1 数据结构说明
Sorted Set 的主要数据结构之一,负责根据元素的分数进行排序和提供快速访问。
主要方法在 t_zset.c 文件中
2 数据结构
c
/* ZSETs use a specialized version of Skiplists */
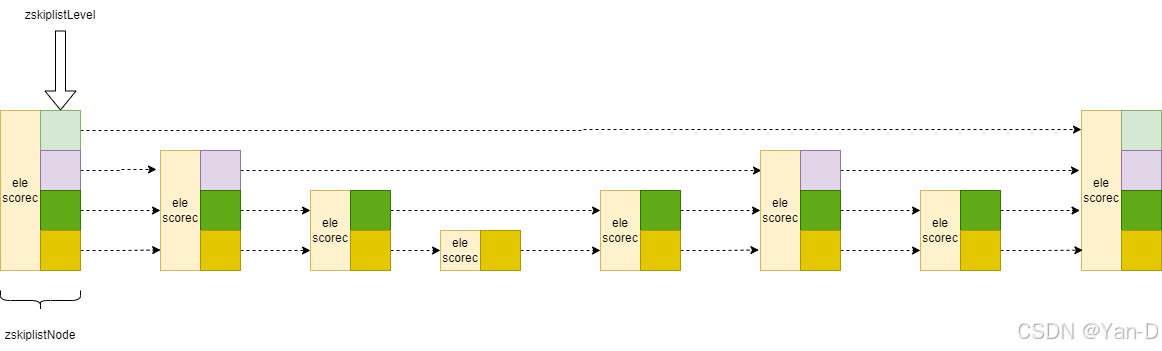
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;zskiplistNode 结构体
sds ele: 一个动态字符串(Simple Dynamic String),用于存储节点的实际元素值。double score: 一个双精度浮点数,表示节点的分数,这是用来排序的关键值。struct zskiplistNode *backward: 指向当前节点的前一个节点的指针,用于在跳跃表中反向遍历。struct zskiplistLevel level[]: 这是一个变长数组,每个元素都是一个zskiplistLevel结构体,代表跳跃表的一个层级。数组的大小取决于跳跃表的层数。
zskiplistLevel 结构体
struct zskiplistNode *forward: 指向当前层级下一个节点的指针。unsigned long span: 表示从当前节点到forward节点之间跨越了多少个节点(包括forward节点本身)。
zskiplist 结构体
struct zskiplistNode *header, *tail: 分别指向跳跃表的头节点和尾节点。头节点通常是一个虚拟节点,它不存储实际的数据。unsigned long length: 记录跳跃表中的节点数量。int level: 当前跳跃表的最大层数。
zset 结构体
dict *dict: 一个字典,用于存储元素到分数的映射,并保证元素的唯一性。字典的键是元素(ele),值是分数(score)。zskiplist zsl: 一个跳跃表,用于根据分数对元素进行排序。跳跃表中的每个节点都包含了一个元素及其对应的分数。
3 核心代码
zslCreate 创建跳表
c
zskiplist *zslCreate(void) {
int j;
zskiplist *zsl;
// 分配内存给 zskiplist 结构体
zsl = zmalloc(sizeof(*zsl));
// 初始化跳跃表的层数为 1
zsl->level = 1;
zsl->length = 0;
// 创建一个虚拟头节点,其层级为 ZSKIPLIST_MAXLEVEL,分数为 0,元素为 NULL
zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL);
// 初始化头节点的每一层
for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {
zsl->header->level[j].forward = NULL;
zsl->header->level[j].span = 0;
}
zsl->header->backward = NULL;
zsl->tail = NULL;
return zsl;
}zslInsert 插入元素
这个函数负责在正确的位置插入一个带有给定分数和元素的新节点,并维护跳跃表的结构。
c
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
unsigned int rank[ZSKIPLIST_MAXLEVEL];
int i, level;
// 确保分数不是 NaN
serverAssert(!isnan(score));
// 初始化 x 为头节点
x = zsl->header;
// 从最高层开始,向下遍历每一层,找到插入位置
for (i = zsl->level-1; i >= 0; i--) {
/* store rank that is crossed to reach the insert position */
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
rank[i] += x->level[i].span;
x = x->level[i].forward;
}
update[i] = x;
}
/* we assume the element is not already inside, since we allow duplicated
* scores, reinserting the same element should never happen since the
* caller of zslInsert() should test in the hash table if the element is
* already inside or not. */
// 随机生成新节点的层数
level = zslRandomLevel();
// 如果新节点的层数大于当前跳跃表的最大层数
if (level > zsl->level) {
for (i = zsl->level; i < level; i++) {
rank[i] = 0;
update[i] = zsl->header;
update[i]->level[i].span = zsl->length;
}
// 更新跳跃表的最大层数
zsl->level = level;
}
// 创建新的节点
x = zslCreateNode(level,score,ele);
for (i = 0; i < level; i++) {
// 将新节点插入到更新节点之后
x->level[i].forward = update[i]->level[i].forward;
update[i]->level[i].forward = x;
/* update span covered by update[i] as x is inserted here */
// 更新跨度
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
}
/* increment span for untouched levels */
// 更新未触及层级的跨度
for (i = level; i < zsl->level; i++) {
update[i]->level[i].span++;
}
// 设置新节点的 backward 指针
x->backward = (update[0] == zsl->header) ? NULL : update[0];
if (x->level[0].forward)
x->level[0].forward->backward = x;
else
zsl->tail = x;
zsl->length++;
return x;
}zslDelete 删除元素
c
int zslDelete(zskiplist *zsl, double score, sds ele, zskiplistNode **node) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
int i;
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
x = x->level[i].forward;
}
update[i] = x;
}
/* We may have multiple elements with the same score, what we need
* is to find the element with both the right score and object. */
// 确保找到了正确的节点
x = x->level[0].forward;
if (x && score == x->score && sdscmp(x->ele,ele) == 0) {
// 调用辅助函数删除节点
zslDeleteNode(zsl, x, update);
// 根据参数决定是否释放节点
if (!node)
zslFreeNode(x);
else
*node = x;// 如果提供了 node 参数,则将删除的节点指针赋值给它
return 1;
}
// 如果没有找到节点,返回 0
return 0; /* not found */
}
c
/* Internal function used by zslDelete, zslDeleteRangeByScore and
* zslDeleteRangeByRank. */
void zslDeleteNode(zskiplist *zsl, zskiplistNode *x, zskiplistNode **update) {
int i;
// 遍历每一层,更新跨度并调整 forward 指针
for (i = 0; i < zsl->level; i++) {
if (update[i]->level[i].forward == x) {
update[i]->level[i].span += x->level[i].span - 1;
update[i]->level[i].forward = x->level[i].forward;
} else {
update[i]->level[i].span -= 1;
}
}
// 更新 backward 指针
if (x->level[0].forward) {
// 如果 x 不是尾节点,更新 x 的下一个节点的 backward 指针
x->level[0].forward->backward = x->backward;
} else {
// 如果 x 是尾节点,更新跳跃表的 tail 指针
zsl->tail = x->backward;
}
// 如果最高层没有节点了,减少跳跃表的层数
while(zsl->level > 1 && zsl->header->level[zsl->level-1].forward == NULL)
zsl->level--;
// 减少跳跃表的长度计数
zsl->length--;
}总结
- 什么是 Redis 的 ZSET(Sorted Set)
- Redis 的 ZSET 是一种有序集合,它结合了 Set 的唯一性和 List 的排序功能。每个元素都有一个分数(score),元素根据分数进行排序。ZSET 支持高效的插入、删除和查找操作。
- ZSET 的内部实现是什么
- ZSET 内部使用两种数据结构:
- 跳跃表(Skip List):用于保持元素的有序性,并提供高效的插入、删除和查找操作。
- 字典(Dictionary):用于保证元素的唯一性,并存储元素到分数的映射关系。
- ZSET 内部使用两种数据结构:
- 跳跃表(Skip List)的优点是什么
- 高效的操作:插入、删除和查找的时间复杂度均为 O(log N)。
- 易于实现:相比平衡树(如 AVL 树或红黑树),跳跃表的实现更为简单。
- 范围查询:支持高效的范围查询操作。
- 为什么 ZSET 使用跳跃表而不是其他数据结构(如 AVL 树或红黑树)
- 简单性:跳跃表的实现比平衡树更简单,代码更容易理解和维护。
- 性能:跳跃表在大多数情况下提供了与平衡树类似的性能,但在某些操作上可能更优。
- 并发友好:跳跃表的随机访问特性使得在多线程环境下更容易处理。
- ZSET 的时间复杂度是多少
- 插入和删除:O(log N)
- 查找:O(log N)
- 范围查询:O(log N + M),其中 M 是返回的结果数量