本文参照百战课堂
一、什么是Elasticsearch的集群
在单台ES服务器上,随着一个索引内数据的增多,会产生存储、效率、安全等问题。
-
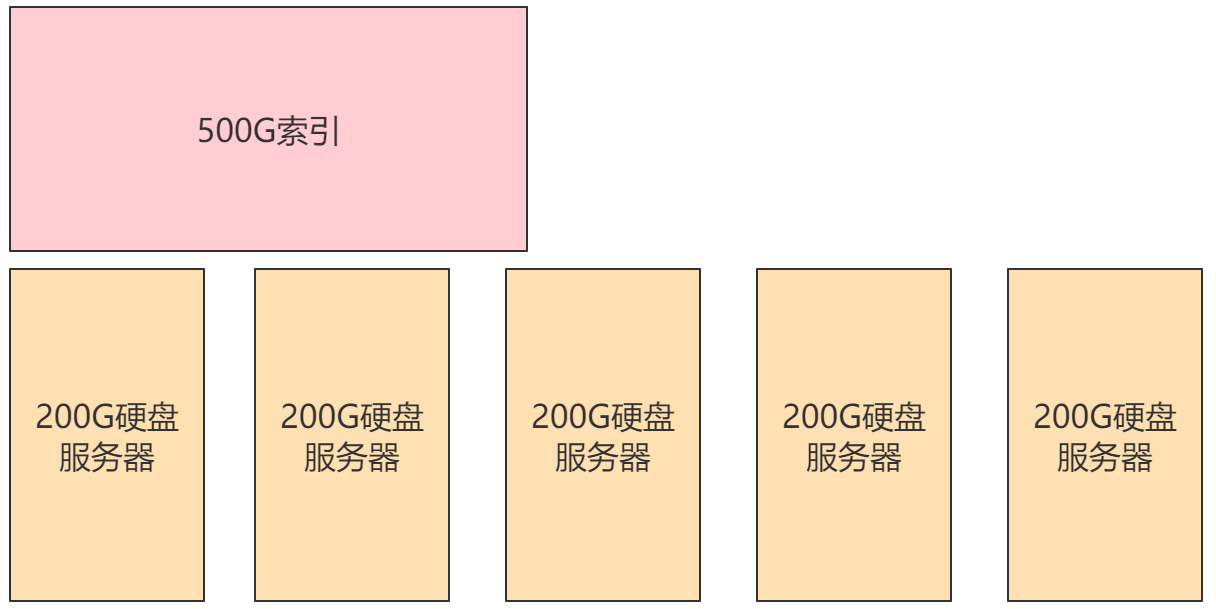
假设项目中有一个500G大小的索引,但我们只有几台200G硬盘的服务器,此时是不可能将索引放入其中某一台服务器中的。
-
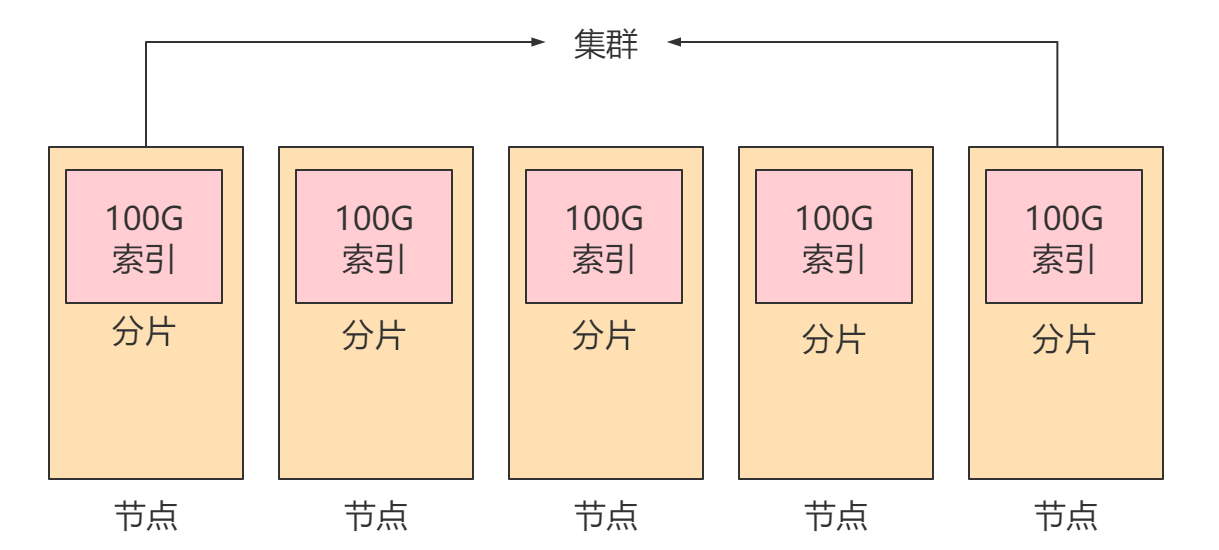
此时我们需要将索引拆分成多份,分别放入不同的服务器中,此时这几台服务器维护了同一个索引,我们称这几台服务器为一个集群,其中的每一台服务器为一个节点,每一台服务器中的数据称为一个分片。
-
此时如果某个节点故障,则会造成集群崩溃,所以每个节点的分片往往还会创建副本,存放在其他节点中,此时一个节点的崩溃就不会影响整个集群的正常运行。
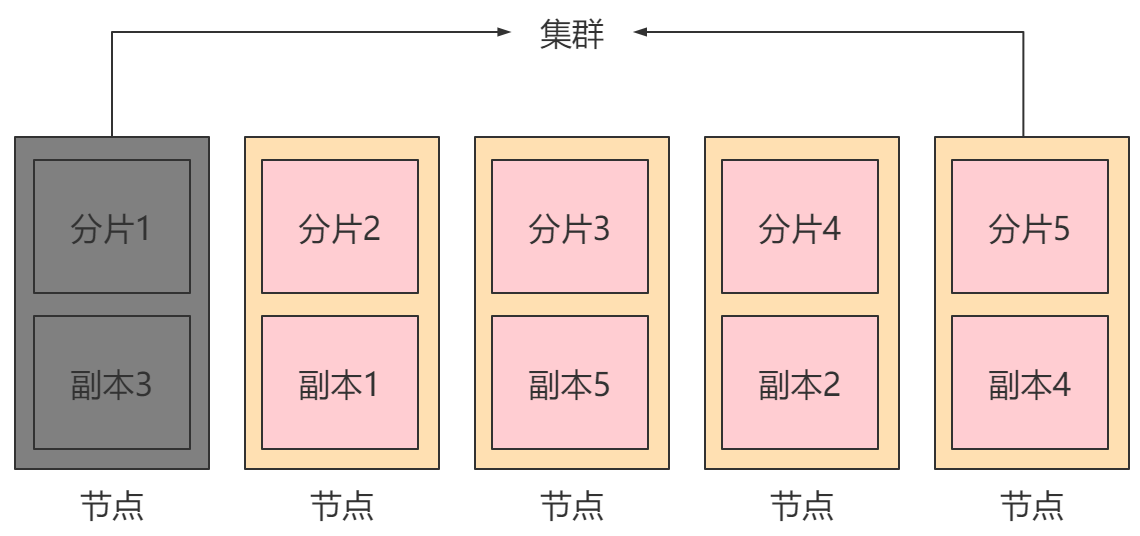
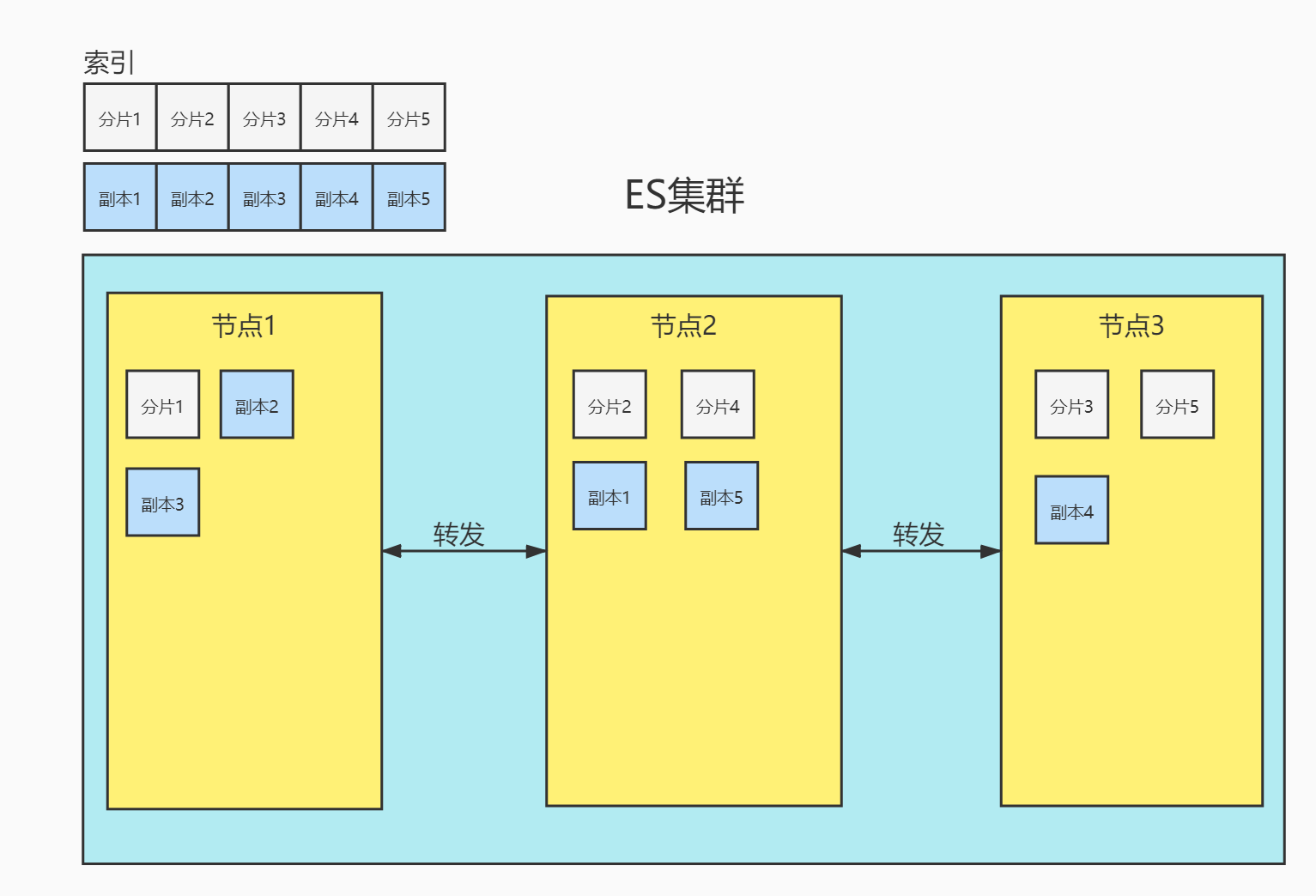
节点(node):一个节点是集群中的一台服务器,是集群的一部分。它存储数据,参与集群的索引和搜索功能。集群中有一个为主节点,主节点通过ES内部选举产生。
集群(cluster):一组节点组织在一起称为一个集群,它们共同持有整个的数据,并一起提供索引和搜索功能。
分片(shards):ES可以把完整的索引分成多个分片,分别存储在不同的节点上。
副本(replicas):ES可以为每个分片创建副本,提高查询效率,保证在分片数据丢失后的恢复。
注:
分片的数量只能在索引创建时指定,索引创建后不能再更改分片数量,但可以改变副本的数量。
为保证节点发生故障后集群的正常运行,ES不会将某个分片和它的副本存在同一台节点上。
二、集群的搭建
在安装elasticsearch服务时一定要做的准备工作
#关闭防火墙:
systemctl stop firewalld.service
#禁止防火墙自启动:
systemctl disable firewalld.service
#打开系统文件:
vim /etc/sysctl.conf
#添加以下配置:
vm.max_map_count=655360
#配置生效:
sysctl -p由于ES不能以root用户运行,我们需要创建一个非root用户,此处创建一个名为es的用户:
#创建用户:
useradd es这里我的搭建就不搞多台服务器了,我把他们放在同一个服务器中,只不过端口不同。
(1)安装第一个节点
修改系统进程最大文件数
bash
#修改系统文件
vim /etc/security/limits.conf
#添加如下内容
es soft nofile 65535
es hard nofile 131072安装
bash
#解压:
tar -zxvf elasticsearch-8.10.4-linux-x86_64.tar.gz
#重命名:
mv elasticsearch-8.10.4 myes1
#移动文件夹:
mv myes1 /usr/local/
#安装ik分词器
unzip elasticsearch-analysis-ik-8.10.4.zip -d /usr/local/myes1/plugins/analysis-ik
#安装拼音分词器
unzip elasticsearch-analysis-pinyin-8.10.4.zip -d /usr/local/myes1/plugins/analysis-pinyin
#es用户取得该文件夹权限:
chown -R es:es /usr/local/myes1修改配置文件
bash
#打开节点一配置文件:
vim /usr/local/myes1/config/elasticsearch.yml
配置如下信息:
#集群名称,保证唯一
cluster.name: my_elasticsearch
#节点名称,必须不一样
node.name: node1
#可以访问该节点的ip地址
network.host: 0.0.0.0
#该节点服务端口号
http.port: 9200
#集群间通信端口号
transport.port: 9300
#候选主节点的设备地址
discovery.seed_hosts: ["127.0.0.1:9300","127.0.0.1:9301","127.0.0.1:9302"]
#候选主节点的节点名
cluster.initial_master_nodes: ["node1","node2","node3"]
#关闭安全认证
xpack.security.enabled: false启动
bash
#切换为es用户:
su es
#后台启动第一个节点:
ES_JAVA_OPTS="-Xms512m -Xmx512m" /usr/local/myes1/bin/elasticsearch -d(2)安装第二个节点
bash
#解压:
tar -zxvf elasticsearch-8.10.4-linux-x86_64.tar.gz
#重命名:
mv elasticsearch-8.10.4 myes2
#移动文件夹:
mv myes2 /usr/local/
#安装ik分词器
unzip elasticsearch-analysis-ik-8.10.4.zip -d /usr/local/myes2/plugins/analysis-ik
#安装拼音分词器
unzip elasticsearch-analysis-pinyin-8.10.4.zip -d /usr/local/myes2/plugins/analysis-pinyin
#es用户取得该文件夹权限:
chown -R es:es /usr/local/myes2修改配置文件
bash
#打开节点二配置文件:
vim /usr/local/myes2/config/elasticsearch.yml
配置信息:
#集群名称,保证唯一
cluster.name: my_elasticsearch
#节点名称,必须不一样
node.name: node2
#可以访问该节点的ip地址
network.host: 0.0.0.0
#该节点服务端口号
http.port: 9201
#集群间通信端口号
transport.port: 9301
#候选主节点的设备地址
discovery.seed_hosts: ["127.0.0.1:9300","127.0.0.1:9301","127.0.0.1:9302"]
#候选主节点的节点名
cluster.initial_master_nodes: ["node1","node2","node3"]
#关闭安全认证
xpack.security.enabled: false启动
bash
#切换为es用户:
su es
#后台启动第二个节点:
ES_JAVA_OPTS="-Xms512m -Xmx512m" /usr/local/myes2/bin/elasticsearch -d(3)安装第三个节点
bash
#解压:
tar -zxvf elasticsearch-8.10.4-linux-x86_64.tar.gz
#重命名:
mv elasticsearch-8.10.4 myes3
#移动文件夹:
mv myes3 /usr/local/
#安装ik分词器
unzip elasticsearch-analysis-ik-8.10.4.zip -d /usr/local/myes3/plugins/analysis-ik
#安装拼音分词器
unzip elasticsearch-analysis-pinyin-8.10.4.zip -d /usr/local/myes3/plugins/analysis-pinyin
#es用户取得该文件夹权限:
chown -R es:es /usr/local/myes3修改配置文件
bash
#打开节点一配置文件:
vim /usr/local/myes3/config/elasticsearch.yml
配置信息如下:
#集群名称,保证唯一
cluster.name: my_elasticsearch
#节点名称,必须不一样
node.name: node3
#可以访问该节点的ip地址
network.host: 0.0.0.0
#该节点服务端口号
http.port: 9202
#集群间通信端口号
transport.port: 9302
#候选主节点的设备地址
discovery.seed_hosts: ["127.0.0.1:9300","127.0.0.1:9301","127.0.0.1:9302"]
#候选主节点的节点名
cluster.initial_master_nodes: ["node1","node2","node3"]
#关闭安全认证
xpack.security.enabled: false启动
bash
#切换为es用户:
su es
#后台启动第三个节点:
ES_JAVA_OPTS="-Xms512m -Xmx512m" /usr/local/myes3/bin/elasticsearch -d测试集群
访问http://虚拟机IP:9200/_cat/nodes查看集群是否搭建成功。
(4)使用Kibana连接集群
解压安装不必多说了
然后
bash
# 打开kibana配置文件
vim /usr/local/kibana-8.10.4/config/kibana.yml添加如下配置
bash
# 主机IP,服务名
server.host: "虚拟机IP"
server.name: "kibana"
# 该集群的所有节点
elasticsearch.hosts: ["http://127.0.0.1:9200","http://127.0.0.1:9201","http://127.0.0.1:9202"]启动kibana
bash
#切换为es用户:
su es
#启动kibana:
cd /usr/local/kibana-8.10.4/bin
./kibana