时序数据库 TDengine 的学习和使用经验
-
- [什么是 TDengine ?](#什么是 TDengine ?)
- [什么是时序数据 ?](#什么是时序数据 ?)
- 使用RPM安装包部署
- [TDengine 使用](#TDengine 使用)
-
- [TDengine 命令行(CLI)](#TDengine 命令行(CLI))
- taosBenchmark
- 服务器内存需求
- 删库跑路测试
- 使用体验
- 文档纠错
什么是 TDengine ?
TDengine 核心是一款高性能、集群开源、云原生的时序数据库 (Time Series Database,TSDB),专为物联网IoT平台、工业互联网、电力、IT 运维等场景设计并优化,具有极强的弹性伸缩能力。同时它还带有内建的缓存、流式计算、数据订阅等系统功能,能大幅减少系统设计的复杂度,降低研发和运营成本,是一个高性能、分布式的物联网IoT、工业大数据平台。
GitHub 社区:https://github.com/taosdata/TDengine
什么是时序数据 ?
时序数据,即时间序列数据(Time-Series Data),是一组按照时间发生先后顺序进行排列的序列数据。日常生活中,设备、传感器采集的数据,证券交易的记录都是时序数据。这些时序数据是周期、准周期产生的,或事件触发产生的,有的采集频率高,有的采集频率低。一般被发送至服务器中进行汇总并进行实时分析和处理,对系统的运行做出实时监测或预警,对股市行情进行预测。这些数据也可以被长期保存下来,用以进行离线数据分析。
时序数据的十大特征:
- 数据是时序的,一定带有时间戳
- 数据是结构化的
- 一个数据采集点就是一个数据流
- 数据较少有更新删除操作
- 数据不依赖于事务
- 相对互联网应用,写多读少
- 用户关注的是一段时间的趋势
- 数据是有保留期限的
- 需要实时分析计算操作
- 流量平稳、可预测
使用RPM安装包部署
硬件环境:
sql
[root@vdb ~]# cat /etc/redhat-release
CentOS Linux release 7.9.2009 (Core)
[root@vdb ~]# uname -a
Linux vdb 3.10.0-1160.el7.x86_64 #1 SMP Mon Oct 19 16:18:59 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux
[root@vdb ~]# ll TDengine-server-3.3.2.0-Linux-x64.rpm
-rw-r--r-- 1 root root 67616512 Sep 15 11:00 TDengine-server-3.3.2.0-Linux-x64.rpm安装
sql
[root@vdb ~]# rpm -ivh TDengine-server-3.3.2.0-Linux-x64.rpm
Preparing... ################################# [100%]
Updating / installing...
1:tdengine-3.3.2.0-3.el7 ################################# [100%]
Start to install TDengine...
System hostname is: vdb
Enter FQDN:port (like h1.taosdata.com:6030) of an existing TDengine cluster node to join
OR leave it blank to build one:
Enter your email address for priority support or enter empty to skip:
Created symlink from /etc/systemd/system/multi-user.target.wants/taosd.service to /etc/systemd/system/taosd.service.
To configure TDengine : edit /etc/taos/taos.cfg
To configure taosAdapter : edit /etc/taos/taosadapter.toml
To configure taos-explorer : edit /etc/taos/explorer.toml
To start TDengine server : sudo systemctl start taosd
To start taosAdapter : sudo systemctl start taosadapter
To start taoskeeper : sudo systemctl start taoskeeper
To start taos-explorer : sudo systemctl start taos-explorer
TDengine is installed successfully!
To start all the components : sudo start-all.sh
To access Commnd Line Interface : taos -h vdb
To access Graphic User Interface : http://vdb:6060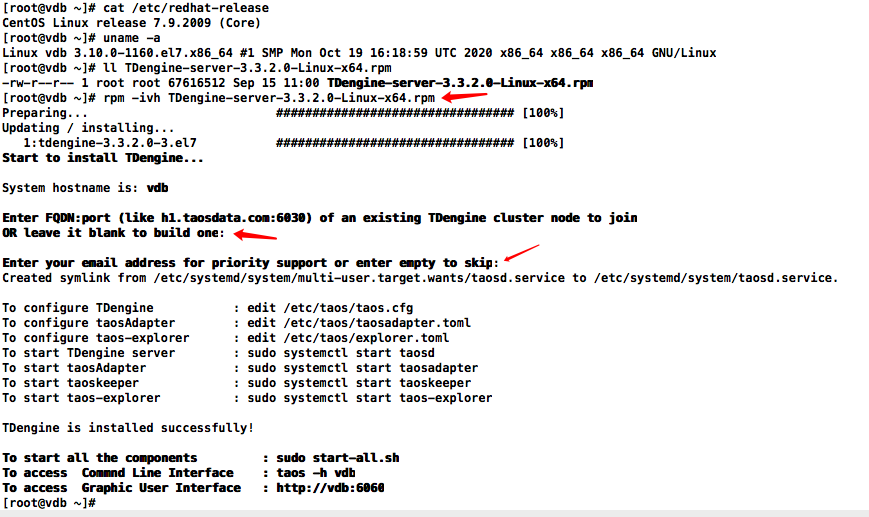
启动 TDengine 的服务进程
sql
systemctl start taosd
systemctl start taosadapter
systemctl start taoskeeper
systemctl start taos-explorer备注:systemctl stop taosd 指令在执行后并不会马上停止 TDengine 服务,而是会等待系统中必要的落盘工作正常完成。在数据量很大的情况下,这可能会消耗较长时间。
默认的网络端口
TDengine 的一些接口或组件的常用端口,这些端口均可以通过配置文件中的参数进行修改。
| 接口或组件 | 端口 |
|---|---|
| 原生接口(taosc) | 6030 |
| RESTful 接口 | 6041 |
| WebSocket 接口 | 6041 |
| taosKeeper | 6043 |
| taosX | 6050, 6055 |
| taosExplorer | 6060 |
TDengine 使用
TDengine 命令行(CLI)
客户端命令taos,语法特性跟MySQL有点类似
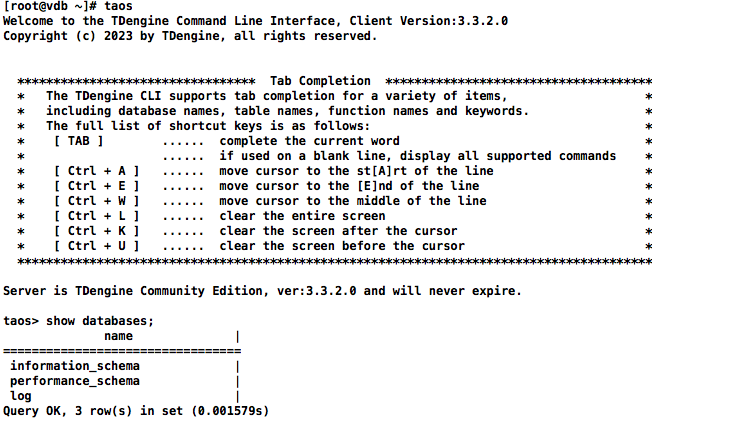
sql
[root@vdb ~]# taos
Welcome to the TDengine Command Line Interface, Client Version:3.3.2.0
Copyright (c) 2023 by TDengine, all rights reserved.
********************************* Tab Completion *************************************
* The TDengine CLI supports tab completion for a variety of items, *
* including database names, table names, function names and keywords. *
* The full list of shortcut keys is as follows: *
* [ TAB ] ...... complete the current word *
* ...... if used on a blank line, display all supported commands *
* [ Ctrl + A ] ...... move cursor to the st[A]rt of the line *
* [ Ctrl + E ] ...... move cursor to the [E]nd of the line *
* [ Ctrl + W ] ...... move cursor to the middle of the line *
* [ Ctrl + L ] ...... clear the entire screen *
* [ Ctrl + K ] ...... clear the screen after the cursor *
* [ Ctrl + U ] ...... clear the screen before the cursor *
****************************************************************************************
Server is TDengine Community Edition, ver:3.3.2.0 and will never expire.
taos> show databases;
name |
=================================
information_schema |
performance_schema |
log |
Query OK, 3 row(s) in set (0.001579s)
taos> CREATE DATABASE demo;
Create OK, 0 row(s) affected (0.173739s)
taos> use demo;
Database changed.
taos> CREATE TABLE t (ts TIMESTAMP, speed INT);
Create OK, 0 row(s) affected (0.002680s)
taos> INSERT INTO t VALUES ('2024-09-15 00:00:00', 10);
Insert OK, 1 row(s) affected (0.000937s)
taos> INSERT INTO t VALUES ('2014-09-15 01:00:00', 20);
DB error: Timestamp data out of range (0.000959s)
taos> INSERT INTO t VALUES ('2024-09-15 01:00:00', 20);
Insert OK, 1 row(s) affected (0.000789s)
taos> INSERT INTO t VALUES ('2024-09-15 00:00:00', 30);
Insert OK, 1 row(s) affected (0.000893s)
taos> INSERT INTO t VALUES ('2024-09-14 00:00:00', 40);
Insert OK, 1 row(s) affected (0.000929s)
taos> SELECT * FROM t;
ts | speed |
========================================
2024-09-14 00:00:00.000 | 40 |
2024-09-15 00:00:00.000 | 30 |
2024-09-15 01:00:00.000 | 20 |
Query OK, 3 row(s) in set (0.001628s)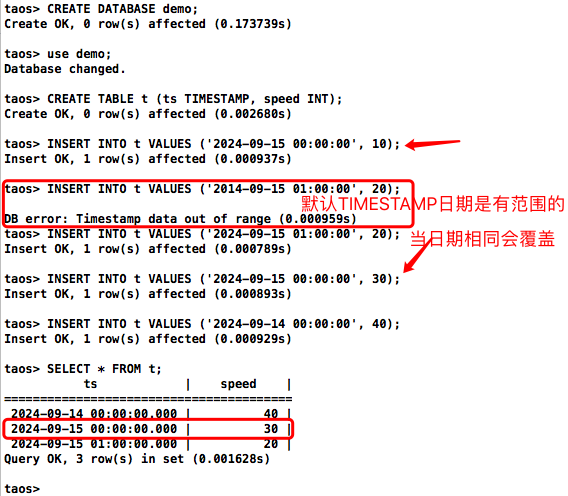
- 默认TIMESTAMP日期是有范围的
- 插入相同日期会直接做覆盖处理
taosBenchmark
taosBenchmark 是一个专为测试 TDengine 性能而设计的工具,它能够全面评估TDengine 在写入、查询和订阅等方面的功能表现。
sql
taosBenchmark -y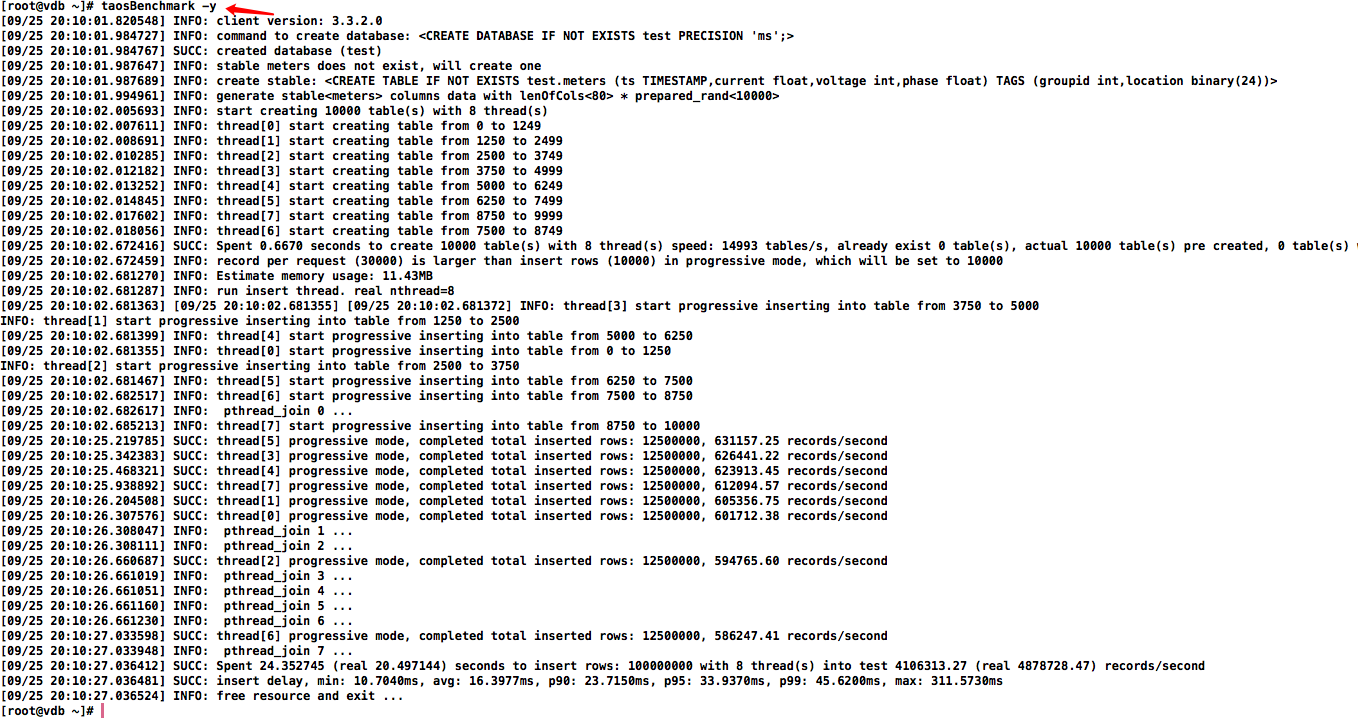
备注:非事务操作,中途中断(Cont+C)插入的数据不会回滚
系统将自动在数据库 test 下创建一张名为 meters的超级表。这张超级表将包含 10,000 张子表,表名从 d0 到 d9999,每张表包含 10,000条记录。每条记录包含 ts(时间戳)、current(电流)、voltage(电压)和 phase(相位)4个字段。时间戳范围从 "2017-07-14 10:40:00 000" 到 "2017-07-14 10:40:09 999"。每张表还带有 location 和 groupId 两个标签,其中,groupId 设置为 1 到 10,而 location 则设置为 California.Campbell、California.Cupertino 等城市信息。
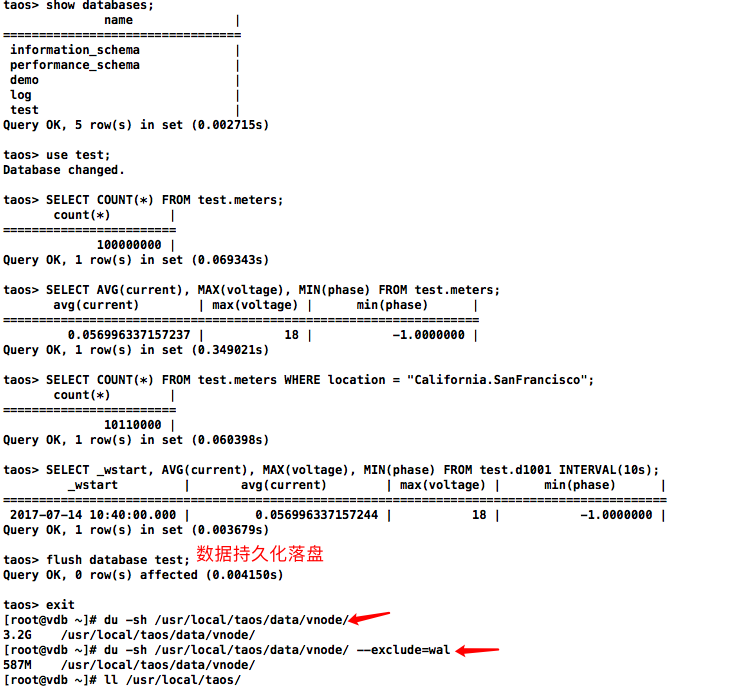
通过系统提供的伪列_wstart 来给出每个窗口的开始时间
备注:实际数据量占用不到590MB的磁盘空间
根据库vgroup_id查找对应数据目录下库对应的目录:
sql
show vgroups;
show vnodes;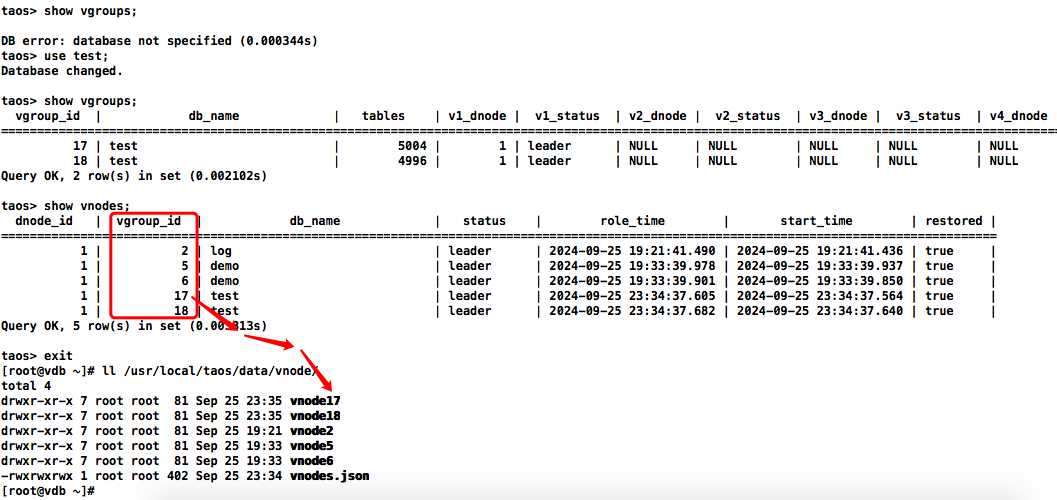
服务器内存需求
每个数据库能够创建固定数量的 vgroup,默认情况下为两个。在创建数据库时,可以通过 vgroups 参数指定 vgroup 的数量,而副本数则由 replica 参数确定。由于每个 vgroup 中的副本会对应一个 vnode,因此数据库所占用的内存计算方式:vgroups ×replica × (buffer + pages × pagesize + cachesize)
系统管理员可以通过如下 SQL 查看 information_schema 库中的 ins_vnodes 表来获得所有数据库所有 vnodes 在各个 dnode 上的分布。
sql
taos> select * from information_schema.ins_vnodes;
dnode_id | vgroup_id | db_name | status | role_time | start_time | restored |
==========================================================================================================================================
1 | 2 | log | leader | 2024-09-25 19:21:41.490 | 2024-09-25 19:21:41.436 | true |
1 | 5 | demo | leader | 2024-09-25 19:33:39.978 | 2024-09-25 19:33:39.937 | true |
1 | 6 | demo | leader | 2024-09-25 19:33:39.901 | 2024-09-25 19:33:39.850 | true |
1 | 11 | test | leader | 2024-09-25 20:10:01.895 | 2024-09-25 20:10:01.854 | true |
1 | 12 | test | leader | 2024-09-25 20:10:01.971 | 2024-09-25 20:10:01.930 | true |
Query OK, 5 row(s) in set (0.002143s)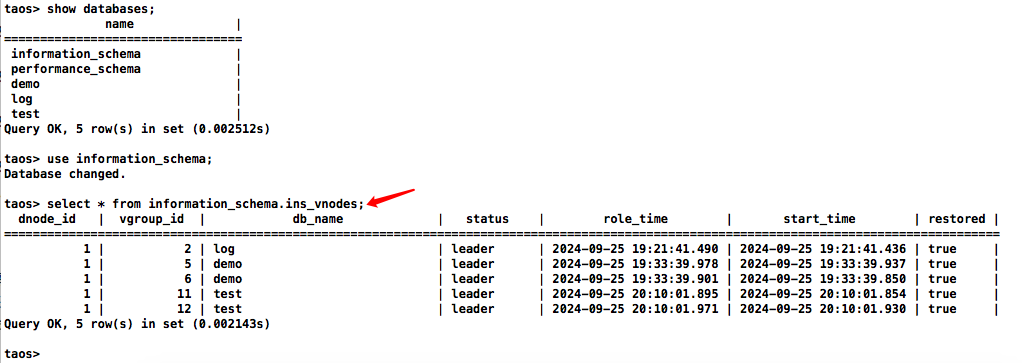
删库跑路测试
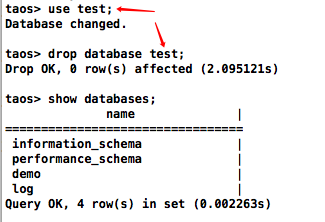
删库过程无需等待,即使有正在操作的会话也会被直接干掉
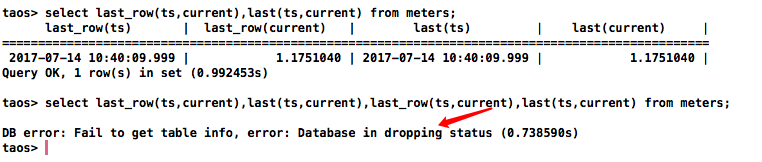
使用体验
- rpm安装体贴还是比较友好的,安装后会打印各个配置文件基本信息和操作命令
- 客户端命令taos,语法特性跟MySQL数据库有点像
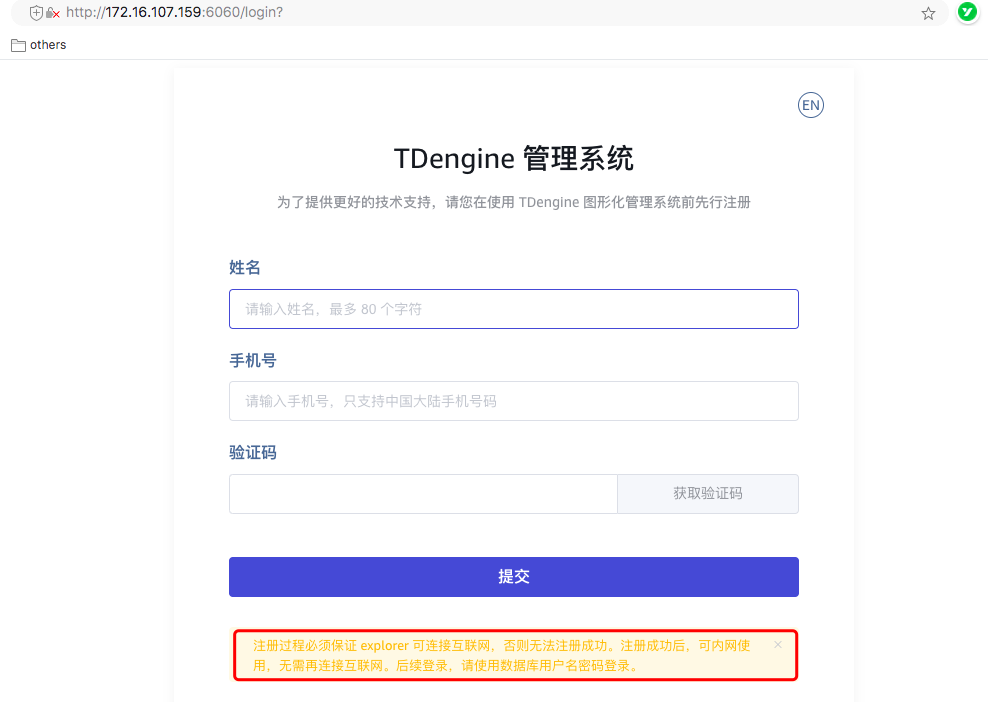
- 可视化组件---taosExplorer注册需要连接互联网,对完全内网环境不是很友好,这块是否可以考虑分开单独特供一个网页注册平台,使用taosExplorer可视化管理工具就不要连网注册了
文档纠错
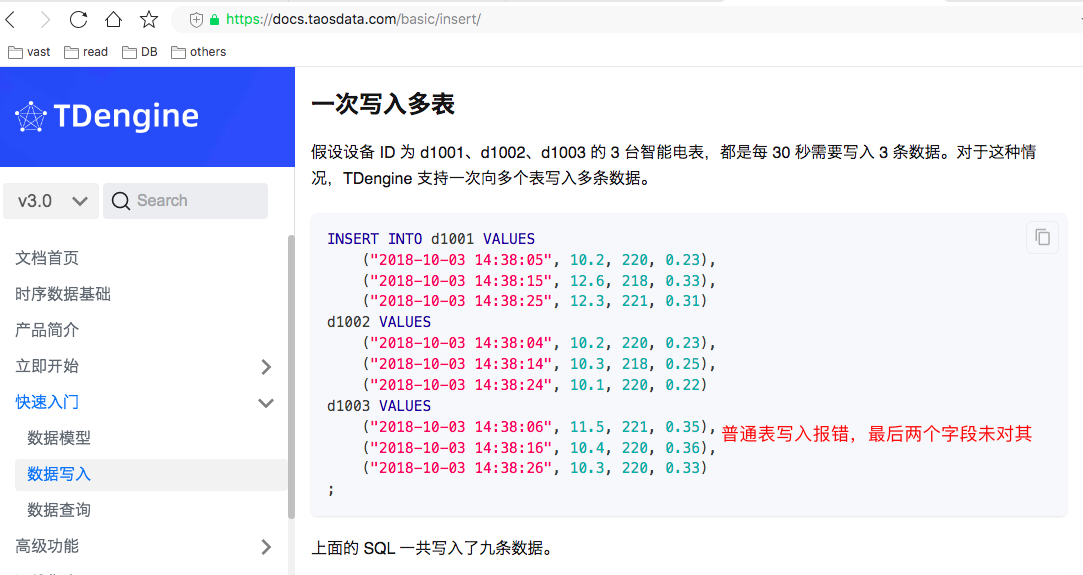
创建的d1003是普通表,且列未指定默认值,但后面插入数据时存在列缺少问题

d1003是普通表:
文档链接:https://docs.taosdata.com/basic/insert/
sql
# 错误SQL
INSERT INTO d1001 VALUES
("2018-10-03 14:38:05", 10.2, 220, 0.23),
("2018-10-03 14:38:15", 12.6, 218, 0.33),
("2018-10-03 14:38:25", 12.3, 221, 0.31)
d1002 VALUES
("2018-10-03 14:38:04", 10.2, 220, 0.23),
("2018-10-03 14:38:14", 10.3, 218, 0.25),
("2018-10-03 14:38:24", 10.1, 220, 0.22)
d1003 VALUES
("2018-10-03 14:38:06", 11.5, 221, 0.35),
("2018-10-03 14:38:16", 10.4, 220, 0.36),
("2018-10-03 14:38:26", 10.3, 220, 0.33)
;
# 更正写法一:补全d1003表插入所有列数据
INSERT INTO d1001 VALUES
("2018-10-03 14:38:05", 10.2, 220, 0.23),
("2018-10-03 14:38:15", 12.6, 218, 0.33),
("2018-10-03 14:38:25", 12.3, 221, 0.31)
d1002 VALUES
("2018-10-03 14:38:04", 10.2, 220, 0.23),
("2018-10-03 14:38:14", 10.3, 218, 0.25),
("2018-10-03 14:38:24", 10.1, 220, 0.22)
d1003 VALUES
("2018-10-03 14:38:06", 11.5, 221, 0.35, "California.SanFrancisco", 2),
("2018-10-03 14:38:16", 10.4, 220, 0.36, "California.SanFrancisco", 2),
("2018-10-03 14:38:26", 10.3, 220, 0.33, "California.SanFrancisco", 2)
;
# 更正写法二:指定表d1003插入列
INSERT INTO d1001 VALUES
("2018-10-03 14:38:05", 10.2, 220, 0.23),
("2018-10-03 14:38:15", 12.6, 218, 0.33),
("2018-10-03 14:38:25", 12.3, 221, 0.31)
d1002 VALUES
("2018-10-03 14:38:04", 10.2, 220, 0.23),
("2018-10-03 14:38:14", 10.3, 218, 0.25),
("2018-10-03 14:38:24", 10.1, 220, 0.22)
d1003(ts, current, voltage, phase) VALUES
("2018-10-03 14:38:06", 11.5, 221, 0.35),
("2018-10-03 14:38:16", 10.4, 220, 0.36),
("2018-10-03 14:38:26", 10.3, 220, 0.33)
;