版本)以及 Stream(5.0 版本)。
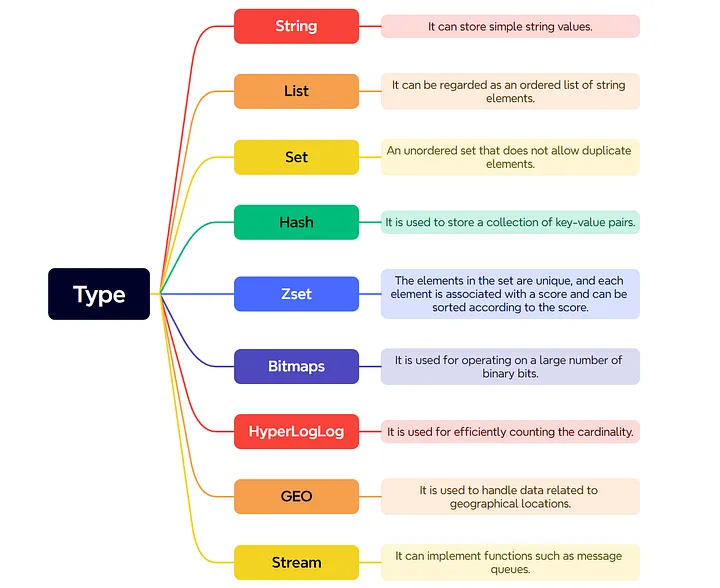
各种数据类型的应用场景
- String:一般用于计数或缓存简单的键值对数据,例如用户信息、配置参数等。
- Hash:用于存储对象信息,如一个用户的详细属性,常用于实现购物车等场景。
- List:适用于消息队列、排行榜等。
- Set:用于处理聚合计算(如并、交、差运算)的场景,比如点赞、共同关注、抽奖活动等。
- Zset:适合实现带权重的排行榜或按时间排序的事件。
- Bitmaps:用于处理二进制状态统计的场景,比如签到、判断用户登录状态、统计连续签到的用户总数等。
- HyperLogLog:适合海量数据基数统计的场景,例如对百万级网页的 UV(独立访问用户数)进行计数。
- GEO:用于基于位置的服务,如查找附近的商家、网约车等。
- Stream:用于实现高级消息队列。
关于各个数据类型的指令使用方式和应用场景,会在后续的文章中一一介绍
Redis 五种常见数据类型是如何实现的?
下面是一张 Redis 数据类型与底层数据结构的对应关系图,其中左边展示的是 Redis 3.0 版本的数据类型实现,现在看来已经有些过时;右边则是 Redis 7.0 版本的数据类型实现。
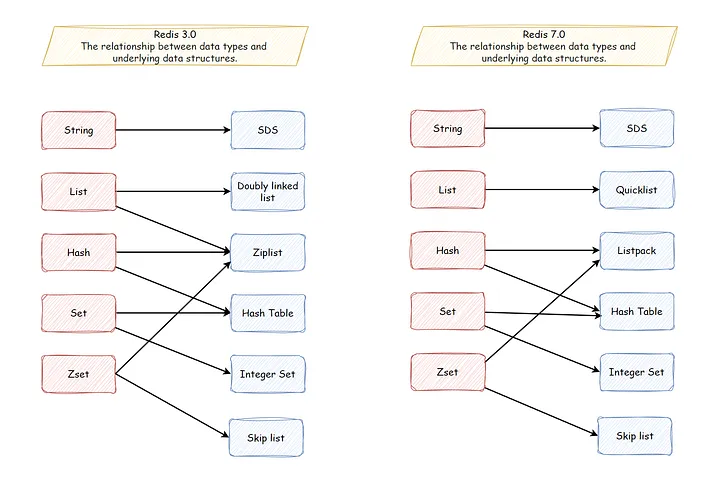
下面对这些底层数据结构做一个简单的介绍,让我们有一个大致的映像,后面会写一篇文章详细剖析这些数据结构。
1. String类型内部实现
在 Redis 中,String 类型的底层数据结构主要是 SDS(Simple Dynamic String)。
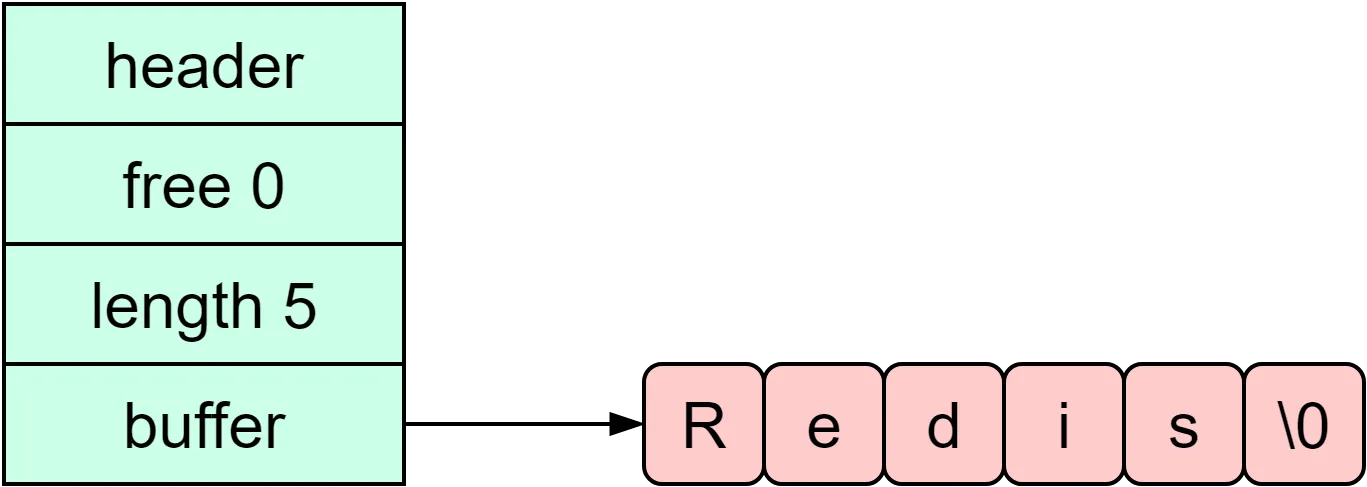
SDS 与我们熟知的 C 语言字符串有所不同。相比于 C语言 原生的字符串,Redis 选择 SDS 作为实现方式有其特定原因:
-
SDS 不仅可以保存文本数据,还可以保存二进制数据。这是因为 SDS 使用 len 属性来判断字符串的结束位置,而不是依靠空字符 ('\0') 标记结束。同时,SDS 的所有 API 都会将 buf\[\] 数组中的数据作为二进制来处理。因此,SDS 不仅可以存储文本,还能存储图片、音频、视频、压缩文件等二进制数据。
-
SDS获取字符串长度的时间复杂度为O(1)。由于C语言的字符串没有记录自身的长度,所以获取长度的复杂度为O(n);而SDS结构体中的len属性记录了字符串长度,所以复杂度为O(1)。
-
Redis 的 SDS API 是安全的,拼接字符串不会导致缓冲区溢出。因为 SDS 会在拼接字符串前检查空间是否足够,如果空间不足,会自动扩展,避免缓冲区溢出的问题。
2. List类型的内部实现
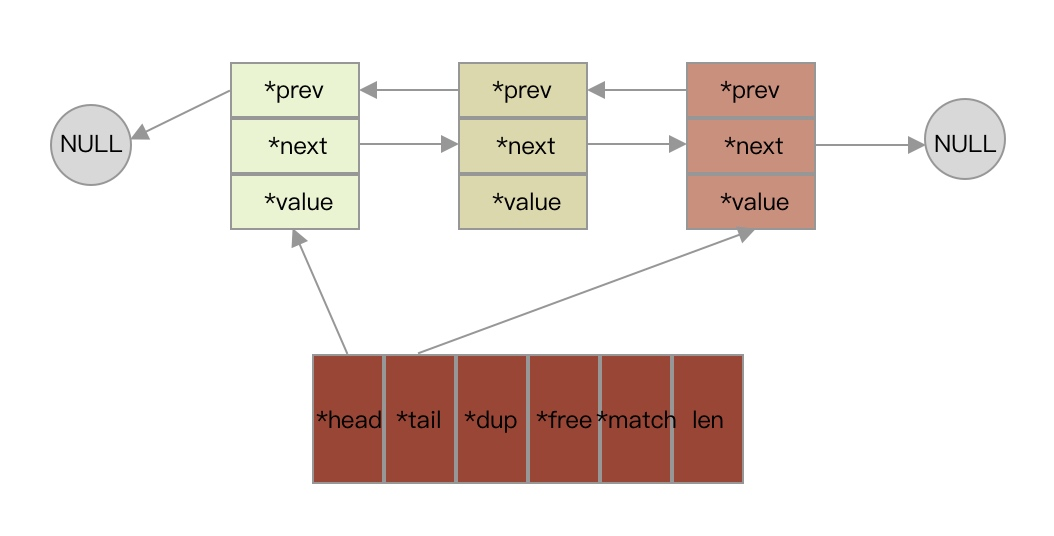
List 类型的底层数据结构通过双向链表或者 ziplist实现:
- 当列表中的元素数量小于 512 个 (默认值,可通过 list-max-ziplist-entries 配置),且每个元素的长度小于 64 字节 (默认值,可通过 list-max-ziplist-value 配置)时,Redis 会使用 ziplist 作为 List 类型的底层数据结构。
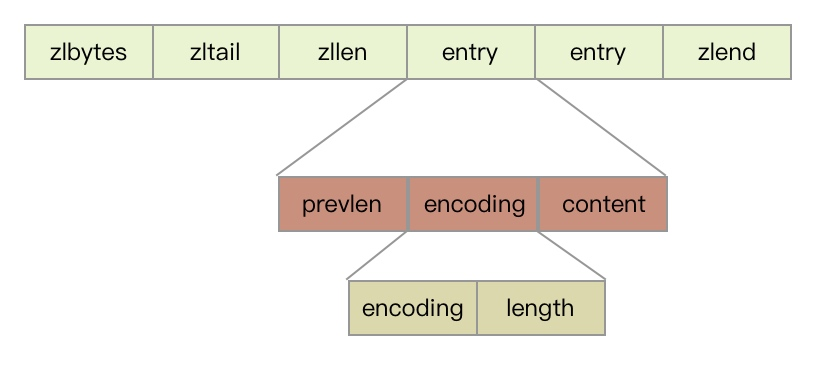
- 如果列表中的元素不满足这些条件,Redis 则会使用双向链表 作为 List 类型的底层数据结构。
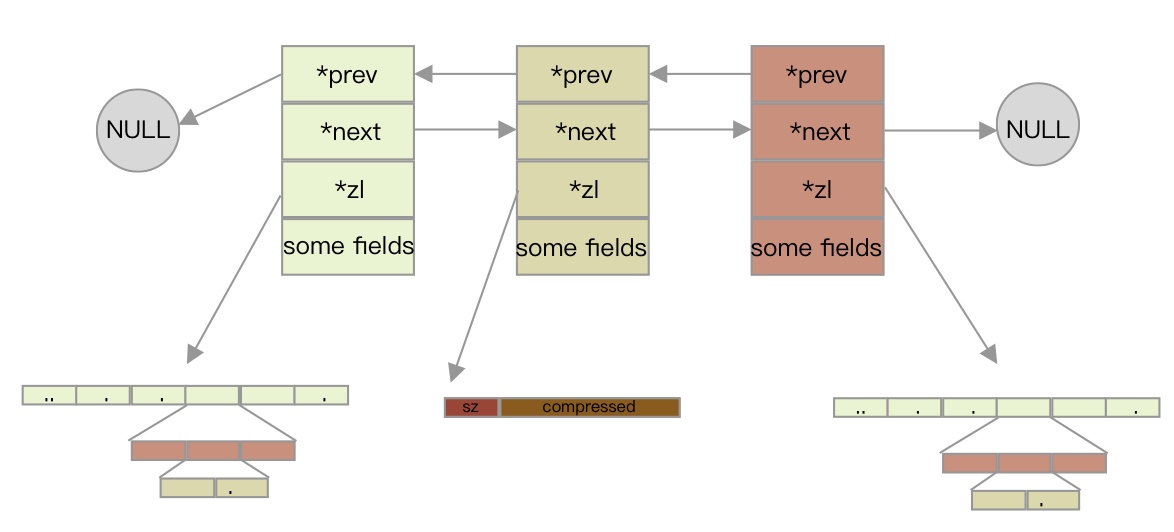
然而,从 Redis 3.2 版本开始,List 类型的底层数据结构改为仅由 quicklist 实现,取代了早期的双向链表和 ziplist。
3. Hash类型的内部实现
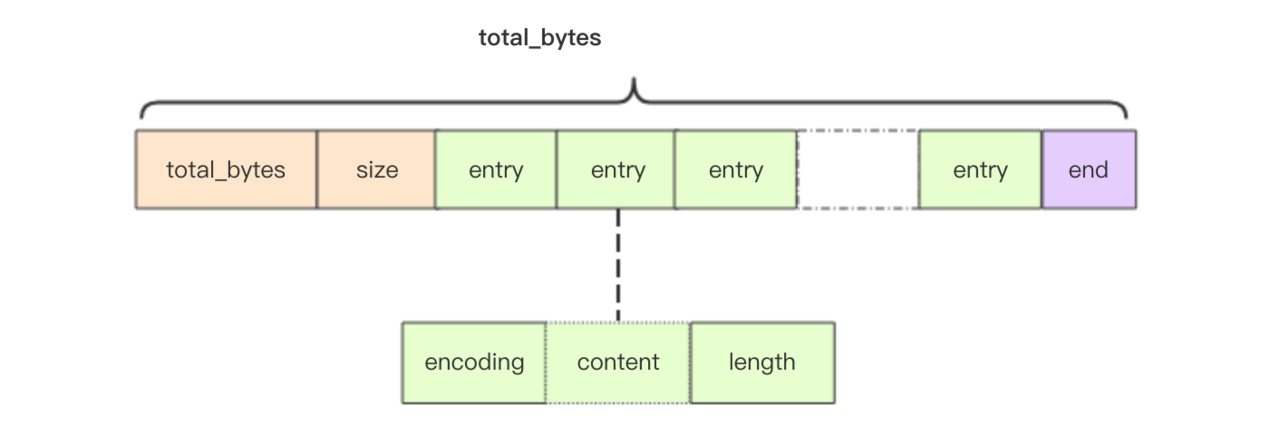
Hash 类型的底层数据结构通过ziplist 或者 hash table实现:
-
当 Hash 类型的元素数量少于 512 个(默认值,可通过 hash-max-ziplist-entries 配置),且所有元素的值小于 64 字节(默认值,可通过 hash-max-ziplist-value 配置)时,Redis 会使用 ziplist 作为 Hash 类型的底层数据结构。
-
如果 Hash 类型的元素不满足这些条件,Redis 则会使用hash table作为底层数据结构。
从 Redis 7.0 开始,ziplist 数据结构已被废弃,取而代之的是 listpack 数据结构。
4. Set 类型的内部实现
Set 类型的底层数据结构可以通过hash table或整数集合实现:
-
当集合中的所有元素都是整数且元素数量少于 512 个(默认值,可通过 set-maxintset-entries 配置)时,Redis 会使用整数集合作为 Set 类型的底层数据结构。

-
如果集合中的元素不满足这些条件,Redis 则会使用哈希表作为 Set 类型的底层数据结构。
5. ZSet类型内部实现
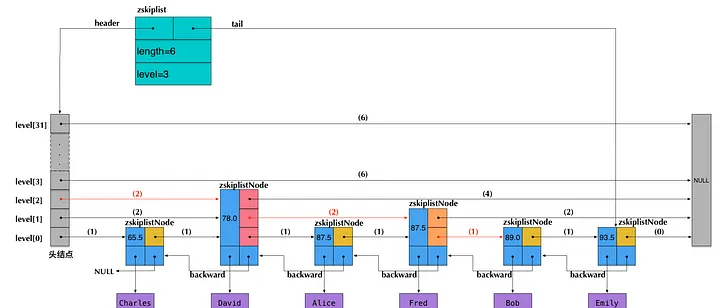
ZSet 类型的底层数据结构可以通过 ziplist 或 skiplist 实现:
- 当有序集合中的元素数量少于 128 个且每个元素的值小于 64 字节时,Redis 会使用 ziplist 作为 ZSet 类型的底层数据结构。
- 如果有序集合的元素不满足这些条件,Redis 则会使用 skiplist 作为 ZSet 类型的底层数据结构。
从 Redis 7.0 开始,ziplist 数据结构已被废弃,取而代之的是 listpack 数据结构。