文章结尾部分有CSDN官方提供的学长 联系方式名片
up主B站: 麦麦大数据
关注B站,有好处!
编号: D025
视频
D025 🏍 摩托车价格预测推荐vue+django大数据分析系统echarts机器学习计算机毕业必学设计
1 系统简介
系统简介:本系统是一个基于Vue+Django构建的摩托车推荐价格预测可视化系统,集成推荐算法、机器学习模型和数据可视化功能,旨在为用户提供个性化的摩托车推荐和价格预测服务。系统的核心功能包括:首页展示、推荐系统、价格预测、摩托车信息查询、摩托车详情页面、用户画像及数据分析,以及用户管理模块。通过RESTful API实现前后端的数据交互,前端采用Vue.js生态系统(包括Vuex、Vue Router)构建用户界面,后端使用Django框架处理业务逻辑,MySQL数据库负责存储用户信息、摩托车数据和交互行为数据。系统还整合了数据可视化工具(如ECharts)以展示用户画像和预测结果,提升用户体验。
2 功能设计
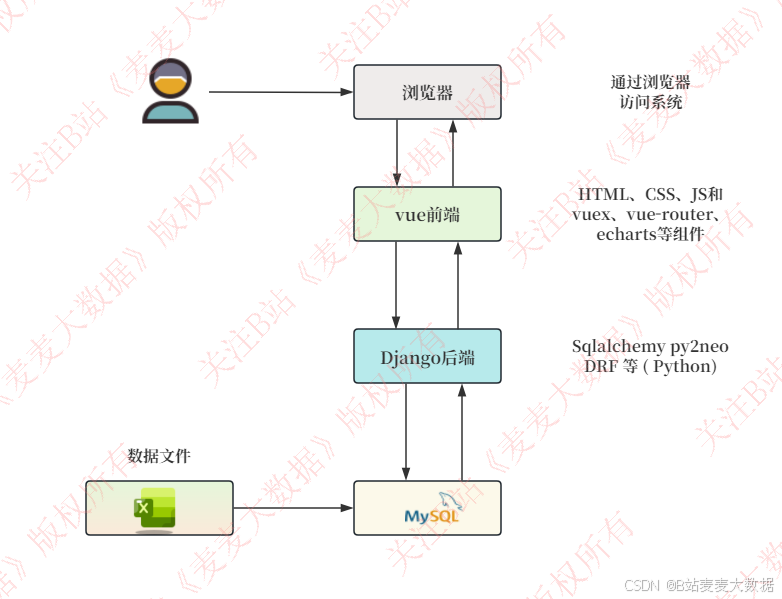
该系统采用典型的B/S(浏览器/服务器)架构模式。具体实现细节如下:
前端:基于Vue.js框架构建,使用Vuex进行状态管理,Vue Router实现路由导航,ECharts负责数据可视化图表的展示。
后端:使用Django框架搭建RESTful API,处理用户请求,执行推荐算法和机器学习模型的计算,管理业务逻辑。
数据库:采用MySQL进行数据持久化存储,包括用户信息、摩托车基础数据、用户交互行为数据(如评论、收藏、评分)、预测结果等。
2.1系统架构图
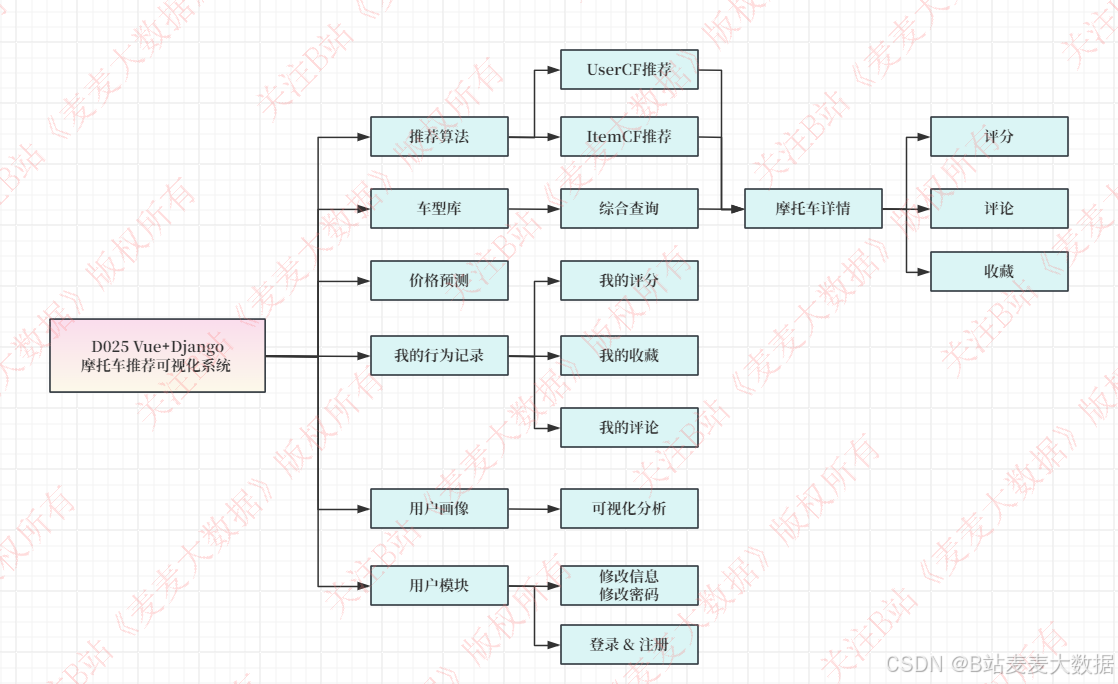
2.2 功能模块图
系统功能我们分为管理员和普通用户,所以给出2张模块图:
普通用户的:
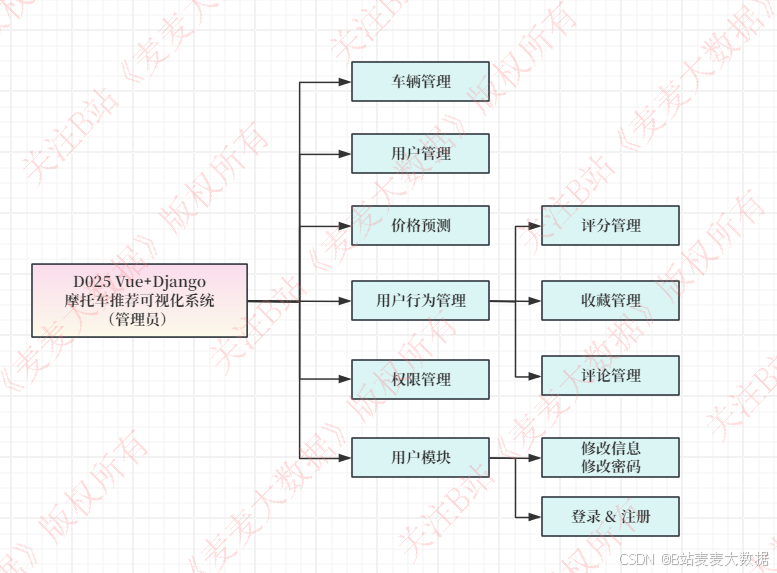
管理员的:
3 功能展示
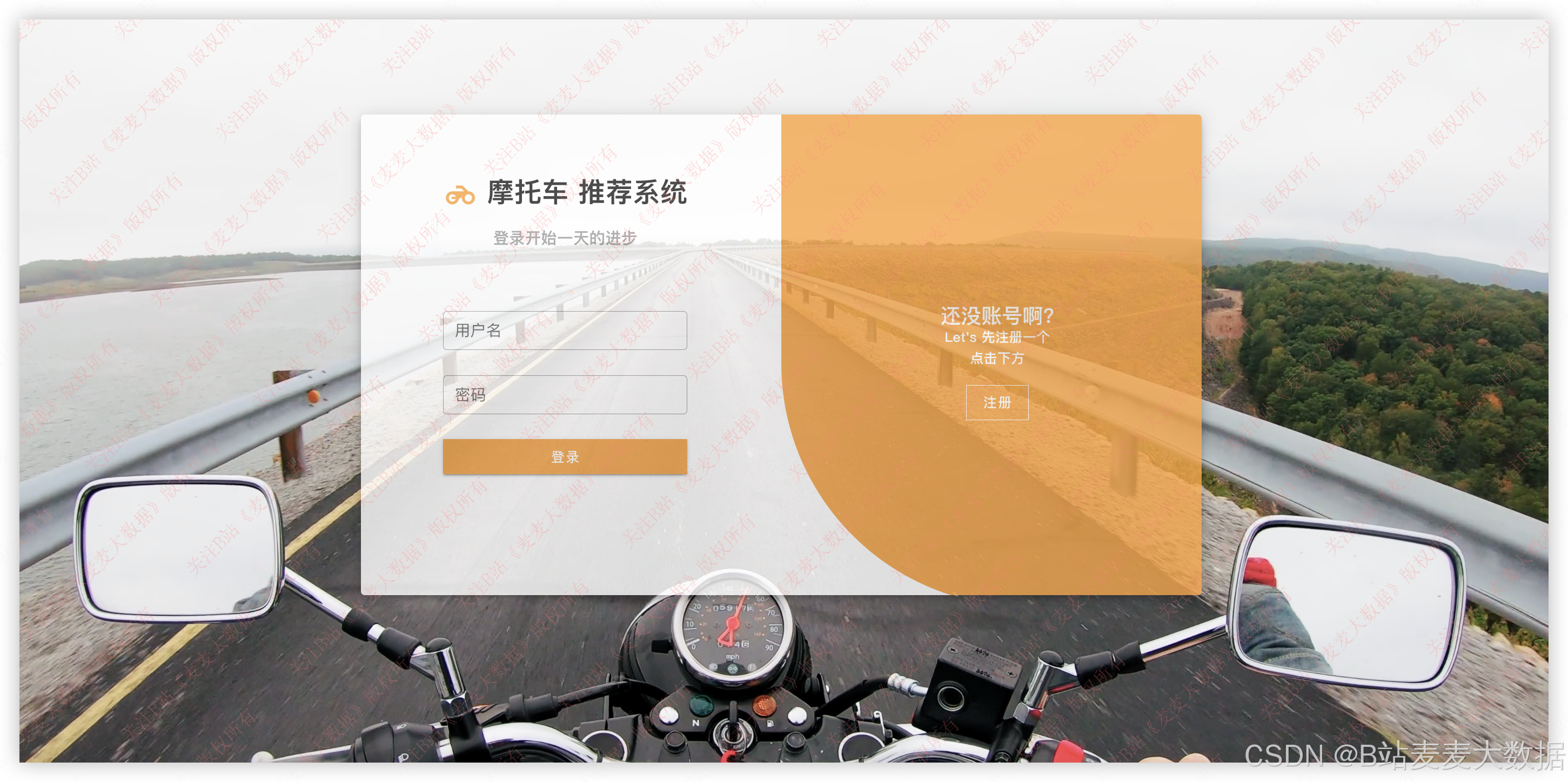
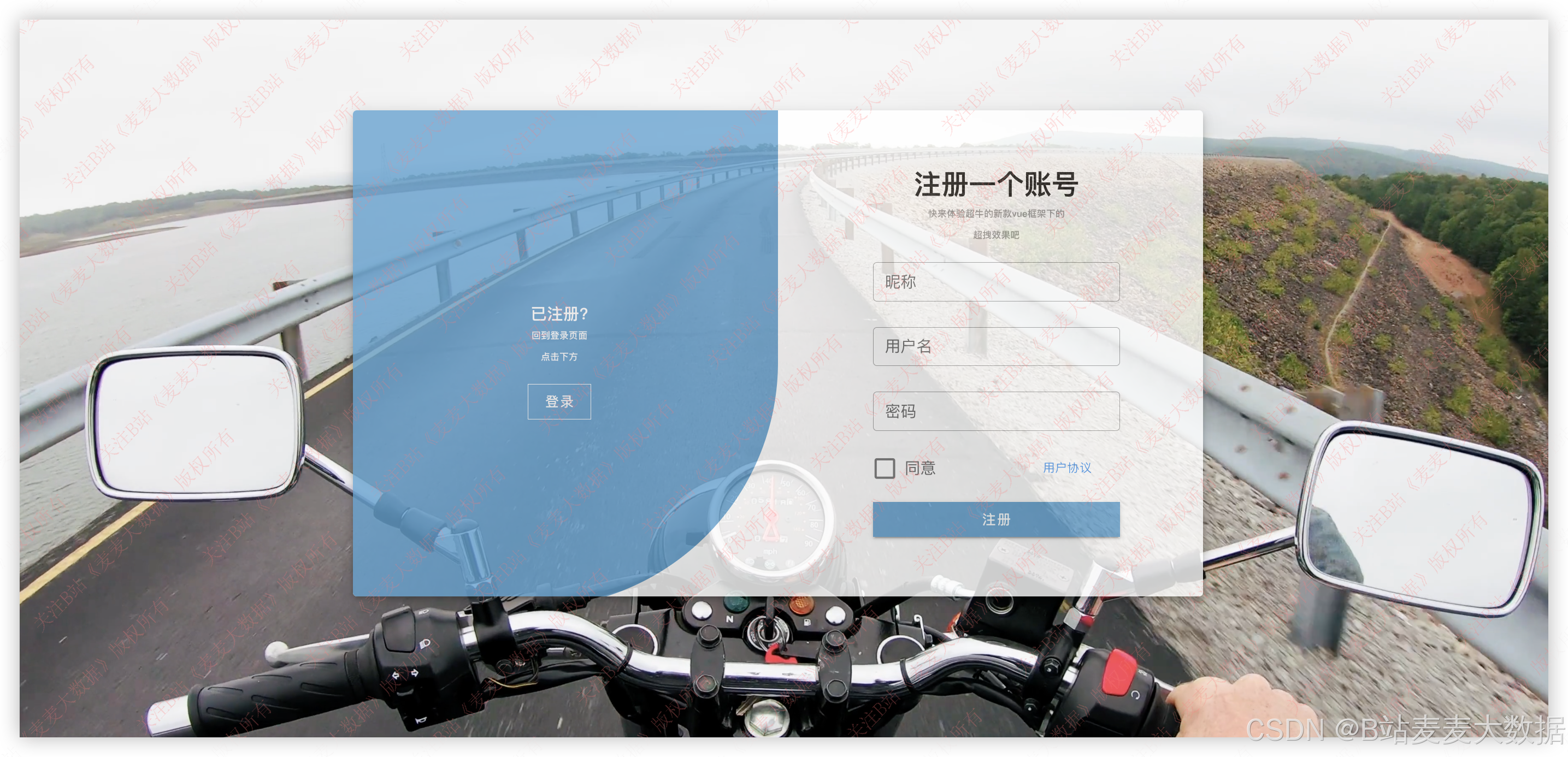
3.1 登录 & 注册
登录界面背景是一个视频,展示和本文系统主题相匹配的内容,登录和注册界面在一个界面下,通过按钮来切换,注册界面输入用户名和密码,会检查这个用户是否存在,登录界面则要检查用户名是否存在以及用户名密码是否正确:
3.2 主页
如果通过校验,则可以进入主页,在主页是一个左侧菜单,右侧操作面板的布局,右上角是登录用户的头像和退出按钮:
3.3 摩托车管理【管理员功能】


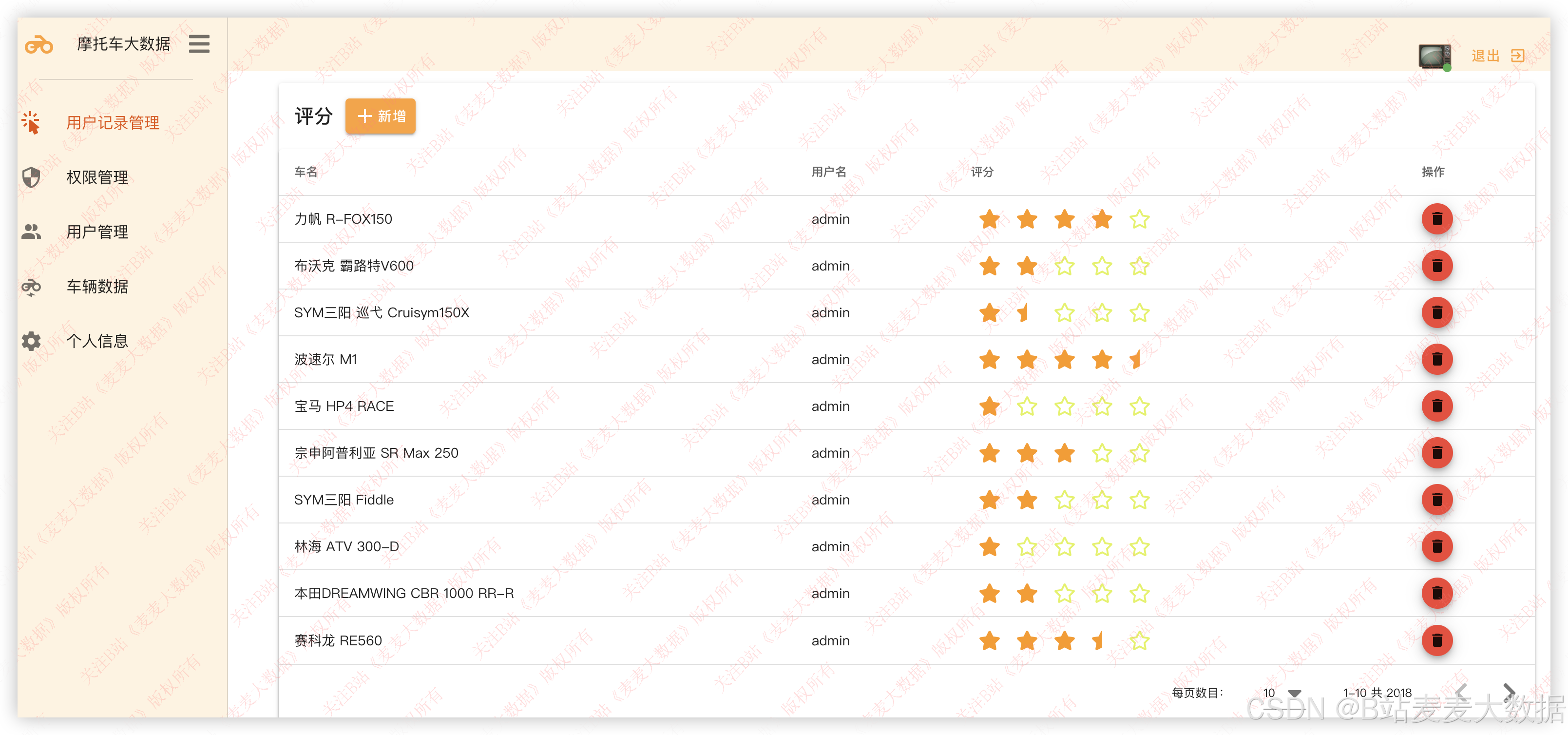
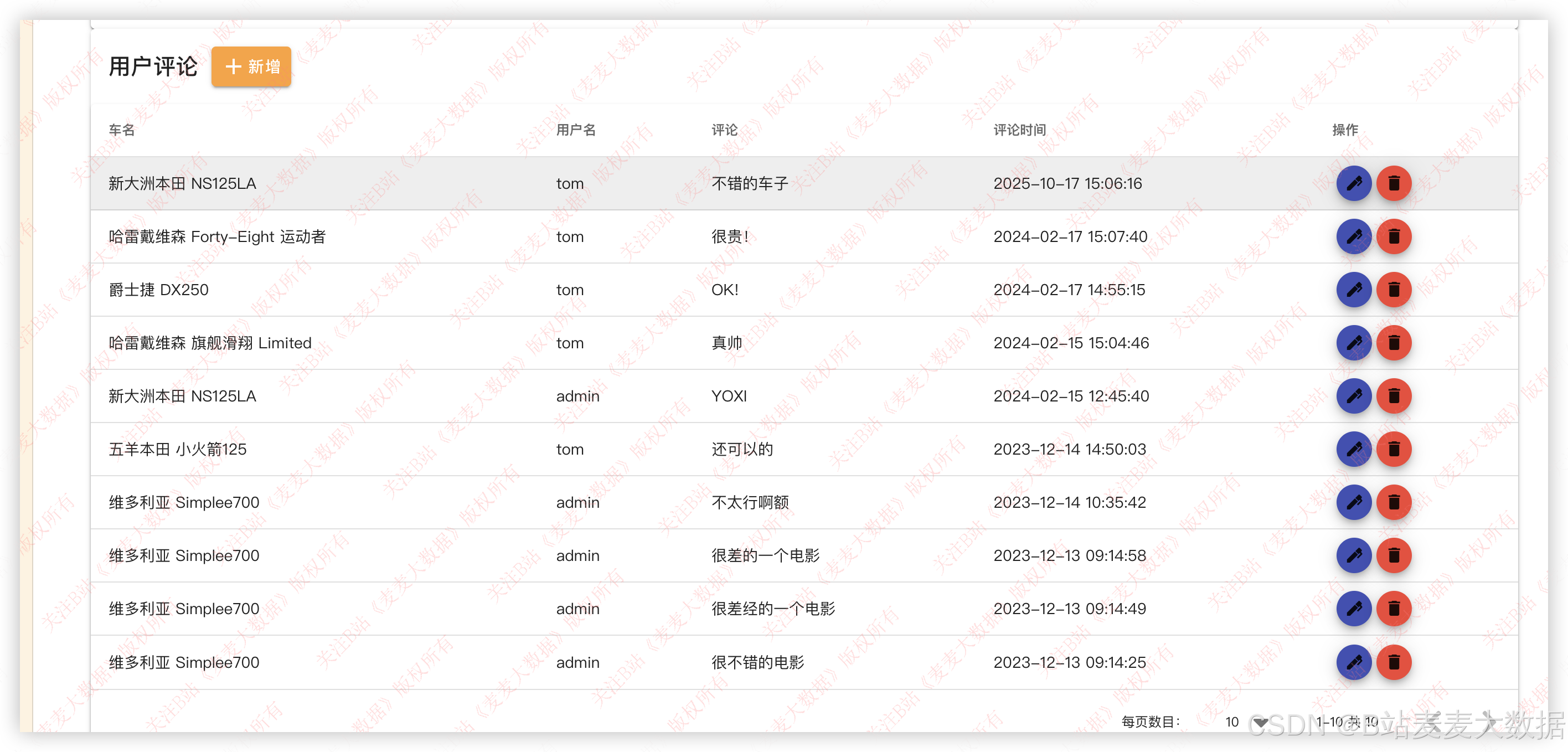
3.4 用户行为管理【管理员功能】
这个功能下有3个管理,这个是评分管理 :
评论管理 :
收藏管理 :

3.5 用户管理【管理员功能】

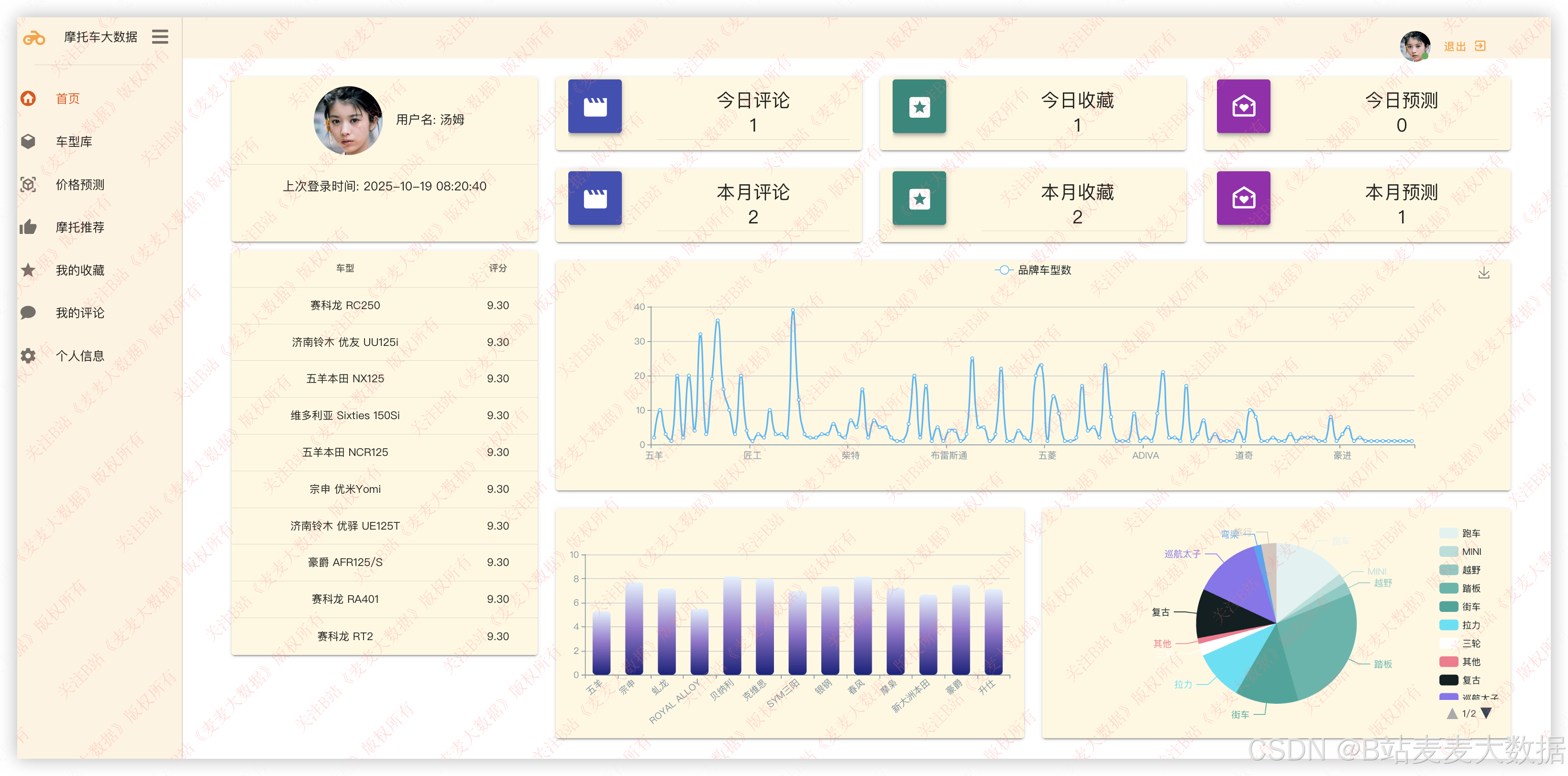
3.6 用户画像【用户功能】
3.7 摩托车推荐【用户功能】
两种推荐,usercf算法 :
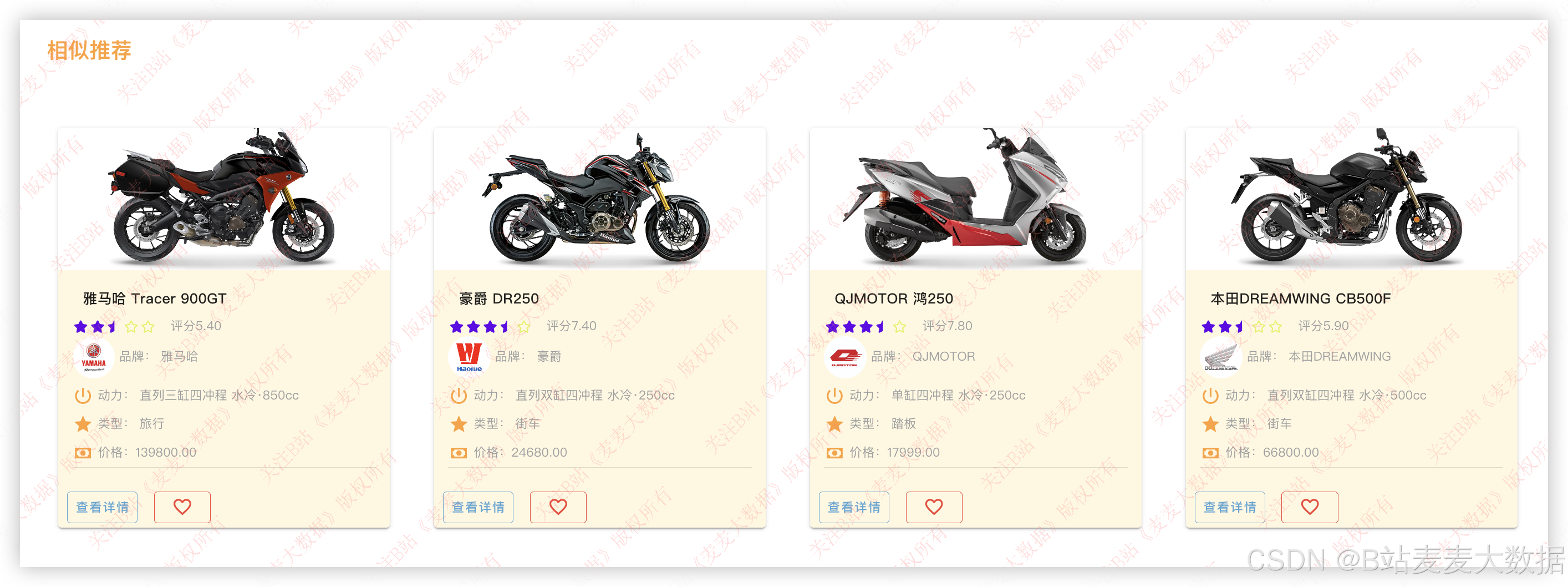
itemcf推荐算法 :

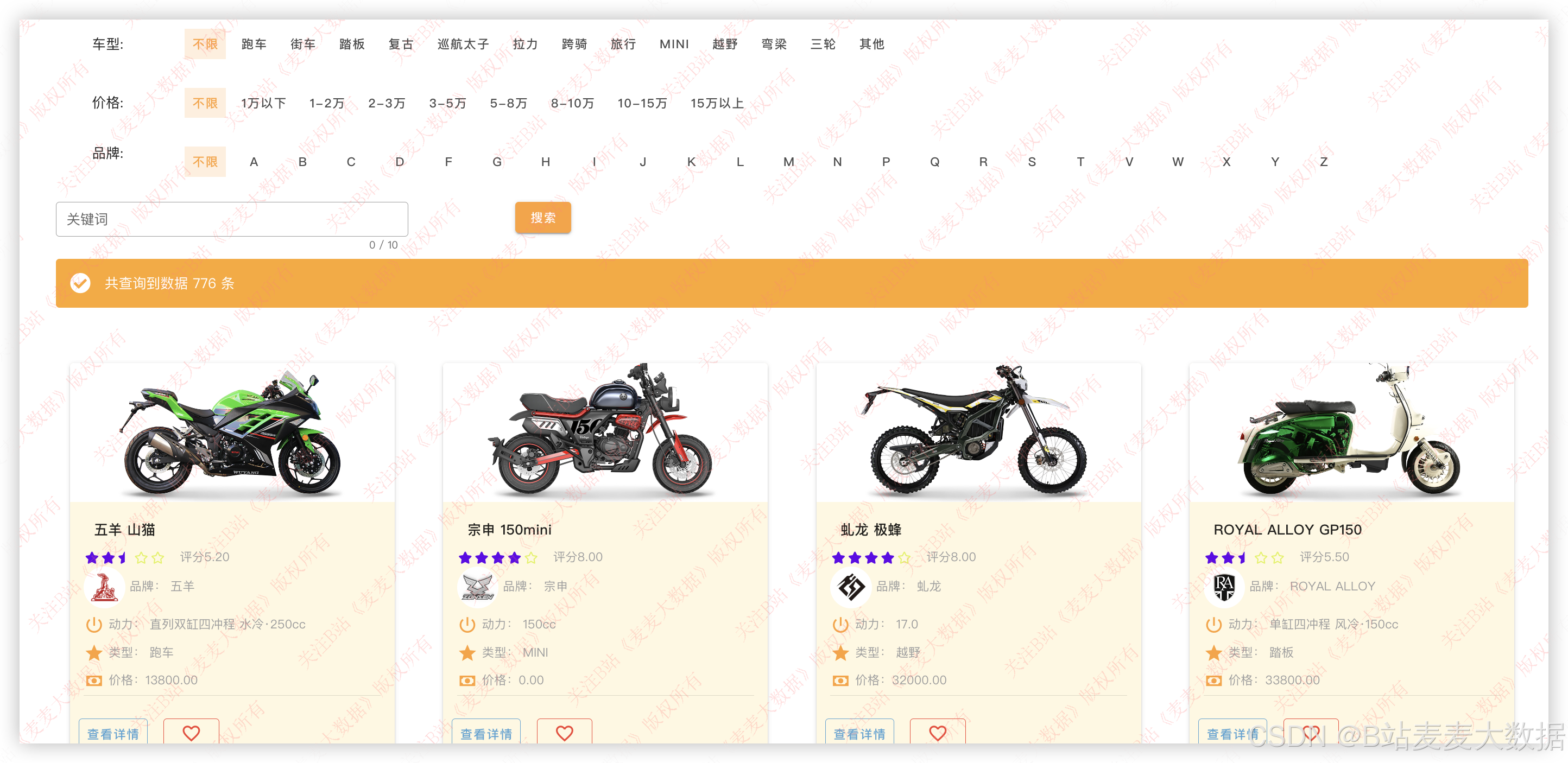
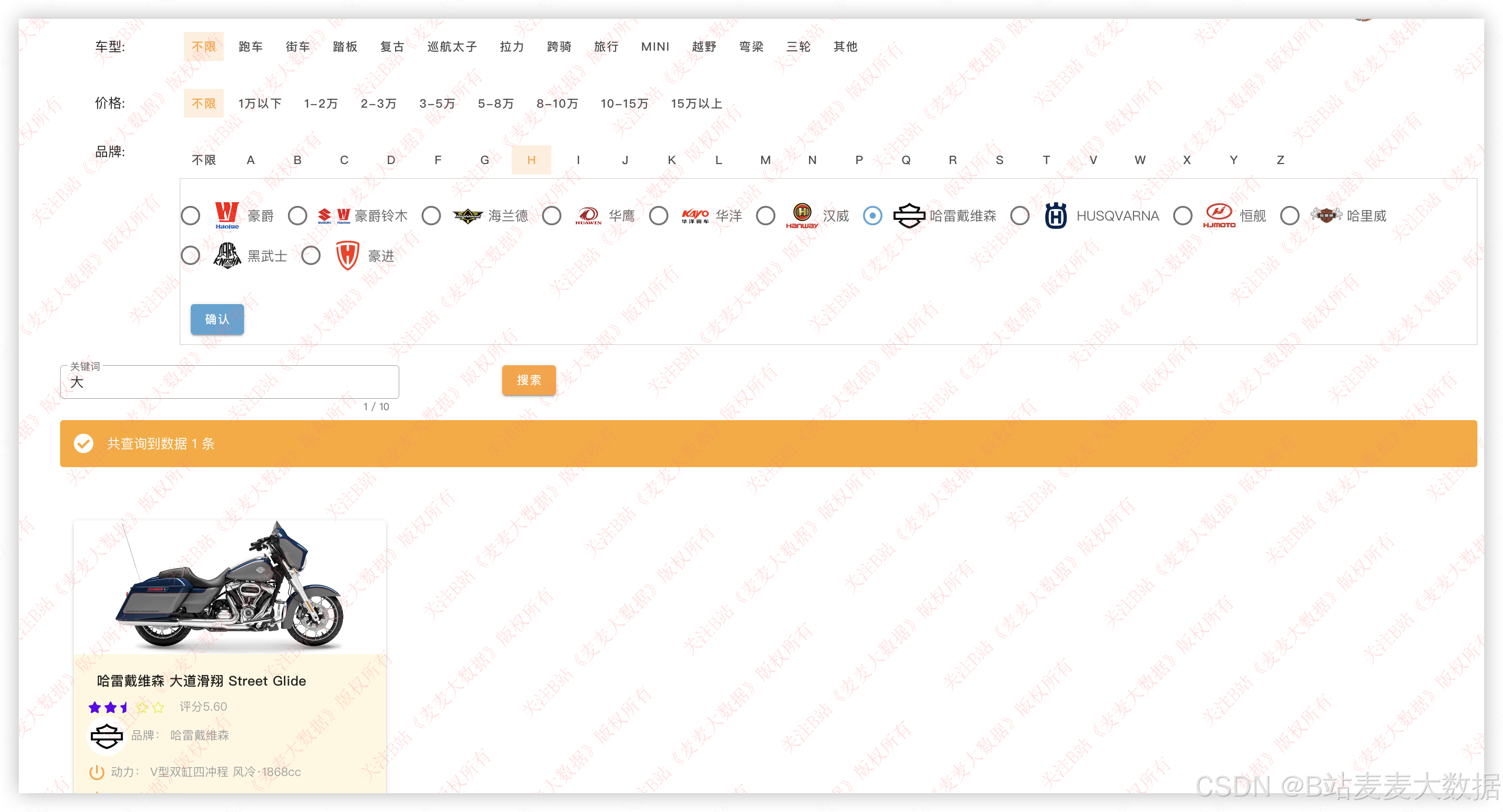
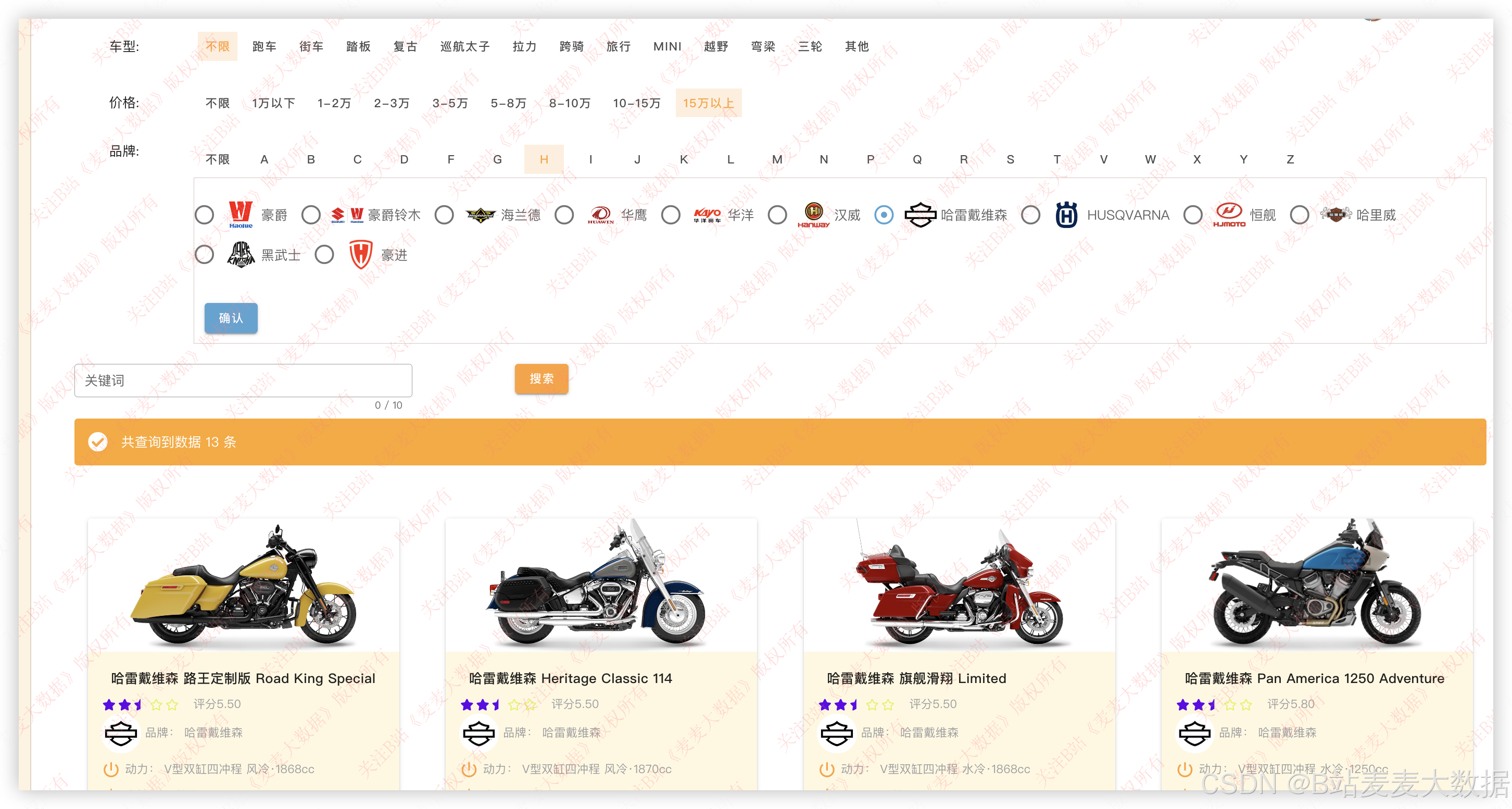
3.8 车型库 / 综合查询【用户功能】
支持用车型、价格、品牌结合关键词进行搜索:
3.9 摩托车详情【用户功能】
点击之后可以查看详情,详情页面下海可以评论、评分、收藏:
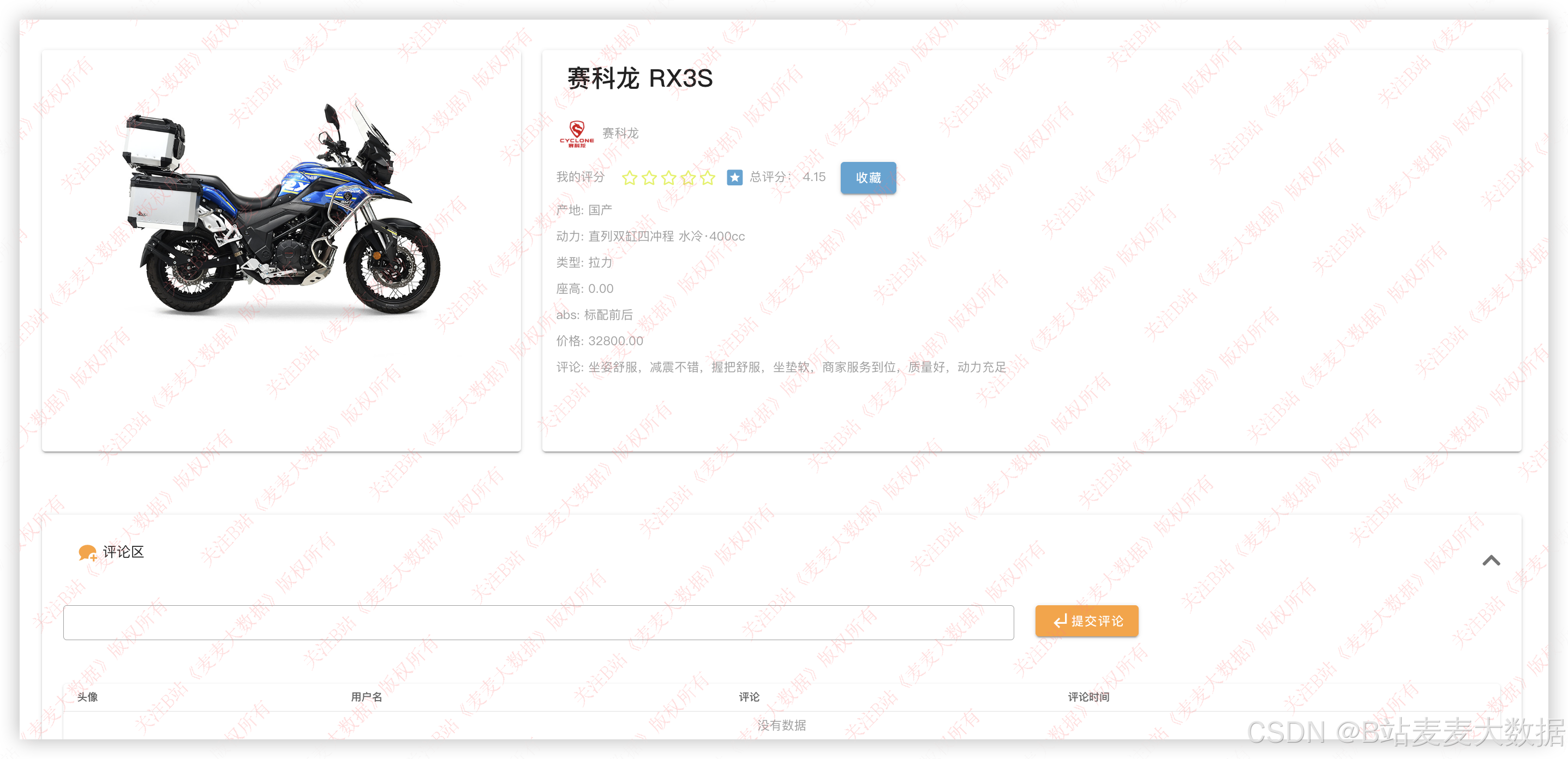
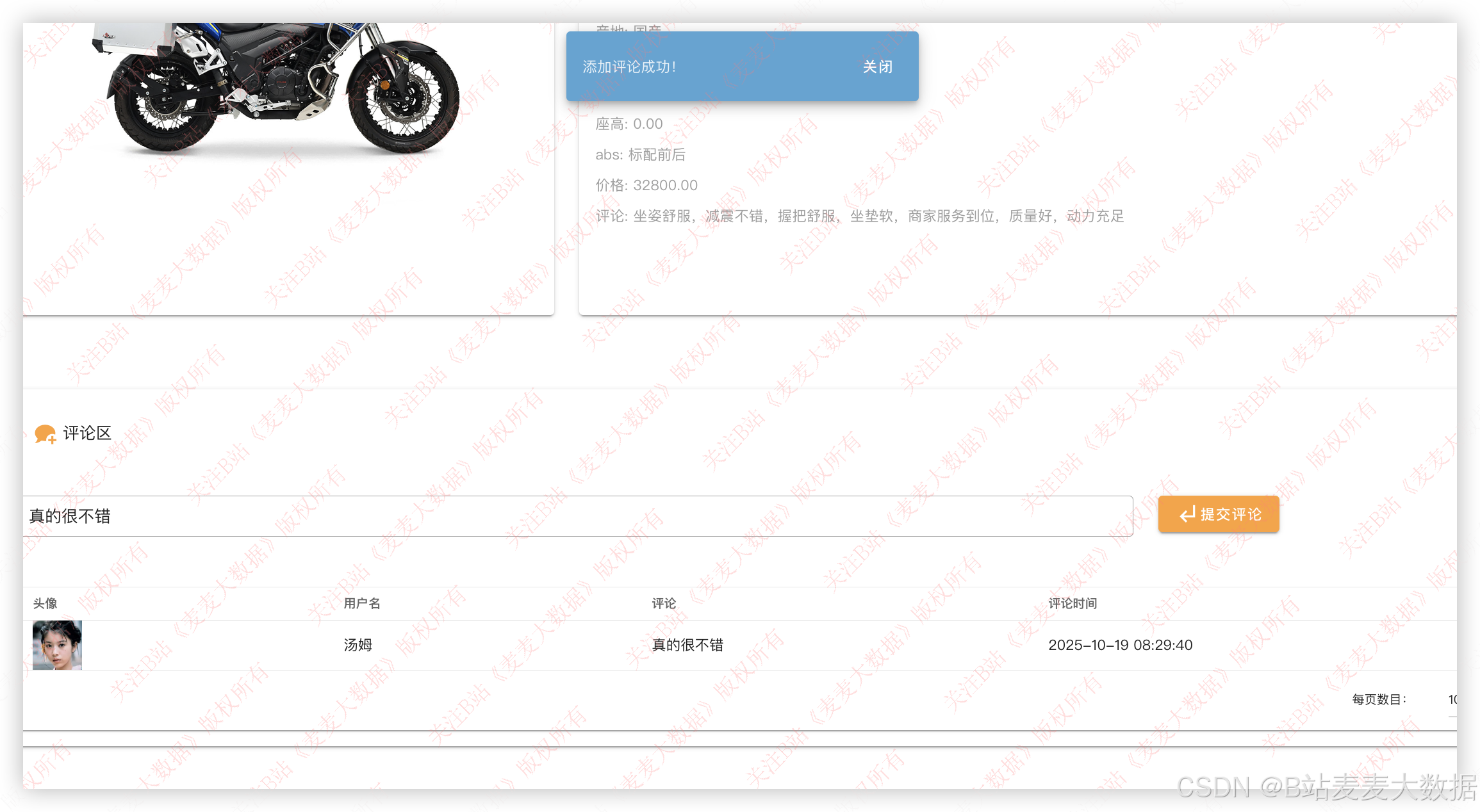
3.10 我的收藏【用户功能】

3.10 我的评论【用户功能】

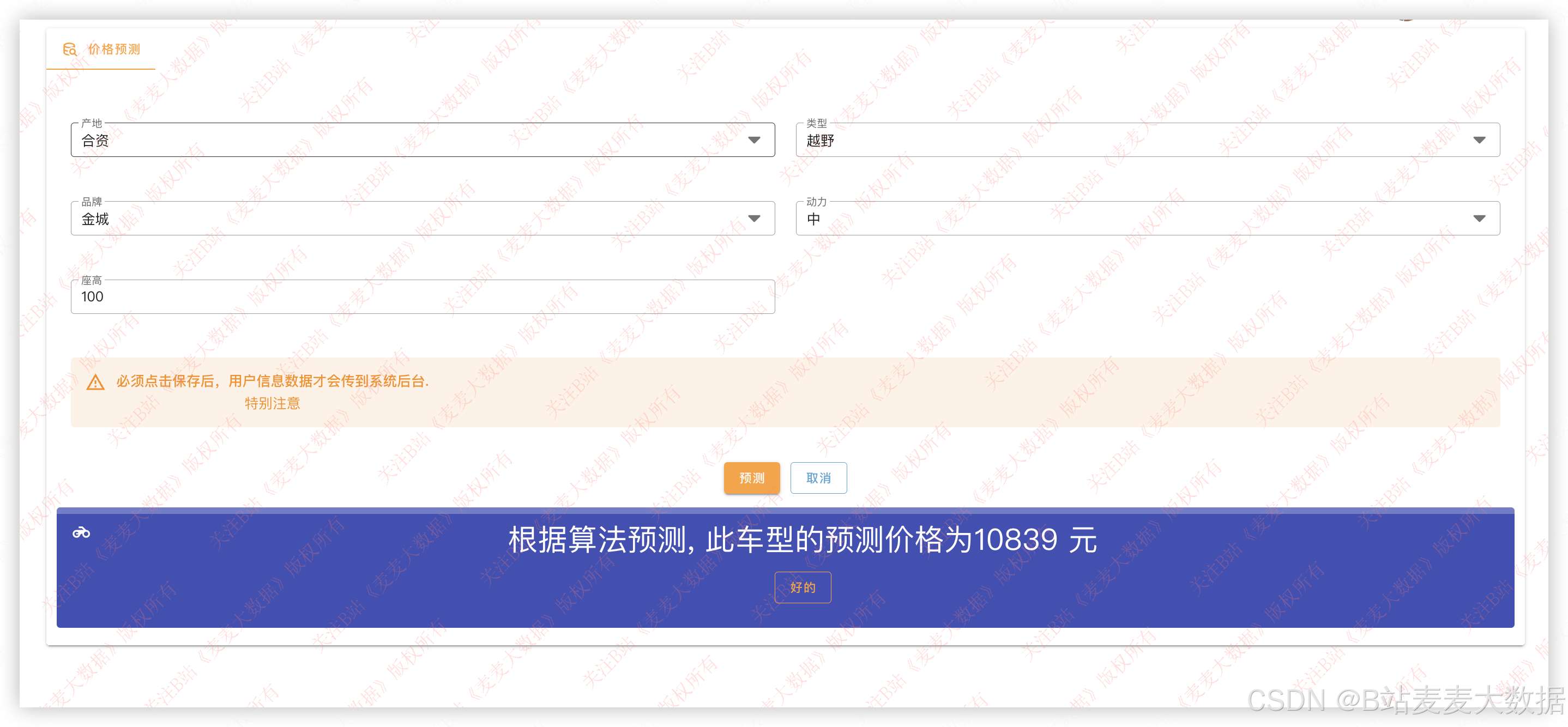
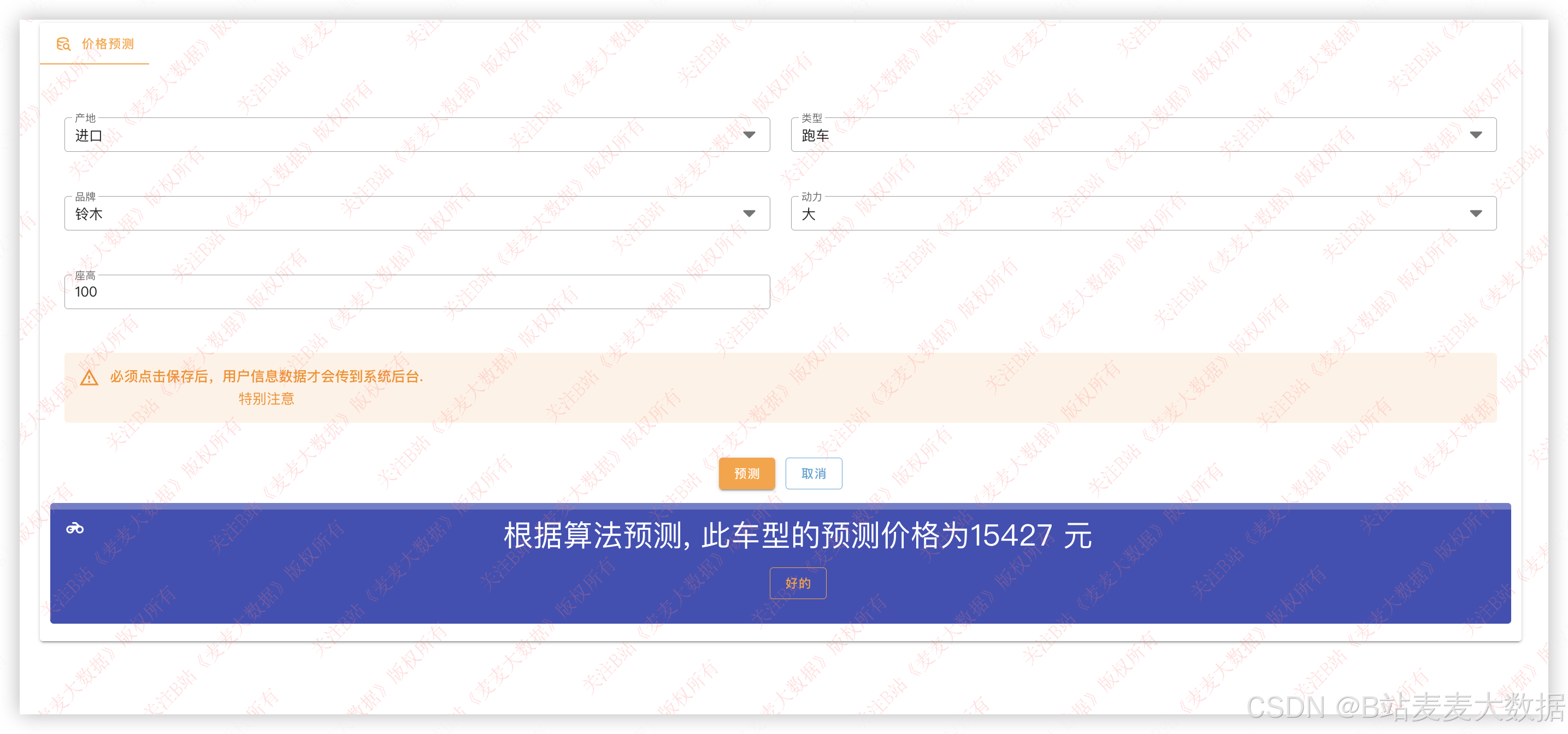
3.11 价格预测【用户功能】
可以利用不同条件,通过机器学习对摩托车价格进行预测,如果买二手车这个功能很有用!
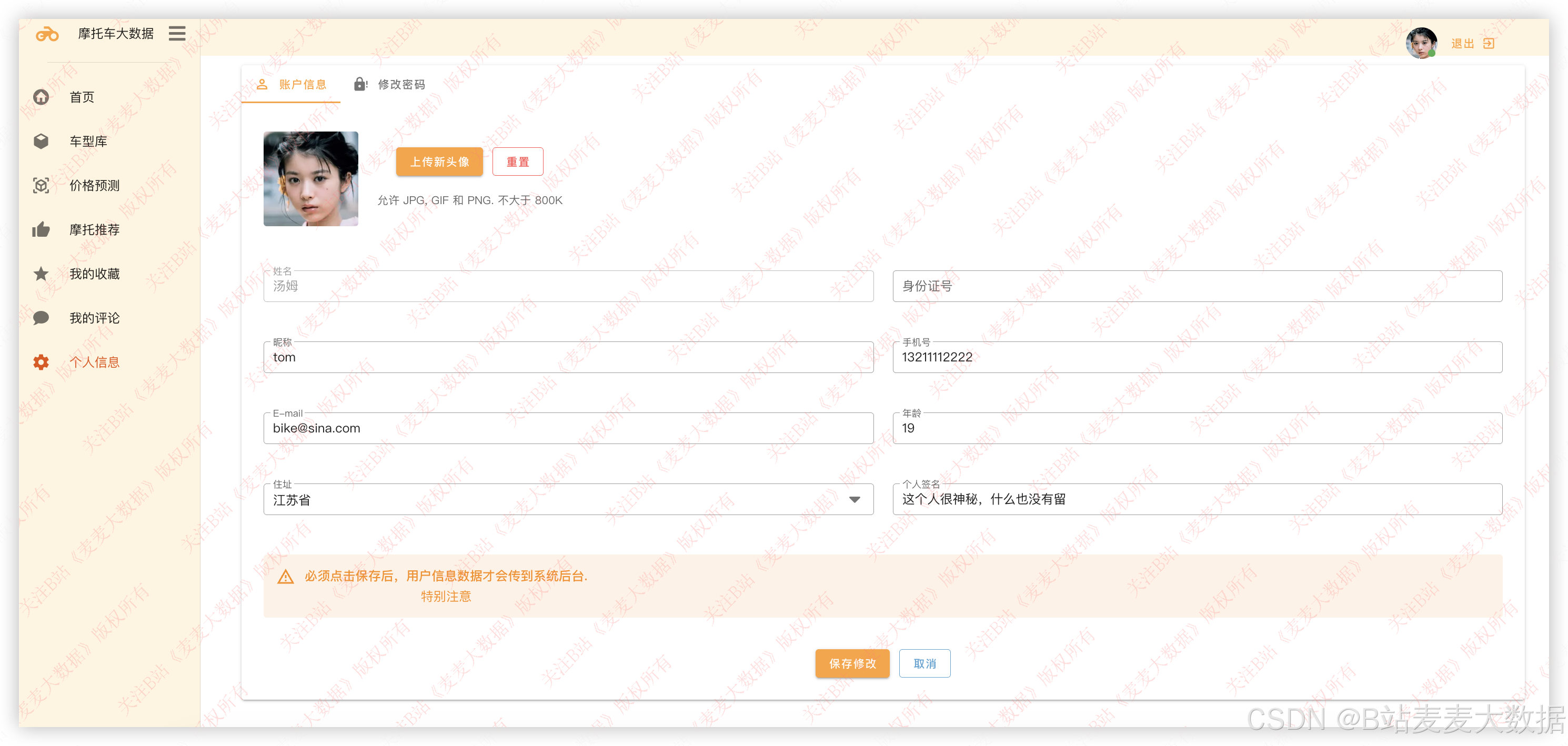
3.12 个人设置
个人设置方面包含了用户信息修改 、密码修改 功能。
用户信息修改中可以上传头像,完成用户的头像个性化设置,也可以修改用户其他信息。
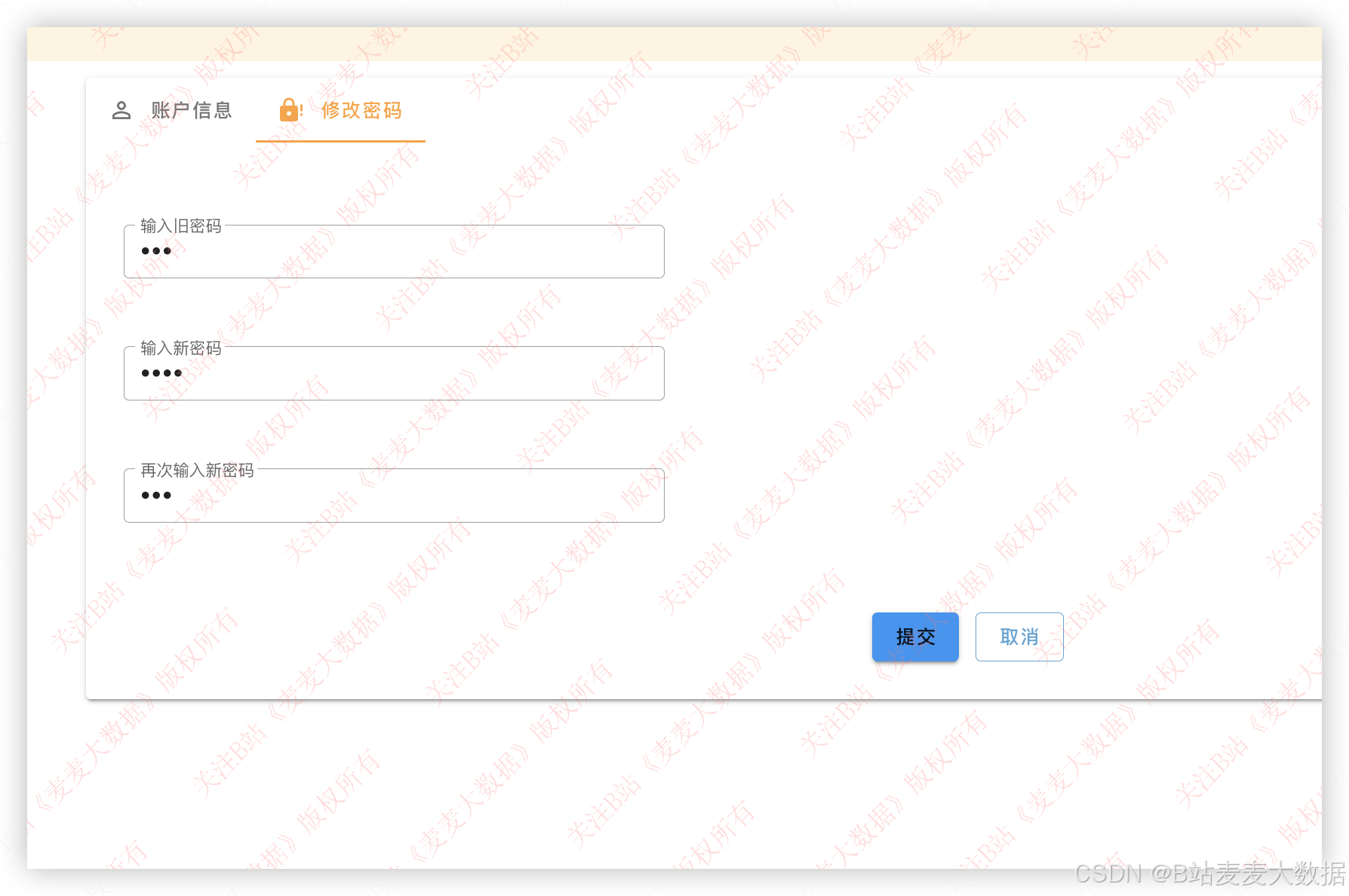
修改密码需要输入用户旧密码和新密码,验证旧密码成功后,就可以完成密码修改。
4程序代码
4.1 代码说明
代码介绍:随着摩托车市场的快速发展,消费者在购买时面临着众多选择,价格预测成为用户决策的重要依据。本系统利用机器学习技术,通过分析品牌、是否进口以及排量等关键参数来预测摩托车的价格。品牌代表了制造商的技术实力和市场口碑,是否进口反映了产品的关税成本和市场定位,排量则直接影响着发动机性能和市场价格。系统通过收集和整理摩托车数据,利用回归算法建立价格模型,并通过训练和测试数据评估模型的准确性,最终为用户提供快速而准确的价格预测服务。该系统不仅帮助消费者做出明智的购车决策,也为二手车交易平台提供参考价值
4.2 流程图

4.3 代码实例
python
# -*- coding: utf-8 -*-
"""
基于机器学习的摩托车价格预测
输入参数:品牌、是否进口、排量
"""
# 导入必要的库
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import StandardScaler
# 假设这是我们的数据(实际使用中应替换为真实数据)
data = {
'Brand': ['BrandA', 'BrandB', 'BrandC', 'BrandA', 'BrandB', 'BrandC', 'BrandA', 'BrandB', 'BrandC', 'BrandA'],
'IsImported': [1, 0, 1, 0, 1, 0, 1, 0, 1, 0],
'Displacement': [500, 300, 650, 800, 250, 350, 900, 700, 400, 600],
'Price': [15000, 8000, 18000, 20000, 7500, 9500, 22000, 19000, 12000, 17000]
}
# 创建数据框
df = pd.DataFrame(data)
# 划分特征和目标
X = df[['Brand', 'IsImported', 'Displacement']]
y = df['Price']
# 特征工程:对分类变量进行独热编码
encoder = OneHotEncoder()
X_brands = encoder.fit_transform(X[['Brand']]).toarray()
X = pd.concat([pd.DataFrame(X_brands, columns=encoder.get_feature_names_out(['Brand'])), X[['IsImported', 'Displacement']]], axis=1)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 数据标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 训练模型(使用随机森林回归器)
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# 模型评估
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print(f"模型均方误差:{mse}")
# 示例预测
new_moto = pd.DataFrame({'Brand': ['BrandA'], 'IsImported': [1], 'Displacement': [500]})
new_moto_encoded = pd.concat([pd.DataFrame(encoder.transform(new_moto[['Brand']]).toarray(), columns=encoder.get_feature_names_out(['Brand'])), new_moto[['IsImported', 'Displacement']]], axis=1)
new_moto_encoded = scaler.transform(new_moto_encoded)
predicted_price = model.predict(new_moto_encoded)
print(f"预测价格:{predicted_price[0]}")