池化技术是比较常见的一种技术,在平时我们已经就接触很多了,比如线程池,数据库连接池等等。当我们要使用一个资源的时候从池中去获取,用完就放回池中以便其他线程可以使用,这样的目的就是为了减少资源开销,提升性能。而Netty作为一个高性能的网络框架,在这一块也自然下足了工夫,下面我们就来看一下在Netty中的对象池是如何实现的吧
原理
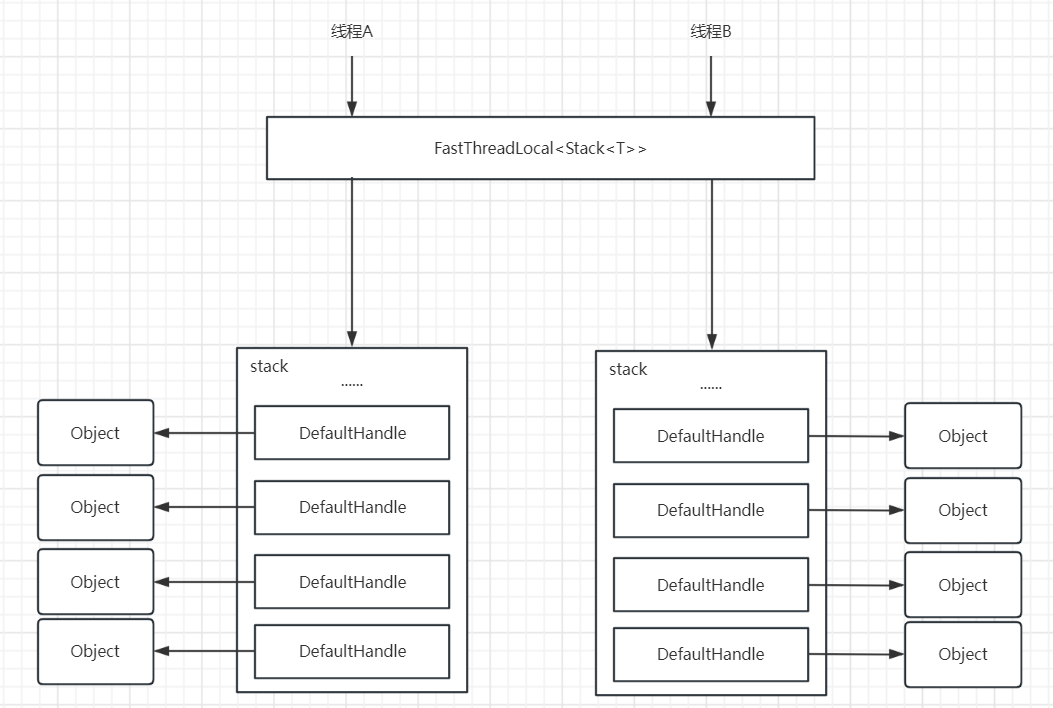
与其他池化实现不同的是,其他的池化实现都是全局的,但是这样的话在实现的过程中就可能会有并发的问题,比如说在获取资源以及回收资源的时候都需要通过加锁等手段去处理,而Netty的对象池为了避免这些问题,采用了ThreadLocal去为每一个线程创造一个对象池,这样的话每一个线程去获取对象以及回收对象的时候就只会在自己所属的对象池中去操作了,自然就避免了加锁的过程处理,简单来说就是通过空间换时间的思想,从而达到了无锁化的目的。
不同的线程池使用独立的对象池虽然解决了上面加锁的问题,但是这也会导致另一个问题,比如说一个线程从自身的对象池中获取到了一个对象,但是这个对象被另外一个线程的对象池拿到并回收了,此时该对象就被回收到不属于自己的对象池中了。Netty为了解决这个问题,引入了一个队列,该队列就是专门存放这些帮助回收的线程回收的对象,举个例子,线程A从对象池中创建了一个对象,这个对象被线程B回收了,但是由于这个对象并不属于线程B的,所以线程B会为线程A创建一个队列,把这个回收对象放到这个队列中,当线程A再去从自身对象池中获取对象的时候,会先去这个队列中看是否有对象,如果有的话,就拿出来放回自身线程池中,这样就解决了上面的问题了。
所以可以看到,Netty对象池中很多都是通过线程隔离的思想去避免线程间并发竞争的情况出现,完全体现出了无锁化的设计思想。
源码解析
(1)整体设计
Recycler
java
public abstract class Recycler<T> {
protected abstract T newObject(Handle<T> handle);
}Recycler是整个对象池的一个外壳,其中提供了一个newObject的抽象方法,主要就是给子类去进行实现的,子类在可以在该方法中去创建出对象池中的对象
stack
java
private static final class Stack<T> {
// 省略部分代码
/**
* 存放handle的数组,也可以认为是存放对象的数组
*/
DefaultHandle<?>[] elements;
// 省略部分代码
}
java
private final FastThreadLocal<Stack<T>> threadLocal = new FastThreadLocal<Stack<T>>() {
@Override
protected Stack<T> initialValue() {
return new Stack<T>(Recycler.this, Thread.currentThread(), maxCapacityPerThread, maxSharedCapacityFactor,
interval, maxDelayedQueuesPerThread, delayedQueueInterval);
}
@Override
protected void onRemoval(Stack<T> value) {
// Let us remove the WeakOrderQueue from the WeakHashMap directly if its safe to remove some overhead
if (value.threadRef.get() == Thread.currentThread()) {
if (DELAYED_RECYCLED.isSet()) {
DELAYED_RECYCLED.get().remove(value);
}
}
}
};stack其实就是真正的对象池实现,当每一个线程想去从stack中获取对象的时候,都会去从上面的FastThreadLocal中去获取到该线程自己的stack,然后再从stack中获取对象。stack中有一个数组,该数组就是真是存放对象的,但是存放的数据类型是一个DefaultHandle,那我们的对象哪里呢?其实我们的对象就是在DefaultHandle里面,这里DefaultHandle帮我们的对象做了一层包装。
Handle
java
public interface Handle<T> extends ObjectPool.Handle<T> { }
public abstract class ObjectPool<T> {
public interface Handle<T> {
void recycle(T self);
}
}
java
private static final class DefaultHandle<T> implements Handle<T> {
private static final AtomicIntegerFieldUpdater<DefaultHandle<?>> LAST_RECYCLED_ID_UPDATER;
static {
AtomicIntegerFieldUpdater<?> updater = AtomicIntegerFieldUpdater.newUpdater(
DefaultHandle.class, "lastRecycledId");
LAST_RECYCLED_ID_UPDATER = (AtomicIntegerFieldUpdater<DefaultHandle<?>>) updater;
}
/**
* 当对象被其他帮助回收的线程回收了时候,该属性的值就是这个帮助回收的线程的id
*/
volatile int lastRecycledId;
/**
* 当原本创建该对象线程从其他帮助回收的线程中拿回该对象的时候,此时就会把lastRecycledId的值赋值给recycleId
*/
int recycleId;
boolean hasBeenRecycled;
Stack<?> stack;
Object value;
DefaultHandle(Stack<?> stack) {
this.stack = stack;
}
@Override
public void recycle(Object object) {
// 校验下回收的对象是否属于当前这个handle
if (object != value) {
throw new IllegalArgumentException("object does not belong to handle");
}
Stack<?> stack = this.stack;
if (lastRecycledId != recycleId || stack == null) {
throw new IllegalStateException("recycled already");
}
stack.push(this);
}
public boolean compareAndSetLastRecycledId(int expectLastRecycledId, int updateLastRecycledId) {
// Use "weak..." because we do not need synchronize-with ordering, only atomicity.
// Also, spurious failures are fine, since no code should rely on recycling for correctness.
return LAST_RECYCLED_ID_UPDATER.weakCompareAndSet(this, expectLastRecycledId, updateLastRecycledId);
}
}DefaultHandle类实现了Recycler中的Handle接口,而Recycler中的Handle接口又继承于ObjectPool的handle接口,在ObjectPool的handle接口中有一个recycle方法,该方法就是用来回收对象的,传入的参数就是要回收的对象,当调用recycle方法的时候,最终会把当前的handle放到对应的stack中,由此可以知道回收对象的入口是在handle,而不是stack。另外一个重点的地方就是DefaultHandle的value属性,它其实就是我们说所需要的原始对象,总体来看,stack与handle的关系如下图所示:
WeakOrderQueue
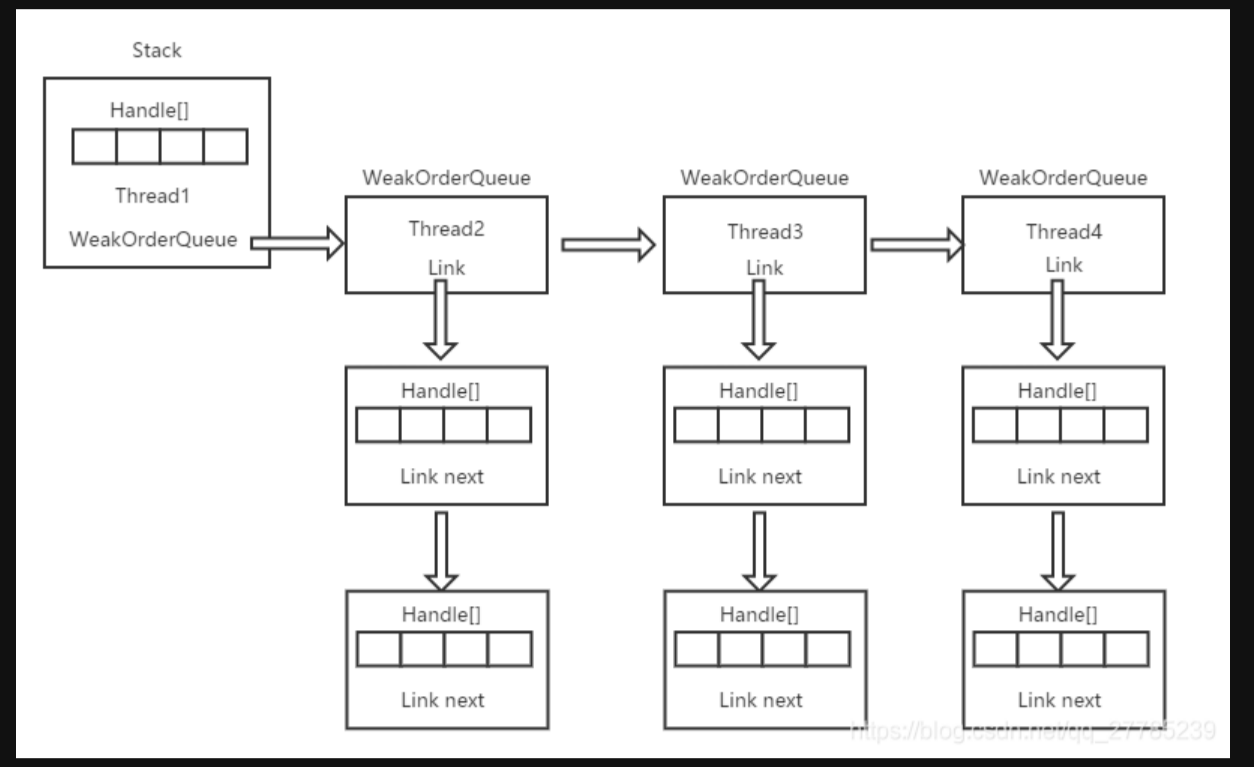
当其他线程帮忙回收对象的时候会把对象存放在哪里呢?答案就是在WeakOrderQueue中,一个帮忙回收的线程针对每一个stack都会有一个WeakOrderQueue去存放回收这个stack的对象,并且WeakOrderQueue中通过link指针去构造出一个link链表,所以一个WeakOrderQueue也就代表着一个link链表。同理,既然WeakOrderQueue是用来存放回收对象的,那么这些回收对象也需要被取走是吧,所以在一个stack中,也构造了一个WeakOrderQueue链表,表示当前这个stack被哪些线程的WeakOrderQueue回收了对象,当需要取这些回收对象的时候,此时就可以取遍历这个WeakOrderQueue即可
Link
一个link对象中包含了一个DefaultHandle数组,这个数组存放的就是帮助其他stack回收的对象,每一个link之间则形成了链表
小总结
所以综上所述,stack,handle,WeakOrderQueue与link这4者之间的关系如下图所示(引用网上的一张图):
最后,如果我们要使用Netty的对象池会怎么去使用呢?在Netty中提供了模板ObjectPool类去对Recycler进行了包装,以便于我们能够更方便地使用,ObjectPool类代码如下:
java
public abstract class ObjectPool<T> {
ObjectPool() { }
public abstract T get();
public interface Handle<T> {
void recycle(T self);
}
public interface ObjectCreator<T> {
T newObject(Handle<T> handle);
}
public static <T> ObjectPool<T> newPool(final ObjectCreator<T> creator) {
return new RecyclerObjectPool<T>(ObjectUtil.checkNotNull(creator, "creator"));
}
private static final class RecyclerObjectPool<T> extends ObjectPool<T> {
private final Recycler<T> recycler;
RecyclerObjectPool(final ObjectCreator<T> creator) {
recycler = new Recycler<T>() {
@Override
protected T newObject(Handle<T> handle) {
return creator.newObject(handle);
}
};
}
@Override
public T get() {
return recycler.get();
}
}
}而ObjectPool可以如下使用:
java
ObjectPool<A> objectPool = ObjectPool.newPool(new ObjectPool.ObjectCreator<A>() {
@Override
public A newObject(ObjectPool.Handle<A> handle) {
return new A(handle);
}
});
A a = objectPool.get();
a.recycle();当然了,我们创建的对象需要持有Handle,因为回收对象的方法是交给Handle去做的:
java
public class A {
private final ObjectPool.Handle<A> handle;
public A(ObjectPool.Handle<A> handle) {
this.handle = handle;
}
public void recycle() {
this.handle.recycle(this);
}
}(2)从stack中获取对象
java
DefaultHandle<T> pop() {
// 获取到当前线程对应的stack中存在的对象的数量
int size = this.size;
// 条件成立:说明stack中没有对象
if (size == 0) {
// 此时需要去从WeakOrderQueue链表中获取对象,也就是从其他帮忙回收对象的线程的WeakOrderQueue中获取
// 条件成立:表示其他帮忙回收对象的线程中也没有对象
if (!scavenge()) {
// 返回null,这样上层会创建新的对象
return null;
}
size = this.size;
if (size <= 0) {
// double check, avoid races
return null;
}
}
// 代码执行到这里说明此时stack中有存活的对象了,此时size数量-1
size --;
// 从数组中获取对象
DefaultHandle ret = elements[size];
elements[size] = null;
// As we already set the element[size] to null we also need to store the updated size before we do
// any validation. Otherwise we may see a null value when later try to pop again without a new element
// added before.
// 更新size数量
this.size = size;
if (ret.lastRecycledId != ret.recycleId) {
throw new IllegalStateException("recycled multiple times");
}
// 重置这两个属性
ret.recycleId = 0;
ret.lastRecycledId = 0;
// 返回对象
return ret;
}(3)其他线程帮忙回收对象
io.netty.util.Recycler.Stack#pushLater
如果代码来到这里,必定就是当前回收对象的线程与创建该对象的线程不是同一个线程
java
/**
* 调用该方法的一定是帮助回收对象的线程。该方法会去把回收的对象放到对应的WeakOrderQueue中
* @param item 回收的对象
* @param thread 帮助回收对象的线程,也就是当前线程
*/
private void pushLater(DefaultHandle<?> item, Thread thread) {
if (maxDelayedQueues == 0) {
// We don't support recycling across threads and should just drop the item on the floor.
return;
}
// we don't want to have a ref to the queue as the value in our weak map
// so we null it out; to ensure there are no races with restoring it later
// we impose a memory ordering here (no-op on x86)
// 获取这个帮助回收对象的线程对应的WeakOrderQueue,
// key=>帮助哪个stack回收
// value=>存放回收这个stack的对象的WeakOrderQueue
Map<Stack<?>, WeakOrderQueue> delayedRecycled = DELAYED_RECYCLED.get();
WeakOrderQueue queue = delayedRecycled.get(this);
// 条件成立:说明当前线程之前还没有帮助过这个stack回收对象
if (queue == null) {
// 条件成立:说明已经超过最大帮助这个stack回收对象的线程上限了
if (delayedRecycled.size() >= maxDelayedQueues) {
// 把需要帮助回收对象的stack作为key放到map中,对应的value是一个dummy的WeakOrderQueue
delayedRecycled.put(this, WeakOrderQueue.DUMMY);
return;
}
// 代码执行到这里说明此时还没有超过最大帮助这个stack回收对象的线程上限
// 给当前stack创建WeakOrderQueue
// 条件成立:说明当前stack已经没有回收对象的数量去分配了,已经不能再创建新的WeakOrderQueue了
if ((queue = newWeakOrderQueue(thread)) == null) {
// 放弃回收这个对象
return;
}
// 把stack和对应的WeakOrderQueue放到线程map中
delayedRecycled.put(this, queue);
}
// 在上面的if中当超过最大帮助这个stack回收对象的线程上限的时候,就会给map中放入一个dummy的WeakOrderQueue
else if (queue == WeakOrderQueue.DUMMY) {
// 放弃回收这个对象
return;
}
// 把要回收的对象放到对应的WeakOrderQueue中
queue.add(item);
}
java
/**
* 每一个线程都对应一个map
* key=>帮助哪个stack回收对象
* value=>帮助这个stack回收对象时,存放对象的WeakOrderQueue
*/
private static final FastThreadLocal<Map<Stack<?>, WeakOrderQueue>> DELAYED_RECYCLED =
new FastThreadLocal<Map<Stack<?>, WeakOrderQueue>>() {
@Override
protected Map<Stack<?>, WeakOrderQueue> initialValue() {
return new WeakHashMap<Stack<?>, WeakOrderQueue>();
}
};首先每个会去从FastThreadLocal中获取到一个map,map的key表示帮助的是哪一个stack去回收对象,value则是已经帮助这个stack回收的对象所存放的队列。
- 如果该线程是第一次帮助这个stack去回收对象,那么就先判断下该线程已经帮助过多少个stack回收对象,如果此时已经达到了帮助上限,那么此次就不能帮助这个stack回收了,然后就给这个stack创建一个DUMMY类型的WeakOrderQueue,以便下一次该线程再帮助这个stack回收对象的时候发现对应的队列是一个WeakOrderQueue能够立刻放弃回收
- 如果该线程不是第一次帮助这个stack回收对象了,那么能够获取到这个stack对应的WeakOrderQueue队列,反之则为这个stack创建一个新的WeakOrderQueue队列,并且把这个新创建的WeakOrderQueue队列放到map中,最后把要回收的对象放到WeakOrderQueue队列中
创建WeakOrderQueue队列
在上面回收的过程中,如果是第一次帮助这个stack回收,则需要为其创建一个新的WeakOrderQueue,代码如下:
java
private WeakOrderQueue newWeakOrderQueue(Thread thread) {
return WeakOrderQueue.newQueue(this, thread);
}
java
/**
* 给指定的stack创建一个回收对象队列
* 该方法可能会被并发调用,因为有可能此时会有多个帮助回收对象的线程在调用该方法去为指定的stack创建回收对象队列
* @param stack 需要帮助回收对象的stack
* @param thread 帮助回收对象的线程
* @return WeakOrderQueue对象
*/
static WeakOrderQueue newQueue(Stack<?> stack, Thread thread) {
// 条件成立:说明指定的stack已经没有回收对象的数量去分配给当前线程去创建回收对象队列了
if (!Head.reserveSpaceForLink(stack.availableSharedCapacity)) {
// 返回null
return null;
}
// 为stack创建一个新的WeakOrderQueue
final WeakOrderQueue queue = new WeakOrderQueue(stack, thread);
// 把这个新创建的WeakOrderQueue放到stack的WeakOrderQueue链表的头部
stack.setHead(queue);
// 返回这个新创建的WeakOrderQueue
return queue;
}可以看到,创建WeakOrderQueue之前需要判断对这个stack的availableSharedCapacity属性进行判断,那么这个属性是什么意思呢?其实就是这个stack有多少个对象是能够被其他线程帮助回收的,比方说100个,那么其他帮助回收的线程回收这个stack的对象加起来一共最多是100个
java
static boolean reserveSpaceForLink(AtomicInteger availableSharedCapacity) {
for (;;) {
// 获取到能够被其他线程回收的对象数量
int available = availableSharedCapacity.get();
// 条件成立:说明此时已经没有回收的对象数量了
if (available < LINK_CAPACITY) {
return false;
}
// 更新可回收的数量对象
if (availableSharedCapacity.compareAndSet(available, available - LINK_CAPACITY)) {
return true;
}
}
}由于可能会有多个帮助这个stack回收对象的线程同时去对availableSharedCapacity进行扣减,所以availableSharedCapacity这里通过AtomicInteger修饰,保证并发的情况下扣减正确
当创建完WeakOrderQueue之后,把这个WeakOrderQueue放到这个stack的WeakOrderQueue链表的头部
java
/**
* 把指定的WeakOrderQueue放到链表的头部,头插法。因为有可能会有多个线程同时去给当前的stack创建回收对象线程,所以该方法需要加锁执行,
* 同时这也是整个Netty对象池中唯一加锁的地方
* @param queue 指定的WeakOrderQueue
*/
synchronized void setHead(WeakOrderQueue queue) {
queue.setNext(head);
head = queue;
}因为上面我们也说了,这里可能会有多个线程调用,也就是说会有多个线程去创建WeakOrderQueue加到stack的链表头部,所以这里需要进行加锁操作,需要注意的是这也是整个Netty对象池中唯一一处加锁的地方,因为整个Netty对象池的设计就是为了无锁化去设计的
往WeakOrderQueue添加回收对象
java
/**
* 把要回收的handle对象放到当前的WeakOrderQueue的尾link节点中
* @param handle 要回收的handle对象
*/
void add(DefaultHandle<?> handle) {
if (!handle.compareAndSetLastRecycledId(0, id)) {
// Separate threads could be racing to add the handle to each their own WeakOrderQueue.
// We only add the handle to the queue if we win the race and observe that lastRecycledId is zero.
return;
}
// 这里是为了控制对象回收的频率,默认每8次回收才能回收1个对象
if (!handle.hasBeenRecycled) {
if (handleRecycleCount < interval) {
handleRecycleCount++;
// Drop the item to prevent from recycling too aggressively.
return;
}
handleRecycleCount = 0;
}
// 获取到link链表中的尾节点
Link tail = this.tail;
// 当前link的写指针
int writeIndex;
// 条件成立:说明这个link已经放满对象了
if ((writeIndex = tail.get()) == LINK_CAPACITY) {
// 创建一个新的link节点
Link link = head.newLink();
// 条件成立:说明这个stack中没有可帮助回收的对象数量了
if (link == null) {
// 放弃回收这个对象
return;
}
// 把新创建的link节点设置为尾节点
this.tail = tail = tail.next = link;
// 重置写指针
writeIndex = tail.get();
}
// 把回收对象放到link节点中
tail.elements[writeIndex] = handle;
handle.stack = null;
// we lazy set to ensure that setting stack to null appears before we unnull it in the owning thread;
// this also means we guarantee visibility of an element in the queue if we see the index updated
// 更新写指针
tail.lazySet(writeIndex + 1);
}WeakOrderQueue中是一个link节点的链表,每次添加回收对象的时候都是通过尾插法,获取到最后一个link节点的写指针,然后根据这个写指针把回收对象放入到这个link节点中。如果link节点已经放满了,那么就新创建出一个link节点(当然每次创建都要扣减availableSharedCapacity,如果扣减完了就返回null,此时就放弃回收这个对象了),并把这个link节点设置为尾节点,最后再把要回收的对象放入到这个新创建的link节点中
(4)从WeakOrderQueue中获取对象
io.netty.util.Recycler.Stack#scavengeSome
java
/**
* 转移link链表中的对象,从头节点开始,如果这个link节点中的对象已经转移完了,就找下一个link节点进行转移,每调一次该方法就转移一个link节点
* @return 当转移了一个link节点的时候返回true,反之返回false
*/
private boolean scavengeSome() {
// 前一个节点
WeakOrderQueue prev;
// 当前遍历到的节点
WeakOrderQueue cursor = this.cursor;
// 条件成立:说明此时是第一次遍历WeakOrderQueue链表
if (cursor == null) {
prev = null;
cursor = head;
// 条件成立:说明WeakOrderQueue为空,表示没有其他线程帮忙回收对象
if (cursor == null) {
return false;
}
}
// 条件成立:不是第一次遍历WeakOrderQueue链表
else {
prev = this.prev;
}
boolean success = false;
do {
// 条件成立:说明转移了回收对象,此时跳出循环
if (cursor.transfer(this)) {
success = true;
break;
}
// 代码执行到这里说明当前的WeakOrderQueue中没有转移到回收对象,此时获取下一个WeakOrderQueue节点
WeakOrderQueue next = cursor.getNext();
// 条件成立:说明这个WeakOrderQueue对象对应的线程挂了,也就是帮助回收的线程挂了
if (cursor.get() == null) {
// If the thread associated with the queue is gone, unlink it, after
// performing a volatile read to confirm there is no data left to collect.
// We never unlink the first queue, as we don't want to synchronize on updating the head.
// 把这个WeakOrderQueue中剩余的link节点中的对象进行转移
if (cursor.hasFinalData()) {
for (;;) {
// 每遍历一次就把这个WeakOrderQueue中的一个link节点的回收对象转移一次
if (cursor.transfer(this)) {
success = true;
} else {
break;
}
}
}
if (prev != null) {
// 释放这个WeakOrderQueue所占用的回收对象的数量
cursor.reclaimAllSpaceAndUnlink();
// 把当前这个WeakOrderQueue从链表中删除
prev.setNext(next);
}
} else {
prev = cursor;
}
// 把下一个节点当作当前节点,继续遍历
cursor = next;
} while (cursor != null && !success);
// 重新赋值prev和cursor
this.prev = prev;
this.cursor = cursor;
return success;
}当我们想要从stack中获取对象时,首先会从WeakOrderQueue链表中获取,从上面代码也可以看到,通过上面的代码可以看到,cursor指针表示的是当前遍历到的WeakOrderQueue,如果这个WeakOrderQueue中的对象已经获取完了,那么就继续从下一个节点去获取,并更新cursor指针,那么这里又是怎样从WeakOrderQueue中获取对象的呢?具体逻辑在transfer方法中:
java
/**
* 把当前WeakOrderQueue对象中的link链表的头节点中的全部可回收对象转移到指定的stack中
* @param dst 指定的stack
* @return true=>有转移回收对象, false=>没有转移回收对象
*/
@SuppressWarnings("rawtypes")
boolean transfer(Stack<?> dst) {
Link head = this.head.link;
// 条件成立:说明该WeakOrderQueue对象中还没有link链表
if (head == null) {
return false;
}
// 条件成立:说明当前头节点已经把回收对象全部转移完了
if (head.readIndex == LINK_CAPACITY) {
// 如果头节点的下一个节点为null,就说明没有回收对象可转移了
if (head.next == null) {
return false;
}
// 把下一个节点设置为头节点
head = head.next;
this.head.relink(head);
}
// 获取到当前的读指针
final int srcStart = head.readIndex;
// 获取到这个link节点中存放的回收对象数量
int srcEnd = head.get();
// 两者相减得到的就是需要转移的回收对象数量
final int srcSize = srcEnd - srcStart;
// 条件成立:说明没有可回收的对象能够转移
if (srcSize == 0) {
return false;
}
// 获取到转移目标的stack中的存活对象数量
final int dstSize = dst.size;
// 计算出当把可回收对象全部转移到stack中时,stack所需的大小
final int expectedCapacity = dstSize + srcSize;
// 条件成立:说明如果把可回收对象全部转移到stack中的时候,stack需要扩容
if (expectedCapacity > dst.elements.length) {
// 对stack进行扩容,得到扩容后的stack大小
final int actualCapacity = dst.increaseCapacity(expectedCapacity);
// actualCapacity - dstSize得到的就是stack扩容之后剩余的大小
// 因为stack扩容之后有可能还是完全放不下link中可转移的回收对象,所以这里取最小值
srcEnd = min(srcStart + actualCapacity - dstSize, srcEnd);
}
// 条件成立:说明link节点中存在可转移的回收对象
if (srcStart != srcEnd) {
// 获取到link节点中的对象数组
final DefaultHandle[] srcElems = head.elements;
// 获取到转移目标stack中的对象数组
final DefaultHandle[] dstElems = dst.elements;
int newDstSize = dstSize;
// 遍历link节点的对象数组的可回收对象
for (int i = srcStart; i < srcEnd; i++) {
DefaultHandle<?> element = srcElems[i];
if (element.recycleId == 0) {
element.recycleId = element.lastRecycledId;
} else if (element.recycleId != element.lastRecycledId) {
throw new IllegalStateException("recycled already");
}
srcElems[i] = null;
// 判断是否能够回收该对象
if (dst.dropHandle(element)) {
// 放弃回收该对象
continue;
}
// 代码执行到这里说明该对象能够被回收
// 重新给handle中的stack属性赋值
element.stack = dst;
// 把对象放到stack的对象数组中,此时就完成了该对象的回收
dstElems[newDstSize ++] = element;
}
// 条件成立:说明这个link已经把可回收对象全部转移完了,此时把下一个link节点设置为头节点
if (srcEnd == LINK_CAPACITY && head.next != null) {
// Add capacity back as the Link is GCed.
this.head.relink(head.next);
}
// 把可回收的对象转移完了之后更新读指针
head.readIndex = srcEnd;
// 条件成立:说明此次没有转移到一个回收对象
if (dst.size == newDstSize) {
return false;
}
// 代码执行到这里说明此次转移到至少一个回收对象,此时更新stack的size
dst.size = newDstSize;
return true;
} else {
// The destination stack is full already.
return false;
}
}我们从上面已经知道,每一个WeakOrderQueue对象其实就是一个由link节点组成的链表,而每一个link节点中存储对象靠的就是一个数组。当调用transfer方法的时候,首先会获取当前link链表的头节点,根据读指针和写指针计算出这个link节点转移对象的数组开始下标和结束下标,然后根据开始下标和结束下标把数组中的对象转移到stack中,最后判断这个link节点是否已经全部转移完里面的对象了,如果已经转移完了,就把下一个link节点置为头节点,这样当下一次再调用transfer方法的时候就能够又能从头节点获取了。也就是说每调用一次transfer方法,就会转移最多一个link节点数量的对象,如果一个对象都没有转移到,那么transfer方法就返回false,反之返回true。
分析了transfer方法,我们再回到scavengeSome方法中重新进行分析,在scavengeSome方法中大概的执行流程如下:
- 首先会通过cursor指针定位到已经遍历到的WeakOrderQueue对象,然后调用这个WeakOrderQueue对象的transfer方法进行对象转移
- 如果transfer方法返回true,则跳出do...while循环,反之如果返回false,则获取下一个WeakOrderQueue,并赋值给cursor指针,然后do...while循环重复上面第一点的步骤
- 如果transfer返回false,则说明这一次没有转移到对象,此时会再去判断当前这个WeakOrderQueue对应的线程是否已经挂了,如果挂了则再判断WeakOrderQueue中是否还存在没有被转移的link节点(因为有可能由于回收频率的控制导致这个link节点中本来有的对象被放弃回收了,但是该节点后可能还存在其他没有被转移的link节点),如果存在,则把剩余的这些link节点中的对象全部转移到stack中,最后再把这个WeakOrderQueue占用的回收对象数量归还给availableSharedCapacity属性,并且把这个WeakOrderQueue从链表中删除
总结来说scavengeSome方法会去遍历WeakOrderQueue链表,如果当前WeakOrderQueue转移不到对象,就换下一个WeakOrderQueue节点进行转移,当发现有WeakOrderQueue节点转移对象成功之后就返回true,反之返回false