1、问题描述
我想对完整格式的 url 进行分词,请问有什么好的解决方案吗?
比如:https://www.abc.com/any/path?param_1=so+me\¶m-2=other#title
看了官方的分词器,感觉没啥合适的?
预处理的话,又不知道该怎么处理更合适?
因为我们的数据量比较大,不太想用 pattern,感觉集群的压力会升高?
我看这个分词器会把识别的 url 当作一个token,但我想实现的是,对 url 尽可能保证精准的拆分。
2、URL 有哪些分词器?
昨天跟 Elastic 官方布道师刘晓国老师一起直播讲 Elastic 认证的时候,刘老师提到:"不是每个人都把每个语法知识点都记得非常清楚,也没有必要。用到的时候查官方文档就可以"。
是这个道理,URL 自定义分词并没有那么常见。那咱们看看官方支持哪些吧?都拎出来用一下,不行就再想办法。
整体看下来直接和 URL 直接相关的就一个:UAX URL email。
间接相关的还有:path_hierarchy 分词、char_group 分词(可配置分割字符)。
无法之法就是挨个试一遍!
3、URL 分析器逐个验证
3.1 UAX URL email 分词
3.1.1 UAX URL email 分词功能
UAX URL email 分词器专门用于处理包含 URL 和电子邮件地址的文本。
它不仅能够正确识别和分词 URL,还可以处理电子邮件地址,并将其分割为有意义的部分。
3.1.2 UAX URL email 分词用途
UAX URL email 分词器适用于文本中包含电子邮件或 URL 的场景,确保这些特殊字符不会被简单地分割成无意义的碎片。
3.1.3 UAX URL email 分词配置示例及验证
go
POST _analyze
{
"tokenizer": "uax_url_email",
"text": "Email me at john.smith@global-international.com"
}分词后的结果是:
go
{
"tokens": [
{
"token": "Email",
"start_offset": 0,
"end_offset": 5,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "me",
"start_offset": 6,
"end_offset": 8,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "at",
"start_offset": 9,
"end_offset": 11,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "john.smith@global-international.com",
"start_offset": 12,
"end_offset": 47,
"type": "<EMAIL>",
"position": 3
}
]
}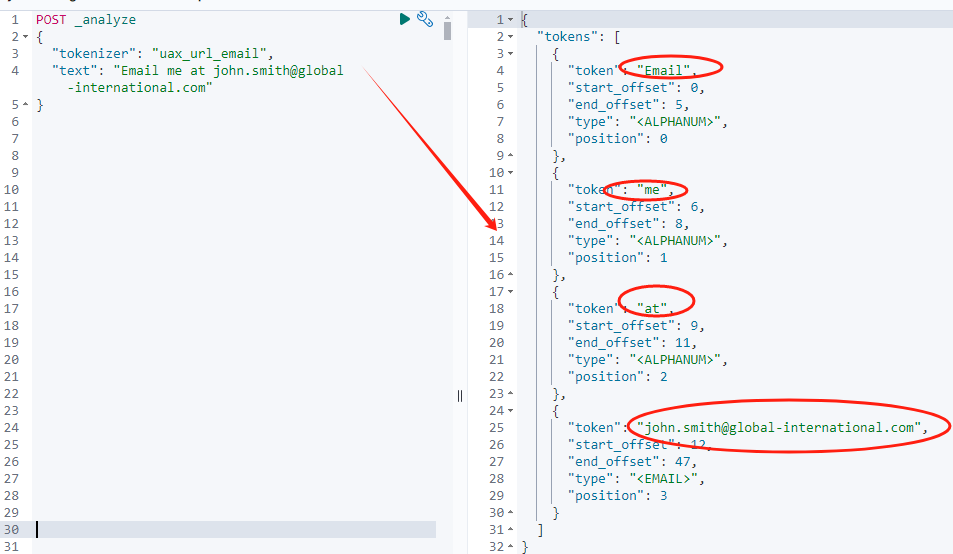
从执行结果看出,单词分词,URL 单独作为一个 token 词项单元。
这时候能想到,如果用这个分词器处理 https://www.abc.com/any/path?param_1=so+me\¶m-2=other#title 的时候,不会做切分。
真实验证如下,和我们预期一致。

如果对参数 max_token_length 稍加调整,
go
PUT my-index-000001
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "my_tokenizer"
}
},
"tokenizer": {
"my_tokenizer": {
"type": "uax_url_email",
"max_token_length": 5
}
}
}
}
}
POST my-index-000001/_analyze
{
"analyzer": "my_analyzer",
"text": "john.smith@global-international.com"
}执行一下:
go
{
"tokens": [
{
"token": "john",
"start_offset": 0,
"end_offset": 4,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "smith",
"start_offset": 5,
"end_offset": 10,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "globa",
"start_offset": 11,
"end_offset": 16,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "l",
"start_offset": 16,
"end_offset": 17,
"type": "<ALPHANUM>",
"position": 3
},
{
"token": "inter",
"start_offset": 18,
"end_offset": 23,
"type": "<ALPHANUM>",
"position": 4
},
{
"token": "natio",
"start_offset": 23,
"end_offset": 28,
"type": "<ALPHANUM>",
"position": 5
},
{
"token": "nal.c",
"start_offset": 28,
"end_offset": 33,
"type": "<ALPHANUM>",
"position": 6
},
{
"token": "om",
"start_offset": 33,
"end_offset": 35,
"type": "<ALPHANUM>",
"position": 7
}
]
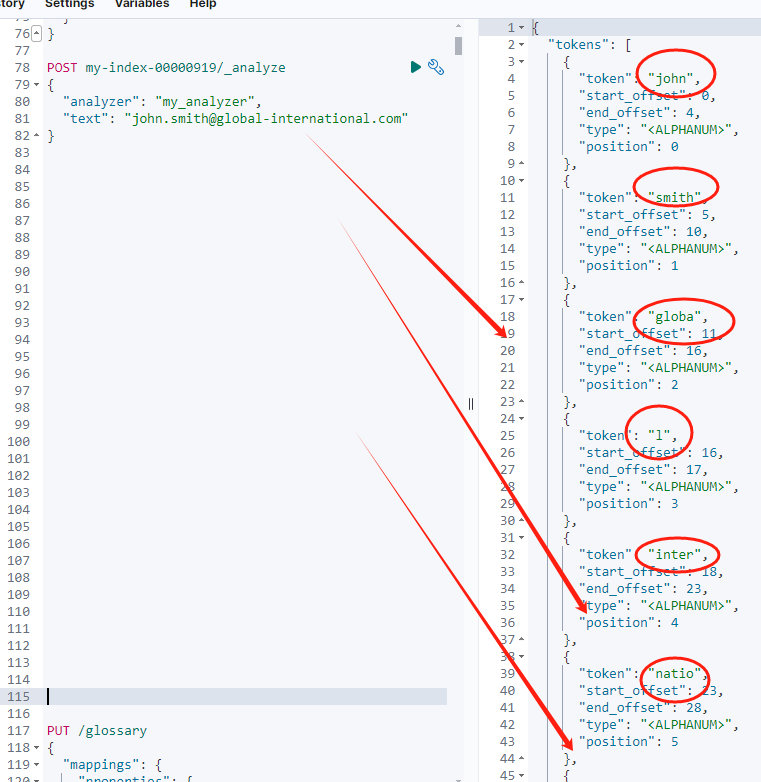
}咋一看,好像是我们想要的结果。仔细一看,不如咋一看。仔细一看,出了问题?!
在上述操作中使用了 uax_url_email 分词器,这个分词器专门处理 URL 和电子邮件地址,并设置了 max_token_length 为 5,这意味着每个分词的最大长度为 5 个字符(这很关键)。

在分析文本 "john.smith@global-international.com" 时,分词器对电子邮件地址进行了分词,结果如下:
"john" 和 "smith" 被分别作为单独的 token,因为它们是以 . 分隔的部分,并且每部分长度在 5 个字符以内。
后面的域名部分 global-international.com 被分割成多个 token,每个 token 长度不超过 5 个字符:"globa"、"inter"、"natio" 这些 token 依次从域名中提取出来。
由于 max_token_length 被限制为 5,长的单词被截断,如 global 被拆分为 "globa" 和 "l"。
最终结果是,整个电子邮件地址被分成 8 个 token,每个 token 的长度 不超过 5 个字符 。
这个分词器对于处理电子邮件地址和 URL 等结构化文本非常有用,同时通过设置 max_token_length 可以控制分词的粒度。
但,截断的处理显然不符合预期。
3.2 path_hierarchy 分词
3.2.1 path_hierarchy 分词功能
path_hierarchy 分词器主要用于处理文件路径、URL 或其他层次结构的字符串。它会逐级分割字符串,并生成所有可能的路径层次。
3.2.2 path_hierarchy 分词用途
适合用于处理文件系统路径、URL 层次结构等,特别是需要检索某一特定层级或更高层级时非常有用。
3.2.3 path_hierarchy 分词使用举例
go
POST _analyze
{
"tokenizer": "path_hierarchy",
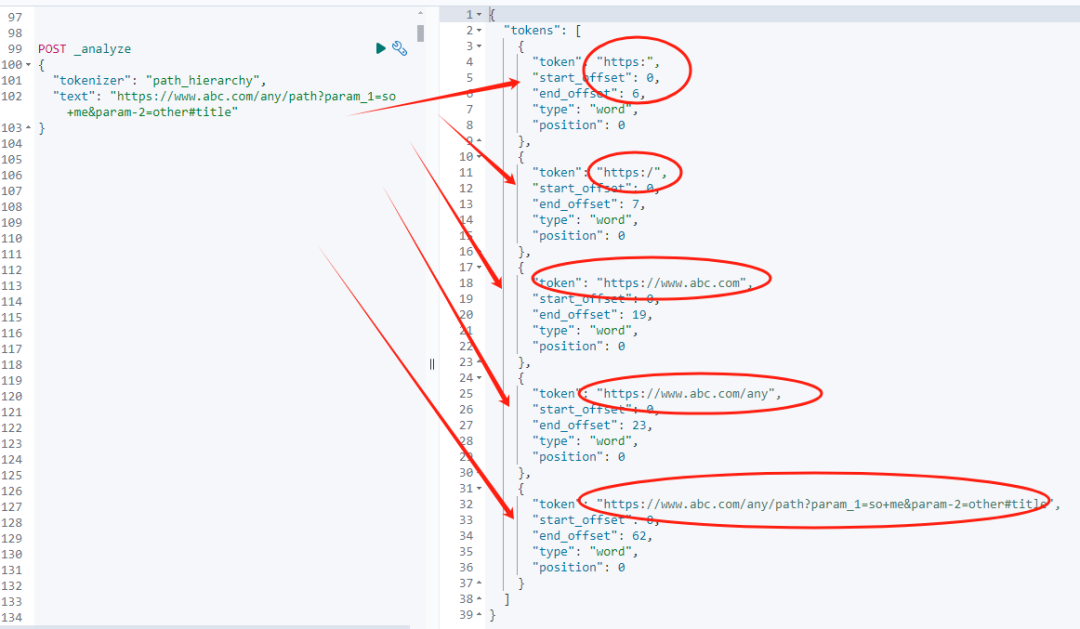
"text": "https://www.abc.com/any/path?param_1=so+me¶m-2=other#title"
}返回结果如下:
go
{
"tokens": [
{
"token": "https:",
"start_offset": 0,
"end_offset": 6,
"type": "word",
"position": 0
},
{
"token": "https:/",
"start_offset": 0,
"end_offset": 7,
"type": "word",
"position": 0
},
{
"token": "https://www.abc.com",
"start_offset": 0,
"end_offset": 19,
"type": "word",
"position": 0
},
{
"token": "https://www.abc.com/any",
"start_offset": 0,
"end_offset": 23,
"type": "word",
"position": 0
},
{
"token": "https://www.abc.com/any/path?param_1=so+me¶m-2=other#title",
"start_offset": 0,
"end_offset": 62,
"type": "word",
"position": 0
}
]
}从上面结果可以看出:path_hierarchy 分词器从最顶层(协议部分)开始,一步步解析出路径中的不同层次,生成多个分层级的 token,每个 token 表示 URL 的某个级别。
这个分词器会对路径中的每一层做分解,但它并不会解析 URL 中的查询参数、片段等部分。
这种分词方式对于处理层次化的 URL 非常有用,适合需要检索某一级 URL 层次的场景。例如,用户可以搜索整个网站、某个目录或具体路径。
3.3 char_group 分词(可配置分割字符)
3.3.1 char_group 分词功能
char_group 分词器允许用户定义分割字符集,例如可以自定义将 . 或 / 作为分割符,从而实现对 URL 进行特定模式的分词。
3.3.2 char_group 分词器用途
适合需要灵活处理 URL 或路径的场景,用户可以根据具体需求配置分割字符。
要对完整格式的 URL 进行精准的分词,同时又要在大数据量的情况下避免增加集群压力,建议使用 char_group 分词器。
char_group 分词器效率高,适合处理大量数据,因为它不使用正则表达式,不会像 开篇提到的 pattern 正则分词器那样消耗大量资源。
3.3.3 char_group 分词使用范例
我们可以配置 char_group 分词器,根据 URL 中常见的分隔符进行分词,例如 ** :, /, ?, &, =, +, #, -, _, . ** 等。
这些字符可以帮助你将 URL 拆分成有意义的部分,如协议、域名、路径、查询参数等。
详见官方文档;
https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-chargroup-tokenizer.html
以下是具体的实现方案:
go
PUT your_index
{
"settings": {
"analysis": {
"tokenizer": {
"url_tokenizer": {
"type": "char_group",
"tokenize_on_chars": [
"whitespace",
":",
"/",
"?",
"&",
"=",
"+",
"#",
"-",
"_",
"."
]
}
},
"analyzer": {
"url_analyzer": {
"tokenizer": "url_tokenizer",
"filter": ["lowercase"]
}
}
}
},
"mappings": {
"properties": {
"url": {
"type": "text",
"analyzer": "url_analyzer"
}
}
}
}上述定义解读如下:
- url_tokenizer:
使用 char_group 分词器,根据指定的字符进行分词。
- tokenize_on_chars:
定义了分词的字符集,包括 URL 中常见的分隔符。
- url_analyzer:
使用 url_tokenizer 作为分词器,并添加了 lowercase 过滤器,将所有词元转换为小写。
开篇问题测试如下:
go
GET your_index/_analyze
{
"analyzer": "url_analyzer",
"text": "https://www.abc.com/any/path?param_1=so+me¶m-2=other#title"
}返回结果:
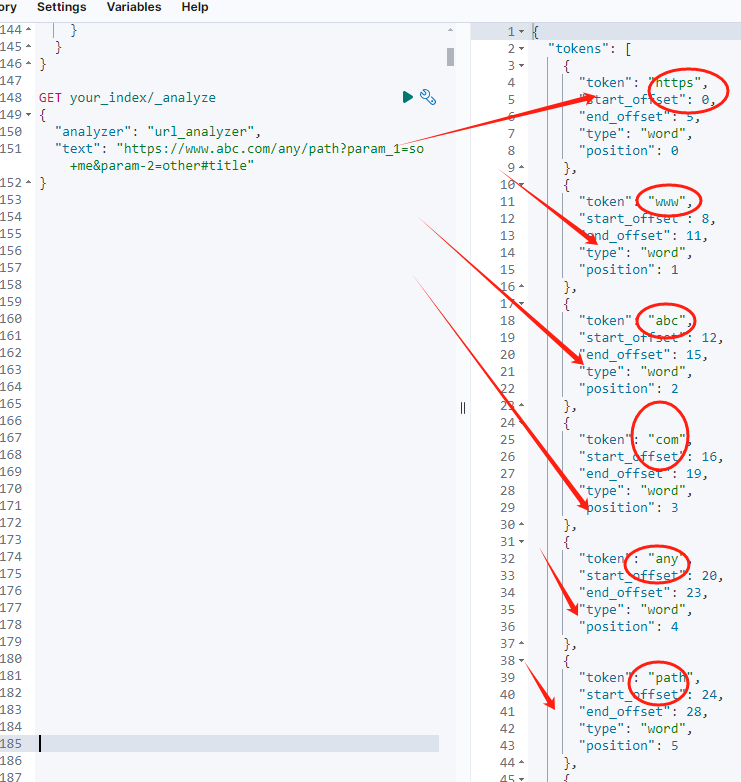
go
{
"tokens": [
{
"token": "https",
"start_offset": 0,
"end_offset": 5,
"type": "word",
"position": 0
},
{
"token": "www",
"start_offset": 8,
"end_offset": 11,
"type": "word",
"position": 1
},
{
"token": "abc",
"start_offset": 12,
"end_offset": 15,
"type": "word",
"position": 2
},
{
"token": "com",
"start_offset": 16,
"end_offset": 19,
"type": "word",
"position": 3
},
{
"token": "any",
"start_offset": 20,
"end_offset": 23,
"type": "word",
"position": 4
},
{
"token": "path",
"start_offset": 24,
"end_offset": 28,
"type": "word",
"position": 5
},
{
"token": "param",
"start_offset": 29,
"end_offset": 34,
"type": "word",
"position": 6
},
{
"token": "1",
"start_offset": 35,
"end_offset": 36,
"type": "word",
"position": 7
},
{
"token": "so",
"start_offset": 37,
"end_offset": 39,
"type": "word",
"position": 8
},
{
"token": "me",
"start_offset": 40,
"end_offset": 42,
"type": "word",
"position": 9
},
{
"token": "param",
"start_offset": 43,
"end_offset": 48,
"type": "word",
"position": 10
},
{
"token": "2",
"start_offset": 49,
"end_offset": 50,
"type": "word",
"position": 11
},
{
"token": "other",
"start_offset": 51,
"end_offset": 56,
"type": "word",
"position": 12
},
{
"token": "title",
"start_offset": 57,
"end_offset": 62,
"type": "word",
"position": 13
}
]
}从结果看,基本符合预期。
4、char_group 优势及注意事项
4.1 char_group 优势
可总结为三条:高效、精准、可扩展。
高效:char_group 分词器不使用正则表达式,性能优于 pattern 分词器,适合大数据量场景。
精准:根据指定的字符进行分词,能够精确地拆分 URL 的各个组成部分。
可扩展:可以根据需要调整 tokenize_on_chars 中的字符,定制分词规则。
4.2 char_group 注意事项
如果需要更复杂的分词逻辑,例如基于特定模式的拆分,可以考虑使用 simple_pattern_split 分词器。
它比 pattern 分词器更高效,因为它使用了不支持回溯的简化正则表达式。
但在本文开篇提到的场景中,char_group 分词器已经足够满足需求。
由于 URL 中可能包含编码字符或特殊符号,我们可以根据实际情况调整分词字符集。
5、小结
没有方案或者网上搜不到方案,AI 不能提供具体方案的时候,可以挨个试一下已有方案,逐步找到适合自己业务场景的最佳方案。
使用 char_group 分词器能够在不增加集群压力的情况下,实现对完整 URL 的精准分词。该方案简单高效,适合处理大量数据。
更多推荐

更短时间更快习得更多干货!
和全球超2000+ Elastic 爱好者一起精进!
elastic6.cn------ElasticStack进阶助手

抢先一步学习进阶干货!