消息存储
提到存储不得不说消息的读写,那么kafka他是如何读写数据的呢?
读取消息
1.通过debug(如何debug) 我们可以得到下面的调用栈,最终通过FileRecords来读取保存的数据
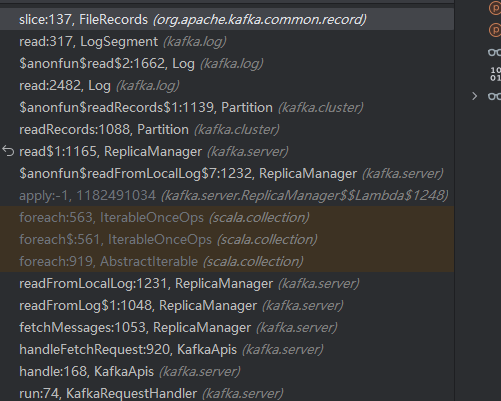
写入消息
1.通过debug(如何debug) 我们可以得到下面的调用栈,最终通过FileRecords来写入数据
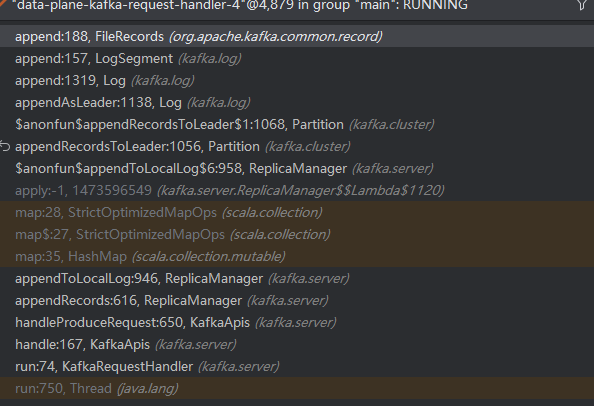
让我们来梳理一下大的调用链路
1.通过 ReplicaManager找到对应的Partition
2.通过 Partition找到 Log
3.通过Log找到 LogSegment
4.通过LogSegment来读写数据
FileRecords分析
FileRecords是具体与文件打交道 使用的是 Java的Nio FileChannel来进行读写数据的
分析一下 FileRecords的几个重要方法。
读方法如下
java
/**
* Return a slice of records from this instance, which is a view into this set starting from the given position
* and with the given size limit.
*
* If the size is beyond the end of the file, the end will be based on the size of the file at the time of the read.
*
* If this message set is already sliced, the position will be taken relative to that slicing.
*
* @param position The start position to begin the read from
* @param size The number of bytes after the start position to include
* @return A sliced wrapper on this message set limited based on the given position and size
*/
public FileRecords slice(int position, int size) throws IOException {
int availableBytes = availableBytes(position, size);
int startPosition = this.start + position;
return new FileRecords(file, channel, startPosition, startPosition + availableBytes, true);
}这个方法还是比较简单的,入参为要从哪里读 读几个字节的 还是比较好理解的 我们继续看他被谁调用了,他是被这个调用了的 kafka.log.LogSegment#read,我们来看debug。
这个是我的consumer 他已经消费了7条,他下次继续拉取消息会带上这个偏移量7条为起始偏移量。
我们继续来看 他是如何通过偏移量来拉取数据的?

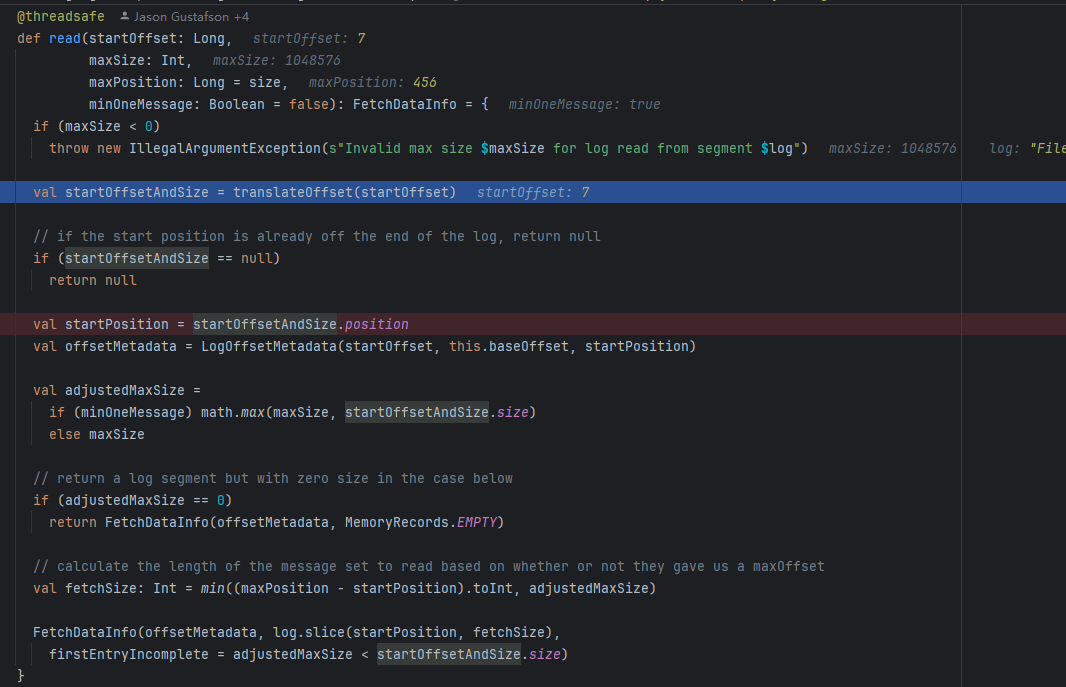
如何通过偏移量来拉取数据的?
scala
/**
* Find the physical file position for the first message with offset >= the requested offset.
*
* The startingFilePosition argument is an optimization that can be used if we already know a valid starting position
* in the file higher than the greatest-lower-bound from the index.
*
* @param offset The offset we want to translate
* @param startingFilePosition A lower bound on the file position from which to begin the search. This is purely an optimization and
* when omitted, the search will begin at the position in the offset index.
* @return The position in the log storing the message with the least offset >= the requested offset and the size of the
* message or null if no message meets this criteria.
*/
@threadsafe
private[log] def translateOffset(offset: Long, startingFilePosition: Int = 0): LogOffsetPosition = {
//通过索引 来进行二分查找找到偏移量的真实log文件当中的物理偏移
val mapping = offsetIndex.lookup(offset)
//构造需要拉取的数据的起始物理地址和 具体要拉多少数据
log.searchForOffsetWithSize(offset, max(mapping.position, startingFilePosition))
}可以看到最终构造了这样一个 对象
java
public static class LogOffsetPosition {
//最开始的偏移量
public final long offset;
//物理偏移量
public final int position;
//要拉取的字节数
public final int size;
} 
我们再来看一下 fetchSize的计算规则
scala
最大拉取字节数的限制
val adjustedMaxSize =
if (minOneMessage) math.max(maxSize, startOffsetAndSize.size)
maxPosition 这个是日志文件最大的物理偏移量,而这个startPosition使我们刚才通过二分查找找到的起始物理地址
他这个一看就很明白 不能超过文件的所存储的范围。这个相减就是能读取到的最大字节数据大小
val fetchSize: Int = min((maxPosition - startPosition).toInt, adjustedMaxSize)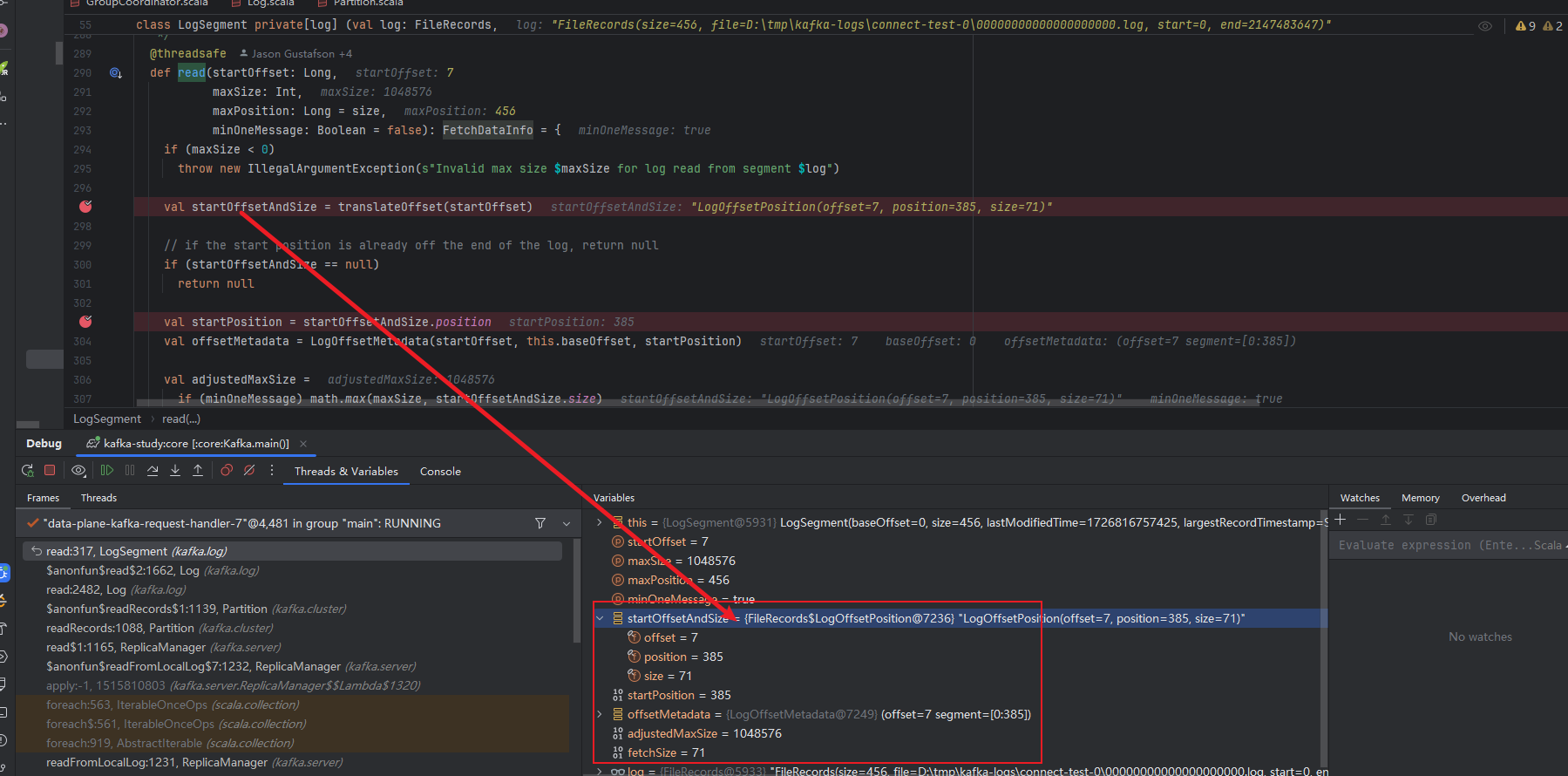
写方法如下
java
/**
* Append a set of records to the file. This method is not thread-safe and must be
* protected with a lock.
*
* @param records The records to append
* @return the number of bytes written to the underlying file
*/
public int append(MemoryRecords records) throws IOException {
if (records.sizeInBytes() > Integer.MAX_VALUE - size.get())
throw new IllegalArgumentException("Append of size " + records.sizeInBytes() +
" bytes is too large for segment with current file position at " + size.get());
int written = records.writeFullyTo(channel);
size.getAndAdd(written);
return written;
}可以看到几个重要信息
1.当前kafka日志文件
2.日志文件的大小 已经写入了1869个字节
3.日志文件的范围 start为起始偏移量 end为最大偏移量
他这个是要将MemoryRecords当中的buffer里面的字节全都写入到文件当中
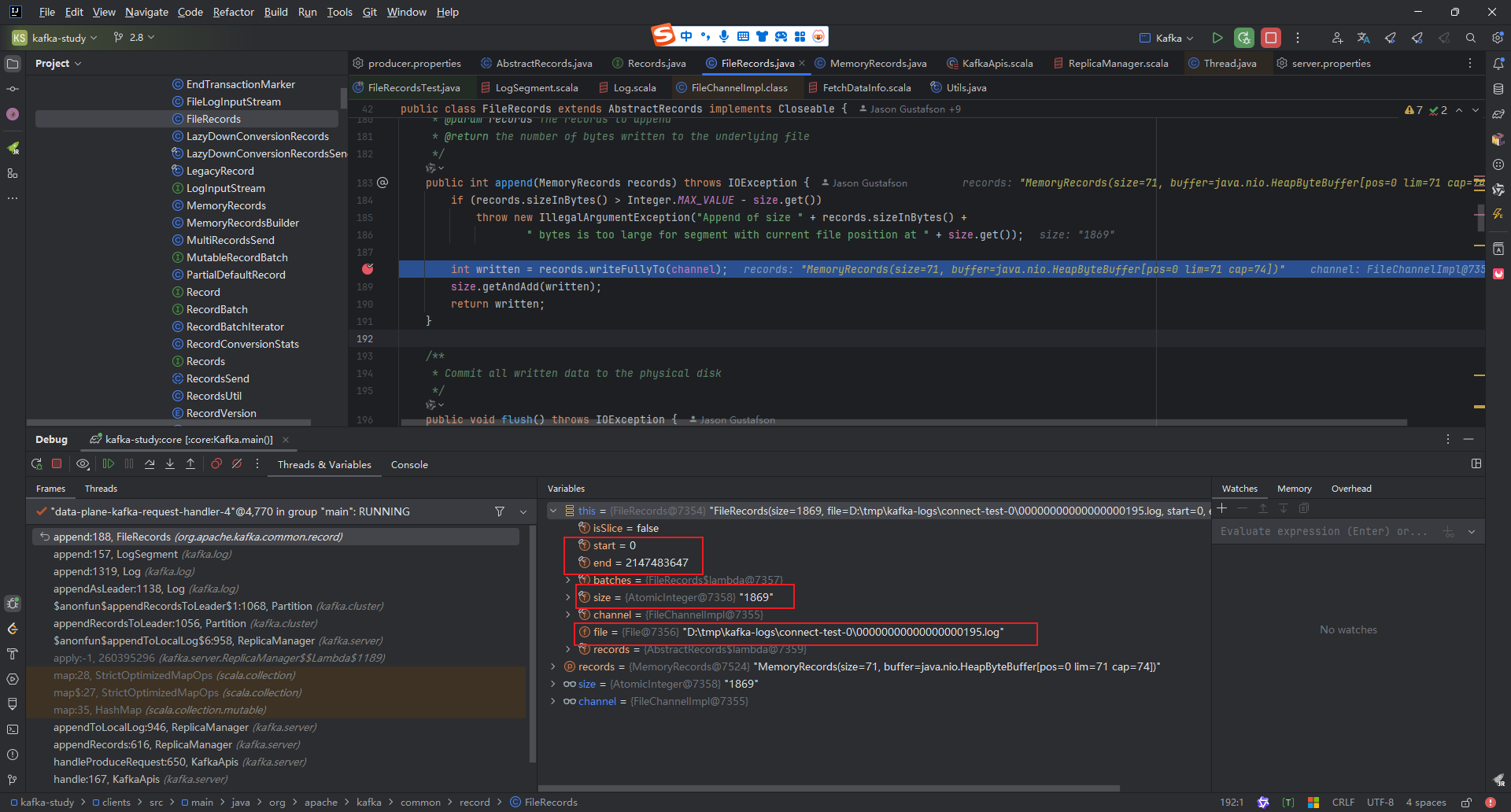
推送消息(将消息发送给消费者或者其他broker的方法)
java
/**
* destChannel 是目标通道
* offset是物理偏移
* length是发送的字节数据大小
*
*/
@Override
public long writeTo(TransferableChannel destChannel, long offset, int length) throws IOException {
long newSize = Math.min(channel.size(), end) - start;
int oldSize = sizeInBytes();
if (newSize < oldSize)
throw new KafkaException(String.format(
"Size of FileRecords %s has been truncated during write: old size %d, new size %d",
file.getAbsolutePath(), oldSize, newSize));
long position = start + offset;
long count = Math.min(length, oldSize - offset);
return destChannel.transferFrom(channel, position, count);
}通过debug可以看到 我们要通过这个方法 这个方法底层就是 零拷贝的系统调用sengfile 发送给consumer或者broker
这个方法底层调用了 java.nio.channels.FileChannel#transferTo 这个方法,这个方法是java sendfile系统调用api
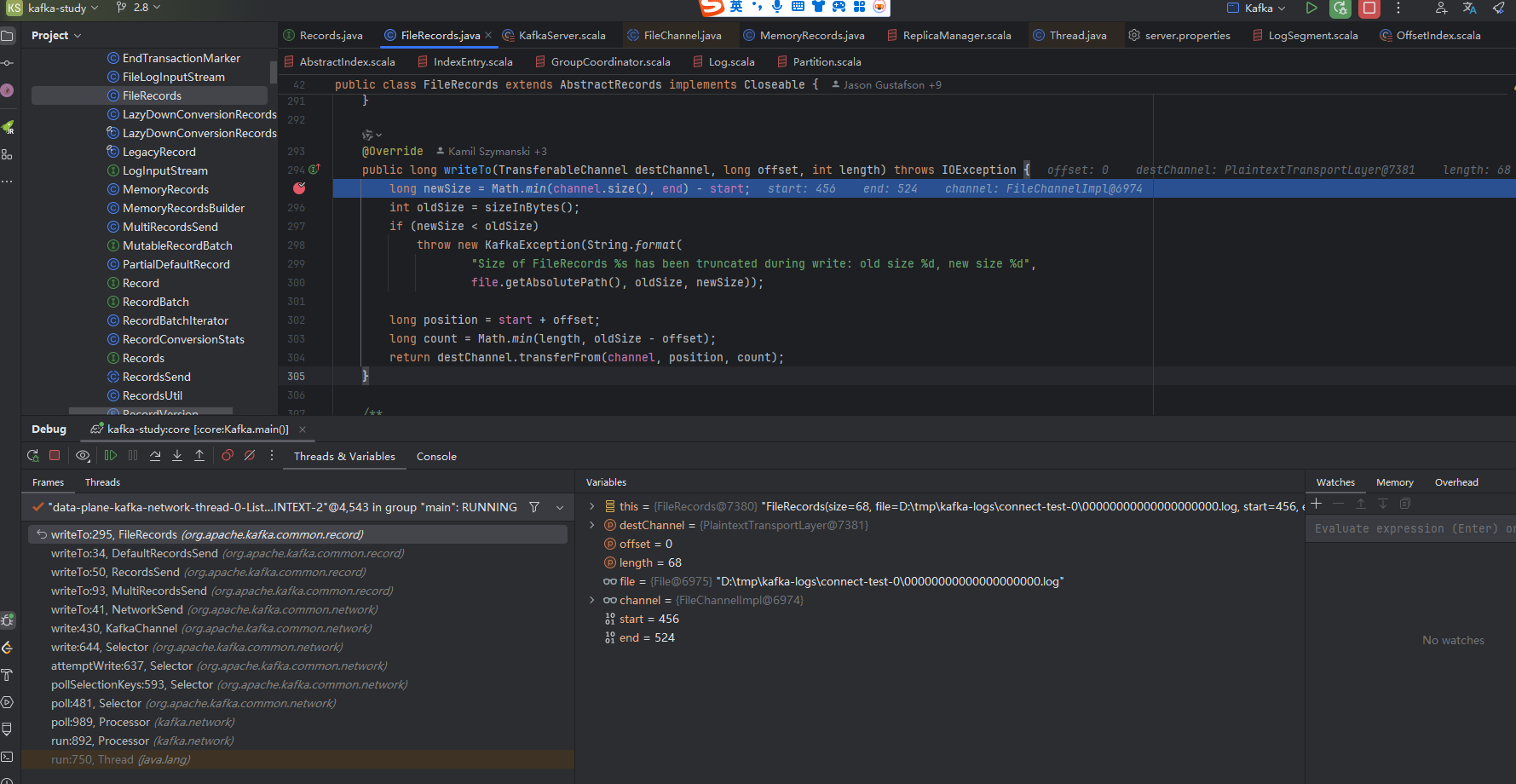
Kafka 将消息封装成一个个 Record,并以自定义的格式序列化成二进制字节数组进行保存:
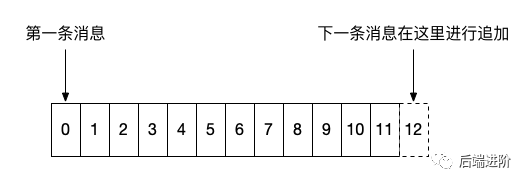
如上图所示,消息严格按照顺序进行追加,一般来说,左边的消息存储时间都要小于右边的消息,需要注意的一点是,在 0.10.0.0 以后的版本中,Kafka 的消息体中增加了一个用于记录时间戳的字段,而这个字段可以有 Kafka Producer 端自定义,意味着客户端可以打乱日志中时间的顺序性。
Kafka 的消息存储会按照该主题的分区进行隔离保存,即每个分区都有属于自己的的日志,在 Kafka 中被称为分区日志(partition log),每条消息在发送前计算到被发往的分区中,broker 收到日志之后把该条消息写入对应分区的日志文件中:
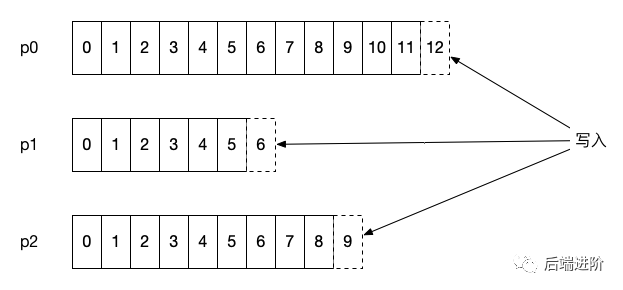
到底 kafka的消息到底是怎么存储的?什么结构?
我们可以看到当我们写入数据时,是通过MemoryRecords来写入的这个时候我们可以看下 他里面的buffer的字节是啥样的,就能看到数据保存的是啥
最终我们找到这个类 org.apache.kafka.common.record.DefaultRecord(请注意我看的是V2的版本代码 老的版本是还有校验和)
可以看到这个注释
plain
* Record =>
* Length => Varint 长度
* Attributes => Int8 扩展字段
* TimestampDelta => Varlong 相对时间戳
* OffsetDelta => Varint 相对偏移量
* Key => Bytes key
* Value => Bytes value
* Headers => [HeaderKey HeaderValue] 还有头
* HeaderKey => String
* HeaderValue => Bytes我们及细看他的writeTo方法
java
/**
* Write the record to `out` and return its size.
*/
public static int writeTo(DataOutputStream out,
int offsetDelta,
long timestampDelta,
ByteBuffer key,
ByteBuffer value,
Header[] headers) throws IOException {
//整个record的长度
int sizeInBytes = sizeOfBodyInBytes(offsetDelta, timestampDelta, key, value, headers);
ByteUtils.writeVarint(sizeInBytes, out);
//扩展字段 暂时没啥用
byte attributes = 0; // there are no used record attributes at the moment
out.write(attributes);
//时间戳
ByteUtils.writeVarlong(timestampDelta, out);
//偏移量
ByteUtils.writeVarint(offsetDelta, out);
if (key == null) {
ByteUtils.writeVarint(-1, out);
} else {
int keySize = key.remaining();
//key的长度
ByteUtils.writeVarint(keySize, out);
//key的值
Utils.writeTo(out, key, keySize);
}
if (value == null) {
ByteUtils.writeVarint(-1, out);
} else {
int valueSize = value.remaining();
//value的长度
ByteUtils.writeVarint(valueSize, out);
//value的值
Utils.writeTo(out, value, valueSize);
}
if (headers == null)
throw new IllegalArgumentException("Headers cannot be null");
//头的长度
ByteUtils.writeVarint(headers.length, out);
for (Header header : headers) {
String headerKey = header.key();
if (headerKey == null)
throw new IllegalArgumentException("Invalid null header key found in headers");
//头的key
byte[] utf8Bytes = Utils.utf8(headerKey);
ByteUtils.writeVarint(utf8Bytes.length, out);
out.write(utf8Bytes);
//头的value
byte[] headerValue = header.value();
if (headerValue == null) {
ByteUtils.writeVarint(-1, out);
} else {
ByteUtils.writeVarint(headerValue.length, out);
out.write(headerValue);
}
}
return ByteUtils.sizeOfVarint(sizeInBytes) + sizeInBytes;
}可以简单画一下 这个是存储的record数据

总结一下:
- 消息的读 是通过索引文件来索引找到真实物理地址,然后连续读,将数据读取出来的。
- 消息的推送 是将读取到的数据通过sendfile发送给拉取数据的客户端。
- 消息的写 通过直接append文件,顺序写的方式,将数据追加到磁盘文件当中。
索引设计
为什么需要索引?什么是索引?
在mq这种存储当中,如何要能够快速找到需要推给consumer的消息?所以能够快速查找数据的索引结构必不可少。索引是一种提高访问数据的数据结构。索引的结构是啥?索引是怎么维护的?
kafka如何设计的索引呢?kafka面临的是海量消息的存储,意味着如果少存一个字段就可能减少天量数据的存储。所以索引就尽量少存数据能够找到最终数据,kafka采用的是稀疏索引,什么是稀疏索引?稀疏索引是一种特殊的索引类型,他不会为每一个存储在磁盘上的数据块创建一个索引项。
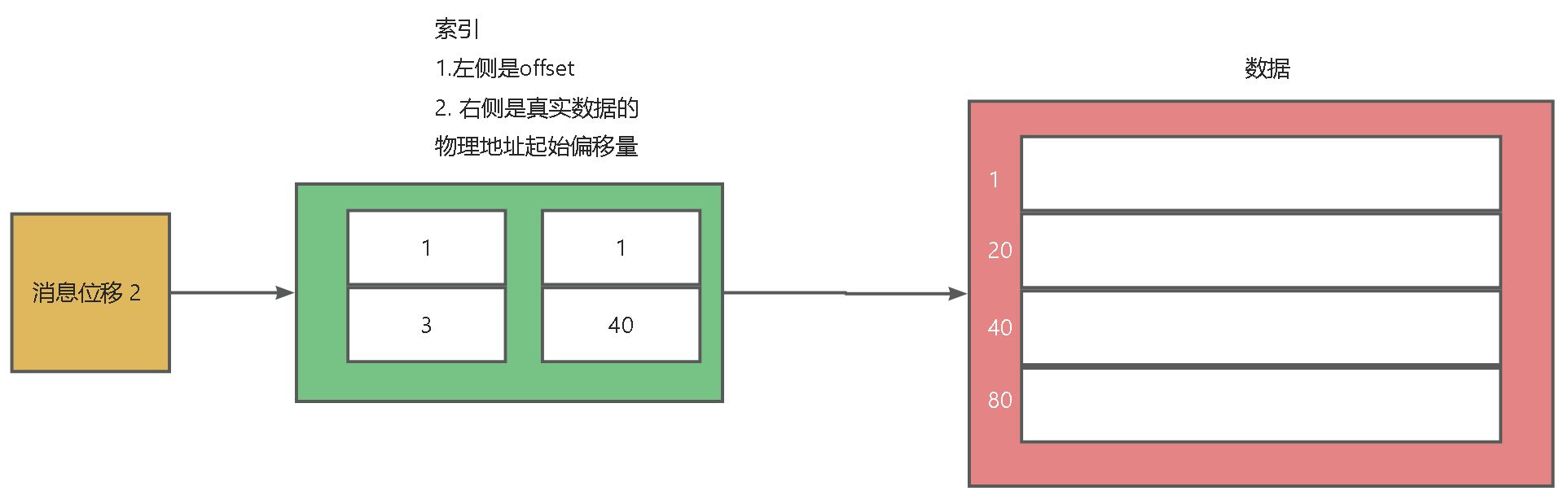
可以看到画的这张图 就是稀疏索引,他并没有为所有数据创建索引项 只创建几个索引项
offset 1:对应起始物理地址1,offset3:它的物理地址的起始地址40。
偏移量索引
可以看到这个索引的定义,可以看到一个索引项包含两个字段 一个是offset,一个是物理地址,总共8个字节,请注意一点 这个offset 起始保存的相对offset,并不是绝对的offset
scala
case class OffsetPosition(offset: Long, position: Int) extends IndexEntry {
override def indexKey = offset
override def indexValue = position.toLong
}可以看到是8个字节
时间戳索引
他还有一个索引就是时间戳索引 也是两个字段 8个字节保存时间戳 4个字节保存offset,也就意味着如果你想通过时间戳来查询数据,先通过时间戳找到offset再通过offset的索引结构再找到物理地址。
scala
/**
* The mapping between a timestamp to a message offset. The entry means that any message whose timestamp is greater
* than that timestamp must be at or after that offset.
* @param timestamp The max timestamp before the given offset.
* @param offset The message offset.
*/
case class TimestampOffset(timestamp: Long, offset: Long) extends IndexEntry {
override def indexKey = timestamp
override def indexValue = offset
}如何借用这个偏移量索引来查找数据呢?
那他是如何借用这个索引来查找数据呢?我们来详细分析一个拉取consumer拉取数据的时候 怎么利用的?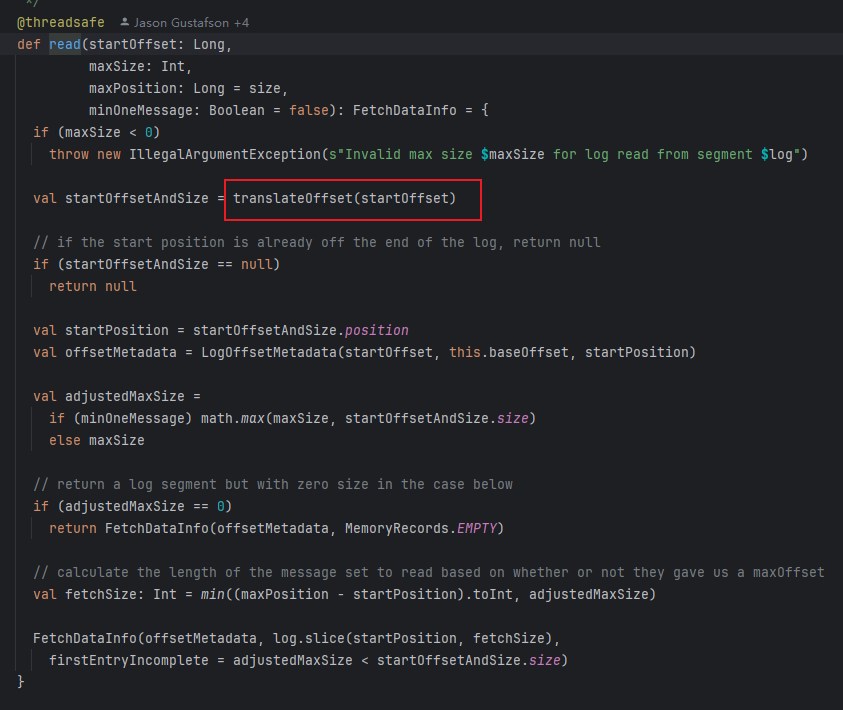
scala
@threadsafe
private[log] def translateOffset(offset: Long, startingFilePosition: Int = 0): LogOffsetPosition = {
//先二分查找 找到小于这个目标offset的 索引信息
val mapping = offsetIndex.lookup(offset)
//再依次遍历找到最终 需要的索引信息
log.searchForOffsetWithSize(offset, max(mapping.position, startingFilePosition))
}最终调用到了 kafka.log.OffsetIndex#lookup => kafka.log.AbstractIndex#indexSlotRangeFor 这个方法可以看到 通过二分查找 找到起始的需要拉取的消息的起始物理地址。
scala
private def indexSlotRangeFor(idx: ByteBuffer, target: Long, searchEntity: IndexSearchType): (Int, Int) = {
// check if the index is empty
//如果索引文件是空的那么就依次遍历
if(_entries == 0)
return (-1, -1)
def binarySearch(begin: Int, end: Int) : (Int, Int) = {
// binary search for the entry
var lo = begin
var hi = end
while(lo < hi) {
val mid = (lo + hi + 1) >>> 1
val found = parseEntry(idx, mid)
val compareResult = compareIndexEntry(found, target, searchEntity)
if(compareResult > 0)
hi = mid - 1
else if(compareResult < 0)
lo = mid
else
return (mid, mid)
}
(lo, if (lo == _entries - 1) -1 else lo + 1)
}
//这个 _warmEntries 不知道是啥 大概率 firstHotEntry=0,除非索引项非常多 数据量非常大 这里可能是一种优化手段 待会我们继续分析
val firstHotEntry = Math.max(0, _entries - 1 - _warmEntries)
// check if the target offset is in the warm section of the index
if(compareIndexEntry(parseEntry(idx, firstHotEntry), target, searchEntity) < 0) {
//二分查找找到小于目标target offset的 索引项的下标
return binarySearch(firstHotEntry, _entries - 1)
}
// check if the target offset is smaller than the least offset
if(compareIndexEntry(parseEntry(idx, 0), target, searchEntity) > 0)
return (-1, 0)
binarySearch(0, firstHotEntry)
}什么时候索引文件不是空的呢?什么往里面添加呢?这个时候我们看到这个方法
kafka.log.LogSegment#append
scala
@nonthreadsafe
def append(largestOffset: Long,
largestTimestamp: Long,
shallowOffsetOfMaxTimestamp: Long,
records: MemoryRecords): Unit = {
if (records.sizeInBytes > 0) {
.
.
.
// append the messages
val appendedBytes = log.append(records)
.
.
.
// append an entry to the index (if needed)
可以看到这里有个调优项 当保存的数据超过 4kb时就会往索引文件当中添加索引项
if (bytesSinceLastIndexEntry > indexIntervalBytes) {
offsetIndex.append(largestOffset, physicalPosition)
timeIndex.maybeAppend(maxTimestampSoFar, offsetOfMaxTimestampSoFar)
bytesSinceLastIndexEntry = 0
}
bytesSinceLastIndexEntry += records.sizeInBytes
}
}可以 通过 log.index.interval.bytes 参数进行控制,默认大小为 4 KB,意味着 Kafka 至少写入 4KB 消息数据之后,才会在索引文件中增加一个索引项。
总结一下 怎么使用偏移量搜索的
偏移量索引搜索
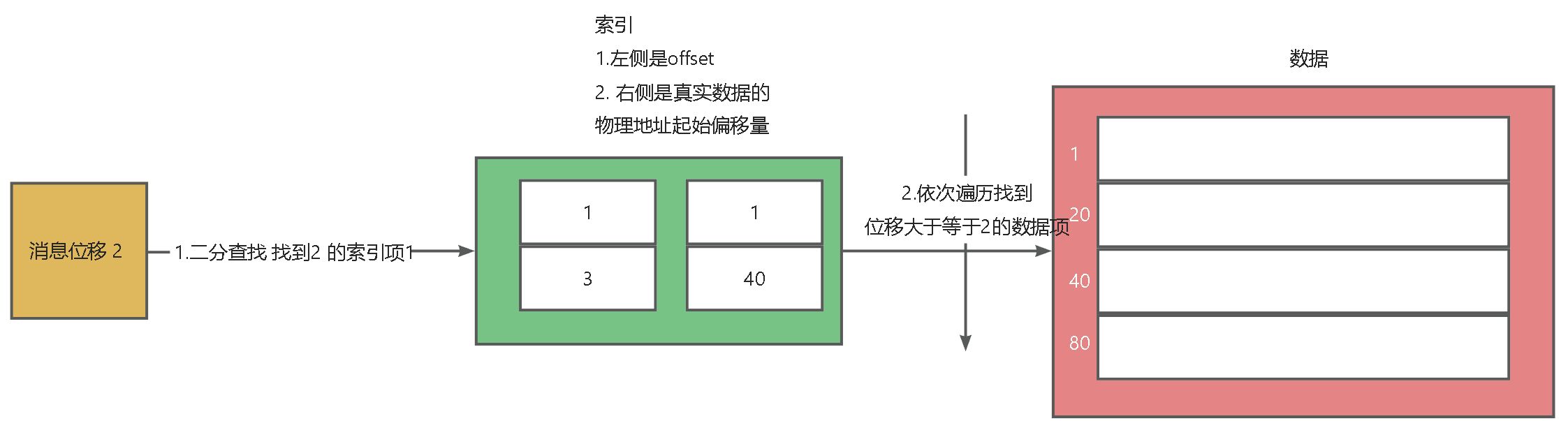
步骤1.对应源码当中的 kafka.log.LogSegment#translateOffset 的
val mapping = offsetIndex.lookup(offset) 这一行
步骤2. 对应源码当中的 kafka.log.LogSegment#translateOffset 的
log.searchForOffsetWithSize(offset, max(mapping.position, startingFilePosition)) 这一行
如何借用这个时间戳索引来查找数据呢?
kafka.log.LogSegment#findOffsetByTimestamp
scala
def findOffsetByTimestamp(timestamp: Long, startingOffset: Long = baseOffset): Option[TimestampAndOffset] = {
// Get the index entry with a timestamp less than or equal to the target timestamp
//先通过时间戳二分查找找到小于这个timestamp 的索引信息
val timestampOffset = timeIndex.lookup(timestamp)
//再通过这个时间戳对应的偏移量 再去 偏移量索引去找 找到索引信息
val position = offsetIndex.lookup(math.max(timestampOffset.offset, startingOffset)).position
//再依次顺序遍历直到找到符合的数据的地址信息
// Search the timestamp
Option(log.searchForTimestamp(timestamp, position, startingOffset))
}
scala
public TimestampAndOffset searchForTimestamp(long targetTimestamp, int startingPosition, long startingOffset) {
for (RecordBatch batch : batchesFrom(startingPosition)) {
if (batch.maxTimestamp() >= targetTimestamp) {
// We found a message
for (Record record : batch) {
long timestamp = record.timestamp();
//大于等与目标时间戳 且 偏移量大于等于查找到的偏移量
if (timestamp >= targetTimestamp && record.offset() >= startingOffset)
return new TimestampAndOffset(timestamp, record.offset(),
maybeLeaderEpoch(batch.partitionLeaderEpoch()));
}
}
}
return null;
}可以看到这个图 就是如下所示

kafka索引性能好的原因
1.mmap技术 通过mmap系统调用老构建索引文件的page cache 缓存,优化了索引文件的读写性能 ,通过AbstractIndex 源码我们可以看到
scala
@volatile
protected var mmap: MappedByteBuffer = {
val newlyCreated = file.createNewFile()
val raf = if (writable) new RandomAccessFile(file, "rw") else new RandomAccessFile(file, "r")
try {
/* pre-allocate the file if necessary */
if(newlyCreated) {
if(maxIndexSize < entrySize)
throw new IllegalArgumentException("Invalid max index size: " + maxIndexSize)
raf.setLength(roundDownToExactMultiple(maxIndexSize, entrySize))
}
/* memory-map the file */
_length = raf.length()
val idx = {
if (writable)
raf.getChannel.map(FileChannel.MapMode.READ_WRITE, 0, _length)
else
raf.getChannel.map(FileChannel.MapMode.READ_ONLY, 0, _length)
}
/* set the position in the index for the next entry */
if(newlyCreated)
idx.position(0)
else
// if this is a pre-existing index, assume it is valid and set position to last entry
idx.position(roundDownToExactMultiple(idx.limit(), entrySize))
idx
} finally {
CoreUtils.swallow(raf.close(), AbstractIndex)
}
}- 冷热分区的二分查找(1.1之后的版本开始有的)
首先这个是怎么诞生的呢?那就不得不说如果没有这个会产生什么问题,这个索引是借助了mmap技术(内存映射技术),那他映射的是哪个内存呢?是映射的操作系统的内核缓存,也就是我们熟知的page cache,可以看到我们程序的MapperBuffer 与 Page cache当中的内存建立了映射,page cache又是映射的具体的文件块,由于page cache是每一个4KB的分块,并不会把所有的数据读取到内存当中来。所以当应用程序读取到不在page cache当中的数据,操作系统会重新把需要的数据加载到page cache中来,这个就是缺页中断,由于这个重新读取文件内容会阻塞读取线程,导致性能问题。
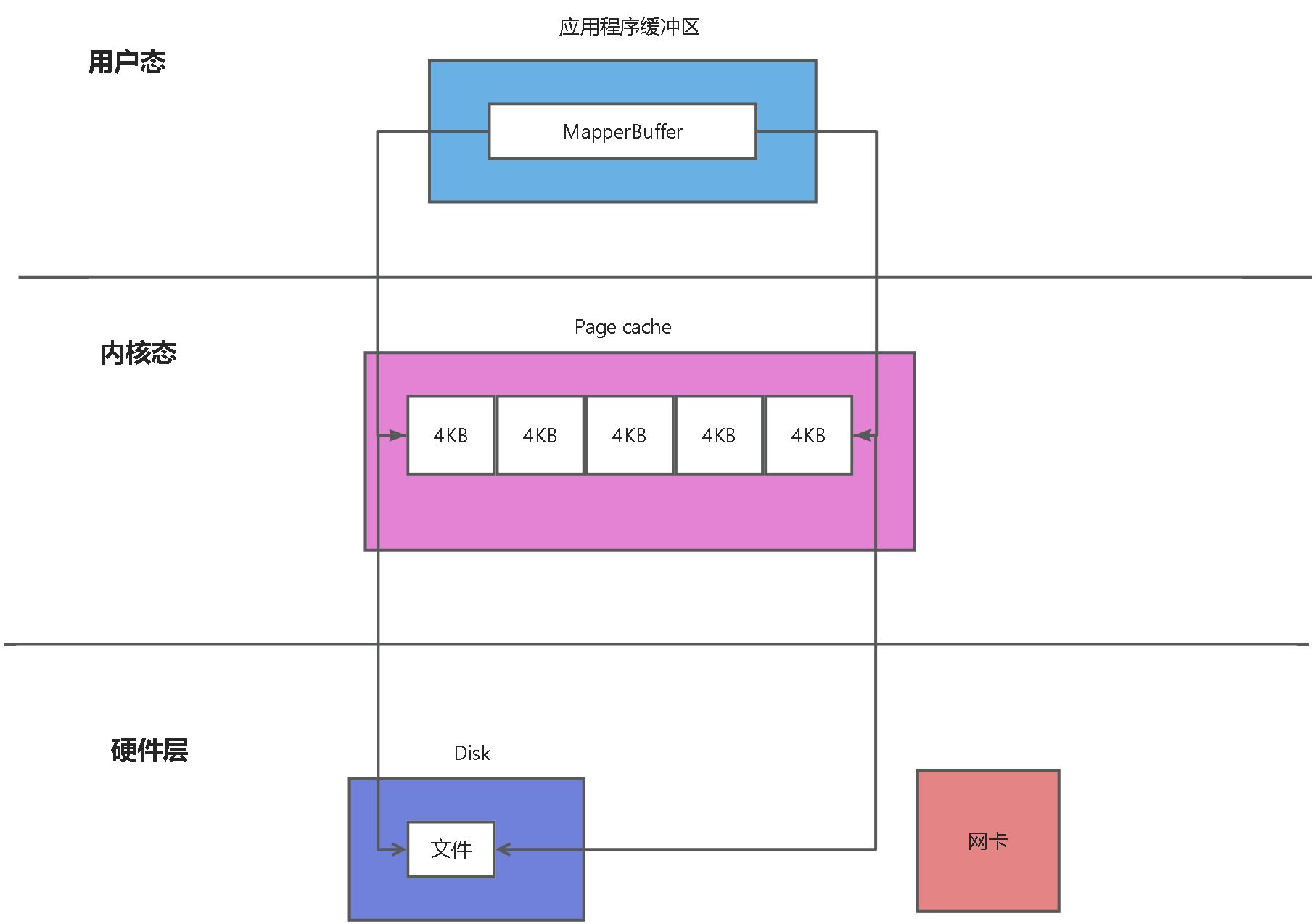
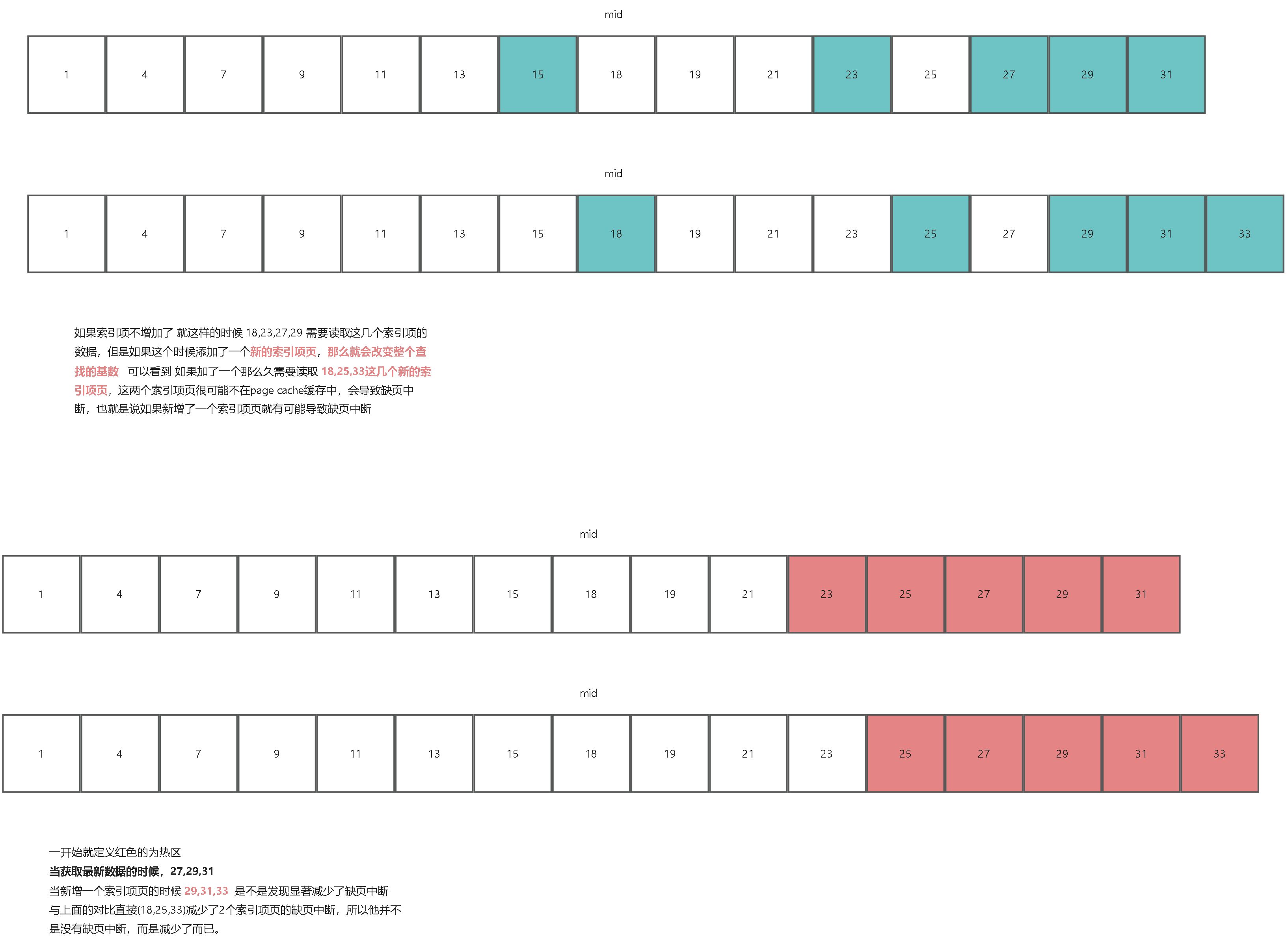
kafka 偏移量索引 二分查找时 有可能会频繁导致 缺页中断,由于每次基本上都是拉取最新的数据,所以最后的索引项基本都是热数据。让我们来对比一下他们的优化前后的差异
关于为什么设置热区大小为8192字节,官方给出的解释,这是一个合适的值:
1. <font style="color:rgb(51, 51, 51);">足够小,能保证热区的页数小于等于3,那么当二分查找时的页面都很大可能在page cache中。也就是说如果设置的太大了,那么可能出现热区中的页不在page cache中的情况。</font>
2. <font style="color:rgb(51, 51, 51);">足够大,8192个字节,对于位移索引,则为1024个索引项,可以覆盖4MB的消息数据,足够让大部分在in-sync内的节点在热区查询。</font>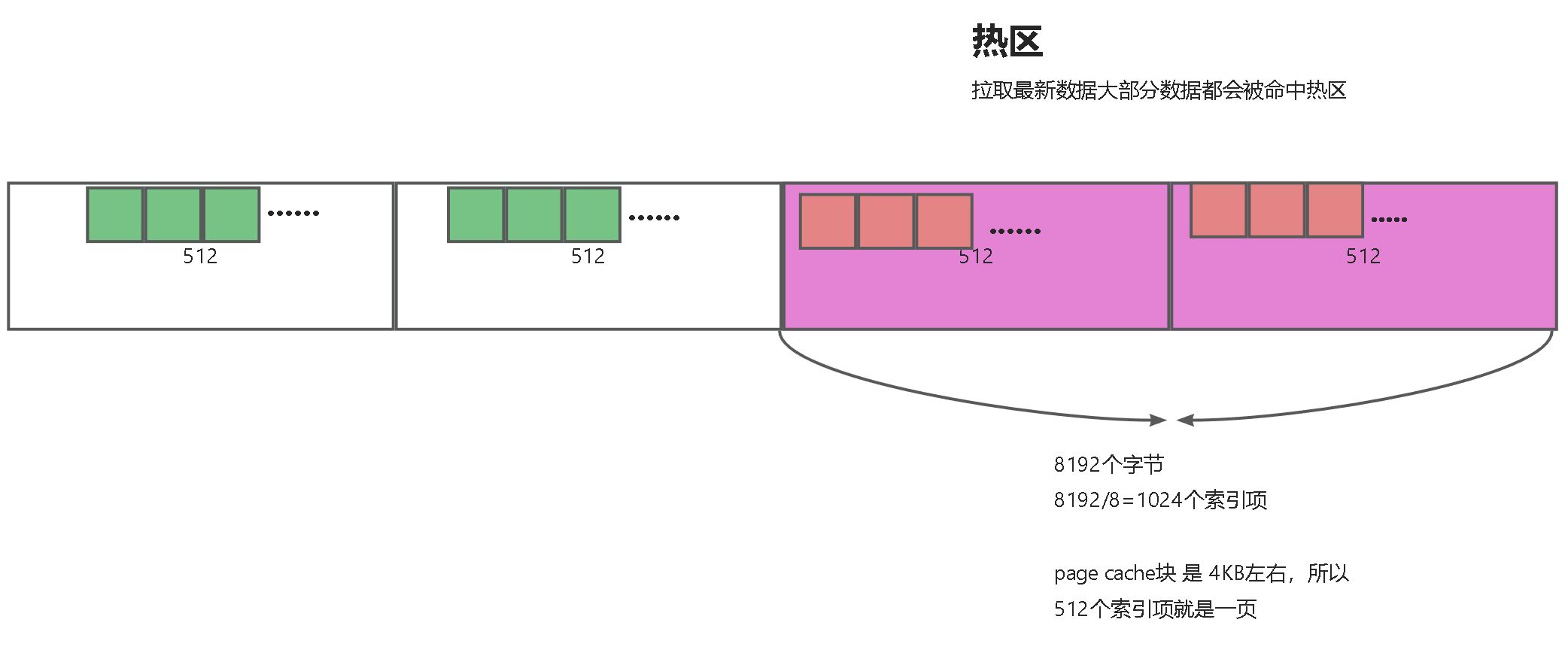
-
顺序写
kafka.log.OffsetIndex#append 可以看到这个 偏移量索引的源码 这个就是往文件的末尾处添加
scala
/**
* Append an entry for the given offset/location pair to the index. This entry must have a larger offset than all subsequent entries.
* @throws IndexOffsetOverflowException if the offset causes index offset to overflow
*/
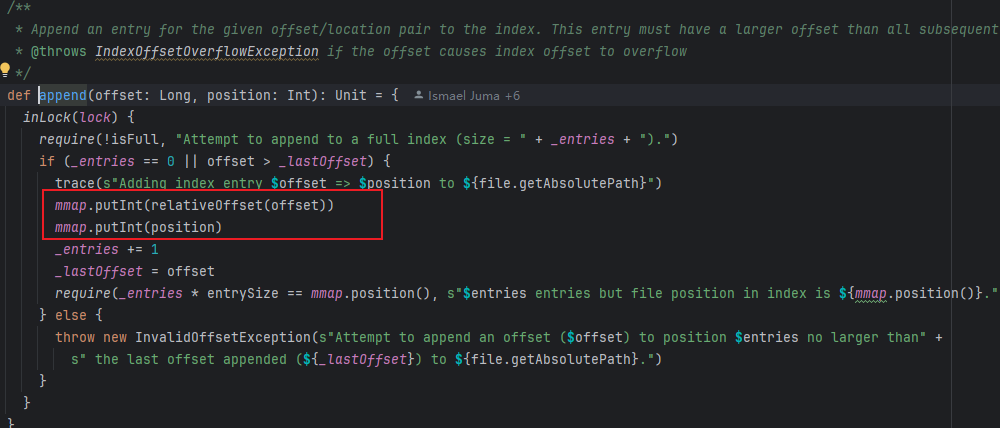
def append(offset: Long, position: Int): Unit = {
inLock(lock) {
require(!isFull, "Attempt to append to a full index (size = " + _entries + ").")
if (_entries == 0 || offset > _lastOffset) {
trace(s"Adding index entry $offset => $position to ${file.getAbsolutePath}")
mmap.putInt(relativeOffset(offset))
mmap.putInt(position)
_entries += 1
_lastOffset = offset
require(_entries * entrySize == mmap.position(), s"$entries entries but file position in index is ${mmap.position()}.")
} else {
throw new InvalidOffsetException(s"Attempt to append an offset ($offset) to position $entries no larger than" +
s" the last offset appended (${_lastOffset}) to ${file.getAbsolutePath}.")
}
}
}总结
kafka的消息存储和索引设计是非常优秀的,使用了相当多的操作系统的优良特性
1.mmap技术来优化 索引文件的读写,以及 索引文件的顺序写。
2.log存储进行分段,并且不立马刷盘,而是定时刷新落盘,这个为了追求极致的性能
3.零拷贝sendfile 的使用,将日志内容发送给consumer和同步给其他broker.
4.冷热分区的二分查找 减少 page cache 缺页中断
所以一个好的中间件 必须与操作系统特性紧密结合,才能让性能直接起飞。