一、什么是对象储存
对象存储(Object Storage)以对象的形式存储和管理数据,这些对象可以是任何类型的数据,例如 PDF,视频,音频,文本或其他文件类型。对象存储使用分布式存储架构,数据在多个节点上进行备份,以保障数据可靠性和持久性。
一般的传统存储方式分为三种:
1、直连式存储
即直接连接计算机,比如固态硬盘,机械硬盘,光盘驱动器这类直接和计算机相连的存储设备。这种方式可以将多个磁盘合并成同一个逻辑磁盘,存储容量大,也易于配置和管理,且费用较低。但因存储系统没有统一管理方案,后期的数据维护,备份也会很麻烦,所以一般企业级不会选择这种存储方式。
2、网络附属存储
可以将网络附属存储当作一种文件专用的存储设备,比如企业内部的 NAS 设备,这是企业专供员工处理数据存储和文件共享的服务器。
3、存储区域网络
传统上,因为连接到服务器的存储设备数量存在限制,所以存储容量也会存在上限。存储区域网络(SAN)进一步引入了网络的灵活性,将多台服务器共享一个公共存储池,消除了带宽瓶颈,又因为多服务器的特点消除了单点故障,提高了存储的可靠性和可用性。该方案成本较高,只适用于存储量比较大的应用场景。
直连式存储被称为"文件存储",网络附属存储和存储区域网络被称为"块存储"。无论是文件存储,块存储还是对象存储,底层的硬件介质都是硬盘,但存储架构完全不同。
在云原生环境下,对象存储因为高性能,高可用的特性被广泛用于云存储,大数据分析,备份和恢复,多媒体内容存储等场景。如今云厂商提供非常成熟的对象存储服务,例如 Amazon S3, 阿里云(Object Storage Service, OSS),基础设施中的对象存储成为构建各类应用必不可少的一环,我们理应对它有更清晰的认知,这也是作为工程师构建稳定可靠应用不可缺少的。
二、S3 协议
S3 协议全称 Amazon Simple Storage Service(Amazon S3),最初是亚马逊提供的简单存储服务,它为应用程序的开发者提供了通过一系列 API 来控制数据的方式,经过多年的发展这些方法逐渐演变为 S3 协议,国内外很多云厂商提供的云存储服务都是在此协议上做了一部分演变,但都保留了通用的 S3 接口。
MinIO 是一个高性能,兼容 S3 的对象存储,它可以在任何云或本地基础架构上运行。MinIO 现在已经成为业界部署范围最广的对象存储设施,从云计算到边缘计算,从公有云到 AI 数据基础设施都有它的身影。
S3 中包含两个基础概念:Bucket 和 Object。
Bucket
亚马逊将存储系统中的一个命名空间当作一个 Bucket,在这个命名空间下你可以放任意文件,二进制文件,PDF,MP3,PNG,Doc......有点类似操作系统中 "文件夹" 的概念,对于存储系统来说它并不关心你存放的是什么类型的文件,它在乎的是你将这些文件放在哪个 "命名空间下",即哪个 Bucket 下。
为了保证不产生歧义,在一个对象存储系统里面所有的 Bucket 都必须是唯一,同时创建这个 Bucket 的权限不可转移,如果是在云对象存储中则不能从一个 Region 转到另一个 Region。
Bucket 就像 Linux 中的根目录,在对象存储系统中,一个 Bucket 像是一个根目录,所有对象都必须要保存在某一个 Bucket 下。
Object
Bucket 里面存储的对象就是 Object,由对象名 (Key) 和数据 (Value) 组成。
下例 MinIO 示例中可以看到,如果想要分享一个对象文件,MinIO 会生成出一长串的 Link,它的链接是:http://#domain/bucket/file?CheckCode 这种方式类似于模拟文件文件夹的层级结构,从某一域名到某个命名空间再到某个存储对象,给这个链接添加一定时期的有效期。
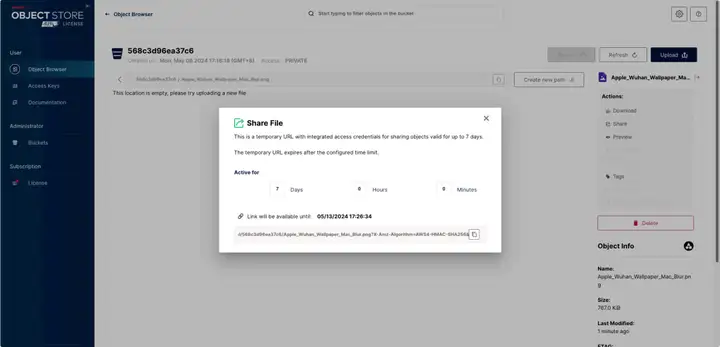
MinIO 还会存储对象文件一些元数据,上图右下角中 Object Info 包含了对象的文件类型,创建时间,加密算法以及用户上传时添加的一部分元信息。这些元信息在对象文件创建后是无法更改的。一般情况下云厂商会根据用户选择不同规格的云存储提供不同的资源限制,但在 MinIO 源码中最大单个对象的大小是 5 TB,最小则是 5 Byte,并且没有文件数量的限制。
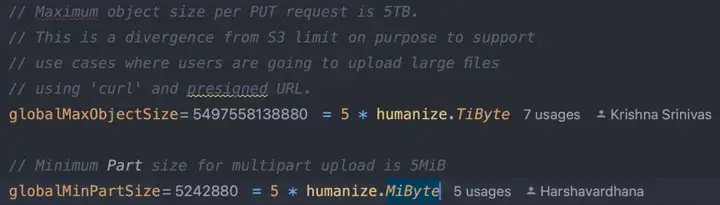
MinIO 还提供 Tag(标签)为对象做一些拓展功能,例如可以为一部分对象指定特殊的 Tag,通过这些 Tag 可以配合权限管理实现颗粒度更细的管理。也可以通过 Tag 对对象进行生命周期的控制,比如定时删除一批带有一个 Tag 的对象文件......
Minio 存储是如何实现的?
试想,设计一个存储服务需要包含哪些功能?经验丰富的架构师可能只从 "存储" 这个关键词就能罗列出一堆相关需求:从最基础的文件上传 / 下载到用户访问文件的权限校验,复杂一点的可能会包含文件的搜索,日志记录,多租户的管理,文件的安全......更复杂的可能会涉及到分布式的存储,磁盘写入,备份,加密等。
当我们将视野无限拔高就会发现实现一个安全可靠,高性能的分布式存储系统并不容易。同时秉承着技术人员的天然直觉,脑海里又会产生怀疑:"对象存储是否真的能做到官网上宣传的那样高性能?如果完全符合,那它是如何实现的?"
让我们从最基础的文件上传 / 下载开始。当客户端发起一个 HTTP 请求,文件随着 HTTP 协议中的 Body 体的二进制流传递到服务端,那么应该如何处理这些二进制流?最简单的方式就是,服务端在宿主机上创建出一个文件,然后将这些文件流写入到这个文件。同样的,如果用户需要下载文件,服务端会从服务器某个文件夹中找到这个文件并复制它的文件流,再传递给客户端。
通常情况下,为了方便管理用户上传的文件,服务端为用户创建各自的文件夹存放文件。如果有文件分类的要求,那么访问文件很有可能变成:http://#domain/文件目录1/子目录1/子子目录1//file.png
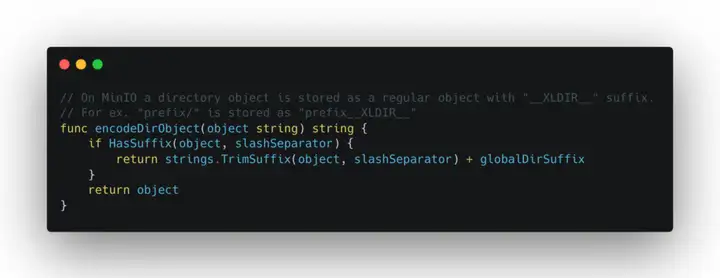
为了避免存入无限嵌套的文件夹元信息,Minio 直接使用 "prefix_XLDIR_" 这样的方式来代替文件的层级关系,比如 http://#domain/文件目录1/子目录1/子子目录1//file.png 就会变成 文件目录1%子目录1%子子目录1%$$%file%XLDIR% 一个对象。在对象存储中没有文件系统中的层级结构,而是采用 "平铺" 的方式将对象(Object)存入某一个 Bucket 中。这样做的好处有两点:
1、对于操作系统而言,无需保存无上限的文件夹元数据,也不会在访问文件时需要一层一层打开文件夹,产生额外的开销。
2、对于 Minio 而言,它不使用外部数据库来存储这些文件夹的元数据,而是直接将元数据以明文的方式存储在一个文件中,并将这个文件与数据文件存储在磁盘上。这意味着对任何对象的操作都会直接反映在元数据文件中,从而实现强一致性。(如果使用外部数据库存储这些信息,那么可能会进一步引发'分布式一致性'问题)
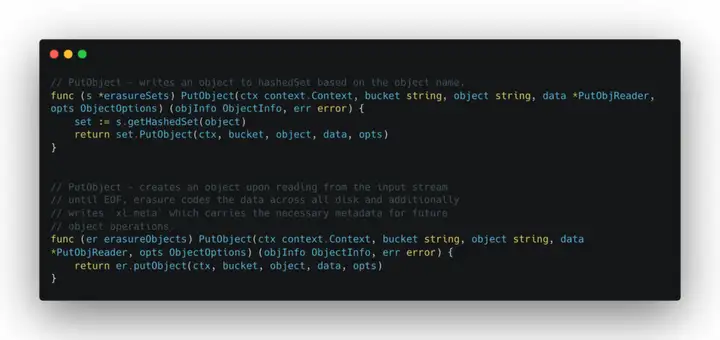
Minio 在对对象文件夹进行编码后,会使用 getHashedSet 函数计算对象的哈希值 Set,对象最终是存储在 Set 上,一个 Set 是一组 Drive 的集合,为了方便理解可以暂时将 Drive 视为一个硬盘。
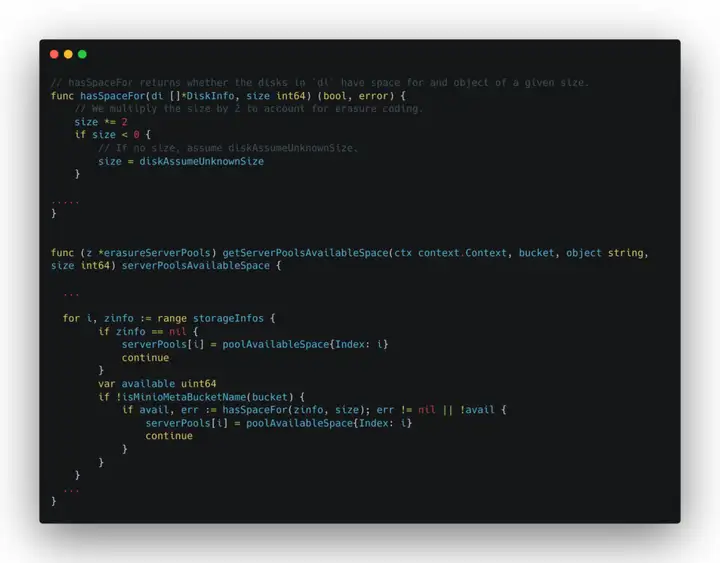
在过去的提交记录中,将对象文件写入磁盘信息前,Minio 会先判断磁盘是否能容纳对象两倍大小的空间,这是因为分布式存储需要写副本,需要一定空间的冗余。在最近的提交记录中我们可以发现 Minio 移除了这一逻辑,转而在 serverPools 初始化时计算可分配空间。
三、纠删码算法
在《设计数据密集型应用》一书中提到:一旦拥有很多机器,硬盘崩溃,内存出错,机房断电......这些硬件故障导致系统失效的事情总有一天会发生。从数学期望的角度来预估,拥有一万个硬盘的存储集群上,平均每天会有一个磁盘出故障。
但为了保障数据的安全,最简单的方式就是进行冗余存储,将一份数据拷贝多份存放在不同地区的数据中心;在物理层面上也是相同的逻辑,即增加硬盘的冗余度来减少系统的故障率。分布式存储一般使用奇数数量来校验一致性,当一个 1 GB 大小的文件存储在硬盘上,为了保证它的安全,存储服务将这个文件拷贝了三份存放在了三块不同的硬盘上。如果三份数据中某一份数据发生损坏,程序会以其中相同的那两份数据为准。
当然这样也会衍生出新的问题:硬盘资源的浪费。
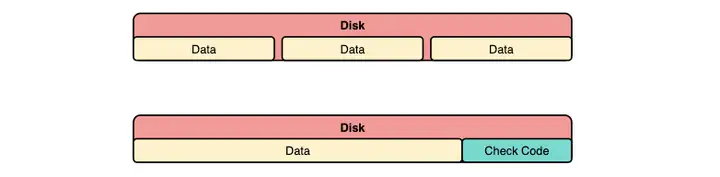
Minio 使用 Reed-Solomon Code 将对象拆分成 N/2 数据和 N/2 奇偶校验块,如果拥有 6 块盘那么一个对象将会拆分成 3 个数据块,3 个奇偶校验块,可以丢失任意 3 块盘,Minio 依然可以从剩下的 3 块盘进行数据恢复。
可见纠删码不止可以降低存储冗余,还是一种恢复丢失和损坏数据的算法技术。
汉明码
Known as a Hamming code 是最早出现的纠错码之一,原本它的目的是为了定位在穿孔卡片计算机中进行运算的 bits 读取错误。
假设我们现在拥有一个 16 bits 大小的块,实际存储的数据只占其中的 11 bits,剩下 5 bits 作为冗余保留。第一位 bit 为奇偶校验的特殊位,如果块中的 1 的总数是奇数,则将这个比特位翻转成 1 ,从而使 1 的总数为偶数。如果块中 1 的总数是偶数,则保持不变。
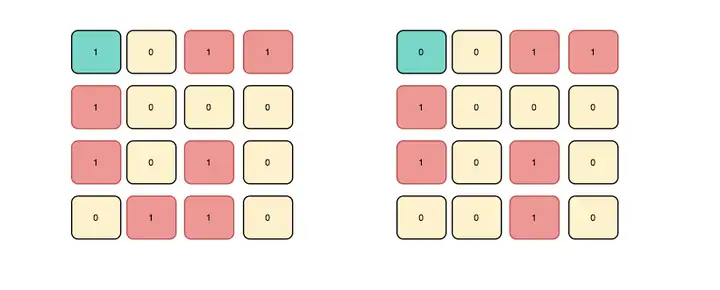
当这个数据块发生变化时,无论是从 0 变为 1 ,还是从 1 变为 0 ,都会导致 1 的数量从偶数变为奇数,这样很容易地就能知道这个数据块中存在错误。但是要注意,如果数据块出现偶数次错误,比如 2,4,6......处错误,那么就无法判断这个数据块是否存在错误。
为了解决这个问题,汉明码使用 4 个比特位来做控制,同时对其中的特殊子集做交叉比对,比如每次只对其中 8 个比特位进行奇偶校验,通过多次对比就能进一步查出错误数据。
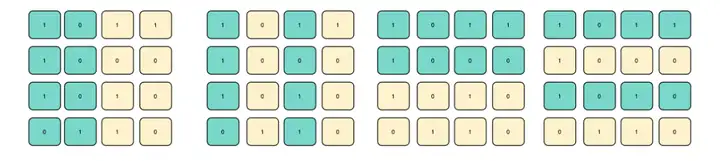
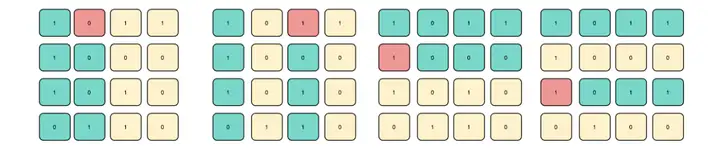
汉明码的 4 位控制位(红色标记),通过每次比对并矫正特殊位便可以将错误信息修复。
Reed-Solomon Code
现代存储系统中常用 Reed-Solomon 作为纠删码,它比汉明码要更加复杂。以 4+2(M+N)冗余比作为例子,Reed-Solomon 会先创建出一个编码矩阵,它的创建规则是:按照冗余比,前 M 行相同,后 N 为冗余数据。
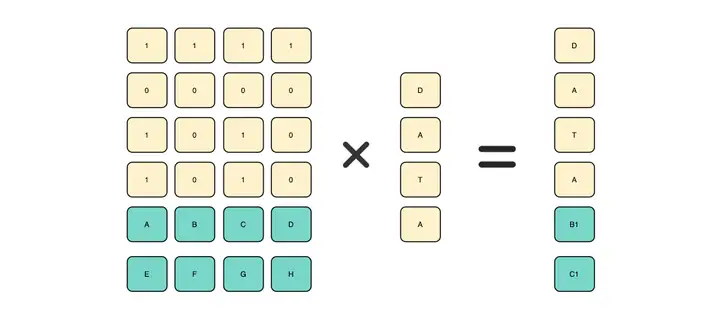
如上图所示,将编码矩阵与数据矩阵相乘,我们可以得到一个编码后的数据矩阵,这就是最终会落盘到硬盘上的数据。不需要将数据多副本备份,纠删码可以拥有更高的磁盘利用率。
假设丢失了其中的两块数据,例如将 DATA 丢失两位,变为 DA ,那么应该如何将它恢复成原数据?
1、先删除丢失的行,无论是编码矩阵还是数据矩阵
2、然后根据编码矩阵,计算出逆矩阵

公式出自:逆矩阵的概念、应用和求解
(https://blog.csdn.net/hlzgood/article/details/110880823)
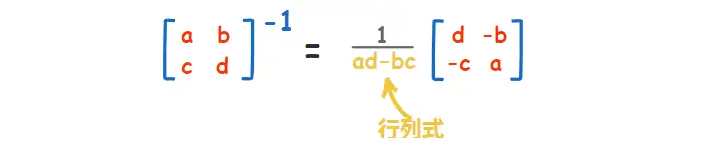
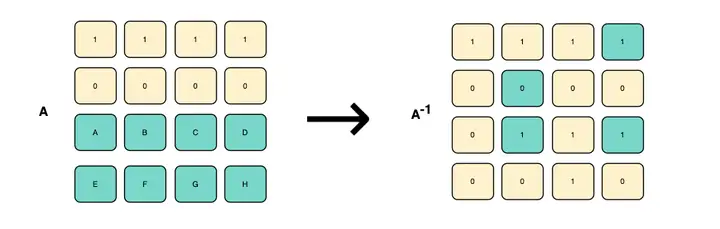
3、根据数据矩阵公式,将现有数据矩阵乘逆矩阵则可得原数据

四、总结
本章我们主要讨论了对象存储和传统文件系统的区别,通过 Minio 我们对 S3 协议有了更深入的了解,对 Minio 源码进行了简要分析并对其中一部分设计进行了解释。当然,想在一篇文章中详尽展示对象存储的各个方面是不现实的,本篇更多的还是聚焦于存储层的具体实现,对于数学领域逆矩阵的概念感兴趣的读者可以自行了解。
对 Minio 有兴趣的读者,如果可以建议阅读一下 Minio 的源码(https://github.com/minio/minio)。
学习资料:
1.《Minio 源码解析 - 存储层实现》
2.汉明码如何克服噪声(https://www.bilibili.com/video/BV1WK411N7kz/?spm_id_from=333.999.0.0)
3.http://cloud.tencent.com/developer/article/2353439
4.http://cloud.tencent.com/developer/article/1919463
5.http://aws.amazon.com/cn/s3/features/
6.http://zhuanlan.zhihu.com/p/670386960
8.http://www.abelsun.tech/arch/minio/minio-erasure-code.html
9.http://zh.wikipedia.org/wiki/%E9%80%86%E7%9F%A9%E9%98%B5
作者:王凯| 后端开发工程师