
文章目录
-
- [JVM 的主要组成部分](#JVM 的主要组成部分)
- [类加载器(Class Loader)](#类加载器(Class Loader))
-
- [1. 加载(Loading)](#1. 加载(Loading))
- [2. 链接(Linking)](#2. 链接(Linking))
- [3. 初始化(Initialization)](#3. 初始化(Initialization))
- [Execution Engine(执行引擎)](#Execution Engine(执行引擎))
-
- [1. 解释器(Interpreter)](#1. 解释器(Interpreter))
- [2. 即时编译器(JIT Compiler)](#2. 即时编译器(JIT Compiler))
- [3. 垃圾回收器(Garbage Collector)](#3. 垃圾回收器(Garbage Collector))
- [Runtime Data Area(运行时数据区)](#Runtime Data Area(运行时数据区))
-
- [1. 方法区(Method Area)](#1. 方法区(Method Area))
- [2. 堆(Heap)](#2. 堆(Heap))
- [3. Java 虚拟机栈(Java Virtual Machine Stack)](#3. Java 虚拟机栈(Java Virtual Machine Stack))
- [4. 程序计数器(Program Counter Register)](#4. 程序计数器(Program Counter Register))
- [5. 本地方法栈(Native Method Stack)](#5. 本地方法栈(Native Method Stack))
- [Native Interface(本地接口)](#Native Interface(本地接口))
- java文件在jvm中的处理过程
- 堆中实现深拷贝与浅拷贝原理
- 对象分配内存底层原理
JVM 的主要组成部分
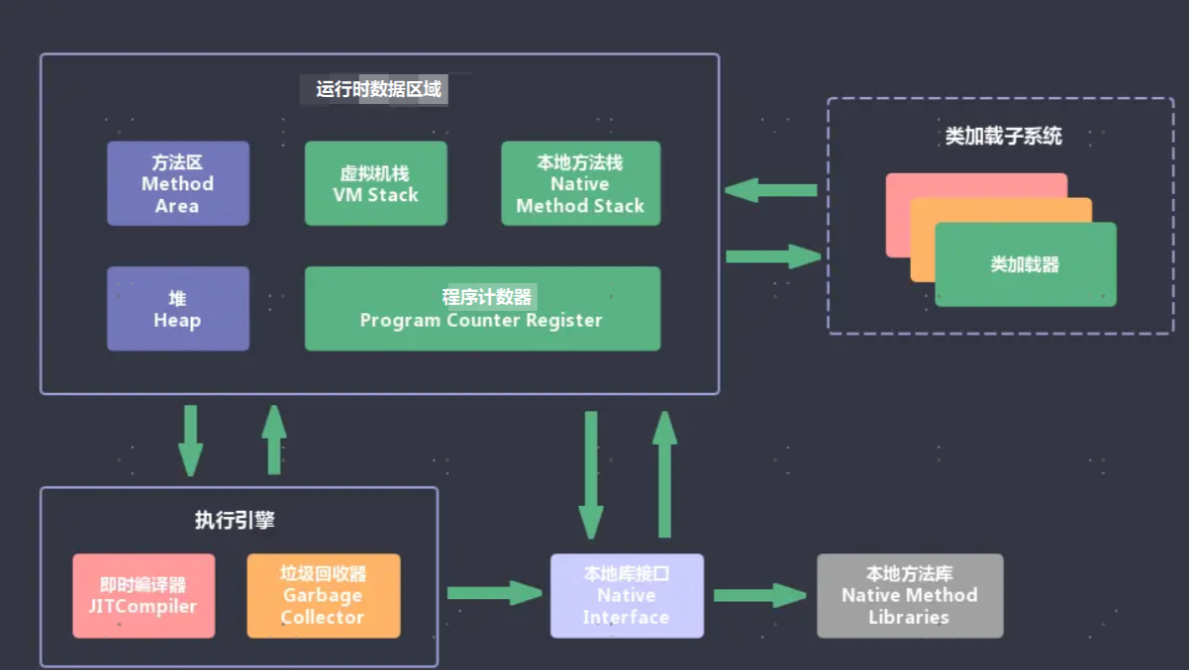
JVM包含两个子系统和两个组件,两个子系统为Class loader(类装载)、Execution engine(执行引擎);两个组件为Runtime data area(运行时数据区)、Native Interface(本地接口)。
对于某些面试官可能就会问到这些组成的原理,下文将详细介绍这四部分
类加载器(Class Loader)

- 功能:负责加载 Java 类文件到 JVM 中。它的主要任务是找到、加载、链接和初始化类。
- 过程 :
- 加载:从文件系统、网络或其他源中读取文件。
- 链接
- 验证:确保字节码符合 JVM 的规范。
- 准备:分配内存并设置类变量的初始值。
- 解析:将符号引用转换为直接引用。
- 初始化:执行静态初始化块和静态变量赋值。
1. 加载(Loading)
- 定义 :类加载的第一步是查找并加载
.class文件。- 来源 :加载可以来自多个地方,包括:
- 文件系统(本地磁盘)
- 网络(远程服务器)
- 其他类加载器(如应用程序特定的加载器)
- 实现:类加载器会读取字节流并将其转换为数据结构,以供后续处理。
对于java来说,类加载器将.class文件(字节码二进制的数据),装载到jvm中,并将类的结构封装成一个class对象放到堆中
2. 链接(Linking)
a. 验证(Verification)
- 目的:确保加载的字节码符合 JVM 的规范,防止潜在的安全问题和错误。
- 检查内容 :
- 字节码的合法性,确保它符合 Java 虚拟机规范。
- 确保类的结构正确,如方法的参数和返回类型等。
b. 准备(Preparation)
- 目的:为类变量(静态变量)分配内存并设置初始值。
- 内存分配:为类的静态字段分配内存,这些字段在方法区的运行时数据区中存储。
- 默认值 :所有类变量在准备阶段会被初始化为默认值(如
0、null、false)。c. 解析(Resolution)
- 目的:将符号引用转换为直接引用。
- 符号引用:在字节码中,类、方法和字段等通过符号名引用。
- 直接引用:解析后,符号引用被转换为内存地址(直接引用),使得 JVM 在运行时可以直接访问。
3. 初始化(Initialization)
- 定义:在链接完成后,类的初始化阶段会执行。
- 执行过程 :
- 执行类的静态初始化块。
- 为静态变量赋值,通常是在定义时指定的值。
- 静态初始化块:如果类中有静态代码块,这些代码会在初始化阶段执行,允许开发者在类加载时执行特定逻辑。
Execution Engine(执行引擎)

功能:负责执行字节码,将其转换为底层机器指令并由 CPU 执行。(jvm其实是无法识别字节码的,所以要转一下)
主要组成:
- 解释器(Interpreter):逐行解释字节码并执行,适合快速启动,但效率较低。
- 即时编译器(JIT Compiler):将热点代码(经常执行的代码)编译为机器码,提高执行效率。编译后的代码存储在内存中,以供后续直接调用。
- 垃圾回收器(Garbage Collector):负责自动管理内存,回收不再使用的对象,防止内存泄漏。
1. 解释器(Interpreter)
- 功能:解释器逐行读取和执行Java字节码,而不是将整个字节码文件编译为机器码。这使得程序可以快速启动和运行。
- 工作原理 :
- 逐行解析:解释器将字节码指令逐行读取,解析每条指令并立即执行。对于每个字节码操作,都会进行相应的操作(如计算、对象创建等)。
- 适用场景:适合小型应用或在开发阶段,快速迭代和测试代码时。
- 优缺点 :
- 优点:启动快,不需要预编译,适合动态变化的代码。
- 缺点:整体执行效率低,因为每次运行都需要解析和执行字节码,增加了开销。
2. 即时编译器(JIT Compiler)
- 功能:JIT编译器在运行时将热点代码(频繁执行的代码段)编译为机器码,从而提高执行效率。
- 工作原理 :
- 热点识别:JIT编译器监测哪些代码被频繁调用,并将这些代码编译为本地机器码。
- 优化执行:编译后的机器码会存储在内存中,后续执行时直接调用,避免再次解析字节码。
- 实时优化:JIT编译器还可以进行多种优化(如内联、死代码消除等),进一步提高性能。
- 优缺点 :
- 优点:执行速度快,减少了解释执行的开销,适合长时间运行的应用。
- 缺点:初次执行时可能存在延迟,因为需要时间编译热点代码;占用更多内存以存储编译后的代码。
3. 垃圾回收器(Garbage Collector)
想深入了解这部分可查看一篇聊透内存泄露,栈内存溢出,JVM中的垃圾回收器超详细
- 功能:自动管理内存,回收不再使用的对象,防止内存泄漏和优化内存使用。
- 工作原理 :
- 对象标记:垃圾回收器会跟踪所有对象的引用情况,标记那些不再被引用的对象。
- 清理:标记完成后,垃圾回收器会清理这些不再使用的对象,释放内存。
- 回收算法:常见的回收算法包括标记-清除、复制、标记-压缩等,不同的算法有不同的效率和内存使用特点。
- 优缺点 :
- 优点:自动管理内存,开发者无需手动释放内存,降低了内存管理的复杂性。
- 缺点:可能导致性能波动,尤其是在垃圾回收时,可能会暂停应用程序的执行(称为"停顿"现象)。
Runtime Data Area(运行时数据区)

- 功能 :JVM 在运行 Java 程序时使用的内存区域,主要包括:
- 方法区:存储类信息、常量、静态变量等。
- 堆:用于存储对象实例和数组,是所有线程共享的。
- Java 虚拟机栈:每个线程都有独立的栈,用于存储局部变量、方法调用等。
- 程序计数器:指示当前执行的字节码指令位置。
- 本地方法栈:用于处理本地方法调用。
1. 方法区(Method Area)
- 功能:方法区是JVM的一部分,用于存储类信息、常量、静态变量、即时编译后的代码等。它是所有线程共享的内存区域。
- 内容 :
- 类信息:存储类的结构,如类的名称、访问修饰符、父类信息、接口信息等。
- 常量池:存储编译时生成的常量,包括字符串字面量和其他基本数据类型的常量。
- 静态变量 :存储用
static修饰的变量,这些变量在整个类的生命周期内是共享的。- GC(垃圾回收):方法区也会进行垃圾回收,特别是对于常量池中的无用常量。
2. 堆(Heap)
- 功能:堆是JVM中最大的内存区域,用于存储对象实例和数组。它是所有线程共享的,适合动态分配内存。
- 内容 :
- 对象实例 :通过
new关键字创建的对象。- 数组:存储所有类型的数组(如整型数组、对象数组等)。
- GC(垃圾回收):堆中的内存管理是JVM的主要任务之一,使用不同的垃圾回收算法(如标记-清除、复制等)来回收不再使用的对象。
3. Java 虚拟机栈(Java Virtual Machine Stack)
- 功能:每个线程都有独立的虚拟机栈,存储局部变量、方法调用和返回值。栈的生命周期与线程相同。
- 内容 :
- 局部变量:存储方法参数和局部变量,包括基本数据类型和对象引用。
- 方法调用:每次方法调用时会创建一个栈帧,保存当前方法的信息和状态。
- 栈溢出 :如果栈深度超过JVM允许的最大值,将会抛出
StackOverflowError。
4. 程序计数器(Program Counter Register)
- 功能:每个线程都有一个独立的程序计数器,用于指示当前执行的字节码指令的位置。它是线程私有的。
- 内容 :
- 指令地址:记录当前线程正在执行的字节码指令地址。
- 线程切换:当线程切换时,程序计数器的值可以帮助恢复执行状态。
5. 本地方法栈(Native Method Stack)
- 功能:本地方法栈用于处理 Java 程序中调用的本地方法(使用 JNI,即 Java Native Interface)。
- 内容 :
- 本地方法调用:存储本地方法的参数和局部变量。
- JNI支持:可以直接调用 C/C++ 等语言编写的底层方法。
- 栈溢出 :类似于虚拟机栈,如果本地方法栈的深度超过JVM设定的最大值,将会抛出
StackOverflowError。
Native Interface(本地接口)
- 功能:允许 Java 代码调用其他语言(如 C/C++)编写的本地方法。这使得 Java 可以利用系统级资源或优化性能。
- 相关工具 :
- Java Native Interface (JNI):是 Java 提供的标准机制,允许 Java 代码和本地应用程序相互调用。
java文件在jvm中的处理过程
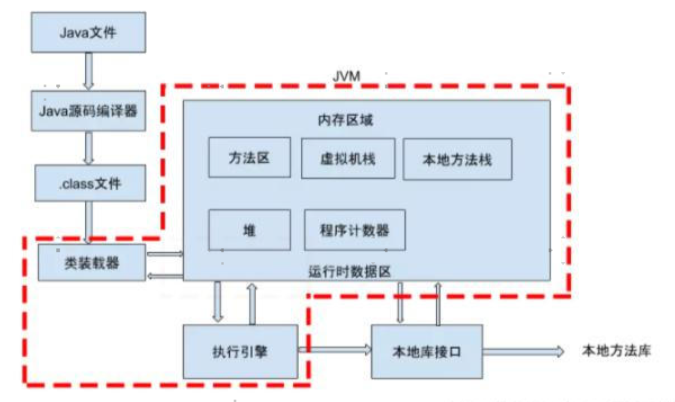
1.java文件,通过java源码编译器,Java 源代码经过编译后生成 `.class文件,存储的是字节码(二进制数据)。
2.类加载器将字节码数据读到方法区中,并在堆中创建一个java.lang.Class对象,用来封装类在方法区内的数据结构
3.而字节码文件只是 JVM 的一套指令集规范,并不能直接交给底层操作系统去执行,因此需要特定的命令解析器执行引擎(Execution Engine),将字节码翻译成底层系统指令,再交由 CPU 去执行
4.在某些情况下,执行过程中需要调用本地库(Native Interface)来实现特定功能。
整体流程总结:
.java文件通过java源码编译器进行编译为.class文件,存储的是字节码(二进制数据),类加载器,通过验证、准备、解析、初始化流程、将字节码数据读到方法区中,并在堆中创建一个java.lang.Class对象,用来封装类在方法区内的数据结构,通过编译器,将字节码翻译成底层系统指令,再交由 CPU 去执行
堆中实现深拷贝与浅拷贝原理
浅拷贝只复制对象的基本属性,而引用属性仍指向原对象。
java
class Address {
String city;
public Address(String city) {
this.city = city;
}
}
class Person implements Cloneable {
String name;
Address address;
public Person(String name, Address address) {
this.name = name;
this.address = address;
}
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
public class ShallowCopyExample {
public static void main(String[] args) throws CloneNotSupportedException {
Address addr = new Address("New York");
Person p1 = new Person("Alice", addr);
Person p2 = (Person) p1.clone();
System.out.println(p1.address.city); // 输出: New York
p2.address.city = "Los Angeles";
System.out.println(p1.address.city); // 输出: Los Angeles (引用共享)
}
}深拷贝复制对象及其引用的所有属性,确保没有共享引用。
java
class Address {
String city;
public Address(String city) {
this.city = city;
}
public Address deepCopy() {
return new Address(this.city);
}
}
class Person implements Cloneable {
String name;
Address address;
public Person(String name, Address address) {
this.name = name;
this.address = address;
}
@Override
protected Object clone() throws CloneNotSupportedException {
Person cloned = (Person) super.clone();
cloned.address = this.address.deepCopy(); // 深拷贝
return cloned;
}
}
public class DeepCopyExample {
public static void main(String[] args) throws CloneNotSupportedException {
Address addr = new Address("New York");
Person p1 = new Person("Alice", addr);
Person p2 = (Person) p1.clone();
System.out.println(p1.address.city); // 输出: New York
p2.address.city = "Los Angeles";
System.out.println(p1.address.city); // 输出: New York (无引用共享)
}
}浅拷贝就是平常对于一个实例的属性赋值,重新set就会覆盖原来的 深拷贝不会覆盖原来的属性值,而是会生成一个新的实例
对象分配内存底层原理
给对象分配内存有两种方式:
- 指针碰撞:意思就是如果Java堆的内存是规整,即所有用过的内存放在一边,而空闲的的放在另一边。分配内存时将位于中间的指针指示器向空闲的内存移动一段与对象大小相等的距离,这样便完成分配内存工作
- 空闲列表:如果Java堆的内存不是规整的,则需要由虚拟机维护一个列表来记录那些内存是可用的,这样在分配的时候可以从列表中查询到足够大的内存分配给对象,并在分配后更新列表记录。

可能存在的并发安全问题:可能出现正在给对象 A 分配内存,指针还没来得及修改,对象 B 又同时使用了原来的指针来分配内存的情况
