Deforum 与 AnimateDiff 不太一样,
AnimateDiff 是生成丝滑变化视频的,而 Deforum 的丝滑程度远远没有 AnimateDiff 好。
它是根据对比前面一帧的画面,然后不断生成新的相似图片,来组合成一个完整的视频。
Deforum 的优点在于可控性好,提示词的变化,镜头的运动方向,画面的变化程度,以及噪声加入的多少,甚至中途改变模型都可以控制。
通过 Deforum 可以很清晰的制作瞬息全宇宙的动态视频效果。
安装
插件下载地址:https://github.com/deforum-art/sd-webui-deforum
解压后,将文件夹放置在:SD安装目录\extensions
重启UI 后,即可在顶部看到 Deforum 的标签:

实操应用
由于 Deforum 是需要不停的画面变化,因此最好选择通用性较好的大模型来生成视频。
运行Tab
在该 Tab 页面,可设置采样方法,视频的宽高,默认是使用随机种子来不断生成图片,如果是生成人物,建议勾选☑️「面部修复」:

提示词Tab
这里填写的提示词,一定要按照官方格式来修改填写,
下方可设置固定的正反向提示词:
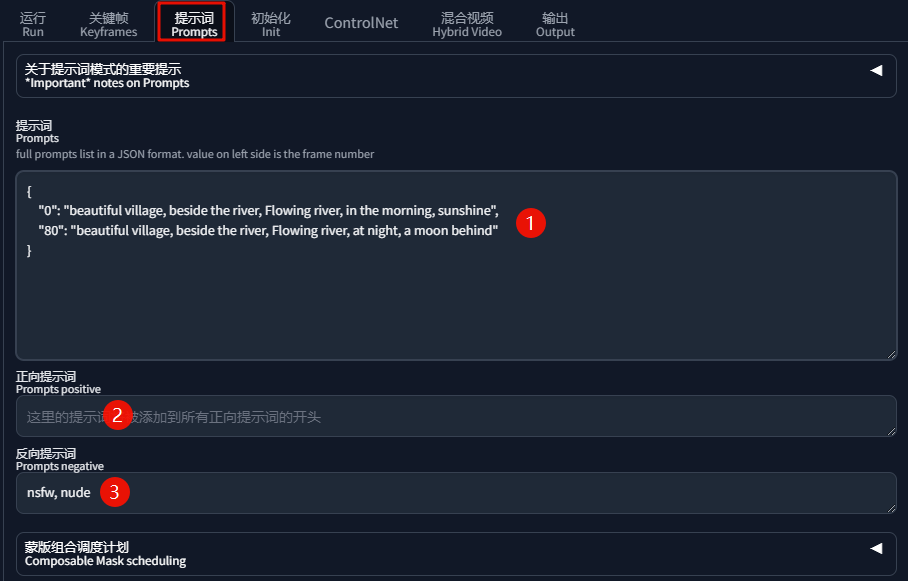
填写好提示词后,其他保持默认值,点击「生成」,等待出图。
生成完毕后,点击图片上方「生成完成后点这里显示视频」即可加载视频,再点击「播放」:

把视频下载⏬下来:

关键帧Tab
「动画模式」无脑选择「3D」即可,因为「3D」是具有最丰富的镜头运动参数的;
「边界处理模式」有两个选项:
- 复制:以视频的上一帧的边缘来扩展图片
- 覆盖(推荐!!!):根据上一帧画面整体来产生画面,不受边缘限制,能让 AI 更具想象力

「生成间隔」(关键参数!!!):
这里的 2 表示:2帧画面,其中1帧是生成的,另外1帧由软件通过插值的方式自动补上去;
因此,数值越大,生成的帧数越少,剩下的都由插值补上,生成速度越快,并且闪烁减少,但清晰度也相对越差:

「强度」:前一帧影响下一帧的强度,数值越大,前后画面的关联性越强;
下图中,0帧是以0.75的关联度来开始变化的,如果发现白天与黑夜间的变化效果不明显,
可补充输入70:(0.6):指的是,70帧后,关联性降到0.6,以便 AI 有更多的创造性:

「迭代步数」、「采样方法」、「模型」都可以指定具体的帧数进行切换,其他的选项卡,保持默认即可:
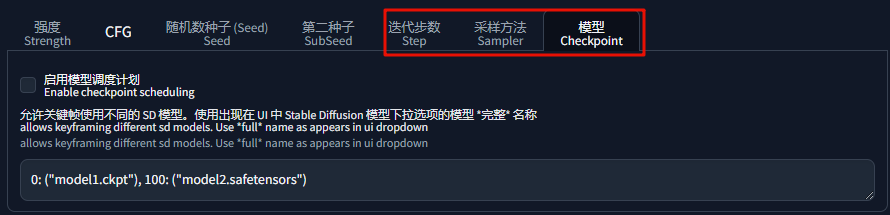
重新调整参数后,完整视频如下:
超过5M,无法添加
今天先分享到这里~
开启实践: SD绘画 | 为你所做的学习过滤