最近这个其实提的人挺多的,Graph RAG的火爆已经是上上个月的事了,其实我之前就讲过,Graph RAG是解决什么问题的,它也没法绝对替代传统RAG
之前关于Graph-RAG的文章
不说Graph擅长得全局问题,和关系梳理,就说它有得干不了得传统RAG领域,其实传统RAG在自己得领域干得也不见得就咋好,Athropic最近推得Contextual Retreival 其实是个不错得改进方案。
它具体能改善哪里呢?
举个最简单得例子,你提了一个问题
"What was the revenue growth for ACME Corp in Q2 2023?"
其实最有用得一个答案是
"The company's revenue grew by 3% over the previous quarter."
然后你经过向量数据库,基本不可能选到这个答案为最优,因为上面所谓得The company和 previous quarter都不太能和ACME Q2 2023有太多语义上得关联,余弦或者欧式,你用啥距离都没用。
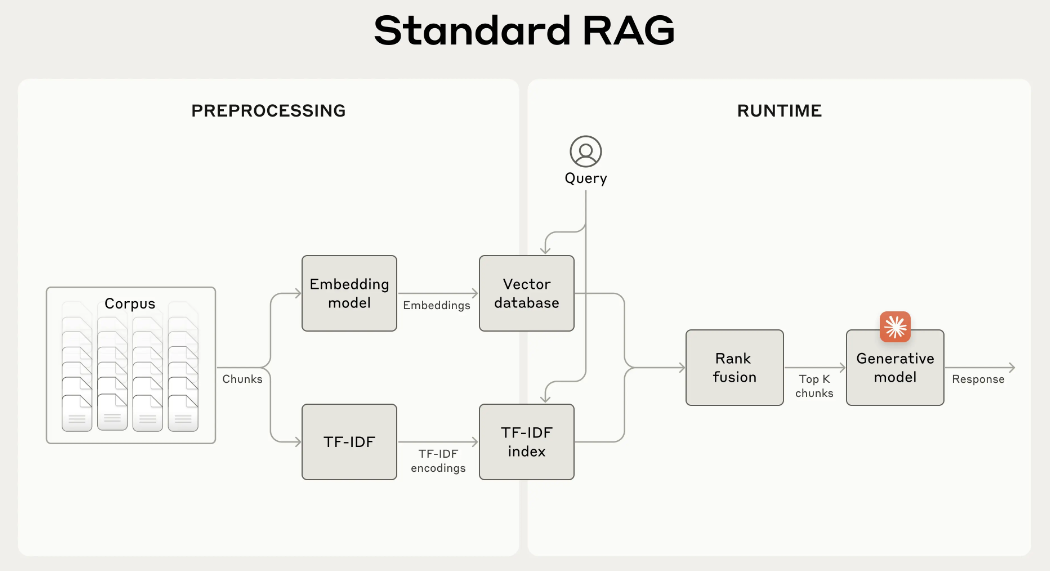
有人说用Hybrid RAG是不是能强点,比如上图,此时,你是加BM25 关键字,还是加Graph-RAG都没啥用,你懂得,因为回答是一系列得"The"指代,并没有和问题中得描述有关键字匹配,也没法建立节点和边得关系。
我们进一步观察问题和答案,是不是这俩东西要是能有点关联性就好了啊,比如切出来得chunk,我给转换一下
original_chunk = "The company's revenue grew by 3% over the previous quarter."
contextualized_chunk = "This chunk is from an SEC filing on ACME corp's performance in Q2 2023; the previous quarter's revenue was $314 million. The company's revenue grew by 3% over the previous quarter."如上面所示,原始得chunk,是两个"The",导致不管是embedding还是BM25都抓不出来它,那要是把original_chunk,通过某种手段,给转换成下面这种contextualized_chunk,把上下文信息给注入到chunk离,这下,如果还是刚才得问题,那必然是一问一个准。
那这个带上下文信息得chunk是咋生成得?
其实和你graph-rag一样,还得让大模型给你生成
graph-rag是让大模型给你生成图,既点和边还有各种声明,contextualized retrieval,是让你切chunk得时候,再把文档给一起带过去,然后给你切得这块chunk,带上上下文得信息。
其实单就原理来说,就这样,贼简单
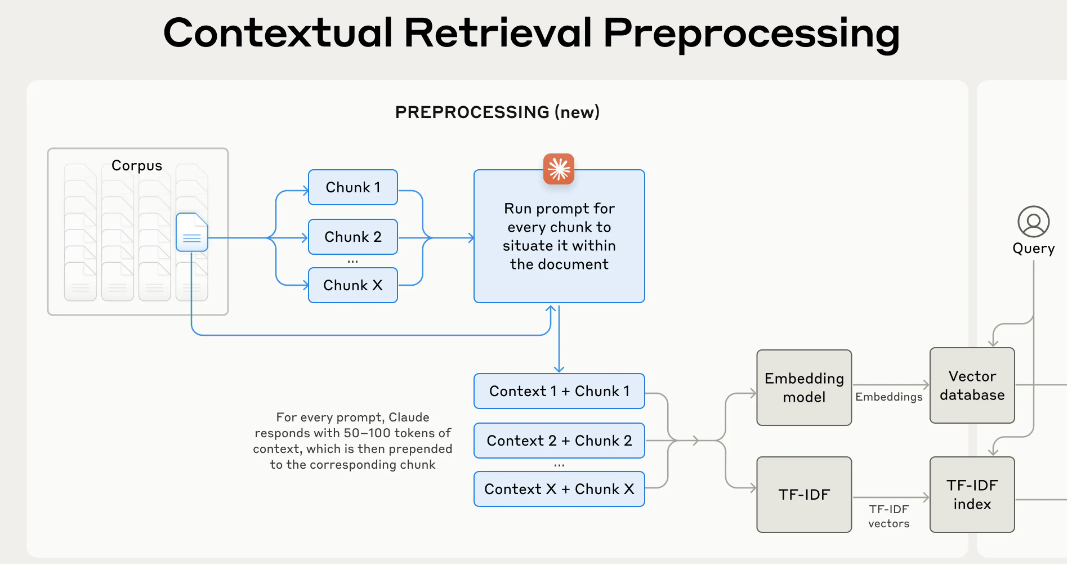
上面这段操作给个prompt就能实现
<document> {{WHOLE_DOCUMENT}} </document> Here is the chunk we want to situate within the whole document <chunk> {{CHUNK_CONTENT}} </chunk> Please give a short succinct context to situate this chunk within the overall document for the purposes of improving search retrieval of the chunk. Answer only with the succinct context and nothing else.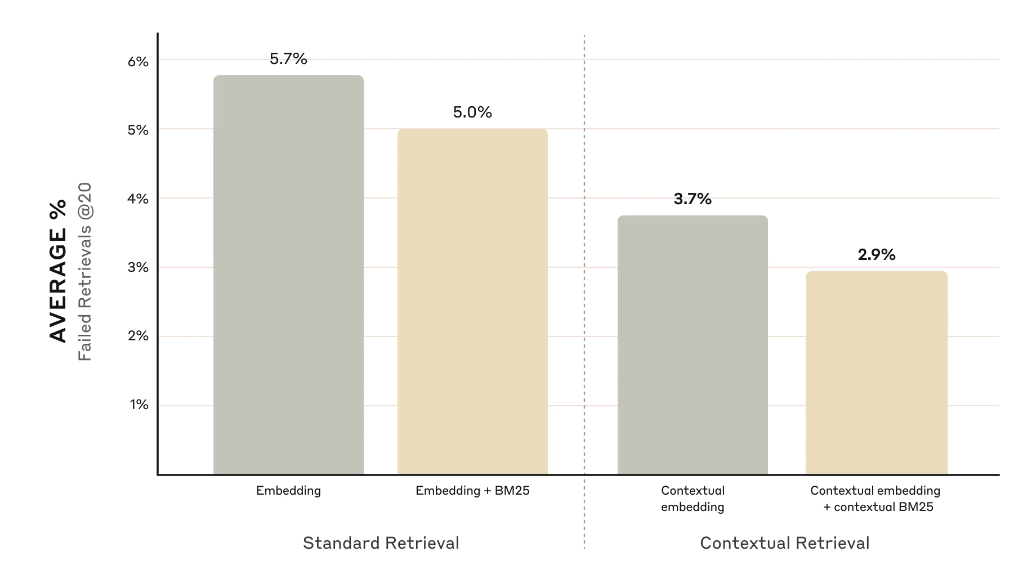
A家自己测试发现用了Contextual Retrieval以后 RAG的错误率能直接下一半下去,这对于查询的命中率提升其实非常高了。
然而细心的观众老爷也发现了吧,这玩意费token啊,这要没事给一个chunk加上下文,就要发一遍全文,谁受得了啊
所以实际上项目里可实现的方法主要有2个
1- 滑动窗口吧,别所有的chunk都给全文,根据chunk在切分的文章位置,发一些文章的部分过去,这样能省不少。
2- prompt cache
prompt cache 也是最近比较火feature,说白了就是inbund token省钱
咋省钱呢,因为你没用它算力,虽然占AI服务商推理显存了

模型推理就是个单向的前向传播,这块没什么可讲的
那Transformer这东西推理实际上,是一个自回归,啥叫自回归呢,就是我要说:"我爱你",第一次我是推出来个"我",然后我用start of token+"我",来推出来"我爱"。以此类推,最后推出来"start of token+我,爱,你+EOT"
那你每次是不是推都要占算力,都要折腾一遍,于是乎空间换算力的又能省时间的东西KVcache就出来了,你第一遍推出来"我"。那你第二遍再做推理的时候就别再推"我"这个logit了,直接用就可以了,而"我"相关的放进显存中,下次推理直接用,以此类推。这也是最长用的推理加速方法,你们爱用的vllm类的推理加速最本质上就这么个简单的路子(不提及page attention和flash attention的话)
但是KVcache这玩意它只能做到到单序列的,也就是反正你这句话用了就用了,下一句别想用,说白了,到下一句话,你还得刷新显存,那CPU到显存到再GPU,你害的来回折腾数据。快也就快一句话。
那我要想快N多句呢?
也不是不行,这就是prompt cache做的事,因为你没法跨序列(sequence)来搞注意力,这个不太现实,所以你就得整一个外挂(这外挂甚至可以不是显存,就是大内存就成,反正几千个token的logit被你一次读,你也不会感觉慢,要不凭啥给你便宜?)
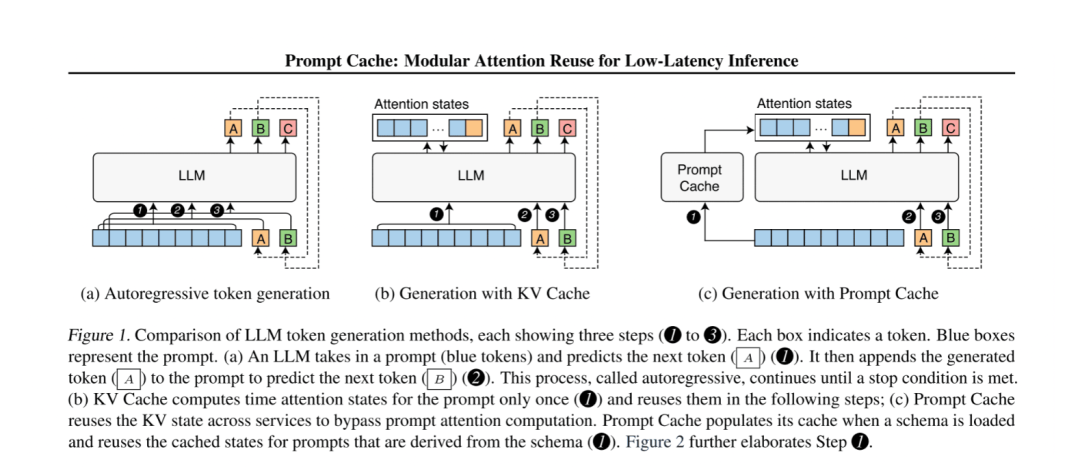
第一幅图是普通的推理,第二幅是加kv cache了,第三幅就外挂一个cache,这个cache就可以在多个序列之间cache已经算出来的logit,那它咋识别的?
答案是PML
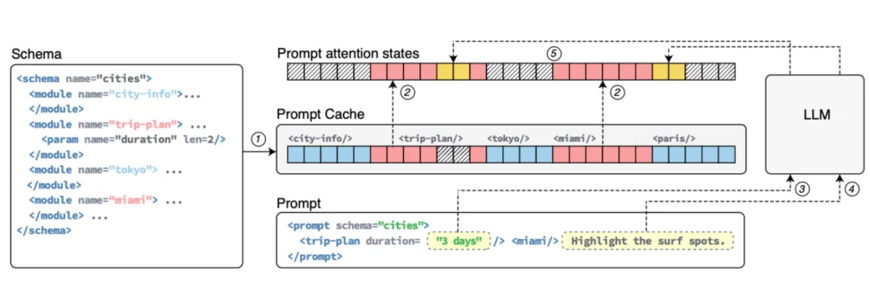
像上图所示 PML明确定义可重用的文本段,称为提示模块(prompt modules)。PML确保在重用注意力状态时位置的准确性,并为用户提供了一个接口来访问他们的提示中的缓存状态。
说白了,假如你用system prompt给LLM写一段贼老长的COS play 提示词,你就给它放倒prompt modules里,LLM通过PML,或者有些LLM原生可区分 prompt中的重用,或者API,就实现了prompt caching的能力
对于AI provider,其实这么做能省钱,省卡,对于user来说,这样能省钱,我们看一下对比
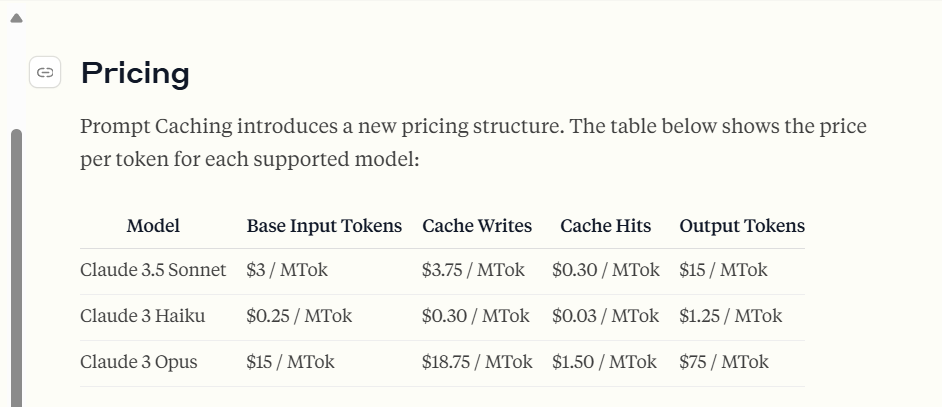
Claude的cache命中,直接省9/10的input token费用,但是需要注意的是,如果你要玩prompt caching,Athropic要多收你点前,写cache它们这边比较贵
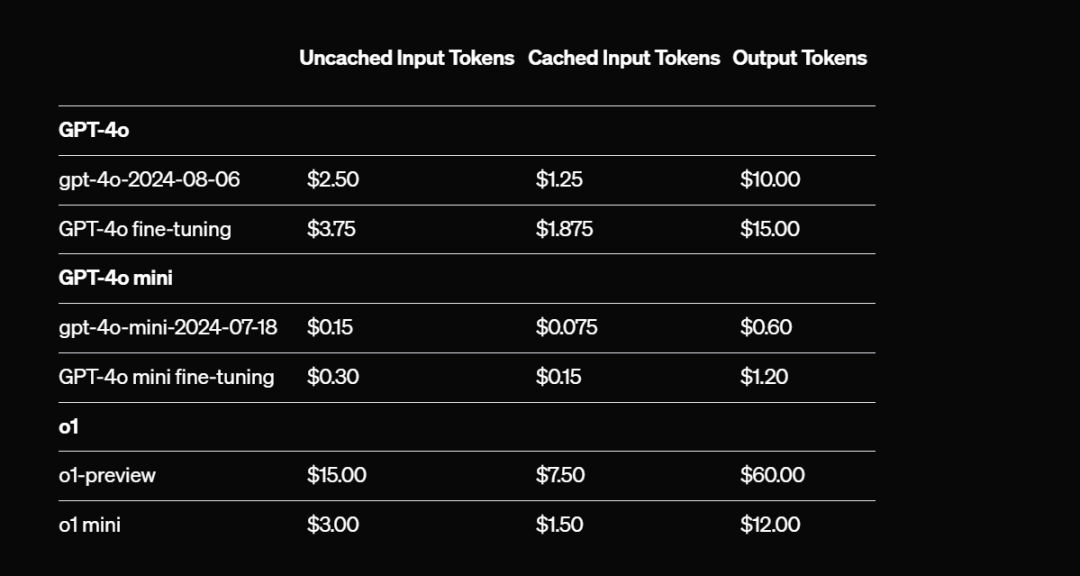
OpenAI就比较粗暴,就是减1半
但是OpenAI这个不需要你在API里写啥,你达到1024以上它就自动给你开,prompt caching来给你省钱,超过1024往上的,是每128个单位上一个台阶,这是自动的好处
因为没用PML,所以OpenAI自动也有自动的坏处
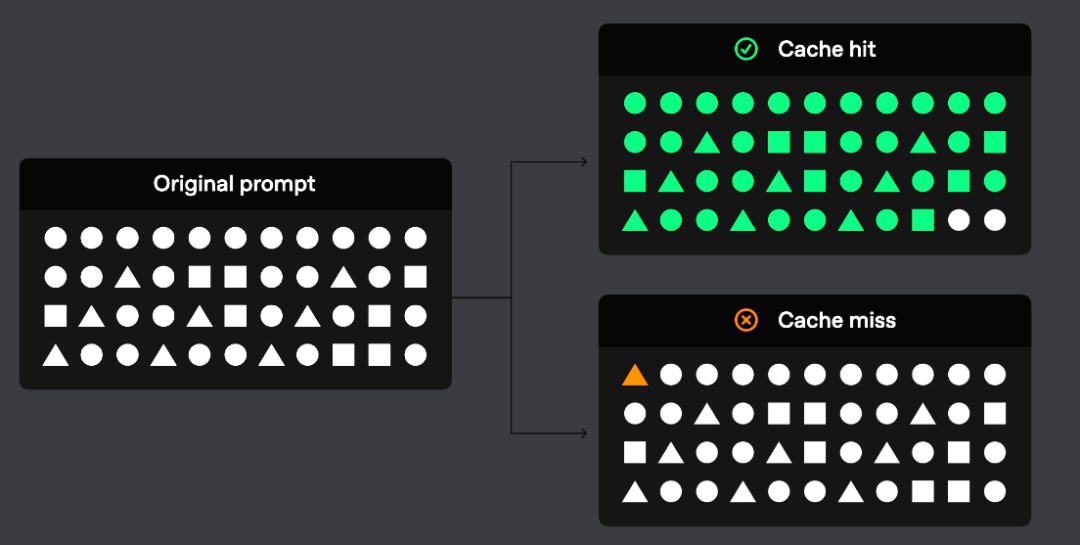
坏处就是你肯定尽量前面的东西要长得一样,不如中间差一个也不给你存,所以最好就用在system Prompt上面(其实一般也就用在system prompt上)
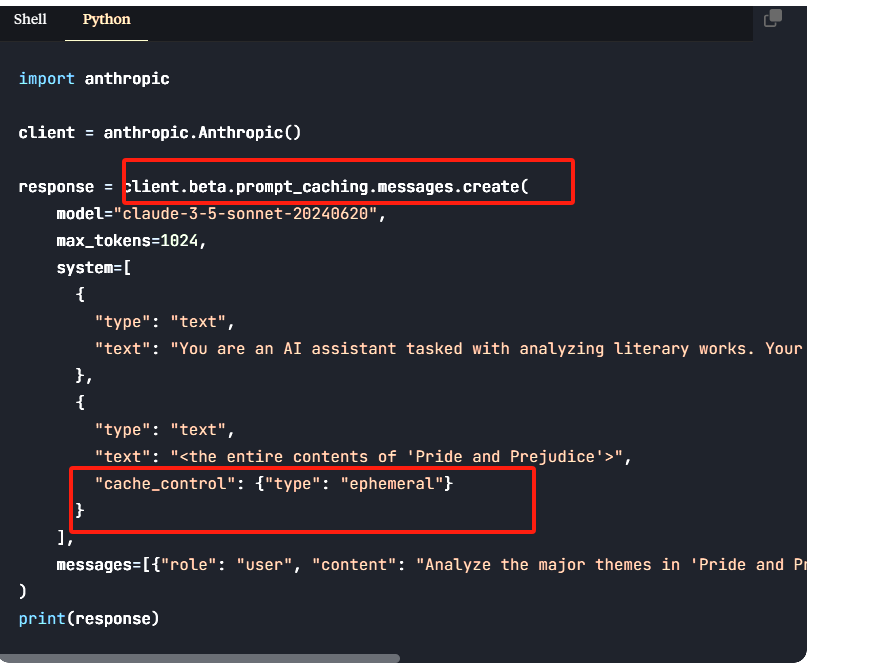
而Anthropic要用的话,就需要明确制定了,明确制定的好处是,可以做成类PML的灵活的机制,但是也麻烦。
有了prompt cache,现在做Contextual-Retrieval 也省了不少的钱(其实做graph-RAG也一样省钱

)
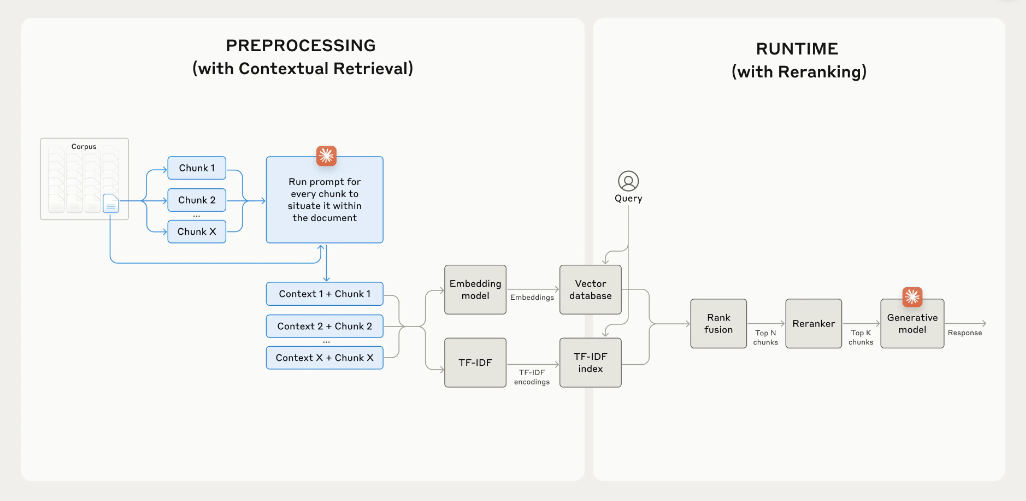
以上工作都做完了,如果再精细化,后面可以跟个rerank,把抽出来的一对带着cotext的chunk再拿rerank模型比如cohere做一次语义排序,然后发给LLM,能效果更好一点。