1 Django中集成celery
# Django --->python 的web框架
-web项目--》用浏览器访问
# celery--->分布式异步任务框架
-定时任务
-延迟任务
-异步任务
1.1 安装模块
#官方文档:https://docs.celeryq.dev/en/stable/django/first-steps-with-django.html
pip install Django==3.2.22
pip install celery
pip install redis # celery 的中间件借助于redis--》redis模块
pip install eventlet # 在windows环境下需要安装eventlet包
# 创建django项目:名字叫 django_celery_crawl
# 保证django能运行
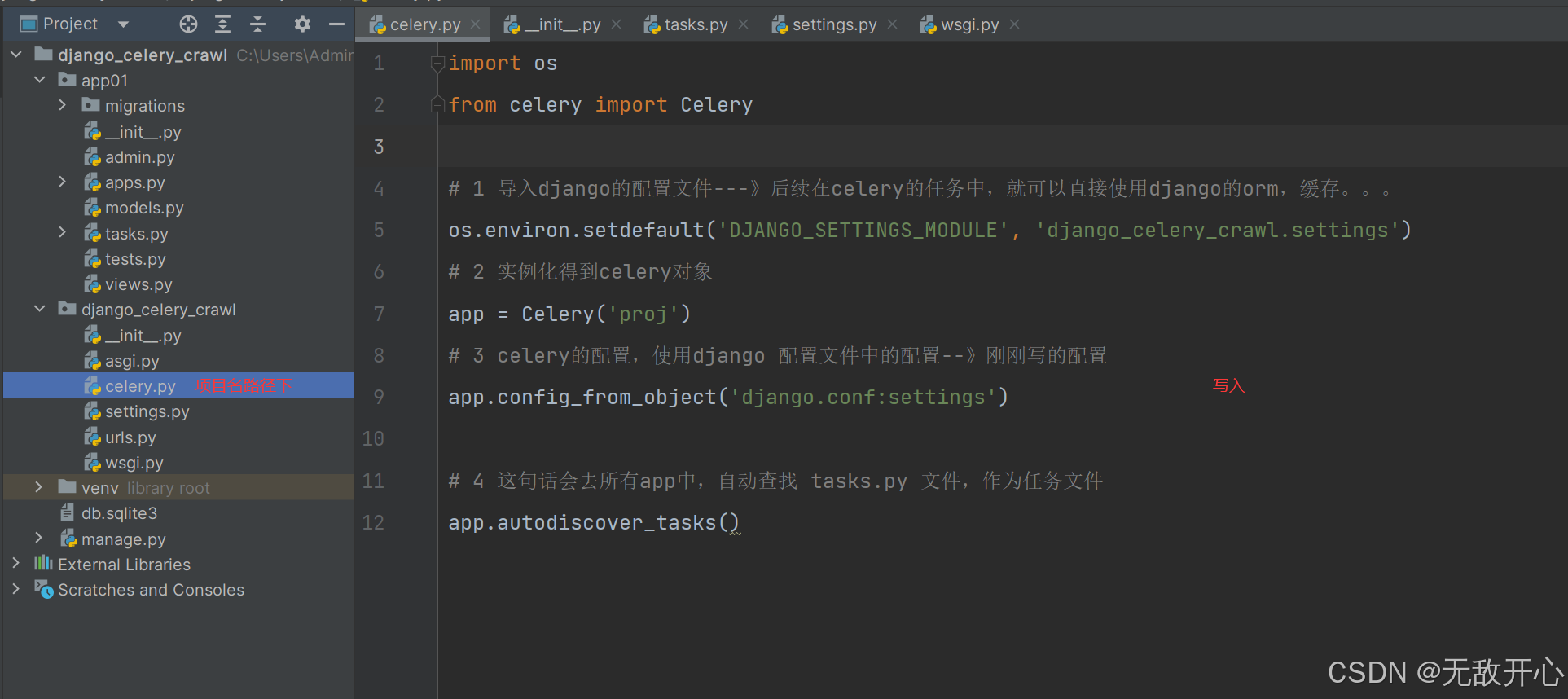
import os
from celery import Celery
# 1 导入django的配置文件---》后续在celery的任务中,就可以直接使用django的orm,缓存。。。
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'django_celery_crawl.settings')
# 2 实例化得到celery对象
app = Celery('proj')
# 3 celery的配置,使用django 配置文件中的配置--》刚刚写的配置
app.config_from_object('django.conf:settings')
# 4 这句话会去所有app中,自动查找 tasks.py 文件,作为任务文件
app.autodiscover_tasks()
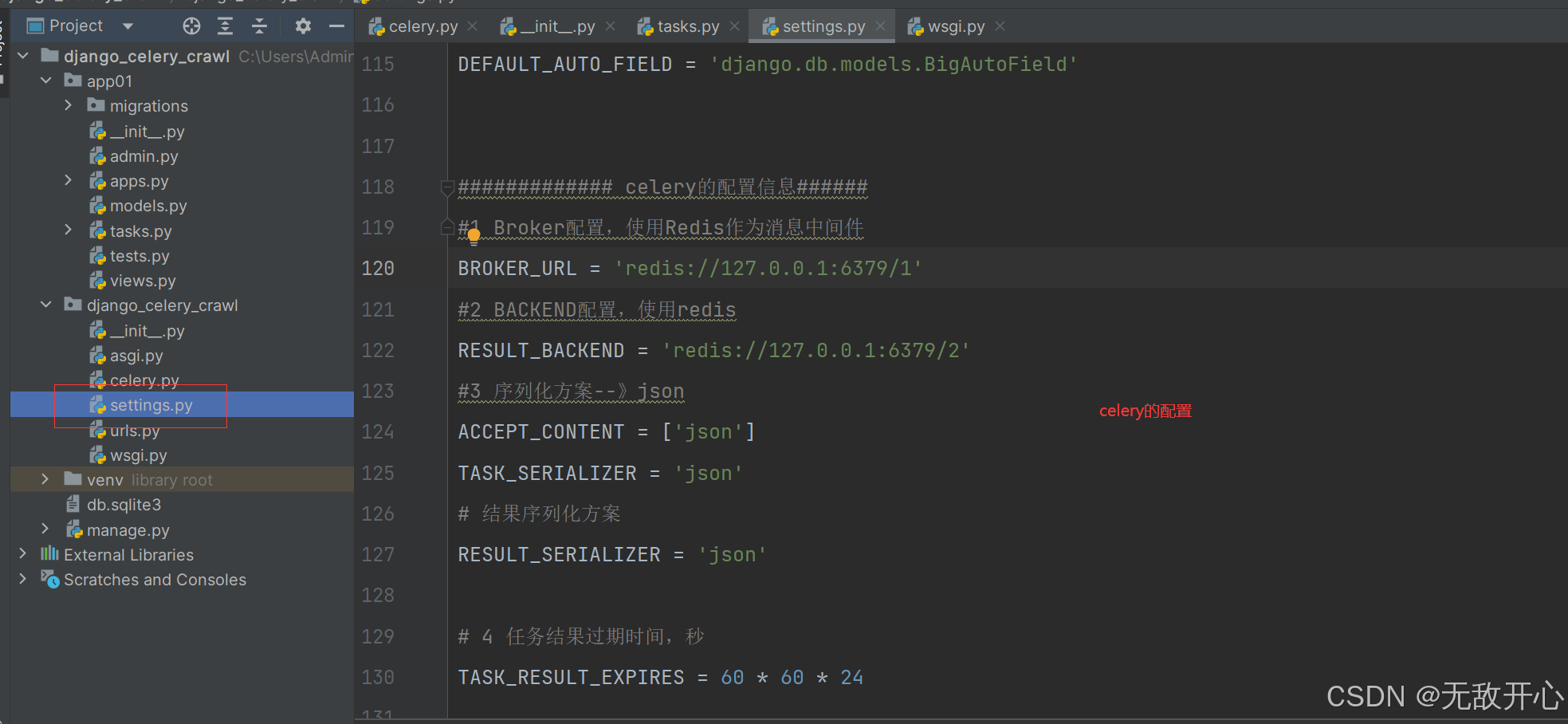
############# celery的配置信息######
#1 Broker配置,使用Redis作为消息中间件
BROKER_URL = 'redis://127.0.0.1:6379/1'
#2 BACKEND配置,使用redis
RESULT_BACKEND = 'redis://127.0.0.1:6379/2'
#3 序列化方案--》json
ACCEPT_CONTENT = ['json']
TASK_SERIALIZER = 'json'
# 结果序列化方案
RESULT_SERIALIZER = 'json'
# 4 任务结果过期时间,秒
TASK_RESULT_EXPIRES = 60 * 60 * 24
#5 时区配置
TIMEZONE = 'Asia/Shanghai'
# 注册任务
from celery import shared_task
# 以后使用shared_task 替换掉 app.task
# 任务函数
@shared_task
def add(a, b):
return a + b
1.5 在项目目录下的 init .py中加入
from .celery import app as celery_app
__all__ = ('celery_app',)
1.6 启动celery的worker-写一个提交异步任务的视图函数
1.6.1 启动worker
# 1 启动worker
celery -A django_celery_crawl worker -l debug -P eventlet
1.6.2 写一个视图函数测试
############### 总路由中 urls.py###############
from django.contrib import admin
from django.urls import path,include
urlpatterns = [
path('admin/', admin.site.urls),
path('app01/', include('app01.urls')), # http://127.0.0.1:8000/app01/send/ 异步发邮件
]
###############分路由中 urls.py###############
from django.contrib import admin
from django.urls import path
from .views import send_mail_view
urlpatterns = [
path('send/', send_mail_view),
]
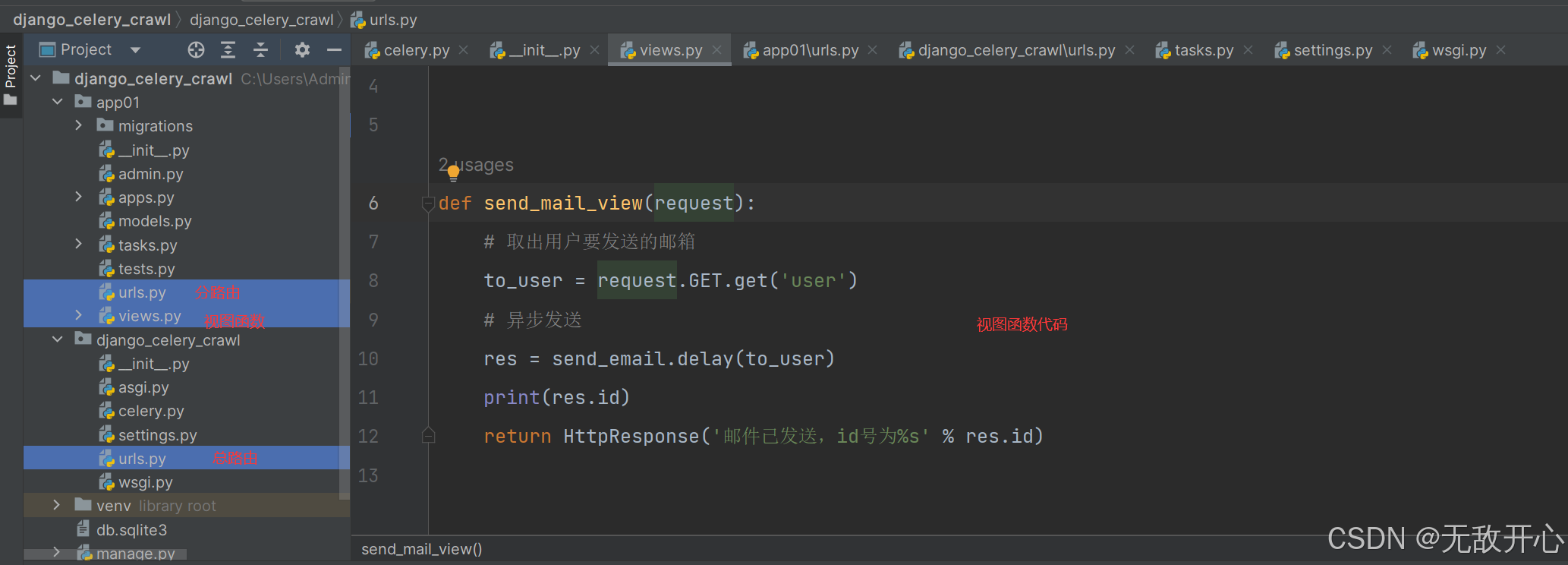
###############视图函数中 views.py###############
from django.shortcuts import render, HttpResponse
from .tasks import send_email
def send_mail_view(request):
# 取出用户要发送的邮箱
to_user = request.GET.get('user')
# 异步发送
res = send_email.delay(to_user)
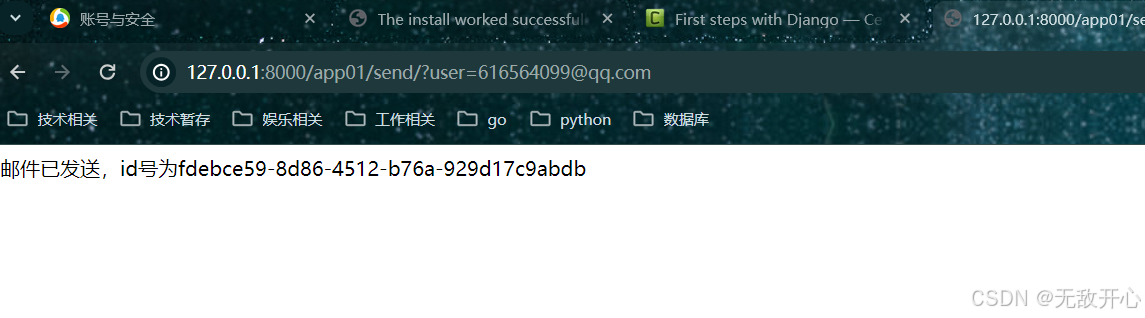
print(res.id)
return HttpResponse('邮件已发送,id号为%s' % res.id)
1.6.3 在浏览器输入:
http://127.0.0.1:8000/app01/send/?user=616564099@qq.com
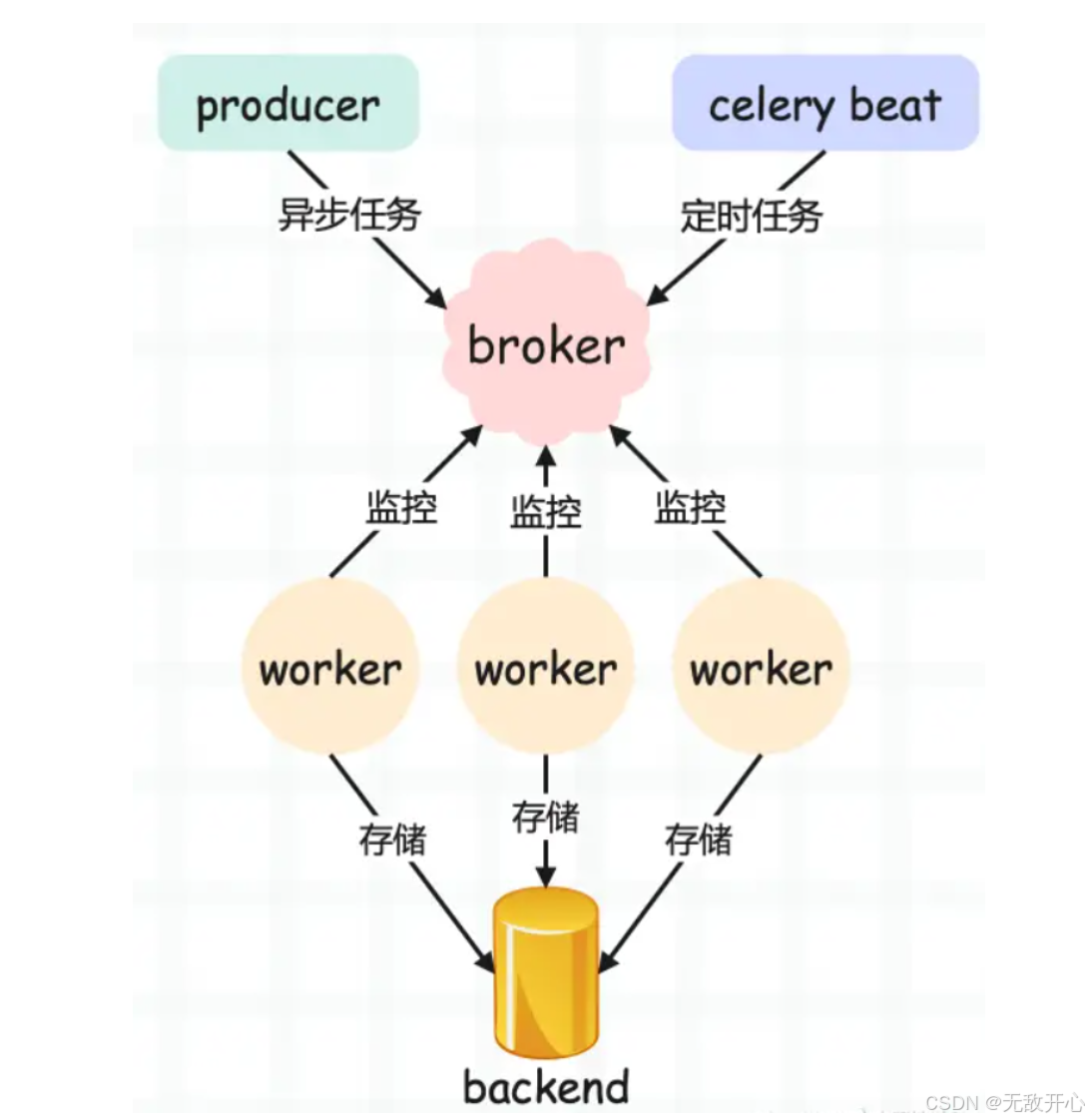
1.7 celery 架构图
2 实现定时任务
# celery集成到django后,以后定时任务的编写,要写到django的配置文件中
2.1 django的配置文件配置
from datetime import timedelta
CELERYBEAT_SCHEDULE = {
'every_5_second': {
'task': 'app01.tasks.add',
'schedule': timedelta(seconds=5),
'args': (33, 44),
}
}
2.2 重启worker---启动beat
# 启动worker
celery -A django_celery_crawl worker -l debug -P eventlet
# 启动beat
celery -A django_celery_crawl beat -l debug
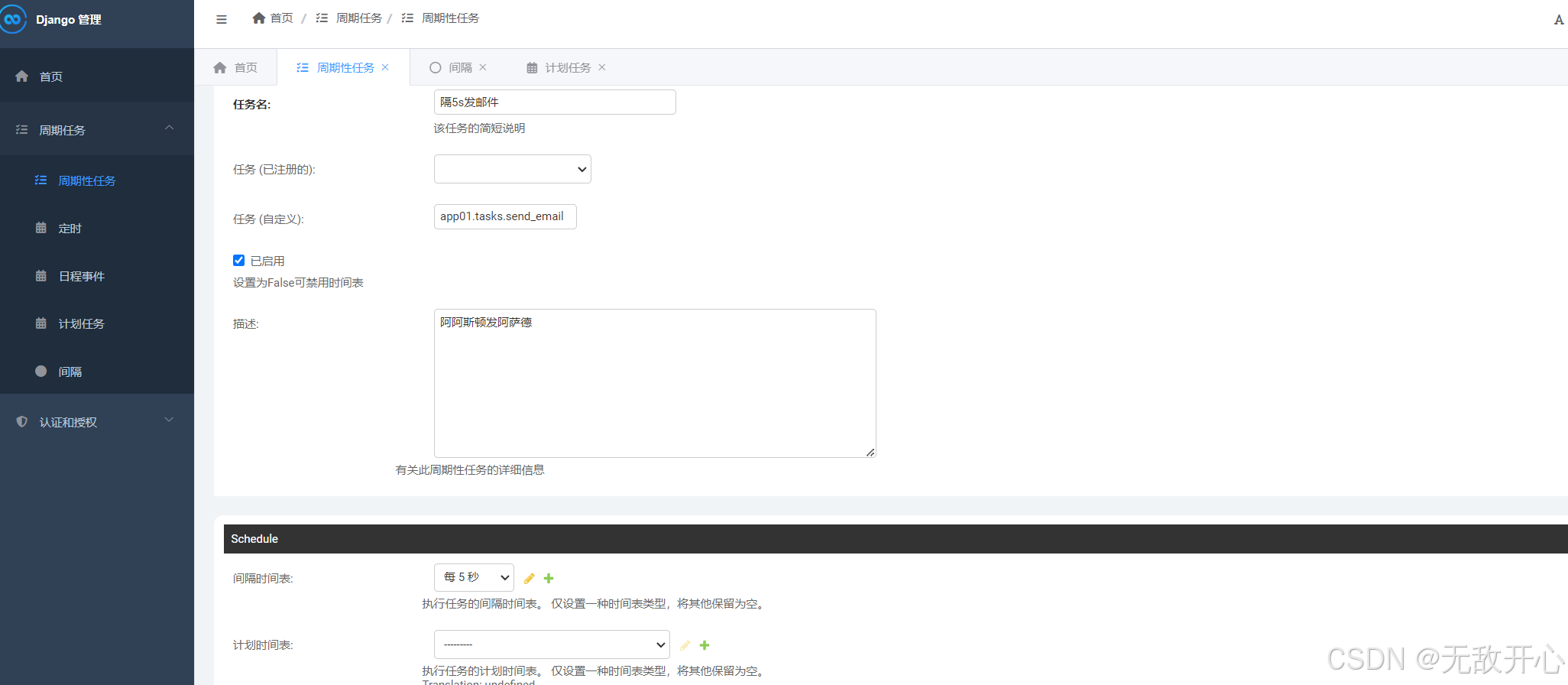
3 通过Admin 后台管理添加定时任务
# 存在问题:
如果要再新加一个定时任务(爬美女图片)
我们只能修改代码 :settings.py-->加入代码
重启worker,重启beat--》才能行
有些麻烦
# 通过点点点,就能自动添加定时任务
-Admin 后台管理添加定时任务
3.1 引入--安装djiango-celery-beat
pip install django-celery-beat
3.2 在app中注册djiango-celery-beat
INSTALLED_APPS = [
...
'app01',
'django_celery_beat' # 注册刚刚第三方模块
]
3.3 配置django的时区
LANGUAGE_CODE = 'zh-hans'
TIME_ZONE = 'Asia/Shanghai'
USE_I18N = True
USE_L10N = True
USE_TZ = False
3.4 在setting中配置调度器
CELERYBEAT_SCHEDULER = 'django_celery_beat.schedulers.DatabaseScheduler'
# 只要配了这个,原来celery中的定时任务统一不能用了,需要我们手动配置了
3.5 数据迁移
#1 django 使用mysql数据库
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'django_celery_crawl', # 去mysql中创建数据库
'HOST':'127.0.0.1',
'PORT':3306,
'USER':'root',
'PASSWORD':'123' # 自己写自己的密码
}
}
# 2 安装mysqlclient
pip install mysqlclient
#3 去mysql 中创建 django_celery_crawl 库
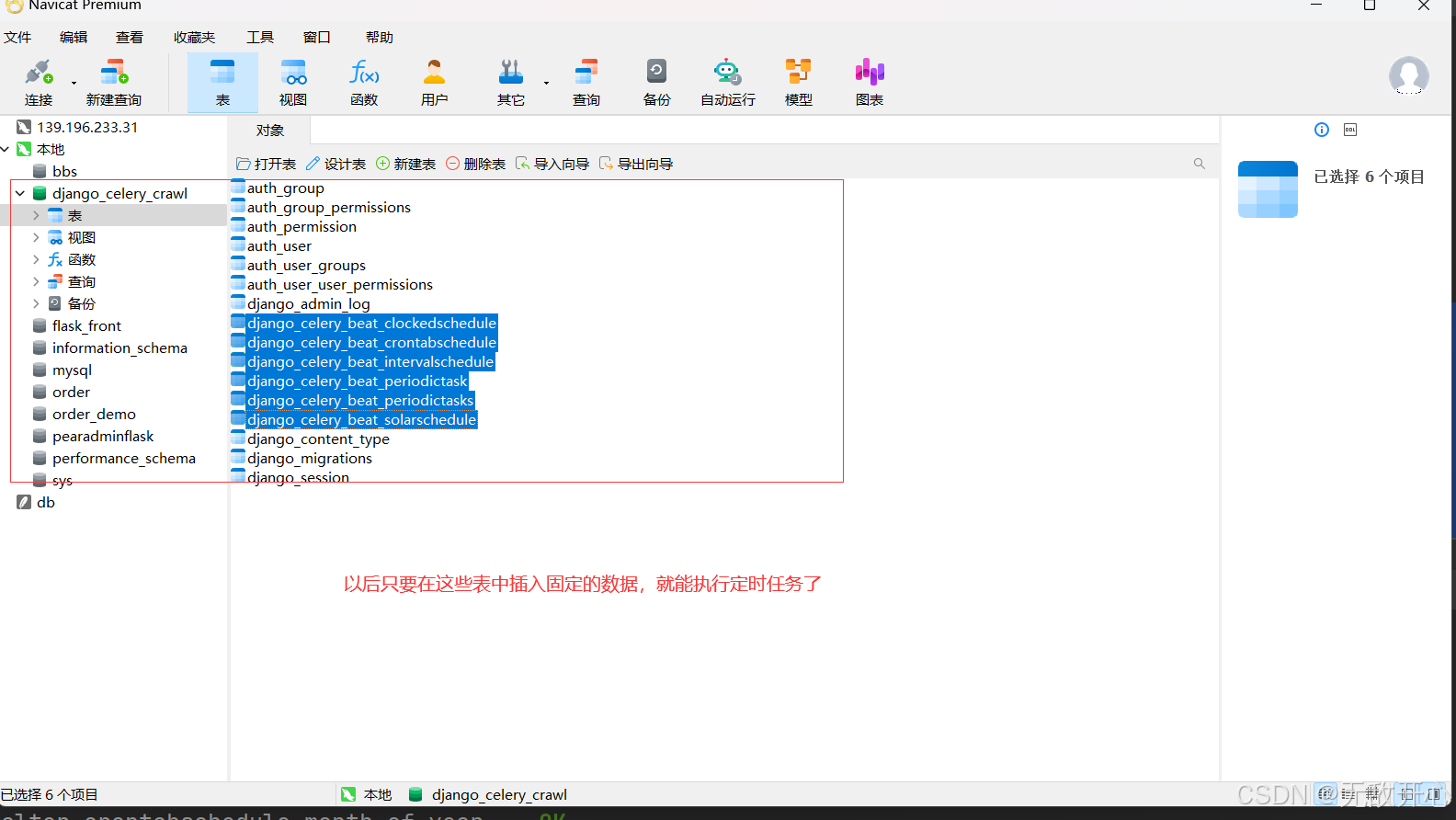
#4 django-celery-beat 这个app会产生表--》以后只要咱么在表里添加记录,就能制定定时任务
python manage.py makemigrations
python manage.py migrate
3.6 使用admin后台管理插入数据
# 咱么如果想向mysql数据表中,插入数据
-可以使用navicat插入
-django提供了一个后台管理--》登录到后台管理,可以图形化界面录入数据
-但是需要个账号登录:命令创建账号
python manage.py createsuperuser
-我创建的是:
账号: admin
密码 : 123456
3.7 美化admin
# 1 simpleui 美化admin
# 2 开源地址
https://gitee.com/tompeppa/simpleui
# 3 文档地址
https://newpanjing.github.io/simpleui_docs/config.html
# 4 安装
pip3 install django-simpleui
# 5 app中注册
INSTALLED_APPS = [
'simpleui',
...
]
3.8 手动添加任务
# 1 启动worker,beat
# 启动worker
celery -A django_celery_crawl worker -l debug -P eventlet
# 启动beat
celery -A django_celery_crawl beat -l debug
# 2 在admin中手动添加
4 通过Admin查看任务运行情况
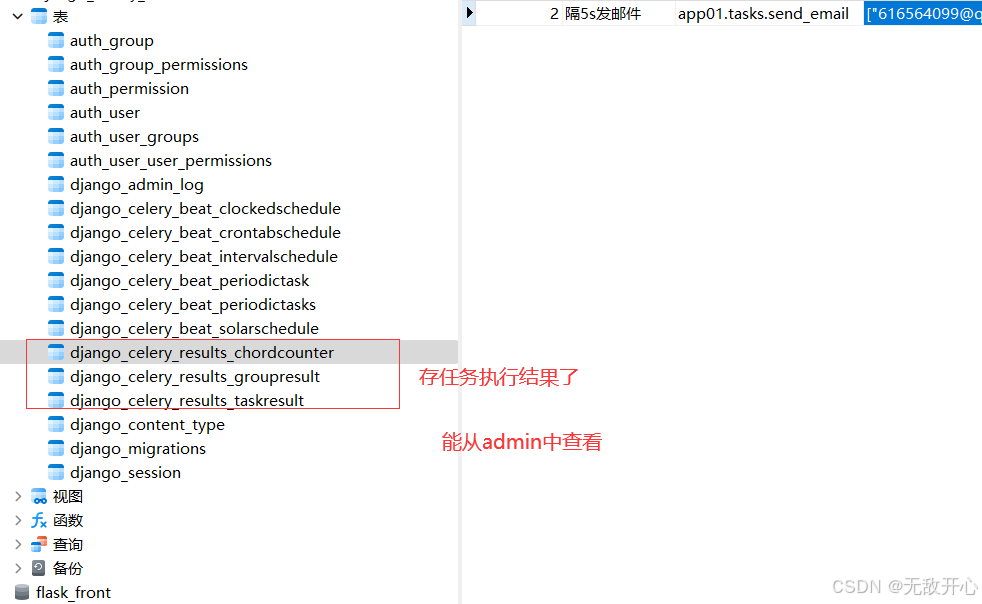
# 在控制台监控任务执行情况或者去redis中查看,还不是很方便,最好是能够通过web界面看到任务的执行情况,如有多少任务在执行,有多少任务执行失败了等。
# 这个Celery也是可以做到了,就是将任务执行结果写到数据库中,通过web界面显示出来。
这里要用到django-celery-results插件。
通过插件可以使用Django的orm作为结果存储,这样的好处在于我们可以直接通过django的数据查看到任务状态,同时为可以制定更多的操作
4.1 安装 django-celery-results
pip install django-celery-results
4.2 app中注册
INSTALLED_APPS = (
...,
'django_celery_results',
)
4.3 修改配置文件
# 让之前backend----》结果存储放在redis中----》改到放到数据中---》因为在数据库中的咱们可以通过admin查看
#RESULT_BACKEND = 'redis://127.0.0.1:6379/1'
# 使用使用django orm 作为结果存储
CELERY_RESULT_BACKEND = 'django-db' #使用django orm 作为结果存储
4.4 迁移数据库
# 执行迁移命令
python manage.py makemigrations
python manage.py migrate
4.5 在admin中查看即可
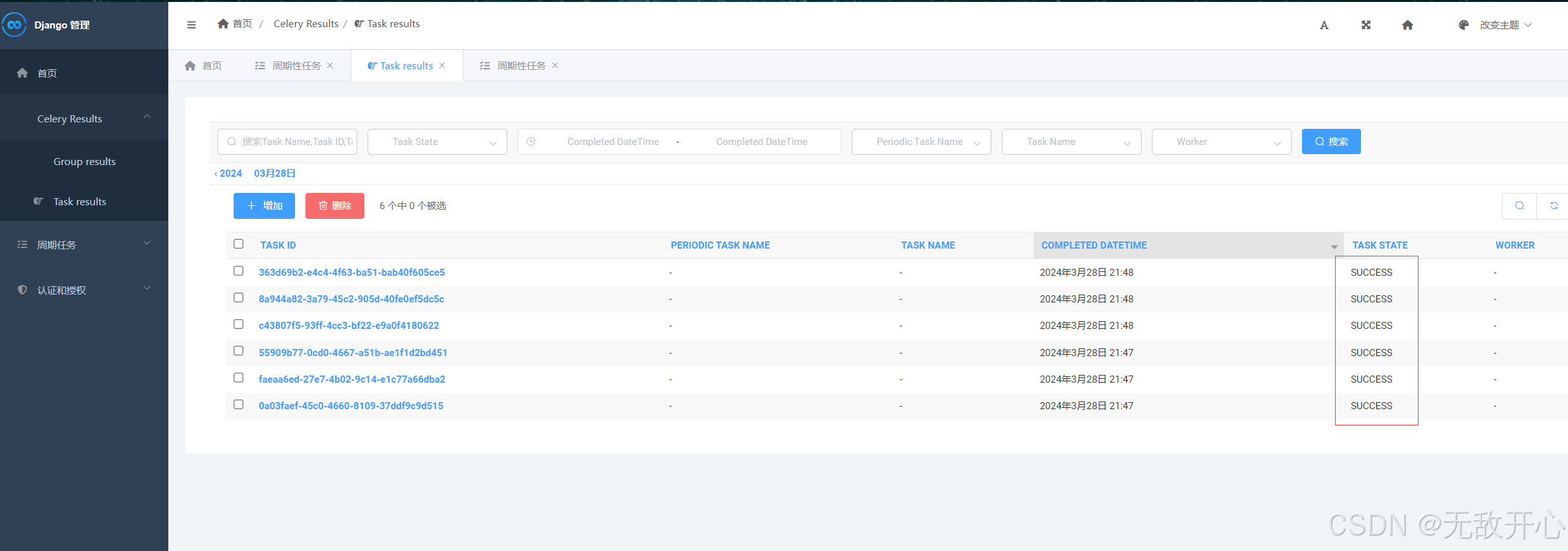
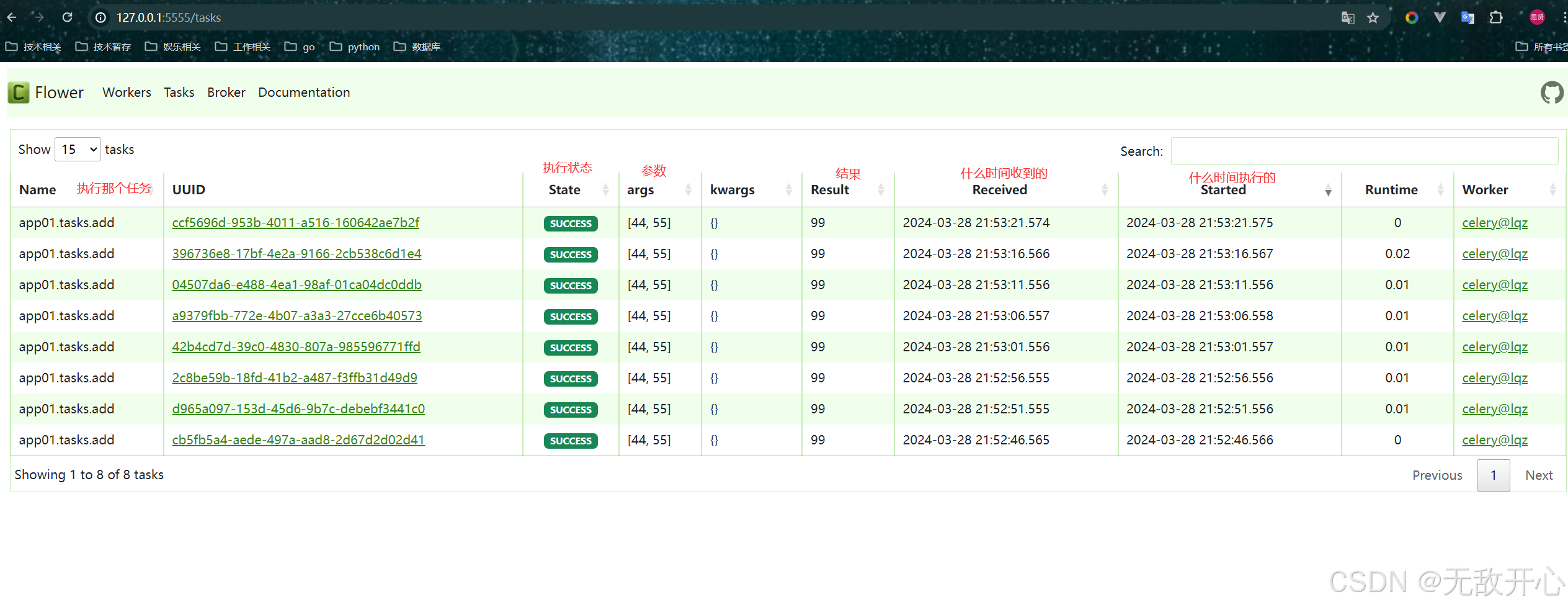
5 通过Flower监控celery运行情况
如果不想通django的管理界面监控任务的执行,还可以通过Flower插件来进行任务的监控。Flower的界面更加丰富,可以监控的信息更全
Flower 是一个用于监控和管理 Celery 集群的开源 Web 应用程序。它提供有关 Celery workers 和tasks状态的实时信息
# Flower可以:
1 实时监控celery的Events
-查看任务进度和历史记录
-查看任务详细信息(参数、开始时间、运行时间等)
2 远程操作
-查看workers 状态和统计数据
-关闭并重新启动workers 实例
-控制工作池大小和自动缩放设置
-查看和修改工作实例消耗的队列
-查看当前正在运行的任务
-查看计划任务(预计到达时间/倒计时)
-查看保留和撤销的任务
-应用时间和速率限制
-撤销或终止任务
3 Broker 监控
-查看所有 Celery 队列的统计信息
5.1 修改结果存储为redis
RESULT_BACKEND = 'redis://127.0.0.1:6379/2'
5.2 安装flower和启动
#1 安装
pip install flower
# 2 启动
celery -A django_celery_crawl flower --port-5555
#3 浏览器访问:
http://127.0.0.1:5555/
# 4 启动 worker,beat,flower
-一般先启动flower
6 任务执行成功或失败告警(邮件)
虽然可以通过界面来监控了,但是我们想要得更多,人不可能天天盯着界面看吧,如果能实现任务执行失败或成功就自动发邮件告警就好了。这个Celery当然也是没有问题的
# 注册任务
import time
from celery import shared_task
### 写个类,继承 Task,写方法
from celery import Task
from django.core.mail import send_mail
from django.conf import settings
class SendEmailTask(Task):
def on_success(self, retval, task_id, args, kwargs):
# 任务执行成功,会执行这个
info = f'爬虫任务成功-- 任务id是:{task_id} , 参数是:{args} , 执行成功 !'
# 发送邮件--》django中发送邮件
send_mail('celery监控成功告警', info, settings.EMAIL_HOST_USER, ['616564099@qq.com'])
def on_failure(self, exc, task_id, args, kwargs, einfo):
# 任务执行失败,会执行这个
info = f'爬虫任务失败-- 任务id是:{task_id} , 参数是:{args} , 执行失败,请去flower中查看原因 !'
# 发送邮件--》django中发送邮件
send_mail('celery监控爬虫失败告警', info, settings.EMAIL_HOST_USER, ['616564099@qq.com'])
def on_retry(self, exc, task_id, args, kwargs, einfo):
# 任务执行重试,会执行这个
print('重试了!!!')
# 以后使用shared_task 替换掉 app.task
# 任务函数
@shared_task
def add(a, b):
return a + b
@shared_task
def send_email(to_user):
time.sleep(2)
return '发送邮件成功:%s' % to_user
@shared_task(base=SendEmailTask, bind=True) # 只要执行它成功或失败,都会给 616564099@qq.com发送邮件
def crawl_cnblogs(self):
print('爬去cnblogs网站技术博客了')
return True
6.2 setting中 邮箱配置
#### 发送邮件配置
EMAIL_HOST = 'smtp.qq.com' # 如果是 163 改成 smtp.163.com
EMAIL_PORT = 465
EMAIL_HOST_USER = '' # 帐号
EMAIL_HOST_PASSWORD = '' # 密码
DEFAULT_FROM_EMAIL = EMAIL_HOST_USER
#这样收到的邮件,收件人处就会这样显示
#DEFAULT_FROM_EMAIL = 'lqz<'306334678@qq.com>'
EMAIL_USE_SSL = True #使用ssl
#EMAIL_USE_TLS = False # 使用tls
6.3 在admin中添加任务执行
# 1 admin中添加任务,只执行一次
# 2 执行完了 flower可以监控到
# 3 也能收到邮件通知
7 定时爬取技术类文章-邮件通知
# 1 爬取目标网站:https://www.cnblogs.com/
-爬取它首页的推荐文章
-文章标题
-文章作者
-文章url地址
-文章摘要
-每隔一天爬一次
-可能会重复--》去重
# 2 安装
-pip install requests
-pip install beautifulsoup4
from django.db import models
class Article(models.Model):
title = models.CharField(max_length=64)
url = models.CharField(max_length=64)
author = models.CharField(max_length=64)
desc = models.TextField()
# 迁移
python manage.py makemigrations
python manage.py migrate
# 数据库才有这个表
7.2 在task中写
# 注册任务
import time
from celery import shared_task
### 写个类,继承 Task,写方法
from celery import Task
from django.core.mail import send_mail
from django.conf import settings
class SendEmailTask(Task):
def on_success(self, retval, task_id, args, kwargs):
# 任务执行成功,会执行这个
info = f'爬虫任务成功-- 任务id是:{task_id} , 参数是:{args} , 执行成功 !'
# 发送邮件--》django中发送邮件
send_mail('celery监控成功告警', info, settings.EMAIL_HOST_USER, ['616564099@qq.com'])
def on_failure(self, exc, task_id, args, kwargs, einfo):
# 任务执行失败,会执行这个
info = f'爬虫任务失败-- 任务id是:{task_id} , 参数是:{args} , 执行失败,请去flower中查看原因 !'
# 发送邮件--》django中发送邮件
send_mail('celery监控爬虫失败告警', info, settings.EMAIL_HOST_USER, ['616564099@qq.com'])
def on_retry(self, exc, task_id, args, kwargs, einfo):
# 任务执行重试,会执行这个
print('重试了!!!')
###爬取技术博客#####
import requests
from bs4 import BeautifulSoup
from .models import Article
from redis import Redis
@shared_task(base=SendEmailTask, bind=True) # 只要执行它成功或失败,都会给 616564099@qq.com发送邮件
def crawl_cnblogs(self):
# 拿到redis链接
conn = Redis(host='127.0.0.1', port=6379)
res = requests.get('https://www.cnblogs.com/')
soup = BeautifulSoup(res.text, 'html.parser')
# 查找:-文章标题-文章作者-文章url地址-文章摘要
# 找到所有文章
article_list = soup.find_all(name='article', class_='post-item')
# 循环一个个文章
for article in article_list:
title = article.find(name='a', class_='post-item-title').text
url = article.find(name='a', class_='post-item-title').attrs.get('href')
author = article.find(name='a', class_='post-item-author').span.text
desc = article.find(name='p', class_='post-item-summary').text.strip()
print(f'''
文章名字:{title}
文章地址:{url}
文章作者:{author}
文章摘要:{desc}
''')
# 去重,不能有重复,如果重复了,就不存到数据库中了---》集合可以去重--》redis集合去重-->根据url去重
# 只要redis的urls的这个集合中,有了这个地址,我们就不存了--》去重了
res = conn.sadd('urls', url)
if res: # 返回1 表示放进集合中了,表示集合中没有,存数据库 返回0,表示集合中有过,不存了
# 保存到数据库中--》创建一个Article的数据表
Article.objects.create(title=title, url=url, author=author, desc=desc)
return True
7.3 以后只需要在后台管理添加定时任务
# 比如一天爬一次
-所有服务都启动,不用管了
8 定时爬取美女图片-告警案例
# 1 爬取目标网站:https://pic.netbian.com
- 爬给定的页面中的图片保存到本地
https://pic.netbian.com/tupian/33985.html
https://pic.netbian.com/tupian/32967.html
### 爬取图片
import os
# 爬取美女图片
@shared_task(base=SendEmailTask, bind=True)
def crawl_photo(self,url):
res = requests.get(url)
res.encoding = 'gbk'
soup = BeautifulSoup(res.text, 'html.parser')
ul = soup.find('ul', class_='clearfix')
img_list = ul.find_all(name='img', src=True)
for img in img_list:
try:
url = img.attrs.get('src')
if not url.startswith('http'):
url = 'https://pic.netbian.com' + url
print(url)
res1 = requests.get(url)
name = url.split('-')[-1]
with open(os.path.join(settings.BASE_DIR,'img',name), 'wb') as f:
for line in res1.iter_content():
f.write(line)
except Exception as e:
continue