一、介绍
champ是由阿里巴巴、复旦大学和南京大学的研究人员共同提出的一种基于3D的将人物图片转换为视频动画的模型,该方法结合了3D参数化模型(特别是SMPL模型)和潜在扩散模型,能够精确地捕捉和再现人体的3D形状和动态,同时保持动画的时间一致性和视觉真实性,以生成高质量的人类动画视频。
- 将静态人物图片转换为动态视频动画,通过精确捕捉和再现人体的形状和动作,创造出既真实又可控的动态视觉内容。
- 能够精确地表示和控制人体的形状和姿势,从源视频中提取的人体几何和运动特征更加准确。
- 能够将来自一个视频的运动序列应用到另一个不同身份的参考图像上,实现跨身份的动画生成。
- 在生成视频时保持了角色和背景之间的一致性,同时通过时间对齐模块确保帧之间的流畅过渡,从而产生高质量的视频输出。
二、部署流程
基础配置推荐:
系统:Ubuntu系统,
显卡:3090,
显存:24G,cuda12.1
1.基础环境
-
查看系统是否有Miniconda3的虚拟环境
conda -V如果输入命令没有显示Conda版本号,则需要安装。

2.更新系统命令
输入下列命令将系统更新及系统下载
apt-get update && apt-get install ffmpeg libsm6 libxext6 -y
3.下载模型
输入下列命令对champ模型进行下载
git clone https://gitclone.com/github.com/fudan-generative-vision/champ.git
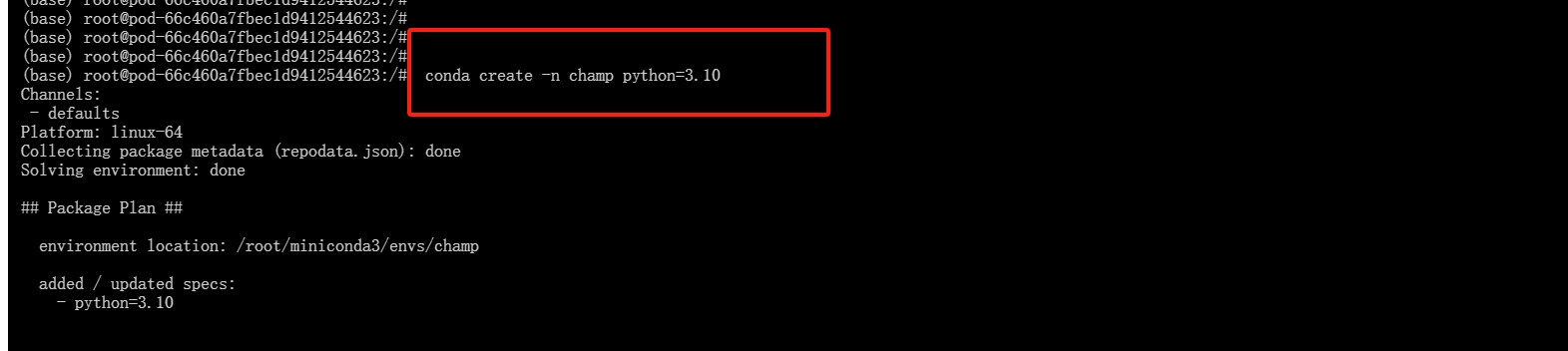
4.创建虚拟环境
-
创建一个名称为"champ",python版本号为3.10的环境
conda create -n champ python=3.10
-
激活"champ"虚拟环境
conda activate champ

5.下载依赖包
进入champ文件输入下列命令:
cd champ
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple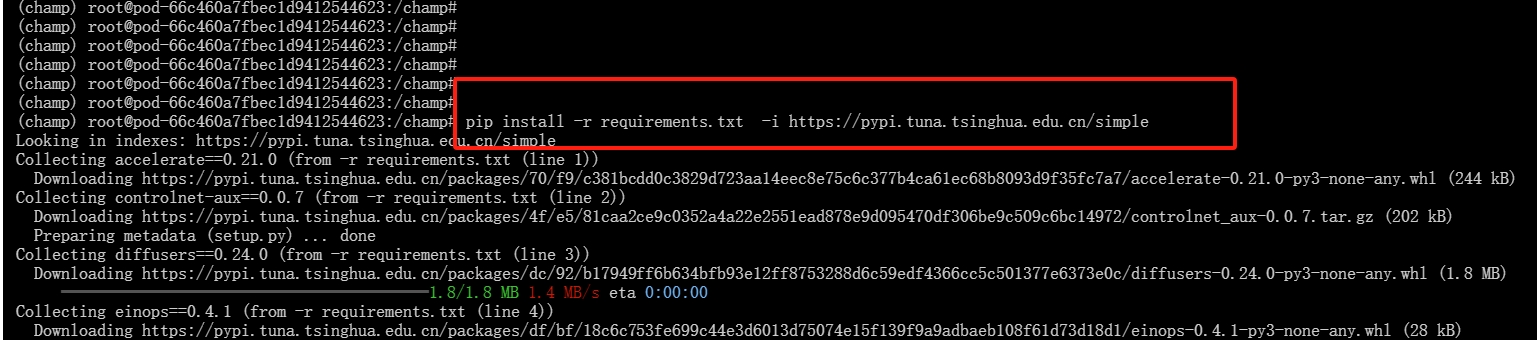
6.下载预训练模型
输入下列命令:
git lfs install
git clone https://huggingface.co/fudan-generative-ai/champ pretrained_models7.下载运动指导动作数据
输入下列命令:
git lfs install
git clone https://huggingface.co/datasets/fudan-generative-ai/champ_motions_example example_data
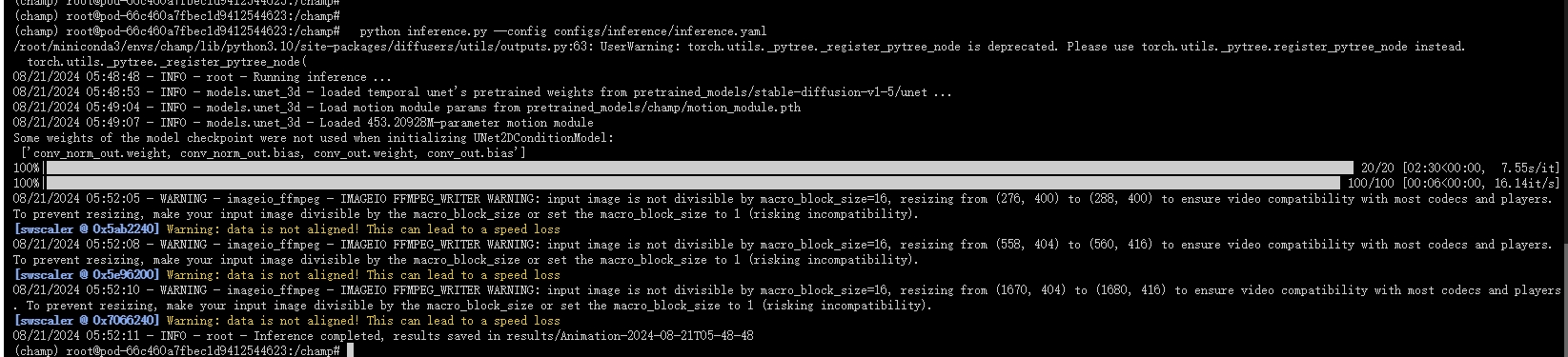
8.运行推理
注意:如果 VRAM 不足,您可以切换到较短的运动序列或从长序列中剪切出一段。我们在其中提供了一个帧范围选择器,您可以将其替换为列表,以方便从序列中剪切出一段。inference.yaml[min_frame_index, max_frame_index]
输入下列命令:
python inference.py --config configs/inference/inference.yaml