在当今的数据驱动时代,组织面临着数据量的爆炸性增长。为了有效管理和存储这些数据,许多组织依赖于 Hadoop 这样的分布式存储系统。Hadoop 集群通过在多个节点上存储数据的冗余副本,提供了高可靠性和可扩展性。然而,随着数据量的不断变化,集群需要灵活地调整其资源以满足性能和存储需求。
一、动态扩缩容的关键性
动态扩缩容功能是集群管理中非常关键的一部分,能够根据工作负载的变化自动调整应用程序的副本数,以确保资源的高效利用和服务的稳定性。
- 动态扩容的必要性
(1)应对数据增长: 随着时间的推移,组织生成和收集的数据量会不断增加。动态扩容允许 Hadoop 集群通过添加新的 DataNode 来增加存储容量,而无需重新配置整个集群或停机。
(2)优化资源利用率:动态扩容使得集群能够在需要时增加资源,从而优化资源利用率。这不仅提高了存储效率,还有助于降低运营成本。
(3)支持业务增长:业务需求的增长往往伴随着数据量的增加。动态扩容支持集群与业务增长同步,确保数据处理和分析能力不会成为业务发展的瓶颈。 2. 动态缩容的重要性
(1)成本效益:随着某些项目或数据集的生命周期结束,对存储资源的需求可能会减少。动态缩容允许集群移除不再需要的节点,从而减少能源消耗和维护成本。
(2)提高运维效率:当硬件需要维护或升级时,动态缩容可以使得集群在不影响服务的情况下,安全地移除特定节点,进行必要的维护工作。
(3)优化性能:通过移除性能低下或故障的节点,动态缩容有助于提高集群的整体性能和稳定性。
二、EasyMR扩缩容详解
袋鼠云大数据存储计算平台EasyMR旨在帮助客户充分释放数据价值,全新推出的Hadoop 节点动态扩缩容功能,目前支持 Hadoop 、 Hbase 组件,且支持 kerbero 安全认证体系,在后续的迭代中也将会支持更多组件。
下面就以 Hadoop 集群 datanode 节点扩缩容为例,用四步简单说明在 EasyMR 中如何操作 datanode 的扩缩容。
- datanode 节点扩容
在实例管理页面,点击添加实例,选择 hdfs_datanode 类型,并指定扩容某个节点。 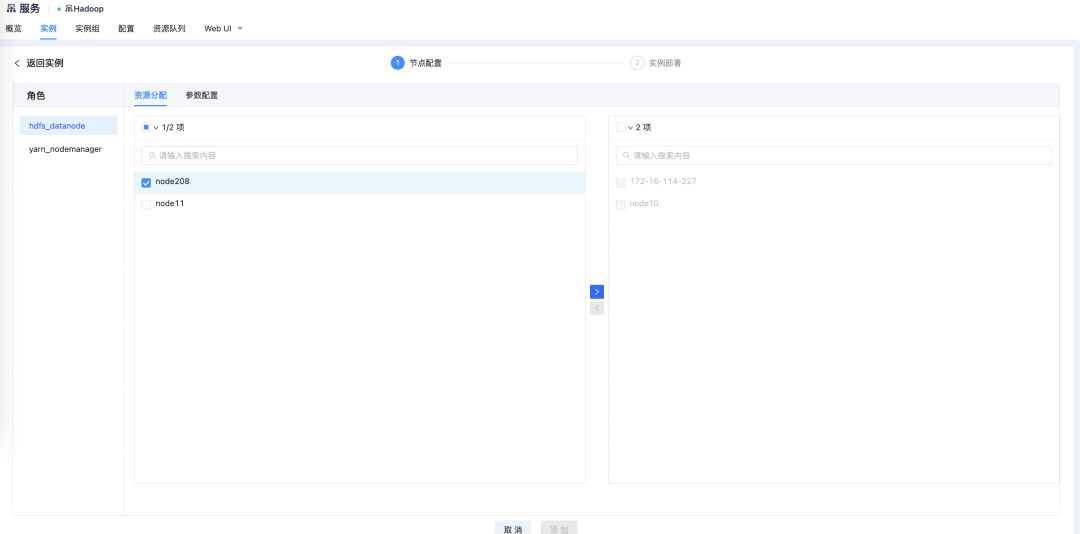 扩容完成后,在 namenode 页面进行查看扩容进度。
扩容完成后,在 namenode 页面进行查看扩容进度。 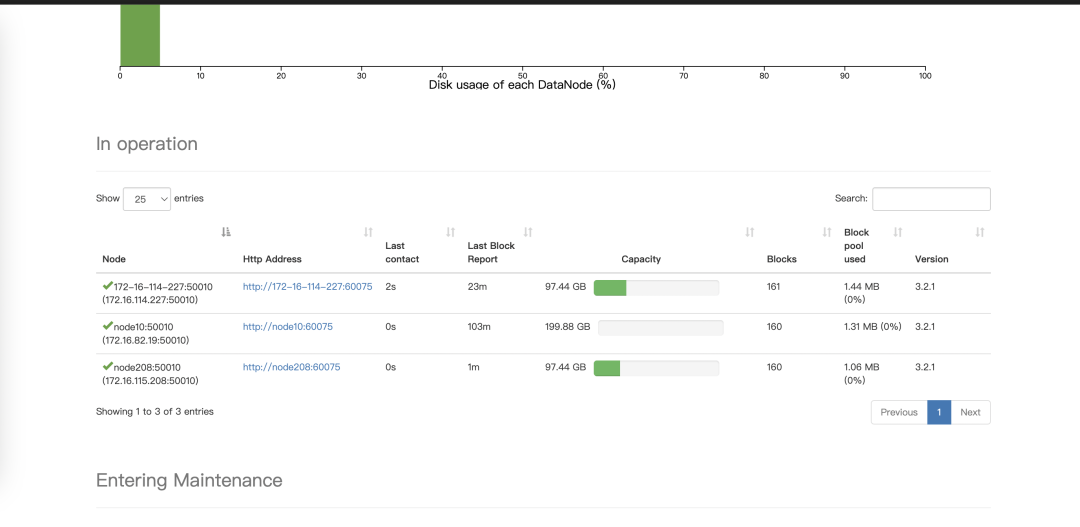 2. datanode 节点退服
2. datanode 节点退服
在 Hadoop 集群的运维过程中,节点的退服是一个常见的操作,这通常涉及到将某个 DataNode 从集群中安全移除。退服的原因可能包括硬件故障、性能升级、维护需求或者集群重组等。
在 EsayMR 实例管理页面,选中要退服的节点,在更多下拉菜单中,选中退服按钮,并进行退服的操作。退服过程中也是通过 namenode 服务的 refreshNode 功能进行退服状态的更新,减少服务的重启给集群带来不可用风险。 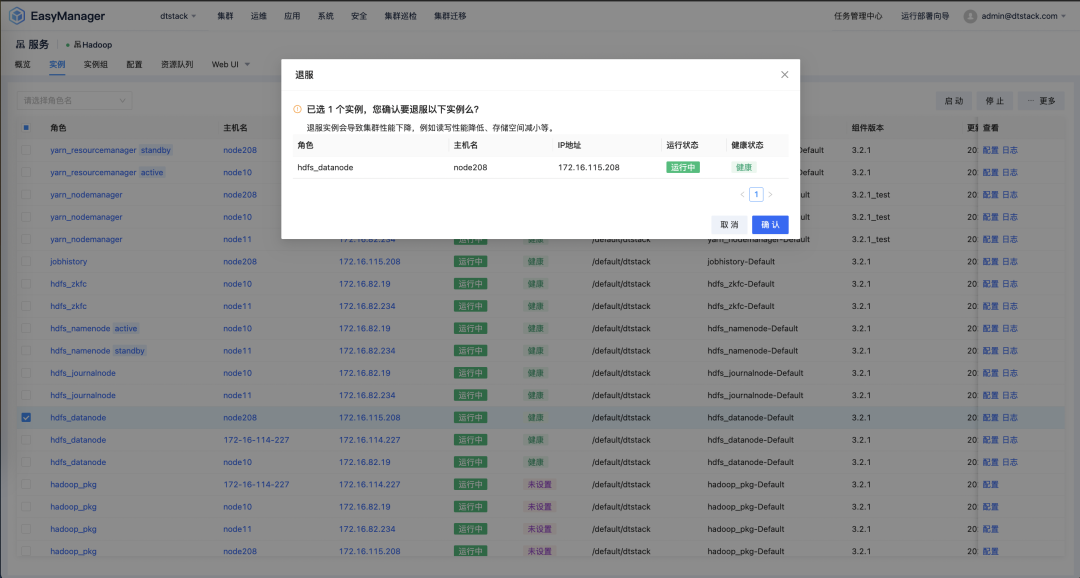 退服完成后,在 namenode 管理页面看到当前节点已经是退服状态。
退服完成后,在 namenode 管理页面看到当前节点已经是退服状态。 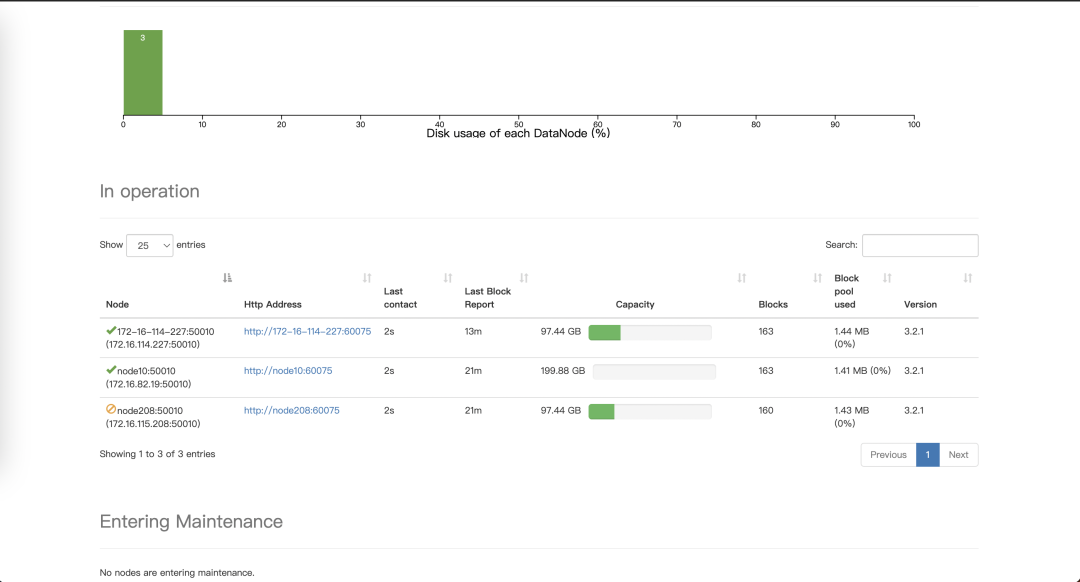 EasyMR 管理页面也会同步当前节点的状态为退服状态。
EasyMR 管理页面也会同步当前节点的状态为退服状态。 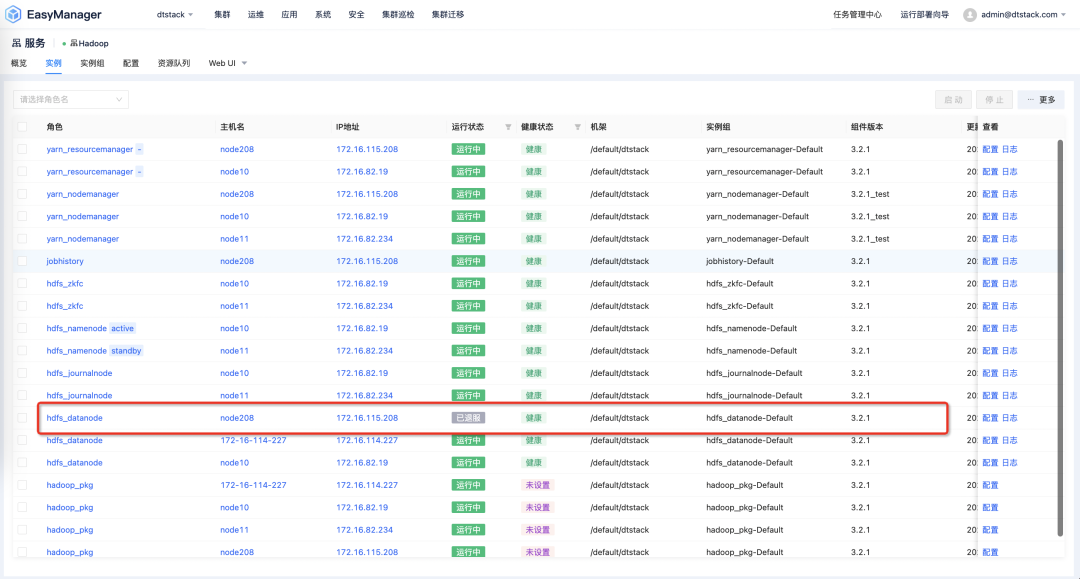 3. datanode 节点入服
3. datanode 节点入服
在 Hadoop 集群管理中,节点退服后重新入服是一个常见的操作,这通常发生在以下几种情况中:
(1)硬件维护或升级: 当某个节点因为硬件故障或者需要进行硬件升级而暂时退服后,一旦维护或升级完成,该节点需要重新加入集群。
(2)软件升级: 集群中的节点可能因为需要安装新的软件版本或者应用补丁而退服,升级完成后,这些节点需要重新入服。
(3)性能优化: 为了优化集群性能,可能会有计划地对某些节点进行退服以进行维护或调整,完成后再重新入服。
(4)故障恢复: 在节点发生故障并修复后,需要重新将其加入集群以恢复正常的集群操作。
(5)集群扩展: 随着业务需求的增长,可能需要将之前退服的节点重新加入集群,以提供更多的计算和存储资源。
(6)数据重新平衡: 在某些节点退服后,集群的数据分布可能会变得不均衡。当这些节点重新入服时,可能需要进行数据重新平衡操作,以优化数据存储和访问效率。
(7)集群升级或重组: 在集群升级或重组过程中,可能会涉及到节点的临时退服和随后的重新入服 在 EsayMR 实例管理页面,选中当前是已经退服状态的节点,在更多下拉菜单中,选中入服按钮,并进行入服的操作。入服过程中也是通过 namenode 服务的 refreshNode 功能进行节点的入服操作。 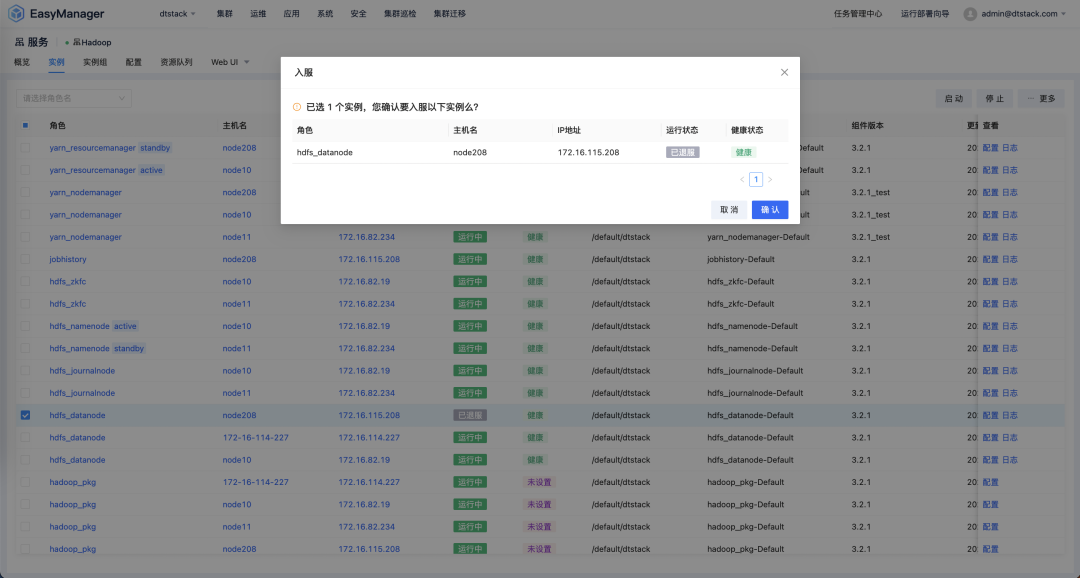 入服成功后,在 namenode 管理页面看到当前节点已经是服役状态。
入服成功后,在 namenode 管理页面看到当前节点已经是服役状态。 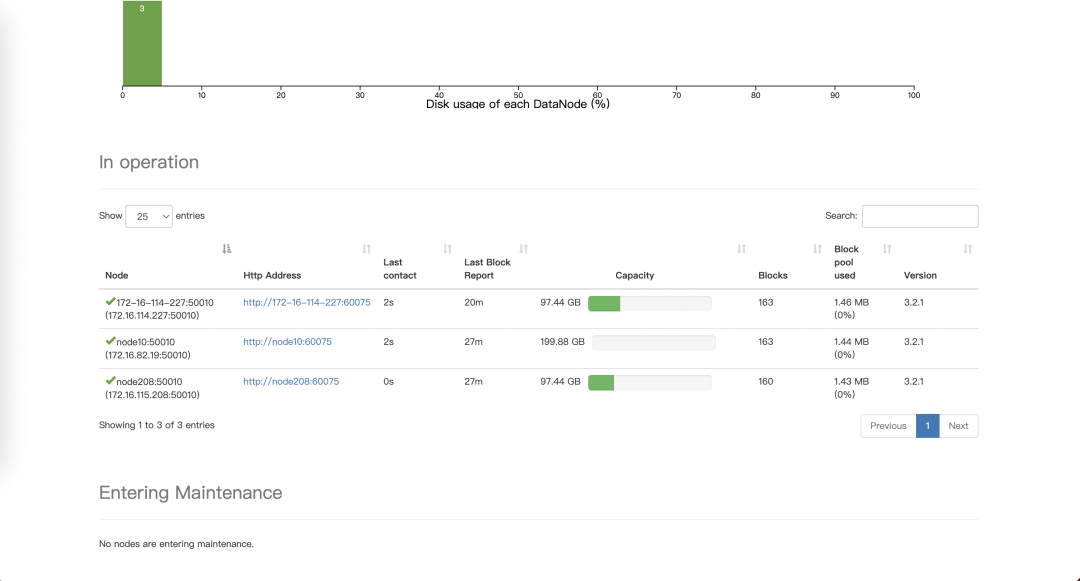 4. datanode 节点删除
4. datanode 节点删除
若节点不再需要进行入服, EasyMR 也支持节点的下架操作。在选中已退服的节点,在更多下拉按钮中找到删除实例选项。 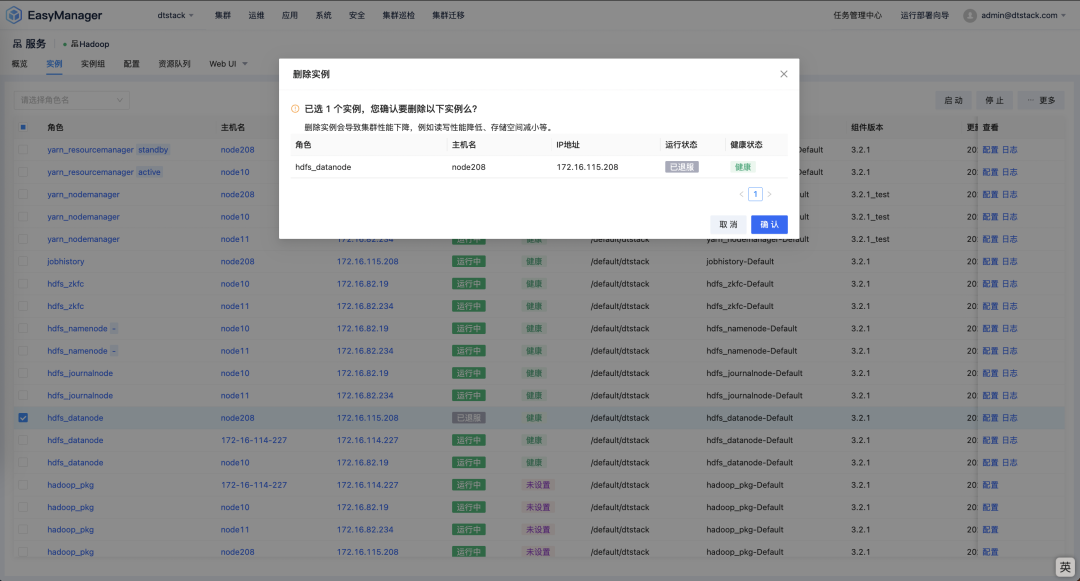 实例删除完成后,在 namenode 管理页面看到当前节点已被删除。
实例删除完成后,在 namenode 管理页面看到当前节点已被删除。 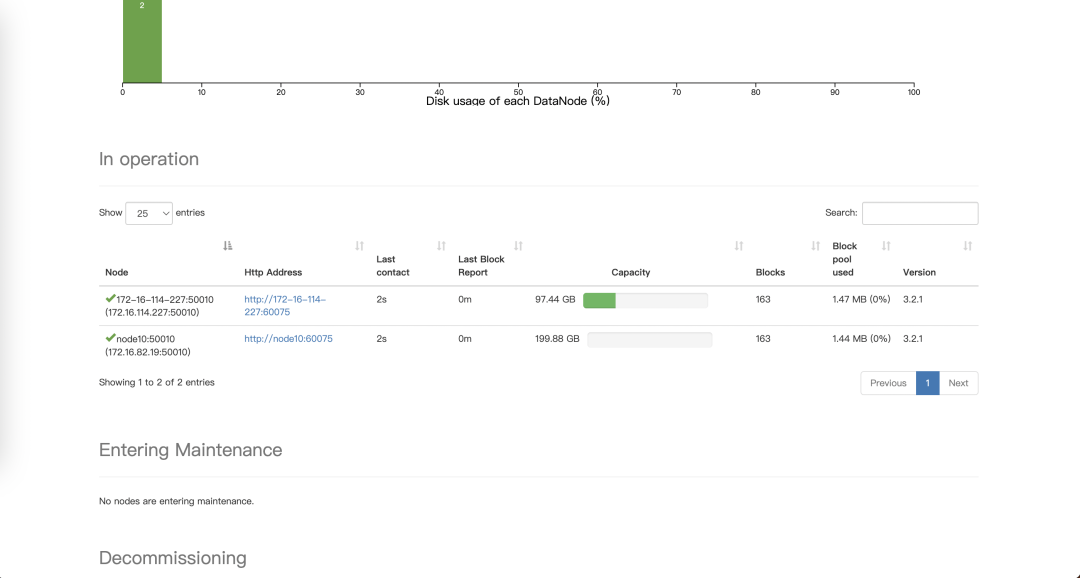
三、总结
通过袋鼠云EasyMR 的 Hadoop 节点动态扩缩容功能,可以根据实际需求灵活调整集群规模,确保数据的安全性和完整性。同时,提高集群的整体性能和稳定性,快速实现集群服务能力提升,提高资源利用率和系统性能,助力企业在数据储存和管理方面实现质的飞跃。 对「EasyMR」兴趣的朋友,可以点击文末的「阅读原文」,免费试用该产品。 《行业指标体系白皮书》下载地址:https://www.dtstack.com/resources/1057?src=szsm
《数栈产品白皮书》下载地址:https://www.dtstack.com/resources/1004?src=szsm
《数据治理行业实践白皮书》下载地址:https://www.dtstack.com/resources/1001?src=szsm
想了解或咨询更多有关大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szcsdn