堆叠面积图具有以下几个重要作用:
一、展示总量与分量关系
堆叠面积图可以清晰地展示多个数据系列的总量以及各个分量在总量中所占的比例。通过不同颜色或阴影的区域,你可以直观地看出每个数据系列对整体的贡献程度。例如,在分析公司不同业务部门的销售额时,堆叠面积图能够显示出总销售额以及各部门销售额的变化情况,帮助管理层了解各个部门对公司整体业绩的影响。
二、比较不同系列的趋势
它可以同时呈现多个数据系列随时间或其他变量的变化趋势。通过观察不同区域的起伏和变化速度,你能够比较不同数据系列的增长、下降或波动情况。比如,在研究不同产品类别的市场份额随时间的变化时,堆叠面积图可以让你快速了解各个产品类别的发展态势以及它们之间的相对竞争关系。
三、突出数据的变化幅度
堆叠面积图能够突出显示数据的变化幅度。当某个数据系列的数值发生较大变化时,其对应的区域面积也会相应地增大或缩小,从而引起人们的关注。这对于发现数据中的异常值、重要事件或趋势转折非常有帮助。例如,在监测环境指标变化时,若某一时期某种污染物的排放量突然增加,在堆叠面积图中会明显地表现为该部分区域的扩大,提醒人们及时采取措施。
四、可视化复杂数据结构
对于具有复杂数据结构的情况,堆叠面积图可以有效地将多个维度的数据整合在一起进行展示。比如,同时考虑不同地区、不同时间段和不同产品类型的销售数据,通过合理设置坐标轴和数据系列,可以在一张堆叠面积图中呈现出丰富的信息,便于进行综合分析和决策。
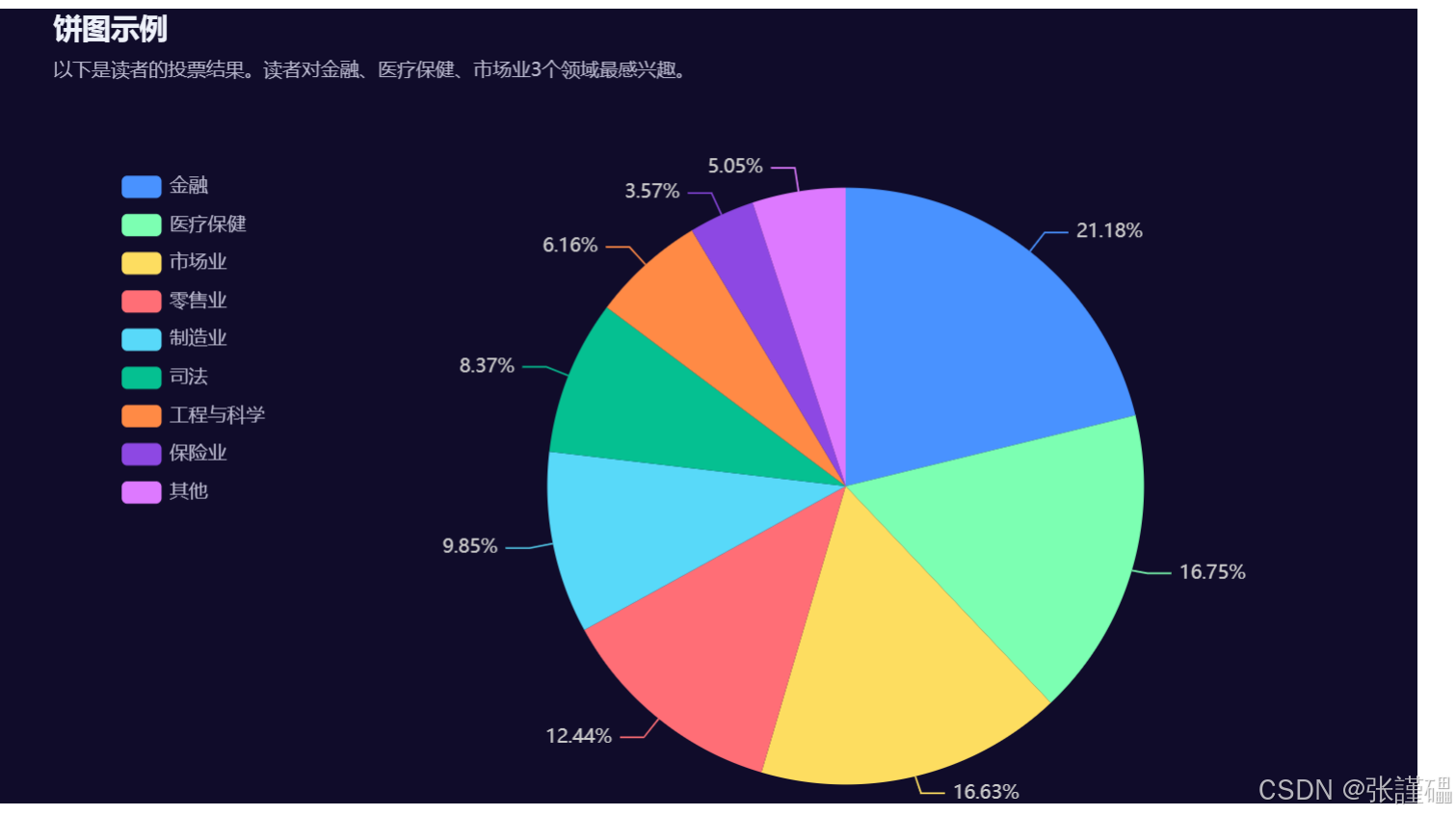
数据集
vote_result.csv
Areas_of_interest,Votes
金融,172
医疗保健,136
市场业,135
零售业,101
制造业,80
司法,68
工程与科学,50
保险业,29
其他,41us_population_by_age.csv
year,year_under5,year5_19,year20_44,year45_64,year65above
1860年,15.4,35.8,35.7,10.4,2.7
1870年,14.3,35.4,35.4,11.9,3
1880年,13.8,34.3,35.9,12.6,3.4
1890年,12.2,33.9,36.9,13.1,3.9
1900年,12.1,32.3,37.7,13.7,4.1
1910年,11.6,30.4,39,14.6,4.3
1920年,10.9,29.8,38.4,16.1,4.7
1930年,9.3,29.5,38.3,17.4,5.4
1940年,8,26.4,38.9,19.8,6.8
1950年,10.7,23.2,37.6,20.3,8.1
1960年,11.3,27.1,32.2,20.1,9.2
1970年,8.4,29.5,31.7,20.6,9.8
1980年,7.2,24.8,37.1,19.6,11.3
1990年,7.6,21.3,40.1,18.6,12.5
2000年,6.8,21.8,37,22,12.4
2005年,6.8,20.7,35.4,24.6,12.4presidential_approval_rate.csv
political_issue,support,oppose,no_opinion
种族问题,52,38,10
教育,49,40,11
恐怖活动,48,45,7
能源政策,47,42,11
外交事务,44,48,8
环境,43,51,6
宗教政策,41,53,6
税收,41,54,5
医疗保健政策,40,57,3
经济,38,59,3
就业政策,36,57,7
贸易政策,31,64,5
外来移民,29,62,9
python
import pyecharts.options as opts
from pyecharts.charts import Line
from pyecharts import options as opts
from pyecharts.charts import Grid
from pyecharts.commons.utils import JsCode
from pyecharts.faker import Faker
from pyecharts.globals import ThemeType
# 原始数据
x_data = ["种族问题","教育", "恐怖活动", "能源政策", "外交事务", "环境", "宗教政策", "税收", "医疗保健政策","经济" ,"就业政策", "贸易政策","外来移民"]
y_data = [100, 100, 100, 100, 100, 100, 100, 100, 100, 100, 100, 100,100]
support_data = [52, 49, 48, 47, 44, 43, 41,41,40,38,36,31,28]
oppose_data = [38, 40, 45, 42, 48, 51, 53,54,57,59,57,64,62]
no_opinion_data = [10, 11, 7, 11, 8, 6, 6,5,3,3,7,5,9]
def create_line_chart(selected_indices):
selected_x_data = [x_data[i] for i in selected_indices]
selected_support_data = [support_data[i] for i in selected_indices]
selected_oppose_data = [oppose_data[i] for i in selected_indices]
selected_no_opinion_data = [no_opinion_data[i] for i in selected_indices]
line = (
Line()
.add_xaxis(xaxis_data=selected_x_data)
.add_yaxis(
series_name="support",
stack="总量",
y_axis=selected_support_data,
areastyle_opts=opts.AreaStyleOpts(opacity=0.5),
label_opts=opts.LabelOpts(is_show=False),
)
.add_yaxis(
series_name="oppose",
stack="总量",
y_axis=selected_oppose_data,
areastyle_opts=opts.AreaStyleOpts(opacity=0.5),
label_opts=opts.LabelOpts(is_show=False),
)
.add_yaxis(
series_name="no_opinion",
stack="总量",
y_axis=selected_no_opinion_data,
areastyle_opts=opts.AreaStyleOpts(opacity=0.5),
label_opts=opts.LabelOpts(is_show=False),
)
.add_yaxis(
series_name="total",
stack="总量",
y_axis=[100] * len(selected_indices),
areastyle_opts=opts.AreaStyleOpts(opacity=0.5),
label_opts=opts.LabelOpts(is_show=True, position="top"),
)
.set_global_opts(
title_opts=opts.TitleOpts(title="堆叠区域图"),
tooltip_opts=opts.TooltipOpts(trigger="axis", axis_pointer_type="cross"),
yaxis_opts=opts.AxisOpts(
type_="value",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
xaxis_opts=opts.AxisOpts(type_="category", boundary_gap=False, axislabel_opts=opts.LabelOpts(rotate=45))
)
)
return line
def create_grid_chart(selected_indices):
line_chart = create_line_chart(selected_indices)
grid = (
Grid()
.add(line_chart, grid_opts=opts.GridOpts(pos_left="10%")))
return grid
# 默认全选
selected_indices = list(range(len(x_data)))
grid_chart = create_grid_chart(selected_indices)
grid_chart.render("stacked_area_chart_with_dynamic_component.html")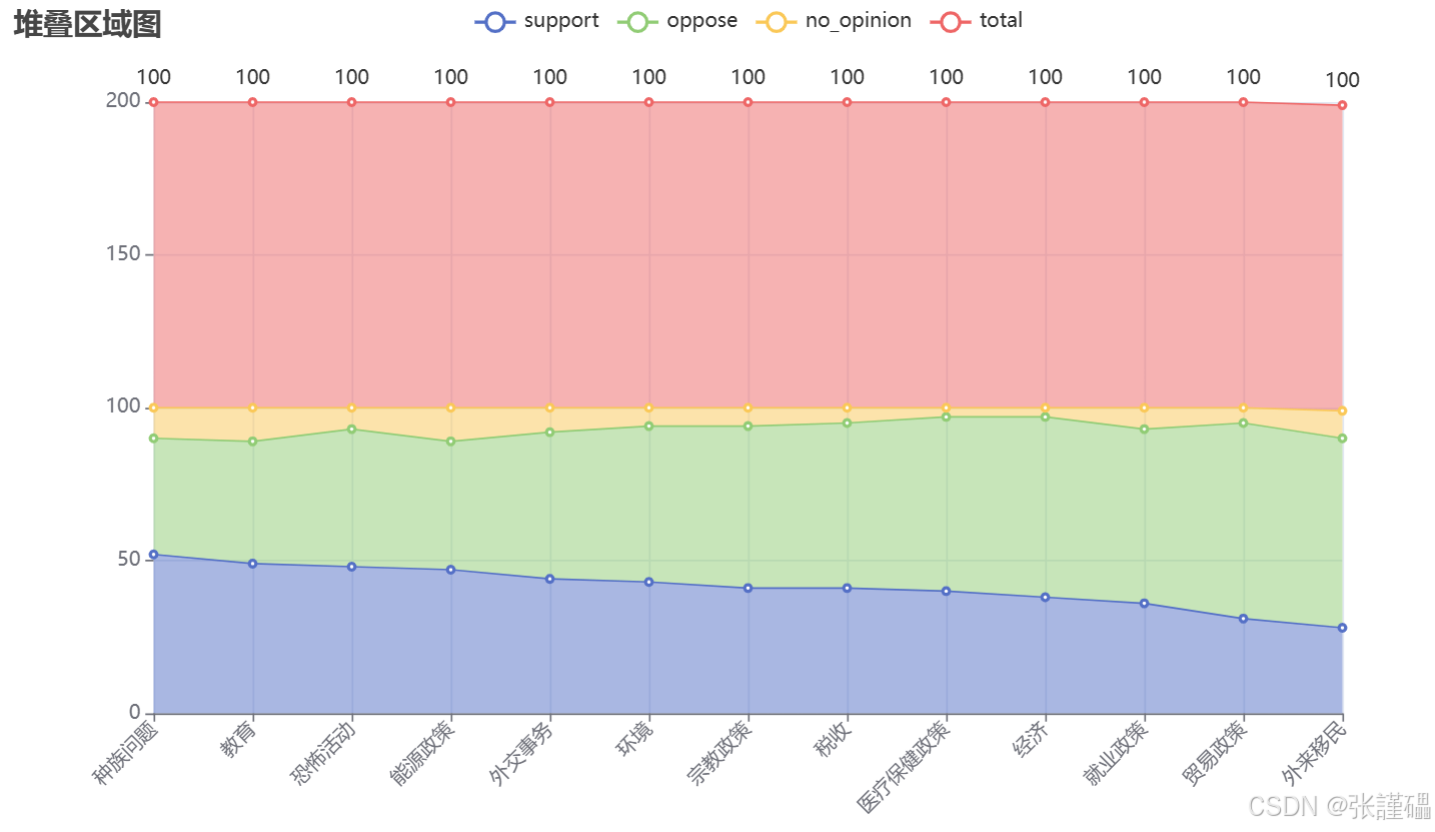
python
from pyecharts.charts import Bar
from pyecharts import options as opts
from pyecharts.globals import ThemeType
import pandas as pd
data=pd.read_csv("./presidential_approval_rate.csv")
print(data)
datax = data["political_issue"].tolist()
print(data)
dataA = data["support"].tolist()
dataB = data["oppose"].tolist()
dataC = data["no_opinion"].tolist()
stackBarDiagram = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.DARK))
.add_xaxis(xaxis_data=datax)
.add_yaxis(
series_name="支持",
y_axis=dataA,
stack=True
)
.add_yaxis(
series_name="反对",
y_axis=dataB,
stack=True
)
.add_yaxis(
series_name="不发表意见",
y_axis=dataC,
stack=True,
)
.set_series_opts(
label_opts=opts.LabelOpts(
position="inside",
is_show=False
)
)
.set_global_opts(
title_opts=opts.TitleOpts(title="柱状图数据堆叠示例",
subtitle="数据科学与大数据21",
pos_left="center"
),
xaxis_opts=opts.AxisOpts(
axislabel_opts=opts.LabelOpts(rotate=50),
name="political_issue"
),
toolbox_opts=opts.TooltipOpts(is_show=True),
legend_opts=opts.LegendOpts(
type_="scroll",
orient="vertical",
pos_left="90%",
pos_top='20%'
),
)
)
stackBarDiagram.render(path="堆叠柱形图.html")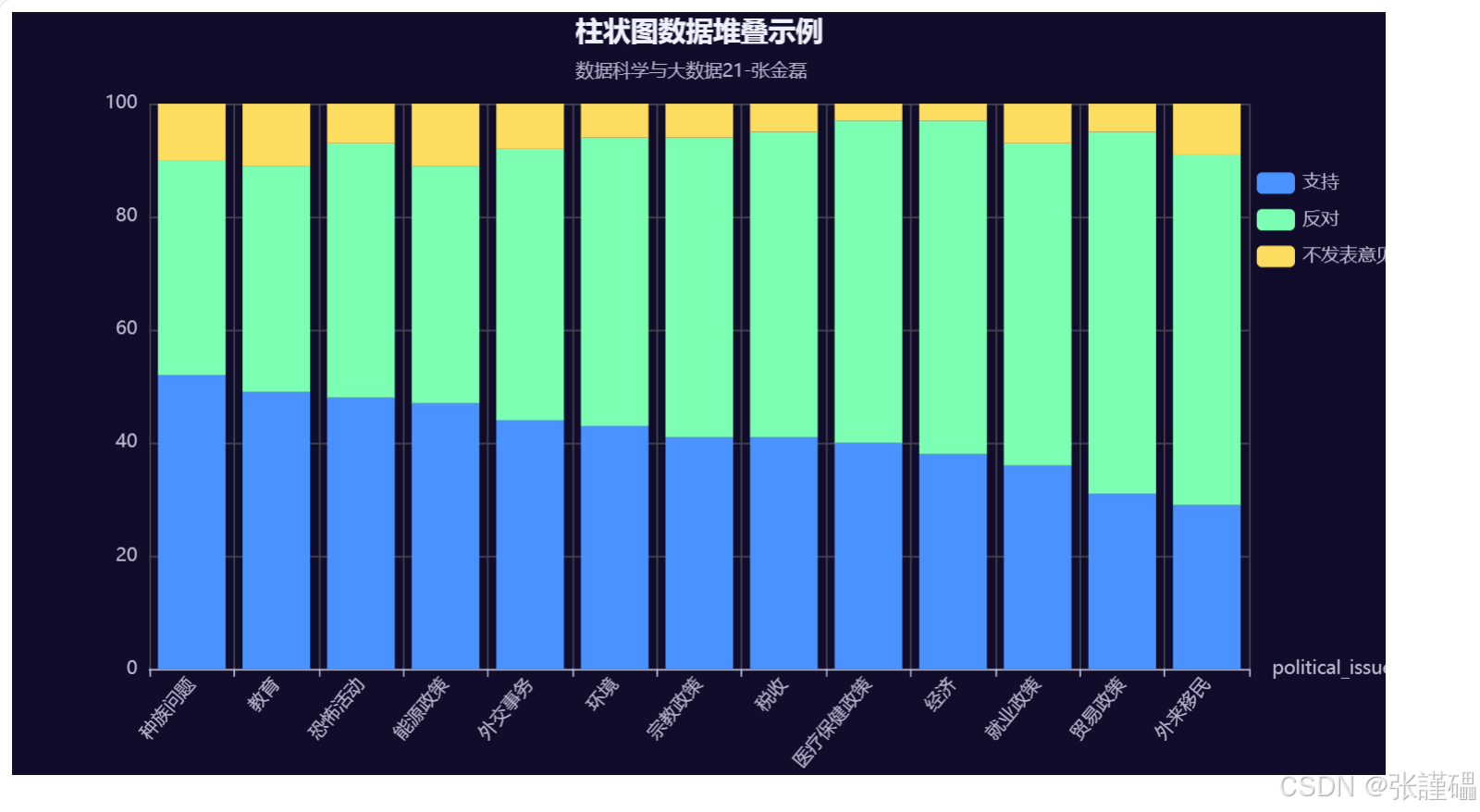
python
from pyecharts.charts import Pie
import pandas as pd
import numpy as np
import pyecharts.options as opts
from pyecharts.globals import ThemeType
vote_result = pd.read_csv('vote_result.csv')
pie = (
Pie(init_opts=opts.InitOpts(theme=ThemeType.DARK))
.add(
series_name="饼图绘制",
data_pair=vote_result.values,
label_opts=opts.LabelOpts(position = "outside",formatter='{d}%'),
center=["60%","60%"]
)
.set_global_opts(
title_opts=opts.TitleOpts(title='饼图示例',
subtitle='以下是读者的投票结果。读者对金融、医疗保健、市场业3个领域最感兴趣。',
pos_right='50%'),
# 图例配置项
legend_opts=opts.LegendOpts(
type_='scroll',
pos_top='20%',
pos_right= '80%',
orient='vertical',
is_show=True
)
)
)
pie.options["bgColor"] = "white"
pie.render('pie.html',bg_color='white')