OpenCSG 导读
在这个数据为王的时代,大模型技术正以前所未有的速度颠覆着各行各业。数据作为驱动大模型的核心燃料,其质量和处理效率直接影响着模型的表现力和应用价值。正所谓"Garbage In, Garbage Out",只有拥有优质的数据,大模型才能发挥其潜力。面对数据处理的复杂性和高要求的工作流,如何高效地获取、清洗、标注和优化数据,成为核心挑战。在这样的背景下,OpenCSG 重磅推出 DataFlow,提供一个全面而高效的数据集处理解决方案。
DataFlow 旨在通过无缝衔接的数据获取、清洗、标注和优化流程,为用户提供一站式的数据处理体验。它不仅是一个工具,更是一个能够将数据从原始状态转化为高价值资源的"炼金术士",帮助用户轻松驾驭数据的复杂性,提炼出真正具有价值的信息。
1 重塑流程,焕新数据
DataFlow 的架构设计体现了高度的模块化和灵活性,旨在应对多样化的数据处理需求。从数据获取到清洗、标注,再到最终的优化和集成,DataFlow 为每一步提供了高效的解决方案。
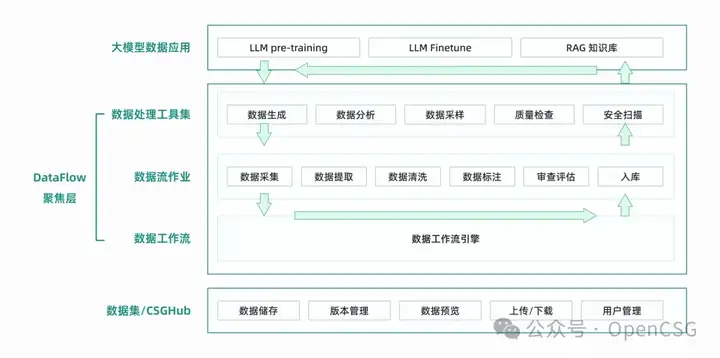
OpenCSG DataFlow设置了数据处理工作流的新标准,它与同类型产品相比拥有诸多不可比拟的优势。与Databrics Lakeflow等同类型产品相比,OpenCSG DataFlow的核心优势在于其与CSGHub的紧密结合。这种集成为用户提供了一个一站式解决方案,涵盖了数据的整个生命周期管理,从数据管理、版本控制、用户权限到存储,无一不包。
更重要的是,DataFlow通过向上与模型训练及微调等高阶功能的结合,并通过模型质量评估反馈回到数据质量的优化上,实现了一个持续迭代和优化的完美闭环。这种完整的全生命周期管理和操作,不仅促进了数据与模型之间的深度交互,还确保了数据处理的高效性与产品的易用性,赋予了DataFlow在市场上的独特竞争优势。
DataFlow的这些特点不仅彰显了它作为数据处理工作流的出众表现,也证明了它在提升用户工作效率、优化数据处理流程方面的前瞻性。这使得OpenCSG DataFlow成为那些寻求全面而轻松管理其数据处理需求用户的首选。
- 在数据获取阶段,DataFlow 支持多种数据源的接入,无论是本地数据、网络爬虫数据、数据托管平台(如 Hugging Face、CSGHub),甚至是通过 LLM 或其他方法生成的合成数据,它都能精准、高效地提取。平台提供了强大的多源适配工具,能够轻松转换和读取 CSV、JSON、Parquet 等多种数据格式,为后续的分析和模型训练奠定坚实的基础。

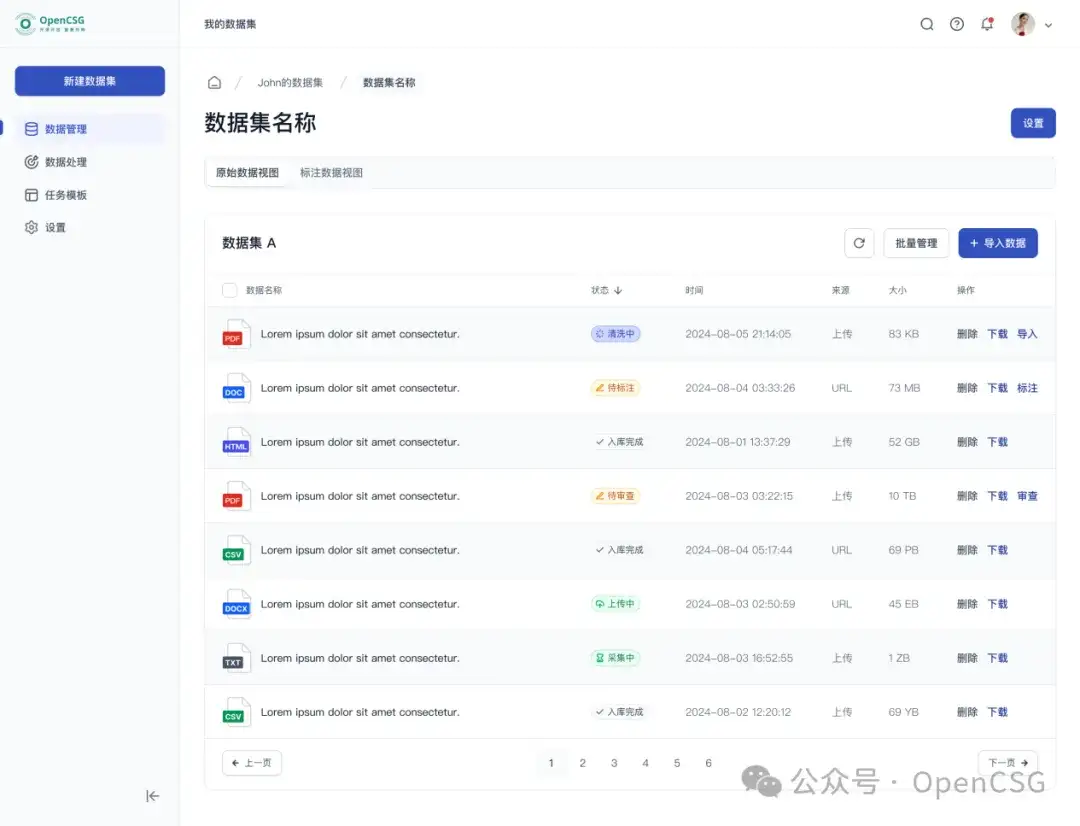
- **在数据清洗环节,**DataFlow 提供了先进的数据处理工具,帮助用户去除无用信息、纠正错误数据、进行复杂格式转换和数据筛选。通过灵活的 Pipeline 引擎,将数据清洗、转换和筛选过程深度优化。用户可以轻松构建数据处实现多线程并行处理,大大提高了效率。此外,DataFlow 使用了 Hugging Face 的数据集接口进行数据传递,保持数据的一致性和完整性。
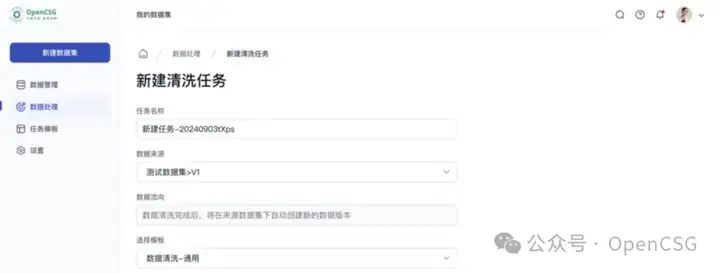
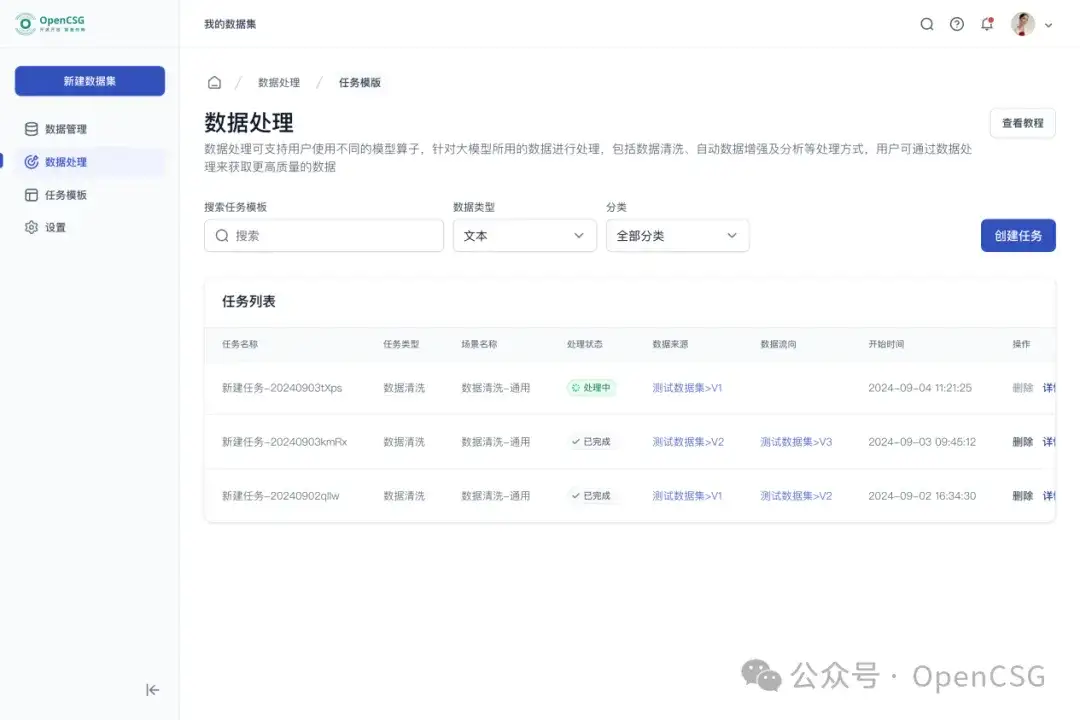
- 数据标注质量往往直接影响模型的表现力。DataFlow 的协作标注功能支持多人实时在线标注同一数据集,确保数据标注的高效性和一致性。平台提供详细的标注指导和可定制的标注模板,通过设立角色权限和审核机制有效提高了数据的标注质量。用户还可以通过工具和仪表盘实时监控标注进度,掌握项目的进展情况。这种智能化的标注系统将数据转变为能"说话"的智慧源泉。
2 灵活架构,自由拓展
DataFlow 的架构设计兼具灵活性和扩展性。平台采用了模块化设计,功能模块之间耦合度低,用户可以根据项目的具体需求灵活配置和调整工作流,从而在各种场景下实现最佳效果。DataFlow 基于 CSGHub 平台,提供了一体化的数据处理和管理体验,能够高效灵活地处理数据提取、清洗、标签化及与 AI 技术的整合,以最优化的方式进行呈现。
平台具备强大的分布式计算能力,DataFlow 实现了数据处理任务的高效并行化。未来,平台还计划支持 Spark 等其他分布式计算框架,并集成 Kubeflow Pipeline等工具以增强 Pipeline 引擎的能力,这都将进一步加强其计算能力和可扩展性,满足海量数据处理和大模型训练的高性能需求。
此外,DataFlow 的优化机制也值得称道。利用超参数优化(HPO)方法对数据处理方式进行自动优化,提高数据处理的速度和质量,使数据集在预训练和微调过程中持续改进,从而增强模型的精度和表现。
在追求精准和高效的自然语言处理领域中,质量上乘的数据集扮演着不可替代的角色。OpenCSG团队成功发布的中文版Fineweb Edu数据集,不仅填补了中文预训练数据集的空缺,更标志着其在促进中文NLP技术进步中所迈出的重要步伐。这一成就背后,DataFlow工具的作用不可或缺。
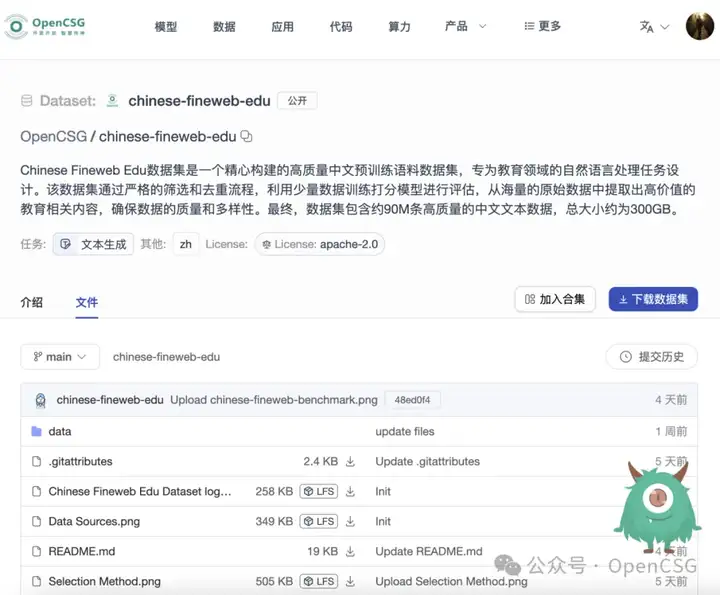
DataFlow工具为OpenCSG的团队提供了一个强有力的数据处理方案,使得从繁杂的原始数据中筛选、清洗到最终处理这一流程变得异常高效和精准。原本可能需要耗费极大人力物力才能完成的数据处理工作,通过DataFlow工具得以在更短的时间内完成,同时还保证了数据的质量和准确性。这一点对于构建一个既广泛又复杂的中文教育领域数据集来说,尤其重要。
更关键的是,DataFlow工具优化了数据处理的整个过程,使得工作流程变得可控和透明。借助于这一工具,OpenCSG团队能够更好地管理数据的筛选、清洗与整理工作,避免了人为错误并提高了工作效率。这不仅意味着中文版Fineweb Edu数据集的生成过程更为精细和高效,也意味着该数据集的质量更为可靠,为依赖这一数据集进行的中文NLP研究和开发奠定了坚实的基础。
3 无缝集成,化繁为简
DataFlow 的强大还在于它的无缝集成与兼容性。它可以与 CSGHub 平台无缝对接,支持通过 Web 界面和命令行等多种方式操作,提供了标准化的 API 和微服务子模块,确保用户能够轻松将 DataFlow 集成到任何现有技术架构中,实现数据处理的智能化和自动化。
DataFlow借助大模型的力量,让流程变得更加简单和自动化,基于Multi-Agent数据处理框架 (Agentic DataFlow), 结合大模型能力打造灵活、高效、可扩展的数据管理平台,通过智能Agents协作,满足复杂的数据分析、获取和处理需求。
Agentic DataFlow是一种创新型的数据处理平台,它运用Multi-Agent系统理念,为复杂数据处理任务提供动态、高度可定制的解决方案。此平台通过集成多个智能Agent,实现数据的获取、处理、存储及审查的自动化,旨在优化数据流程,提高数据处理效率与质量。
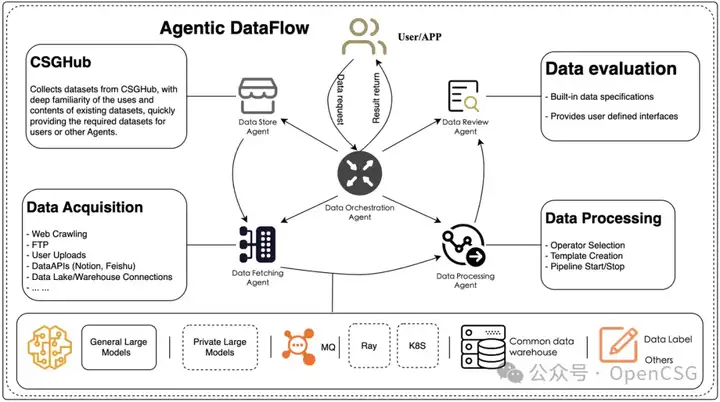
Agentic DataFlow为平台提供四大明显优势:
- **灵活性:**通过多个专门的Agent组件,结合专有大模型的能力,根据数据处理任务的具体需求,动态组合成最优处理流程。
- **扩展性:**Agent的设计使得整个系统易于添加新的功能和数据源,满足未来数据处理的需求。
- **高效性:**自动化的数据处理尽量减少人工介入,提高了处理速度和准确性。
- **用户友好:**提供直观的界面供用户定义数据规范,减少技术门槛。
DataFlow 一直在持续进化,工具集和数据流引擎性能不断提升。平台支持多种数据源和格式的处理,提供丰富的 Pipeline 模板目录,用户可以快速创建和定制数据处理流程。平台还支持用户通过易于使用的 UI 界面定制特殊 Pipeline,并进行存储与分享等。同时,平台提供全面的监控功能,用户可以实时监控 Pipeline 运行状态,查看日志等。在以上功能基础上,DataFlow 能够快速响应用户的需求,极大地提升数据处理的效率和精度。
4 拥抱未来,开源开放
在后续的发展中,DataFlow 将继续扩展其功能和技术支持,以适应快速变化的技术环境和用户需求。未来我们将:
Part.1 丰富 Pipeline 模板和工具集
增加数据处理 Pipeline 模板和工具集,扩展平台的功能覆盖面,满足更多样化的数据处理需求。
Part.2 优化用户体验
继续优化用户界面和操作流程,提供更多可视化工具和报告功能,帮助用户更好地理解数据处理过程和结果。
Part.3 扩展分布式计算能力
支持更多分布式计算框架,以进一步提高数据处理的效率和可扩展性,满足未来更加复杂的数据需求。
Part.4 增强智能化和自动化
引入更多智能优化功能,进一步提升平台智能度,优化数据管理过程。
Part.5 加强安全性和合规性
引入更多安全加密技术和合规管理工具,确保数据在处理和传输过程中始终得到充分保护。
另外,OpenCSG即将把数据处理工作流引擎模块开源开放,拥抱社区的力量,为你的数据处理流程带来前所未有的灵活性和效率。我们将把这一创新的数据工作流引擎开放开源,让数据处理的力量触手可及。
DataFlow工作流引擎的设计哲学是:解耦合、复用与扩展、性能优化和易于管理。我们相信,通过将数据处理操作进行解耦,不仅可以提高代码的可维护性和可读性,还可以让用户根据需求轻松定制数据处理流程。DataFlow工作流引擎的模块化设计,意味着你可以随时添加或移除处理步骤,或者引入全新的数据处理操作,无缝实现扩展。
随着OpenCSG DataFlow工作流引擎的即将开源,我们正开启一段充满潜力的旅程。我们邀请开发者、数据科学家和所有对数据处理充满热情的人加入我们,共同探索这一模块化、高性能且易于管理的数据处理工作流引擎的无限可能。立即加入我们,让我们共同定义数据处理的未来。
最后,DataFlow 正以其卓越的性能和灵活性,为用户提供高效、可靠的数据处理解决方案。作为 OpenCSG 的战略产品之一,DataFlow 将持续推动数据管理技术的发展,为用户提供更加优质的服务和支持。未来,OpenCSG 将继续与各行业的合作伙伴携手,推动数据管理和大模型技术的创新,助力更多企业在数据驱动的新时代中脱颖而出。