目录
[这里解释下 Using join buffer (Block Nested Loop):](#这里解释下 Using join buffer (Block Nested Loop):)
[(1)Nested Loop Join](#(1)Nested Loop Join)
[(2)Block Nested Loop Join](#(2)Block Nested Loop Join)
[(3)Index Nested Loop Join](#(3)Index Nested Loop Join)
[DBdoctor SQL审核-识别多表Join问题](#DBdoctor SQL审核-识别多表Join问题)
多表join问题SQL
对于某个复杂业务场景,通常需要根据多个过滤条件才能拿到两个表中的信息。例如,某开发同事费了半天劲写了一个多表join的SQL实现了功能,但上线后却发现对应接口响应特别慢,通过一步步排查后才定位到问题SQL,SQL如下:
select cell.*, res.pod_name from dbfree.dbins_cell cell right join dbfree.dbins_resource res on
cell.ip = res.pod_ip where cell.ip in ('10.174.156.14', '10.174.187.144', '10.174.67.11') and
res.path in ('/dev/sdb6', '/dev/sdb5') order by res.namespace;看下该问题SQL的执行计划:

执行计划中可以看到两个表的type都是ALL,且cell表的Extra中出现 Using join buffer (Block Nested Loop),代表两个表发生了全表扫描,且使用了join buffer。
这里解释下 Using join buffer (Block Nested Loop):
-
Using join buffer:表示 MySQL 在执行JOIN时使用了连接缓冲区。这意味着外层表的部分行被加载到内存中,以便与内层表进行匹配。
-
(Block Nested Loop):指的是 MySQL 使用了块嵌套循环算法,而不是简单的嵌套循环。这种方法优化了JOIN操作,尤其是在内层表没有索引时,能够提高连接的性能。
对性能产生的影响:
-
内存使用: 使用连接缓冲区意味着 MySQL 会消耗更多内存,因此可以处理更大块的数据,从而减少 I/O 操作并提高性能。
-
缺乏索引 : 这个提示通常表明内层表缺乏合适的索引,导致 MySQL 需要通过全表扫描的方式来处理
JOIN操作。虽然Block Nested Loop比简单的嵌套循环更高效,但相较于使用索引,仍然可能比较慢。
三种join算法介绍
join操作是一种将两个或多个表的行结合起来的方法,本质就是把各个表中的记录都取出来依次匹配的组合加入结果集并返回给用户。
例如SQL:
select * from employee e join department d on e.id = d.employee_idjoin操作主要使用以下几种算法:
(1)Nested Loop Join
这是最基本的连接算法,也被称为嵌套循环连接。对于第一个表中的每一行,它会扫描第二个表中的所有行来寻找匹配的行。这种方法的效率通常较低,特别是当表的大小增加时,因为它需要进行大量的磁盘I/O操作。
相当于两个嵌套for循环:
for(employee表行 eRow : employee表){
for(department表的行 dRow : department表){
if(eRow.id = dRow.emp_id){
return eRow;
}
}
}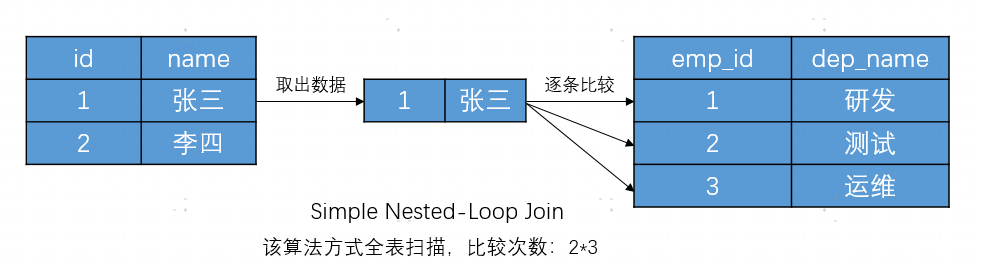
例如 employee 表有2行,department表有3行,Nested Loop Join 算法的开销如下:
-
每一次循环,employee表扫描1次,department表比较3次
-
共有2次循环,比较 2 * 3 = 6次
MySQL不会简单的使用Nested Loop Join,而是利用buffer,即Block Nested Loop Join。
(2)Block Nested Loop Join
这是一种改进的嵌套循环连接算法,核心思路是减少内层表的扫表次数,它使用了一个叫做连接缓冲区(join buffer)的内存结构来减少磁盘I/O操作。将第一个表按照join_buffer_size的大小进行分块(Block),将每个块作为一批数据放入缓存(而不是单独的一行),它会扫描第二个表中的所有行来寻找匹配的行。这种方法的效率通常比嵌套循环连接要高。
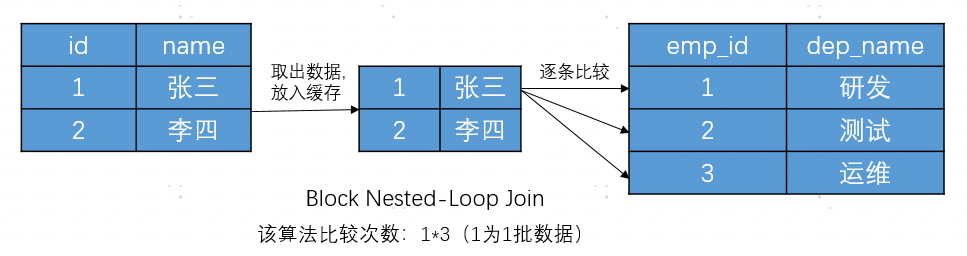
Block Nested Loop Join 算法有以下特点:
-
当执行计划中的type为ALL、INDEX或RANGE时,可以使用buffer。
-
可以修改参数optimizer_switch中的block_nested_loop,设置是否开启该算法,默认为on。

-
如果buffer大小配置的足够大,可以将employee表的全部数据放入,则department表仅需要扫表1次。join_buffer_size默认大小为256K。
-
增大buffer_size是一种优化思路,同理,去除不必要的查询字段,减少需要放入buffer中的数据也是一个方向。
-
在MySQL 8.0.18版本及以后,使用 hash join代替Block Nested Loop Join,基本思想是将驱动表的数据加载到内存(数据大小超过join_buffer_size时加载到磁盘,性能会变差),并建立hash表,这样只需要遍历一次驱动表,然后再去通过hash表寻找匹配的行。
(3) Index Nested Loop Join
这是一种改进的嵌套循环连接算法,核心思路同样是减少内层表的匹配次数,需要关联字段在被驱动表中建立索引。对于第一个表中的每一行,它使用索引来查找第二个表中的匹配行,而不是扫描整个表。这种方法的效率通常比嵌套循环连接要高,但前提是必须有适当的索引。
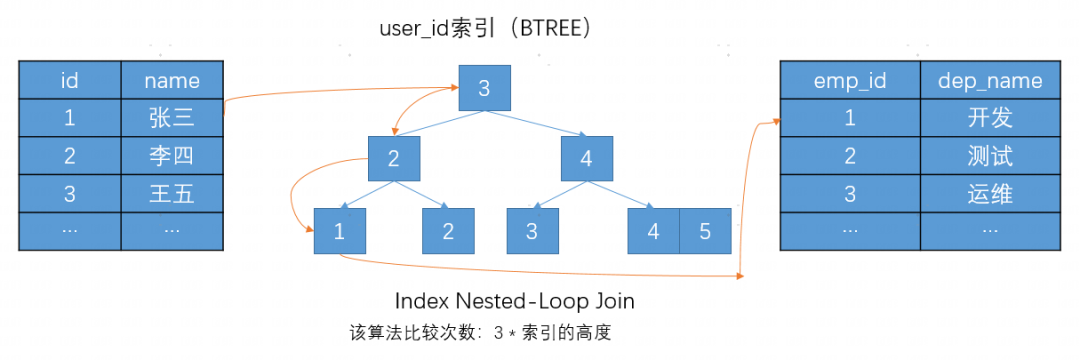
有了合适的索引后,Index Nested-Loop Join算法可以将匹配次数由 外层表行数 * 内层表行数 减少为 外层表行数 * 内层表索引的高度。
问题定位
综上所述,编写多表join的SQL时,通常的连接优化方向如下:

再回过头来看文章最开头的问题SQL
select cell.*, res.pod_name from dbfree.dbins_cell cell right join dbfree.dbins_resource res on
cell.ip = res.pod_ip where cell.ip in ('10.174.156.14', '10.174.187.144', '10.174.67.11') and
res.path in ('/dev/sdb6', '/dev/sdb5') order by res.namespace;可以从以下几个角度排查问题:
-
关联字段是否有索引
-
若关联字段有索引,索引有没有失效
-
小表驱动大表
-
不要使用 * 作为查询列,只返回需要的列
经排查发现,被驱动表cell的关联字段ip不存在索引,DBA认为找到问题了,可是给字段cell.ip加上索引后,再次查看执行计划。

咦,驱动表怎么换了?执行计划中第一行为驱动表,第二行为被驱动表。cost优化器认为经过where cell.ip in 条件过滤后的cell表数据更少,更适合作为驱动表。DBA继续给res.pod_ip加索引,再次查看执行计划。

执行计划中type没有all了,但是第二行res表的ref怎么是func?连接条件为等值查询,字段cell.ip和res.pod_ip类型均为varchar,怎么还会有函数操作?
func表示索引查找涉及函数或表达式 :当你在JOIN或WHERE子句中使用了函数或表达式(比如字符串函数、日期函数、数学运算等),MySQL 可能无法直接使用索引 进行等值匹配,而是会调用某个函数来计算结果。这会导致 MySQL 在执行计划中显示ref为func。
DBA没招了,那就用DBdoctor吧,其免费的SQL审核功能可以很方便的发现多表Join的相关问题。
DBdoctor SQL审核-识别多表Join问题
在DBdoctor 3.2.3 版本中,完善了SQL审核的全生命周期覆盖,自动闭环审核出的问题SQL,新增了SQL审核静态规则 300+,其中就有部分和多表join相关的规则。
将问题SQL放入SQL窗口,点击审核。
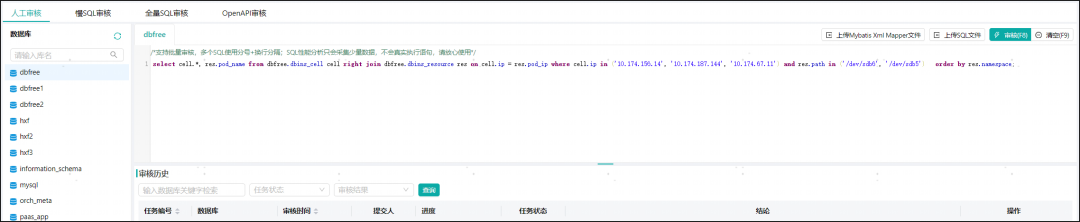
审核任务报表中出现多表关联,关联字段charset不同,导致索引失效。
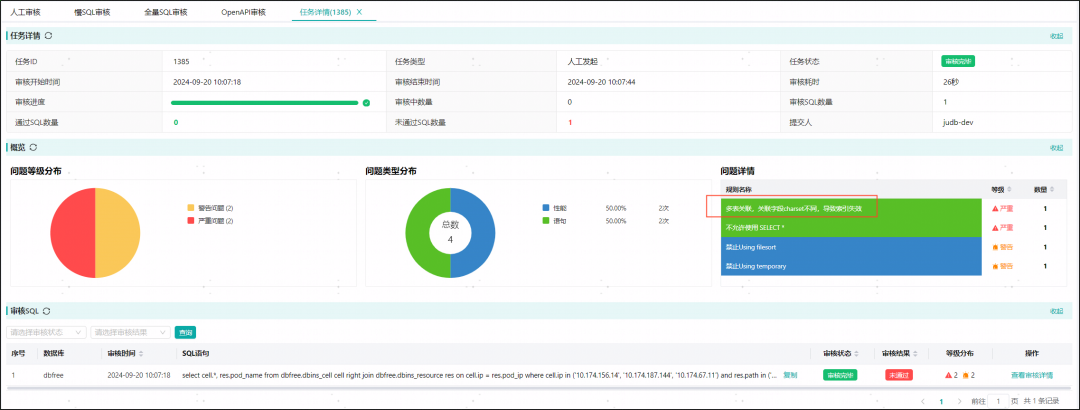
点击查看审核详情,展示了每条命中规则的解释和建议;除命中规则外,DBdoctor通过自研Cost优化器给出了各个索引的性能分析结果,并基于此推荐了最优索引。
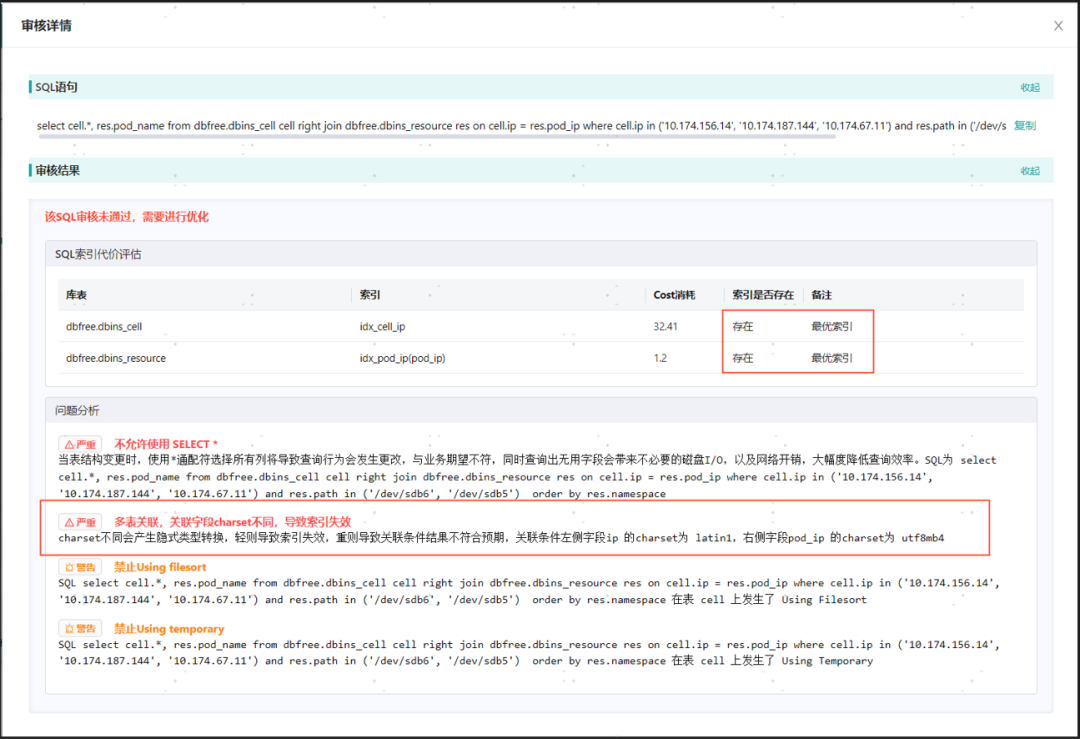
可以看到
- 问题分析部分,有一条严重问题:**多表关联,关联字段charset不同,导致索引失效,**关联条件左侧字段ip 的charset为 latin1,右侧字段pod_ip 的charset为 utf8mb4。
那这条sql的问题就非常清楚了,关联字段的charset不一样!
开发同学修改cell表的字符集,再次查看执行计划:

可以看到被驱动表type为ref,ref列中使用了索引dbfree.cell.ip,至此问题解决。
但是驱动表中的extra信息出现了Using filesort、Using temporary,详细介绍可参考《一条SQL使用order by,引发IO问题》《MySQL Using temporary案例详解及优化方法》
总结
编写多表join的SQL时,需要注意关联字段是否使用索引、小表驱动大表、适当调整join buffer大小等。DBdoctor 3.2.3版本提供了强大的SQL审核工具,它可以帮助开发者在代码部署前识别并解决潜在的SQL问题。现在,小伙伴们可以免费体验这项功能,提升你的数据库性能和稳定性。立即下载DBdoctor,让你的SQL编写更加高效和安全!
*****************************************************************************