由于 SD 具有强大的可控性,在固定人物角色方面,SD 是远超 MJ 的,
其中最好用,也是最优先的方法就是训练一个自己专属的角色模型,例如之前使用秋叶训练器得到的 LoRA模型。
另外,如果不想自己训练模型的话,可以到网上下载别人已经训练好的专门角色 LoRA:

按照详情页的要求,加载 LoRA,填写对应的触发词,开始生成:
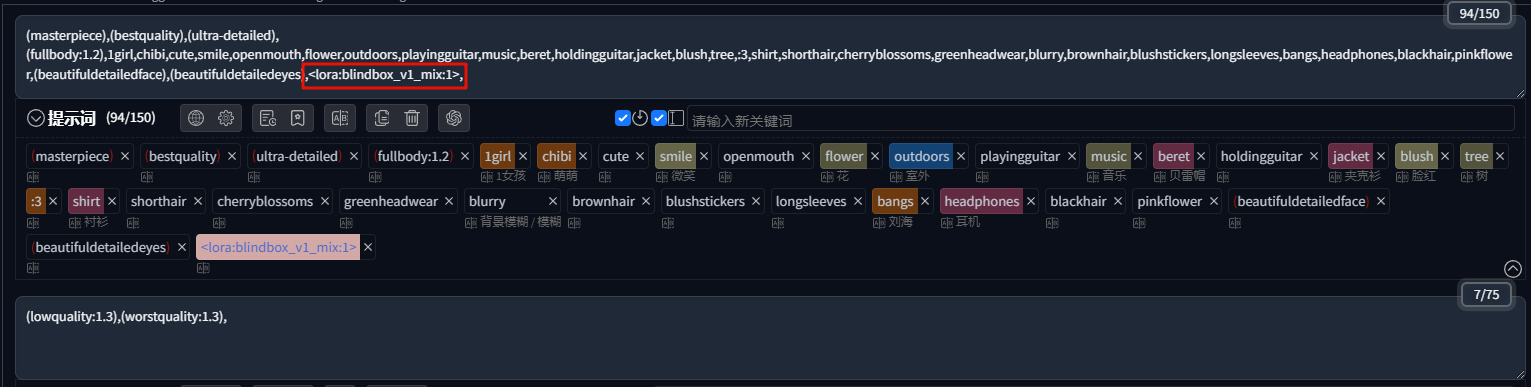
生成得到的4张图,人物风格就基本固定了:

个性角色生成
最后一种情况,就是我们需要的角色比较特别,网上找不到,而且又不想自己生成模型,哪还有没有办法?
我们输入提示词,自己生成一个角色:
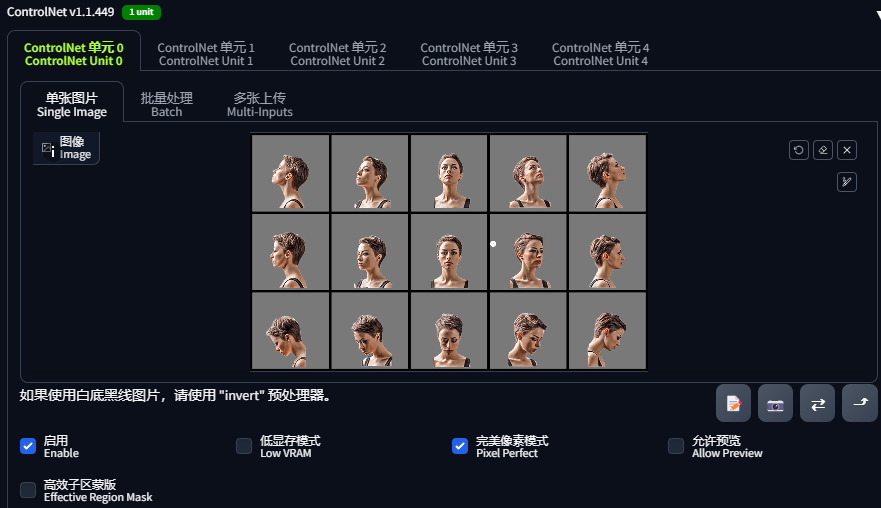
开启第一个 ControlNet,加载一张包含全角度头像的图片:
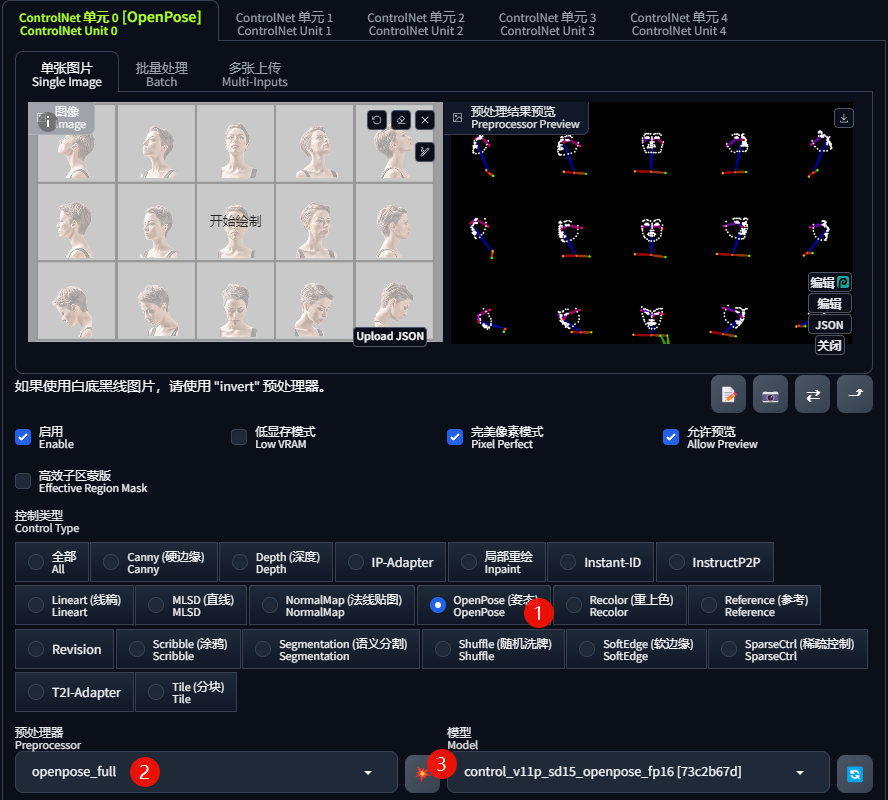
获取图片分辨率,控制类型选择「OpenPose」,预处理器选择「openpose_full」,点击💥,能得到所有的头像表情:
开启第二个 ControlNet,上传对应的网格图片,能有效防止头像与头像之间的污染问题:

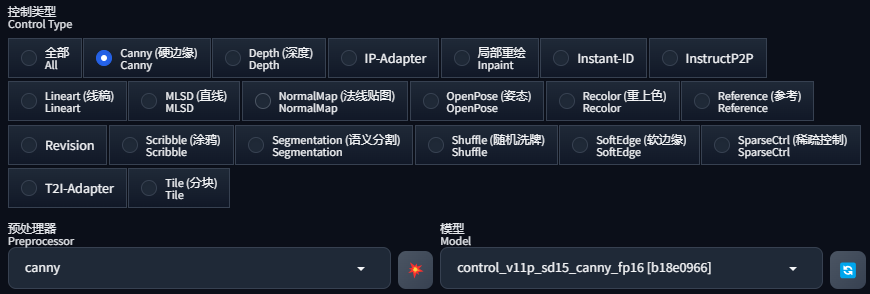
控制类型选择「Canny」:
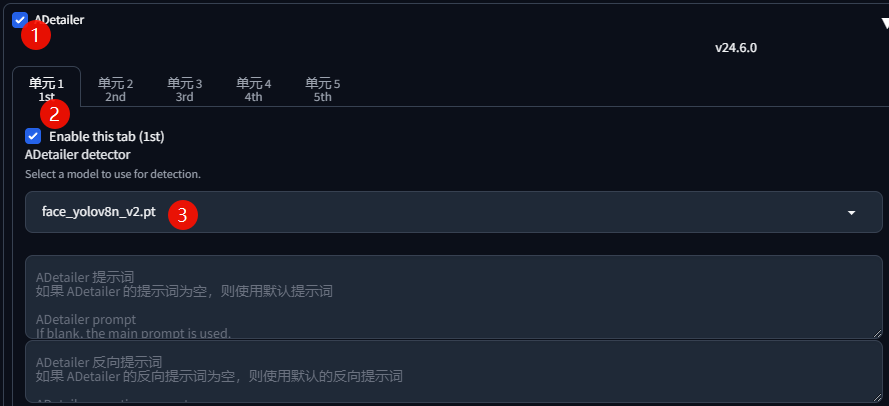
由于涉及到的头像很多,必须要开启「ADetailer」:
同时开启高清修复:

完成以上的一些列配置,点击「生成」。
由于是在同一前空间生成的图片,角色一致性能够得到很好的统一,
如果某些角度生成的头像达不到预期的效果,只需要重新生成一次即可,毕竟这是在抽卡,全凭运气。
来看看成品!
第一个是迪士尼风格的:

第二个是插画风格的:

今天先分享到这里~
开启实践: SD绘画 | 为你所做的学习过滤