本文根据2024云栖大会实录整理而成,演讲信息如下:
演讲人:
王 峰 | 阿里云智能集团研究员、开源大数据平台负责人
李 钰|阿里云智能集团资深技术专家
范 振|阿里云智能集团高级技术专家
李劲松|阿里云智能集团高级技术专家
蒋 乾|七猫免费小说数仓负责人
活动:
2024 云栖大会 - 开源大数据专场
基于向量化的大数据计算技术在近几年呈现爆发趋势,Databricks 推出了向量化 Spark 引擎-Photon,Facebook 开源了 Velox 向量化批计算引擎。向量化计算推动离线批计算能力大幅提升,与此同时业务时效性的提升也让企业对于实时流计算有了更多的需求。
在这样的背景之下,9月20日2024年云栖大会之上,阿里云阿里云智能集团研究员、开源大数据平台负责人王峰宣布阿里云实时计算 Flink 产品推出业界首款向量化流计算引擎-Flash,100%兼容 Apache Flink 业界流计算标准,且相对开源 Flink 具备5-10倍性能优势,助力企业在大数据实时化升级的道路上降本增效。

实时计算Flink版的 Flash 流计算引擎已开启邀测,欢迎用户通过工单和业务团队联系开通试用。
王峰表示:"我们对这项技术充满信心,计划通过阿里云向公有云领域推广,旨在服务于更多中小型客户。特别是那些已采用 Flink 的中小企业,或是云环境中的云原生企业,我们将使它们能够在无需修改代码的前提下,利用新的向量化兼容 Flash 引擎,达到降低成本并提升效率的目的。"

目前凭借在阿里巴巴内部生产环境中的超过10个业务部分,10万以上的 CU 规模进行了实际应用和业务测试,Flash 已成功助力业务方节省52%的平均成本,并展现出广泛的应用潜力。阿里云计划采取分阶段策略推广 Flash,以确保产品的稳定性和可靠性,同时也鼓励感兴趣的开发者和企业参与测试,共同探索向量化计算在大数据处理领域的更多可能。
一、开源大数据平台实现全面 Serverless 产品化
近年来随着大数据业务的快速发展和云原生技术的普及,计算服务 Serverless 化已经成为刚需,在本次云栖大会上,阿里云智能集团资深技术专家、EMR 团队负责人李钰宣布 EMR Serverless Spark 产品正式启动商业化。阿里云开源大数据平台已全面实现了 Serverless 产品化,包括 EMR Serverless Spark、EMR Serverless StarRocks、Serverless 实时计算 Flink 版等。
EMR Serverless Spark 是一款云原生,专为大规模数据处理和分析而设计的全托管 Serverless 产品。该产品自研向量化 Fusion 引擎,100% 兼容开源 Spark 编程接口,相比于开源 Spark 性能提升300%;提供交互式 Notebook 以及嵌入式 SQL Editor 开发环境、并提供版本管理、工作流调度、监控诊断等一站式平台能力;支持弹性伸缩、按量付费,进一步降低计算成本。结合 DLF 新一代湖仓数据管理平台,助力阿里云客户构建兼容开源和全面开放的数据湖仓解决方案。

今年是 EMR Serverless StarRocks 存算一体版本正式商业化一周年,自发布以来已在超过 500+ 生产客户,覆盖 20+ 行业落地 ,为企业提供稳定高效,开箱即用的全托管企业级数据平台的同时,也面临一些技术场景的挑战,在云栖大会上 EMR Serverless StarRocks 正式宣布推出商业化生产可用的 2.0 存算分离架构,提供了 StarOS 升级、Multi-Warehouse、弹性伸缩、内表优化、湖表优化等能力。
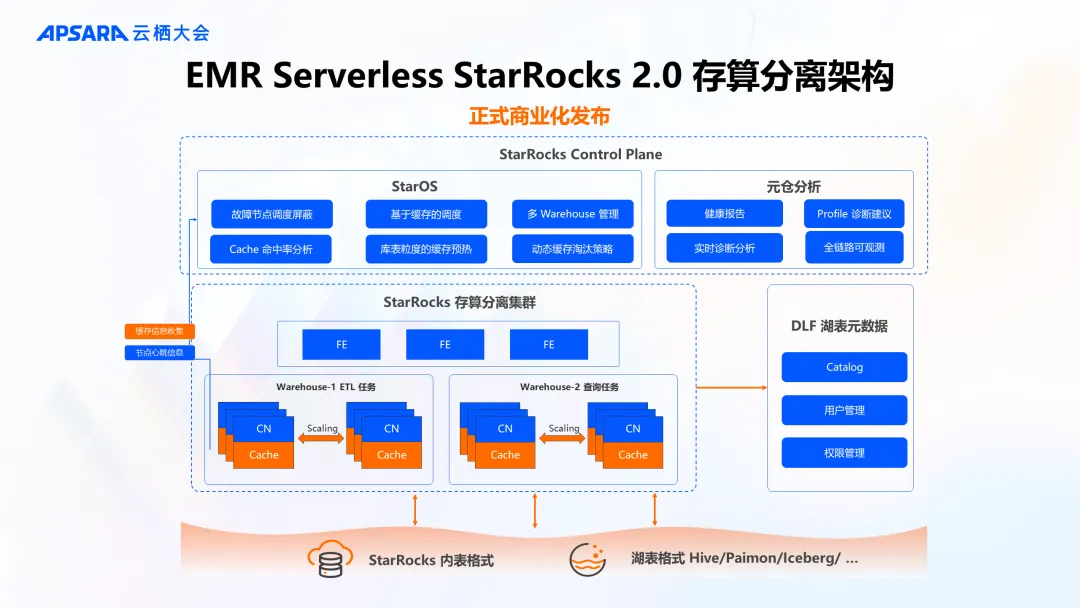
近年来,通过对大数据业务和在线业务进行离在线负载混部实现降本增效,逐渐成为客户的通用诉求。2024云栖大会上**EMR 管控平台的全面升级:**EMR on ACS 引入了与 ACS 的无缝集成、资源队列和定额(Quota)管理、作业监控及诊断分析功能,并新增对多计算引擎的支持;而在 EMR on ECS 产品形态中,全新推出了自动化弹性伸缩与智能化诊断分析能力。这些增强的能力都将助力客户智能化的实现在离线混部和降本增效。

二、阿里云湖仓架构全面升级
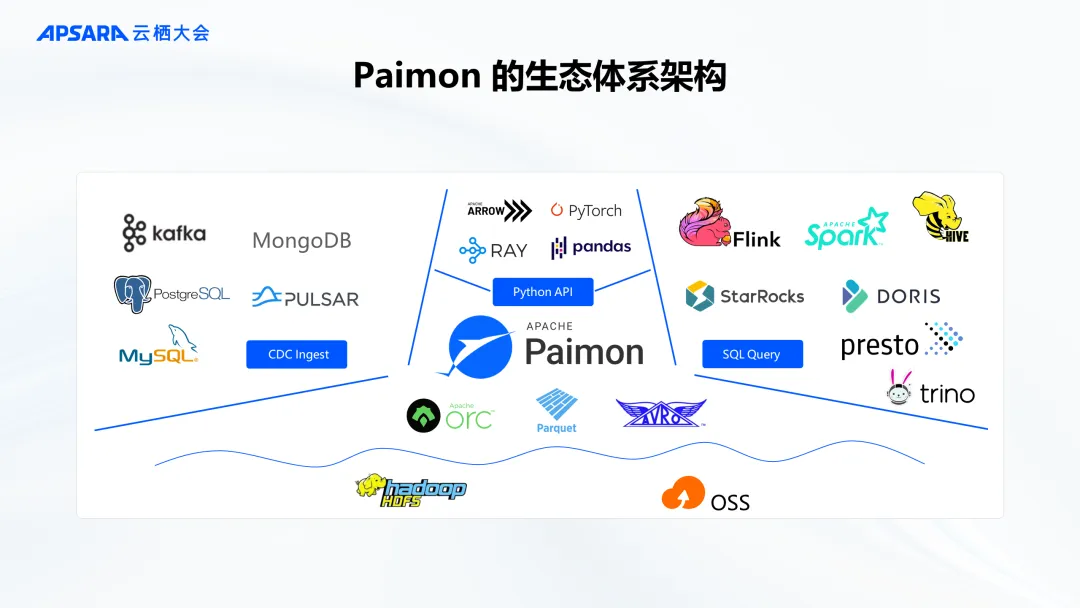
随着数据湖和数据仓库技术的不断演进,湖仓架构开始在数据基础设施中发挥关键作用,可帮助企业快速构建一体化数据分析平台,加速获取 AI 赋能的业务洞察,有效降低数据基础设施与管理成本。在这样的行业趋势之下,Apache Paimon 作为一种高性能、高扩展性的存储层,正成为构建实时湖仓架构的关键技术之一。
阿里云智能集团高级技术专家李劲松在2024云栖大会上介绍到了 Paimon 的发展历史以及 Apache Paimon 在 Streaming+实时场景的优势。Apache Paimon 作为一种高性能、高扩展性的存储层为用户提供了数据湖实时流式处理、湖上 OLAP 加速、数据湖非结构化处理等技术方案。
Paimon 自2022年从Flink社区开始孵化以来,短短两年,**已在越来越多的公司及场景落地,帮助业务更实时、更开放、成本更低的构建湖仓架构。**结合在2024云栖大会正式对外发布的阿里云 OpenLake 解决方案,企业可构建大数据、搜索、AI 一体化的能力体系,实现多模态数据统一纳管、多种计算引擎平权计算、大数据 AI 一体化开发,基于数据资产构筑竞争力。
三、七猫免费小说云上数仓实践
在2024年云栖大会的开源大数据专场上,七猫免费小说的数据仓库负责人蒋乾分享了关于云上数据仓库数据治理的最佳实践。**借助阿里云 EMR 的强大技术支持,七猫免费小说成功实现了数据仓库架构与数据治理的规范化和流程化演进,**核心体现在如下三个方面:
-
存算分离架构的升级:为数据处理提供了更高的灵活性和扩展性。
-
元数据和数据血缘的构建:为数据的追踪和管理奠定了坚实的基础。
-
数据治理实践:在数据治理的过程中逐步形成了规范的体系。

四、活动预告
Flink Forward Asia 2024 是一场大数据行业的盛会,将于11月29日至30日在上海举行。这是了解 Flink 社区最新动态和发展计划的绝佳机会,也是与国内外一线厂商分享生产实践经验、交流技术成果的重要平台。参与者可通过官网提交议题或报名参会。现在报名不仅可享受早鸟优惠,参会更有机会获得活动精美周边相送。无论您是开发者还是数据领域的从业者,都不可错过这场汇聚行业精英的盛会!

点击下方链接或扫描二维码立即报名并参与议题征集:
Flink Forward Asia 2024 - Apache Flink 官方峰会

欢迎各位踊跃报名,一起分享和学习现下流行新技术!