2.1 数据介绍
有某公司的销售数据表 sales.csv 如下:
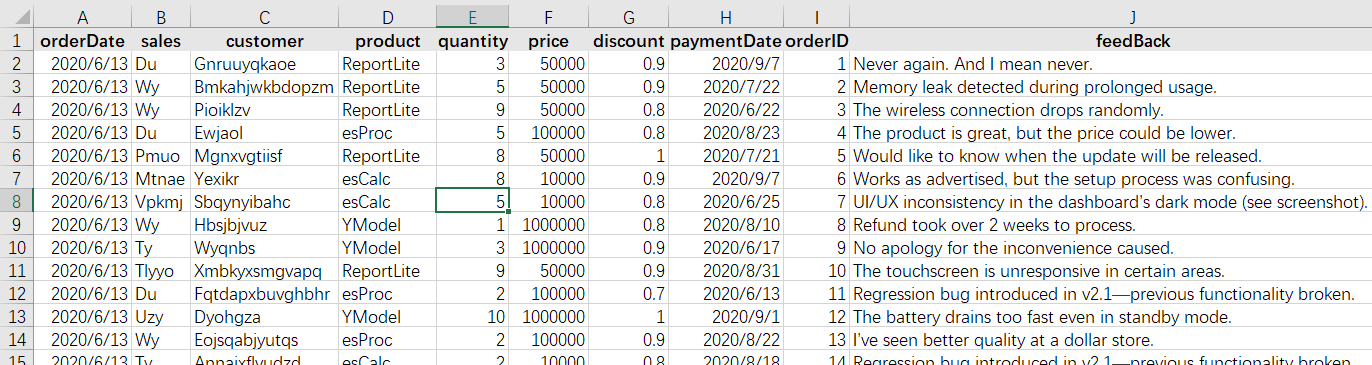
第一行 是标题 ,解释每一列存了什么东西。第二行开始每一行是一条数据,对应一个订单。
这种数据有个专业的术语,叫结构化数据。这是现代数据处理中最常见的数据类型。
整个表格的数据统称为一个数据表 ,其中的每一行(除了标题)称为一条记录 ,列称为字段 ,标题中的字符串称为字段名 。上面这个表中能看见的部分有 12 条记录,对应着这个 Excel 的第 2 到第 13 行;有 8 个字段,字段名分别是 orderDate, sales, customer, product, quantity, price, discount, paymentDate。字段名互不相同,可以唯一地标识某个列。这些字段(包括名称和次序),称为数据表的数据结构 ,简称结构。
结构化数据也就是有数据结构的数据。
表格中 A2:H13 部分就是数据表里的数据了。我们会说某条记录的某个字段的取值是什么。比如这里第 2 条记录的 sales 字段取值为 Hef,第 8 条记录的 quantity 字段取值为 8。数据表中每条记录的每个字段都会有一个取值。
注意,数据表中只有字段有名称,记录没有名称。我们后面会讲用什么办法来标识和区分记录。
可以有各种各样的数据表,不同数据表的数据结构当然可以不同。一个数据表一定要有一套数据结构,而且也只能有一套。有时我们也会说到记录的结构,意思就是指记录所在的数据表的结构。
因为结构化数据经常会以这种行列式表格的形式呈现,我们也会直观地把记录和字段称为行 和列,这是数据库界的通行术语,并不是我们发明的通俗说法。甚至,有时候数据表呈现出来时已经没有明显的行和列了(马上要讲到这样的例子),但人们仍然会用行和列这些术语来表示记录和字段。
本文档用到的 sales.csv 文件中列名的含义如下:
| 列名 | 含义 |
|---|---|
| orderID | 订单 ID,取值为自然数列,和记录序号一致 |
| orderDate | 下单日期 |
| sales | 销售 |
| customer | 客户 |
| product | 产品 |
| quantity | 订单数量 |
| price | 订单价格 |
| discount | 订单折扣 |
| paymentDate | 付款日期 |
| feedBack | 客户反馈 |
2.2 选出去年的所有销售记录
第一步:读取 sales.csv 文件中的数据
| A | |
|---|---|
| 1 | =file("sales.csv").import@tc() |
A1 函数file("sales.csv")表示从主目录中找到 sales.csv 这个文件,并产生文件对象,这里参数是个字符串,要加双引号。import@tc()表示读入文件对象 file("sales.csv") 中的数据,这里@t是函数 import 的选项,表示文件的第一行是标题行,如果没有这个选项,会把第一行当成数据读入。@c表示文件中数据的列间分隔符是英文逗号,如果没有这个选项,会默认当成 tab 分隔符。当两个选项 @t 和 @c 同时写时,可以省略一个 @, 写成@tc。
在界面中可以看到 A1 的值:
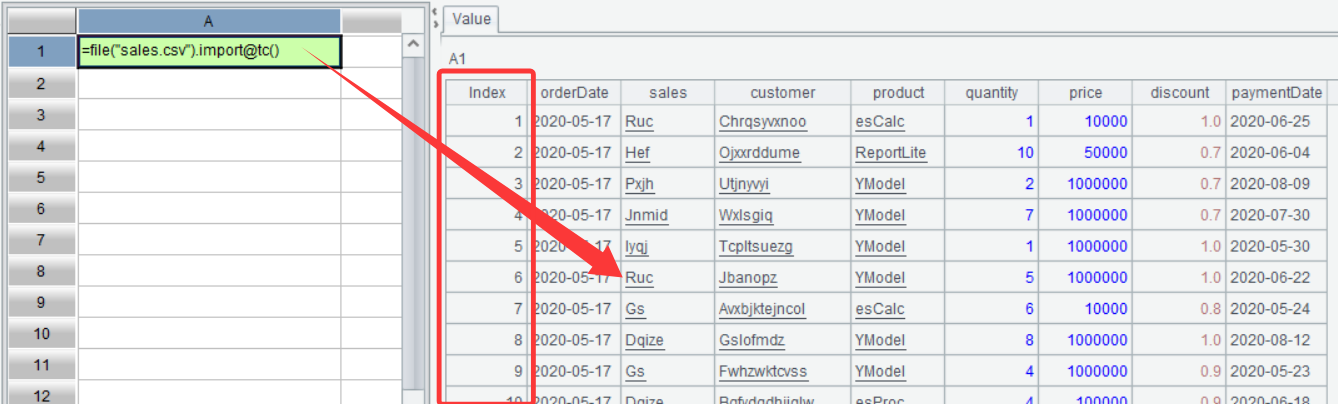
从图中可以看出 A1 的值是一个二维表。前面介绍过,sales.csv 文件中存储的是结构化数据,SPL 中用于装载结构化数据的对象称为序表 ,从名称上可以理解为有次序的二维表。上图中 A1 的值就是一个序表,从图上看,序表比原始的结构化数据多了一个 Index,这就是序表的记录次序,也称为记录序号,可以通过序号来访问序表中的某一条记录,比如 =A1(3),将返回 A1 中的第三条记录:

第二步:从 A1 中选出 2024 年下单的数据:
| A | |
|---|---|
| 1 | =file("sales.csv").import@tc() |
| 2 | =A1.select(year(orderDate)==2024) |
A2 select 函数表示过滤,这里的过滤条件year(orderDate)==2024表示选出 orderDate 的年份等于 2024 的数据。在 SPL 中相等比较用==,而=表示赋值。year函数表示获得日期参数的年份。
界面上可以再看一下 A2 的值:
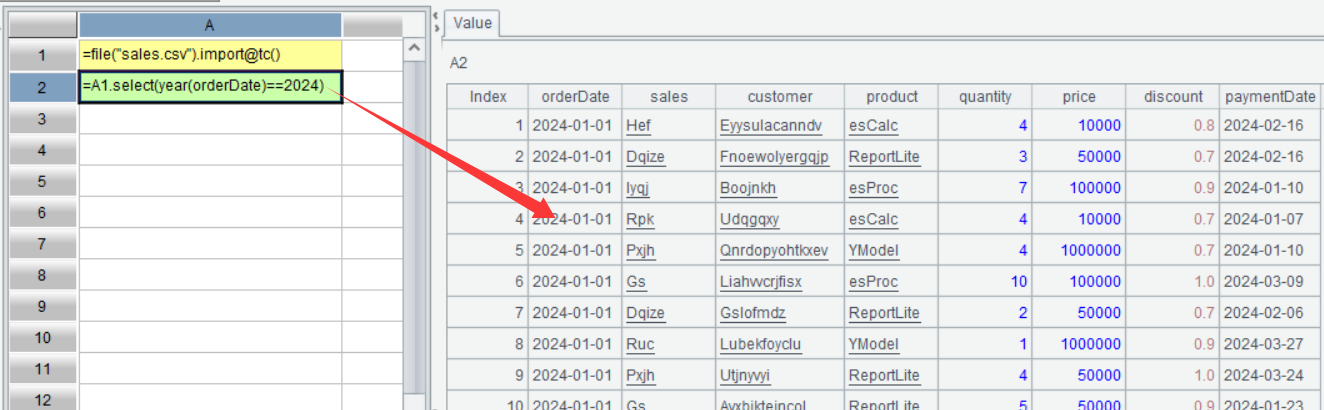
从界面上看,A2 是 2024 年的销售记录,表面上看和 A1 的序表似乎长得差不多,但它不是序表,它只是从 A1 序表中取出的部分记录组成的一个有序集合,在 SPL 中有个专门的名称叫排列。
2.3 计算去年的总销售额、单笔最大订单额、订单个数
第一步:读取 sales.csv 文件中的数据
| A | |
|---|---|
| 1 | =file("sales.csv").import@tc(orderDate,quantity,price,discount) |
A1 由于本例中只用到了orderDate,quantity,price,discount这几个字段,所以可以在 import 函数参数中指定这几个字段,这样读数时只读这几个字段,可以提高读数效率,减少内存占用。
第二步:过滤出 2024 年的数据,并算出订单金额,以计算列的形式添加到原排列中
| A | |
|---|---|
| 1 | =file("sales.csv").import@tc(orderDate,quantity,price,discount) |
| 2 | =A1.select(year(orderDate)==2024).derive(quantity*price*discount:amount) |
A2 derive 函数表示添加计算列,其中quantity*price*discount是计算表达式,amount是新产生的计算列的列名,表达式和列名之间用冒号分隔。特别强调的是表达式在前面,列名在后面。
第三步:聚合运算
| A | |
|---|---|
| 1 | =file("sales.csv").import@tc(orderDate,quantity,price,discount) |
| 2 | =A1.select(year(orderDate)==2024).derive(quantitypricediscount:amount) |
| 3 | =A2.sum(amount) |
| 4 | =A2.max(amount) |
| 5 | =A2.count() |
A3 对 A2 中的 amount 字段求和。
A4 对 A2 中的 amount 字段求最大值。
A5 对 A2 计数,算出 A2 的记录数。
2.4 选出金额最大的三个订单
| A | |
|---|---|
| 1 | =file("sales.csv").import@tc() |
| 2 | =A1.select(year(orderDate)==2024).derive(quantitypricediscount:amount) |
| 3 | =A2.sort(-amount) |
| 4 | =A3.to(3) |
A3 sort 函数是排序,缺省是从小到大排,想从大到小排,相当于其相反数从小到大排,所以这里加了个负号,写成-amount。
A4 A3.to(3)表示选出 A3 中的前三条记录。熟练之后可以把 A3 和 A4 写到一起:A2.sort(-amount).to(3)。
A4 的结果为:

可以看出,这种算法虽然简单,但是没有解决排名并列的问题,对于可能存在并列的数据,SPL 还有个 top 函数可以处理:
| A | |
|---|---|
| 1 | =file("sales.csv").import@tc() |
| 2 | =A1.select(year(orderDate)==2024).derive(quantitypricediscount:amount) |
| 3 | =A2.top@r(3;-amount) |
A3 A2.top@r(3;-amount)表示将A2排序后取前 3 条记录。缺省排序规则和sort函数一致,但是top函数有个@r选项可以解决并列的情况。特别需要强调的是,3和-amount之间是分号分隔,这时候返回的是排名前三的记录。如果写成逗号分隔,则返回排名前三的amount字段值。和 Excel 及其它程序语言不同,SPL 的参数分隔符不只是逗号,还可能有分号和冒号(在前面 derive 函数中就出现过冒号,用来分隔计算式和字段名)。
A3 的结果为:
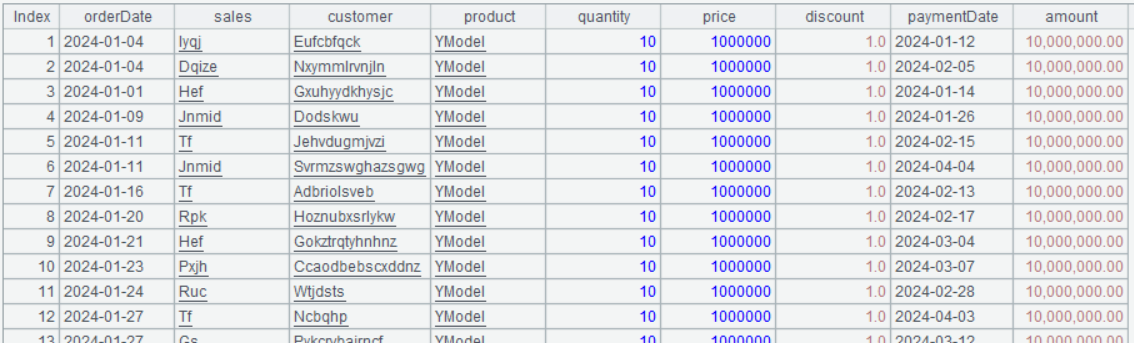
top 函数解决了排名并列的问题。
2.5 第一笔付款的订单、最后一笔付款的订单
| A | |
|---|---|
| 1 | =file("sales.csv").import@tc() |
| 2 | =A1.select(year(orderDate)==2024) |
| 3 | =A2.minp(paymentDate) |
| 4 | =A2.maxp(paymentDate) |
A3 A2.minp(ParmentDate)表示从排列 A2 中选出paymentDate的值最小的记录,这里用于选出第一笔付款的订单,它有点相当于 top(1,...)。由于本例中日期数据只精确到日,同一天可能存在多单付款,如果要把同一天付款的所有订单都选出,可以给 minp 函数加上@a选项,如:A2.minp@a(paymentDate)。
A4 选出最后一笔付款的订单,maxp 函数规则和 minp 一致,这里不再赘述。
2.6 统计 2025 年 5 月 1 日以后下单的客户数和付款的客户数(去重)
| A | B | |
|---|---|---|
| 1 | =file("sales.csv").import@tc() | 2025-05-01 |
| 2 | =A1.select(orderDate>B1) | |
| 3 | =A2.icount(customer) |
|
| 4 | =A2.select(paymentDate).icount(customer) |
A3 A2.icount(customer)表示对A2逐行获得customer的值,并对结果进行去重计数。
A4 A2.select(paymentDate)表示选出paymentDate不为空的记录,即已付款记录