倒排索引是什么?
【定义】倒排索引(Inverted Index)是一种用于信息检索的数据结构,尤其适用于文本搜索。它与传统索引的主要区别在于,传统索引是根据文档来查找词语的位置,而倒排索引则是根据词语来查找文档。倒排索引在搜索引擎、数据库系统以及自然语言处理等领域有着广泛的应用。
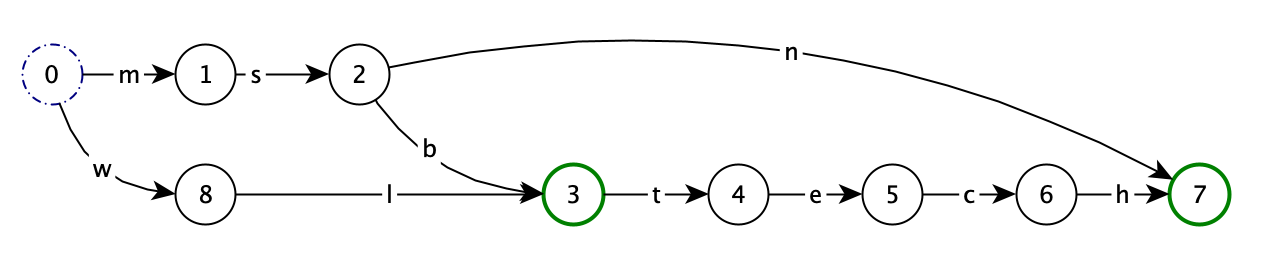
倒排索引的结构包含:
- 词项索引(term index):存放在 .tip 文件中。存放 FST 的公共前缀和公共后缀。
- 词项字典:存储的关键词,使用 FST(Finite State Transducer) 数据结构压缩。存放在 .tim 文件中。后缀词块,倒排表的指针。
- 倒排表:存储的是:包含当前词项的文档 ID 有序列表,是 int 型。int 的最大值是 2^32 ,所以分片存储的文档是有上限的。存放在 .doc 文件中。
由于词典的 size 会很大,全部装载到 heap 里不现实,因此Lucene为词典做了一层前缀索引(Term Index),这个索引在Lucene4.0以后采用的数据结构是FST (Finite State Transducer)。 这种数据结构占用空间很小,Lucene 打开索引的时候将其全量装载到内存中,加快磁盘上词典查询速度的同时减少随机磁盘访问次数。
FST 可以理解为前缀树的变种,FST 不但利用公共前缀,还是利用了公共后缀。FST 的对空间的空间的压缩还大。
Lucene4+ 开始大量使用数据结构:FST(Finite State Transducer)
FST 优点:
- 空间占用小,通过对字典中单词前缀和后缀的重复利用,压缩存储空间。
- 查询速度快。时间复杂度: O(len(str))

| term index | term dictionary(词项字段) | Posting list(倒排表) | 标记匹配 |
|---|---|---|---|
| 小米 | 1,2,4 | ||
| 手机 | 1,2,3 | ||
| NFC | 4,5 |
索引结构
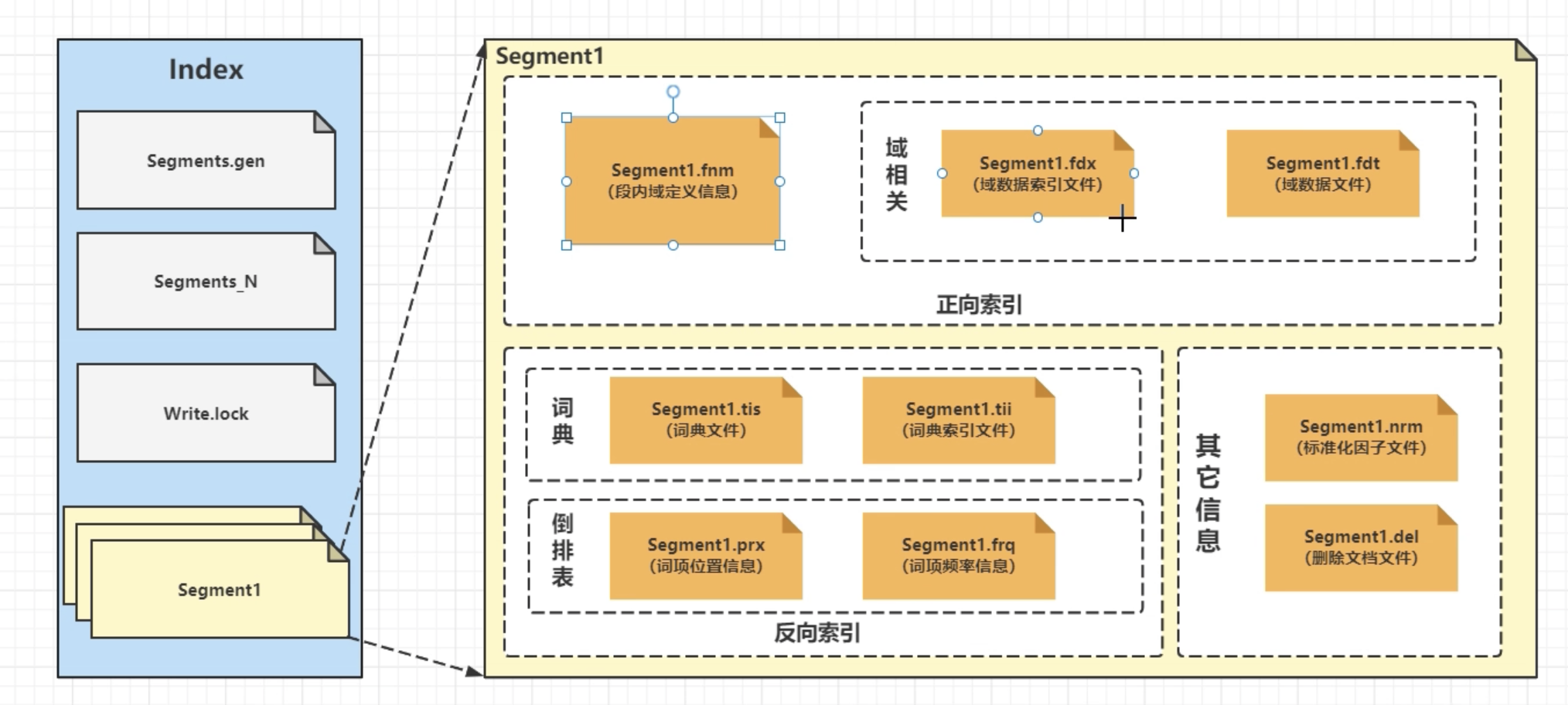
倒排索引核心算法
倒排表的压缩算法
Posting list 使用的压缩算法:(高效压缩、快速的编码解码)
-
FOR(Frame Of Reference):针对稠密数组压缩。稠密的定义:数组中数据差值比较小
- 核心思想:用减法来削减数值大小,从而达到降低空间存储。
-
RBM(Roaring Bit Map):针对稀疏数组压缩。稀疏的定义:数组中数据差值比较大
- 解决 FOR 算法缺陷:如果减法的结果差值,依然很大。
- 核心思想:通过除法来缩减数值大小,但是并不是直接的相除。将一个数拆成高 16 位和低 16 位。
FOR
如下图:Posting list 中是升序排列的 6 个 int 数据。
压缩前数据所占空间为:4 byte * 6 = 24 byte
接下来看 FOR 的压缩过程
- 第一位数保留原始数据,从第二数起,保留与前一位数的差值,如下图 Deltas list
- 根据 Deltas list 中数据稠密程度划分出小数组(自动划分)
- 【目的】小数组内每个数据占用的空间,都是有小数组内最大的数据所决定。划分小数组的目的,也是为了进一步压缩空间。避免一个大数据,导致所有数据都必须占用这么大的空间。
- 根据每个小数组中的最大值,确定每个数据的占用空间
- 左边数组的最大值为 277,至少占用 8 个 bit: 2 8 = 512 2^8= 512 28=512。那么左边数组需要占用:2 * 8bit = 16 bit
- 右边数组的最大值为 30,至少占用 5 个bit: 2 5 = 32 2^5= 32 25=32。那么右边数组需要占用:4 * 5bit = 20 bit
- 每个小数组中每个数占用的空间也需要记录一下,解码时需要使用。下图 8 bit 和 5bit 也各需要一个 1 byte 的空间存储
- 程序中的数据都是使用字节存储的。因此需要将 bit 转换为字节。16 bit = 2 byte;20 bit = 3 byte。20 bit 必须用 3 byte 存储。
- 因此最终压缩后数据占用空间为:1 byte + 2 byte + 3 byte + 1 byte = 7 byte。空间压缩了 2/3
RBM
RBM(Roaring Bit Map):针对稀疏数组压缩。稀疏的定义:数组中数据差值比较大。
核心思想:通过除法来缩减数值大小,但是并不是直接的相除。将一个数拆成高 16 位和低 16 位。
如下图:posting list 的差值也非常大。可以使用 RBM 算法进行压缩。
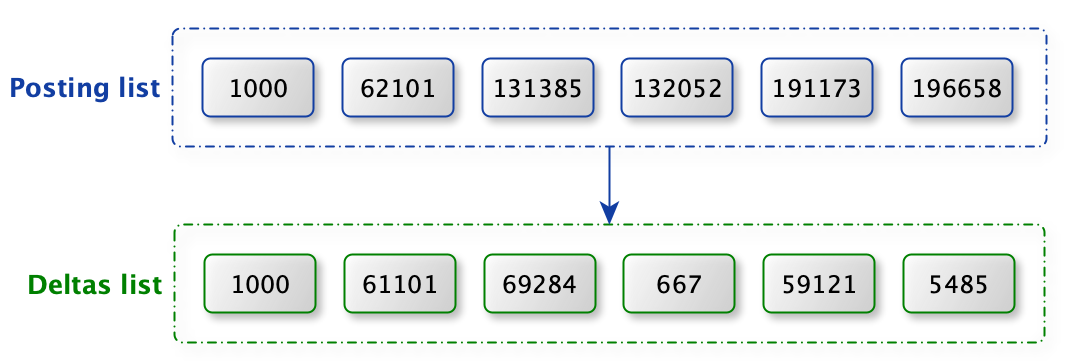
Posting list 中是升序排列的 6 个 int32 数据。
- 通过除以 2 16 = 65536 2^{16}=65536 216=65536 ,获取到高 16 和低 16 两个 short 数
- 以高 16 数给key,以低 16 数为 value,构建倒排列表
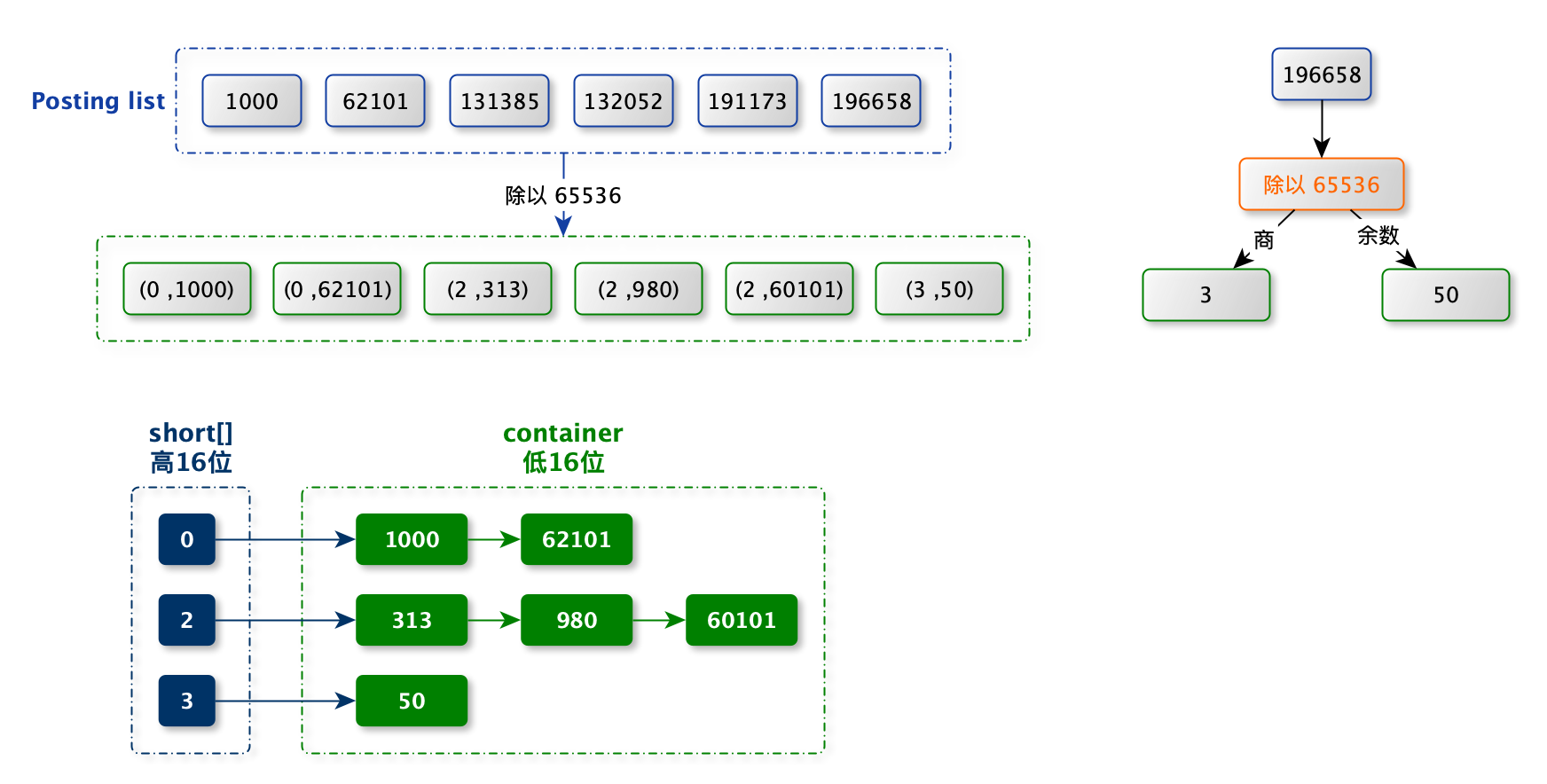
Short\[\] 数组存放高位,相同高位存放 value。
支撑的 container 的类型:
-
ArrayContainer:container 中的数据以 short 数组形式存储。
-
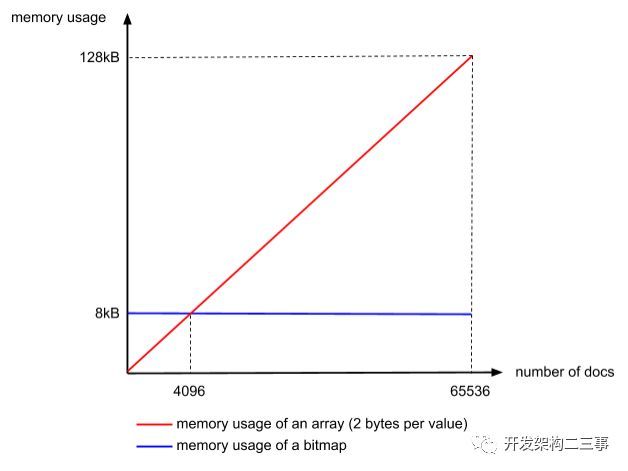
container 中的数据是升序且不重复的。并且最多有 65536 个数。因此最大占用空间为:(65536*16/2)/1024=128KB。
-
当 value 小于2096 个数或者 8KB时,使用 ArrayContainer。否则使用 BitMapContainer。
-
-
BitMapContainer:container 中的数据用 bitMap 存储。
-
bitMap:要支持 65536 位的数据存储,占用空间为:(65536/8)/1024 = 8KB
-
bitMap 占用的空间是固定,无论多少数据都是 8KB。
-
因此但数据量小于 2096 个时,使用 ArrayContainer 比较合适。
-
因此但数据量大于 2096 个时,使用 BitMapContainer 比较合适。
-
-
-
RunContainer:此 container 适合存储连续数据。如下图:有 100w 个连续数据,那么直接存储一个范围即可。

词项索引的压缩算法
【定义】FST 是 Finite State Transducer 的缩写,是一种计算模型,它是有限状态自动机(Finite State Automaton, FSA)的一种扩展。FST 可以看作是一个双向的自动机,它在读取输入的同时产生输出。
【用途】FST 常用于自然语言处理、编译器设计、模式识别等领域,用于处理和转换数据,例如文本的自动翻译、语音识别与合成等。
与前缀树相比,FST 不但能够共享前缀,还能共享后缀。