大家好,我是刘明,明志科技创始人,华为昇思MindSpore布道师。
技术上主攻前端开发、鸿蒙开发和AI算法研究。
努力为大家带来持续的技术分享,如果你也喜欢我的文章,就点个关注吧
正文开始
昇腾芯片集成了AICORE和AICPU等计算单元。其中AICORE负责稠密Tensor和Vector运算,AICPU负责复杂控制逻辑的处理。
为充分发挥昇腾芯片的运算、逻辑控制和任务分发能力,MindSpore提供了数据图下沉、图下沉和循环下沉功能,极大地减少Host-Device交互开销,有效地提升训练与推理的性能。MindSpore的计算图包含网络算子以及算子间的依赖关系。
从用户的视角来看,网络训练的流程如下:
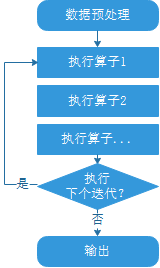
本教程以训练的执行流程为例介绍数据下沉、图下沉和循环下沉的原理和使用方法。
数据下沉
为了提升网络的执行性能,通常使用专用芯片来执行算子,一个芯片对应一个Device,Host与Device的一般交互流程如下:
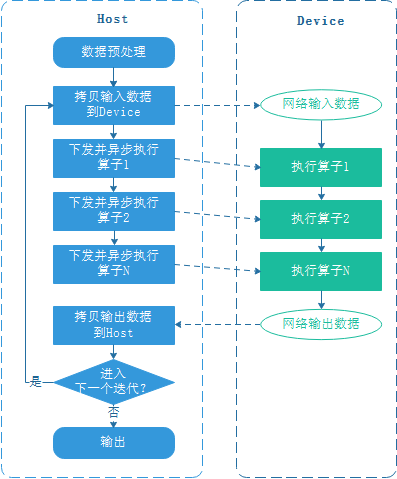
由上图可见,每个训练迭代都需要从Host拷贝数据到Device,可通过数据下沉消除Host和Device间拷贝输入数据的开销。
使能数据下沉后,MindSpore会在Device侧创建专门的数据缓存队列,MindSpore数据处理引擎使用高性能数据通道将数据的预处理结果发送到Device的数据队列上,计算图通过GetNext算子直接从数据队列拷贝输入数据,Host向数据队列发送数据和计算图从数据队列读取数据形成流水并行,执行当前迭代的同时可向数据队列发送下一个迭代的数据,从而隐藏了Host-Device数据拷贝的开销,MindSpore高性能数据处理引擎的原理参考这里。
GPU后端和昇腾后端都支持数据下沉,GPU数据下沉的Host-Device交互流程如下:
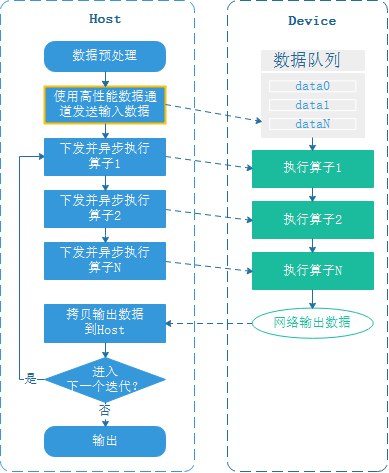
用户可通过train接口的dataset_sink_mode控制是否使能数据下沉。
图下沉
一般情况下,每个训练迭代都需要下发并触发device上每个算子的执行,Host与Device交互频繁。
为减少Host与Device的交互,在图编译时,将网络中的算子打包并一起下发到device,每次迭代只触发一次计算图的执行即可,从而提升网络的执行效率。
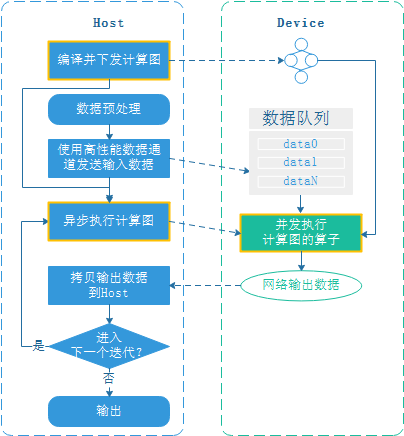
GPU后端暂不支持图下沉;使用昇腾设备时,开启数据下沉会同时启用图下沉。
循环下沉
启用数据下沉和图下沉后,每个迭代的计算结果都会返回Host,并由Host判断是否需要进入下一个迭代,为减少每个迭代的Device-Host交互,可以将进入下一个迭代的循环判断下沉到Device,这样等所有迭代执行完成后再将计算结果返回到Host。循环下沉的Host-Device交互流程如下:
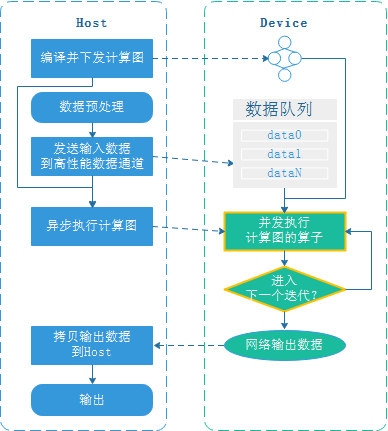
用户通过train接口的dataset_sink_mode和sink_size参数控制每个epoch的下沉迭代数量,Device侧连续执行sink_size个迭代后才返回到Host。
使用方法
Model.train实现数据下沉
Model的train接口参数dataset_sink_mode可以控制数据是否下沉。dataset_sink_mode为True表示数据下沉,否则为非下沉。所谓下沉即数据通过通道直接传送到Device上。
dataset_sink_mode参数可以配合sink_size控制每个epoch下沉的数据量大小。当dataset_sink_mode设置为True,即数据下沉模式时:
如果sink_size为默认值-1,则每一个epoch训练整个数据集,理想状态下下沉数据的速度快于硬件计算的速度,保证处理数据的耗时隐藏于网络计算时间内;
如果sink_size>0,此时原始数据集可以被无限次遍历,下沉数据流程仍与sink_size=-1相同,不同点是每个epoch仅训练sink_size大小的数据量,如果有LossMonitor,那么会训练sink_size大小的数据量就打印一次loss值,下一个epoch继续从上次遍历的结束位置继续遍历。
下沉的总数据量由epoch和sink_size两个变量共同控制,即总数据量=epoch*sink_size。
当使用LossMonitor、TimeMonitor或其它Callback接口时,如果dataset_sink_mode设置为False,Host侧和Device侧之间每个step交互一次,所以会每个step返回一个结果,如果dataset_sink_mode为True,因为数据在Device上通过通道传输,Host侧和Device侧之间每个epoch进行一次数据交互,所以每个epoch只返回一次结果。