文章目录
-
- HTTP的请求方法
- HTTP的状态码
- TCP的短连接与长连接
- [Connection 头部](#Connection 头部)
- [Content-Type 头部](#Content-Type 头部)
- [Set-Cookie 头部](#Set-Cookie 头部)
-
- [Session ID](#Session ID)
| 本文代码参照前一篇博客 |
|---|
HTTP的请求方法
HTTP协议存在多种请求方法,但是较为常用的请求方法基本为GET方法与POST方法;
其中GET方法与POST方法的不同之处在于:
-
GET方法GET方法主要为从服务器中获取资源,用于请求数据而不对数据进行更改;同时
GET方法将会把参数以url的形式提交给服务器;有一段
html代码为如下:html<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>Document</title> </head> <body> <h1>Hello World</h1> <p>Here is page 1.</p> <form method="get"> Name:<br> <input type="text" name="firstname" value="Username"> <br> Passwd:<br> <input type="password" name="lastname"> <br> <br> <input type="submit" value="Submit"> </form> </body> </html>该网页对应的样式为:
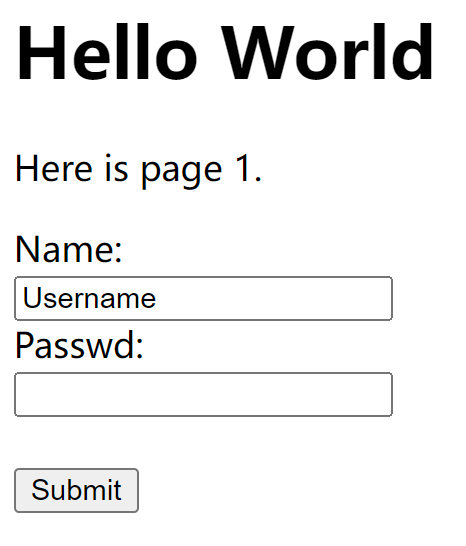
其中表单标签中的
method方法设置为get方法,这意味着当进行submit提交时表单中的信息将会以GET方式提交给服务器(默认情况,即表单标签中不设置method属性时默认也以GET方式进行提参);假设此处文本框内填入的信息为
abcde与123456并进行提交操作;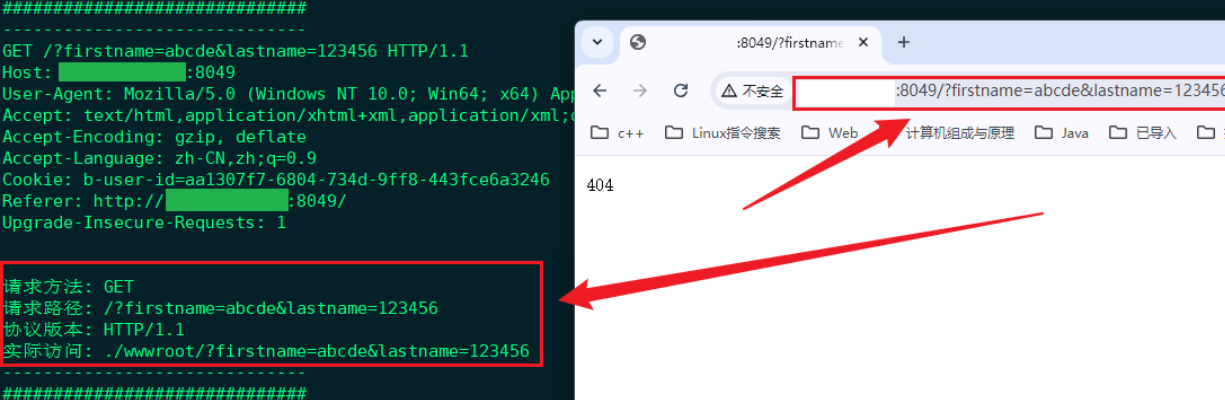
参数以
url的形式被提交给服务器,此时提交的信息存在暴露风险; -
POST方法当使用
POST方法对参数进行提交时对应的参数将会以请求正文的方式交由给服务器;对上述
html代码中的get方法修改为post方法再次进行一次输入与提交;html<form method="post">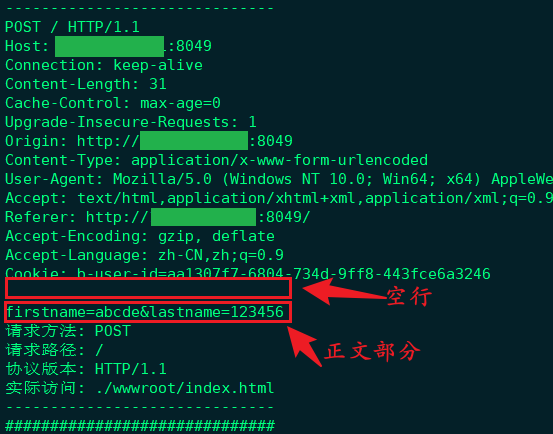
对应的请求方法由
GET变成了POST,同时提参的方式由url形式提参变成了以请求正文的方式进行提参;
基本上大多数的搜索引擎对于关键词搜索的方式都采用的是GET的方式;
以www.baidu.com为例;
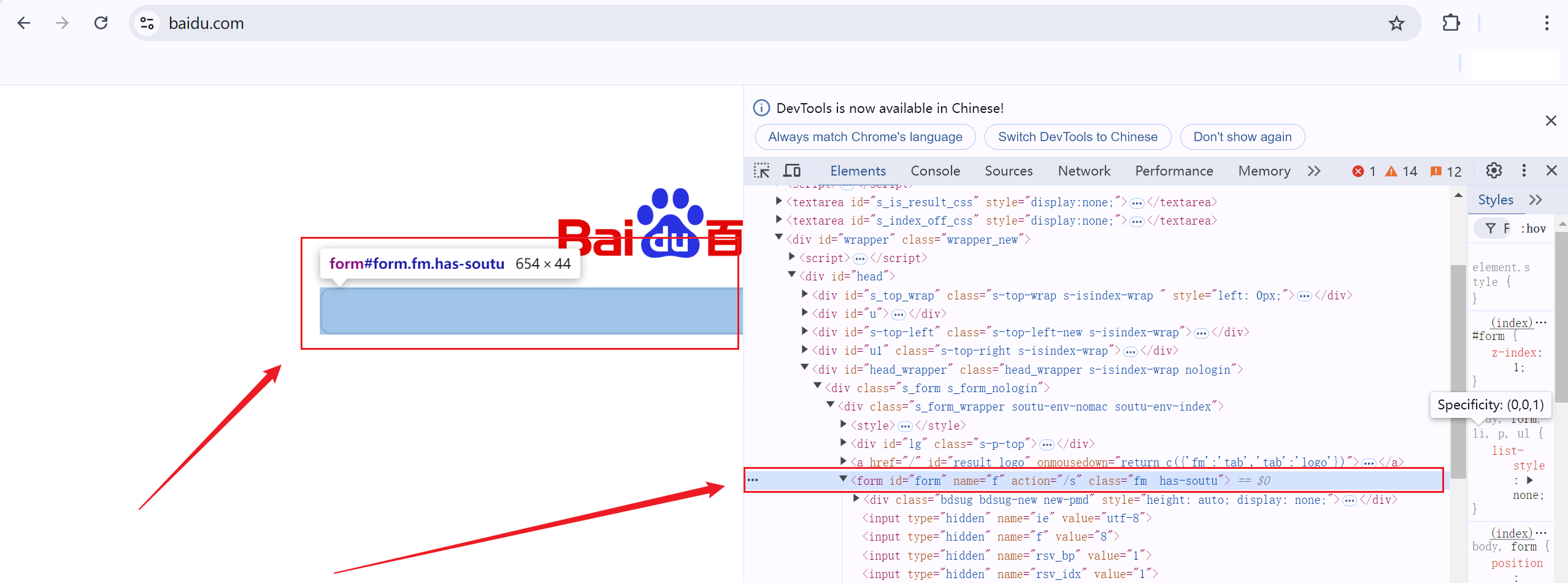
在这个页面中,对于搜索框的表单中未指定method方法,表示默认使用GET方法,当然从搜索后的url也可表明这一点;

对于GET方法而言,其通过URL进行提参,参数数量受限,同时提参信息不私密;
POST方法也支持提交参数,但采用的方式是以正文形式进行提交;
对于安全性而言,POST与GET方法都不安全,安全是以是否对提交的信息进行加密处理从而判断其提交信息是否安全而不是对应的提交方式;
HTTP的状态码
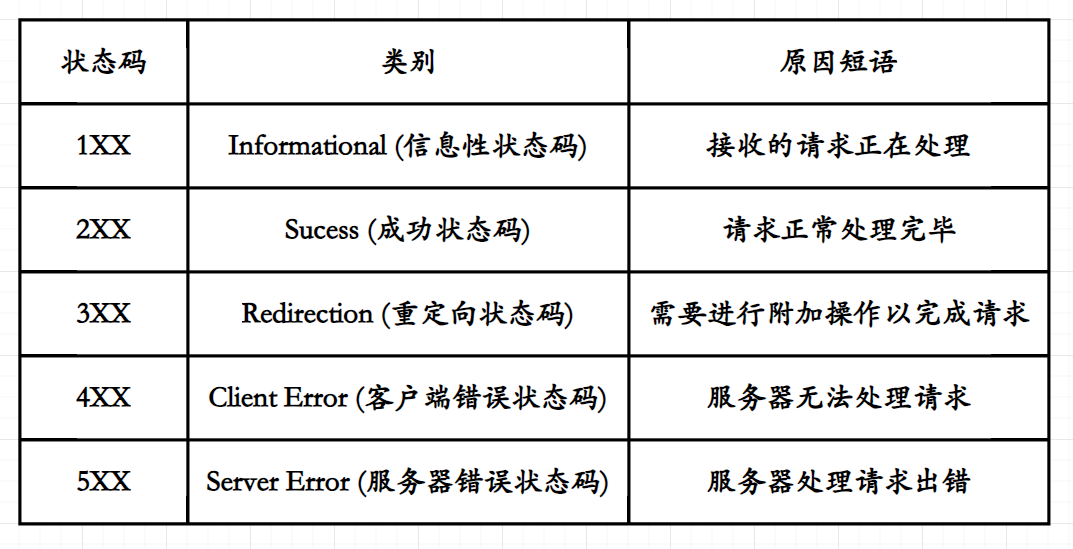
-
1XX以
1为开头的状态码被称为信息性状态码;通常情况下当一个客户端向服务端发起请求时,在请求未处理完成时服务端将率先响应给客户端一个状态码为
1XX的响应,表示当前请求还在被处理中;通常情况下这种响应的出现较少,在实际应用中并不频繁;
主要用于一些高级和特化的用途,如果设计应用需要处理复杂的请求过程,协议升级或是长时处理的请求则可能会使用
1XX的状态码; -
2XX通常情况下以
2开头的状态码才是最常见的状态码也是最常用的状态码;以
200为例,这个状态码表示来自客户端的请求已经处理完毕并且返回一个正确的响应给客户端; -
4XX4开头的状态码一般为服务器无法处理请求,通常情况下这类状态码表示客户端错误;以常见的
404为例,该状态码一般表示服务器站点中不存在对应的资源;通常情况下一个站点中都将为自己的站点设置一个对应的
404页面以提示用户其所访问的资源不存在;这里以
Google搜索引擎为例: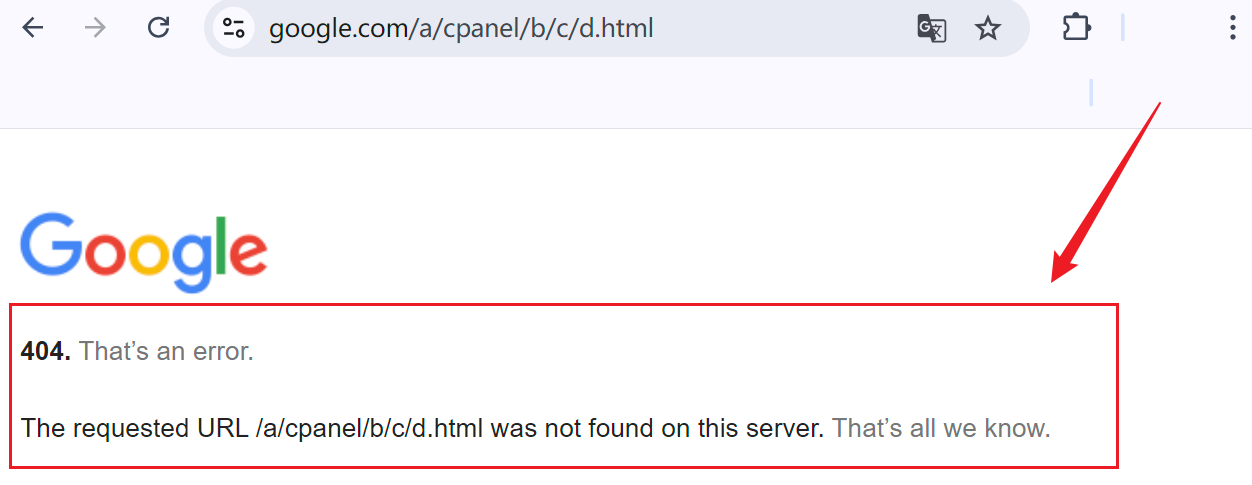
当试图访问一个为
google.com/a/cpanel/b/c/d.html路径时,对应的将会跳出一个404的页面;这是一种处理当用户访问该站点下不存在的资源时的一种措施,以明确提醒所访问的资源不存在;
这种错误被归咎于客户端错误的原因是在一个站点下并不是存在所有资源,客户端向服务器发起请求时若是试图访问一个站点(服务器)下不存在的资源或是无权限进行访问的资源即表示该请求是一个不合法的请求,所以为客户端错误;
-
5XX5开头的状态码通常表示服务器错误,假设一个客户端试图向一个已经高负载的服务端发出一个合法的请求,当服务端接收到请求时或许需要创建一个新的线程来处理这个来自客户端的合法请求,而服务端由于负载过高无法再创建线程来处理该合法请求即可能会返回客户端一个5开头状态码的响应表示服务器错误;或者是在处理过程中出现无法与数据库连接等错误都为服务器错误;
模拟404状态
在博客『 Linux 』HTTP(二)以及之前的博客中,模拟实现了一个简单的HTTP协议服务器,但是并没有完全完善其中的代码;
在这个服务器当中没有设置对应的404措施;
模拟实现这个状态的思路即为判断当前服务器中是否存在该资源,若是不存在对应的路径资源则返回一个特定的404页面以表示当前资源路径不存在;
假设存在一个html文件,其文件名为err.html,其对应代码为如下:
html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<center>
<h2>
Resources not found
</h2>
<a href="http://example:8049/">
Come back to Home Page;
</a>
</center>
</body>
</html>其页面展示为:

对应的需要实现出这种效果需要在服务器中判断所访问的资源是否存在;
cpp
/* httpserver.html */
class HttpServer
{
public:
static std::string ReadHtmlContent(const std::string &path)
{
std::ifstream in(path);
if (!in.is_open())
{
return ""; // 打开失败则 返回空串
}
// 打开失败时此函数不进行后续操作
std::string content;
std::string line;
while (std::getline(in, line))
{
content += line;
}
in.close();
return content;
}
// 单独封装处理工作
static void HandlerHttp(int sockfd)
{
char buffer[10240];
ssize_t n = recv(sockfd, buffer, sizeof(buffer) - 1, 0);
if (n > 0)
{
buffer[n] = 0;
HttpRequest request;
request.Deserialize(buffer);
request.Parse();
request.DebugPrint();
// 返回响应
std::string line_feed = "\r\n"; // 换行
std::string text;
bool ok = true; // 设置变量用于条件判断从而修改返回响应时能够返回对应的状态码
text = ReadHtmlContent(request.resource_path); // 调用函数对文件进行读取 // 响应正文
if (text.empty())
{
// 当返回的为空串时则表示访问资源不存在 返回响应时返回对应的404页面即可
std::string err_html = wwwroot;
err_html += "/";
err_html += "err.html";
text = ReadHtmlContent(err_html);
ok = false;
}
std::string response_line;
// 根据条件变量状态来返回不同的状态码
if (ok)
response_line = "HTTP/1.0 200 OK" + line_feed;
else
response_line = "HTTP/1.0 404 Not Found" + line_feed;
std::string response_header = "Content-Length: ";
response_header += std::to_string(text.size());
response_header += line_feed;
std::string blank_line = "\r\n";
response_header += line_feed;
std::string response = response_line + response_header + text;
send(sockfd, response.c_str(), response.size(), 0);
}
close(sockfd);
}
private:
uint16_t port_;
static const uint16_t defaultport;
NetSocket listensock_;
};在这段代码中调用ReadHtmlContent()函数打开请求所访问资源,若是当打开资源失败时则返回一个空串;
调用该函数的函数判断返回的是否为空串,如果为空串则修改所要访问的资源为指定路径下的err.html文件并修改对应响应的状态码;
重新编译代码,运行服务器并尝试访问一个不存在的资源;
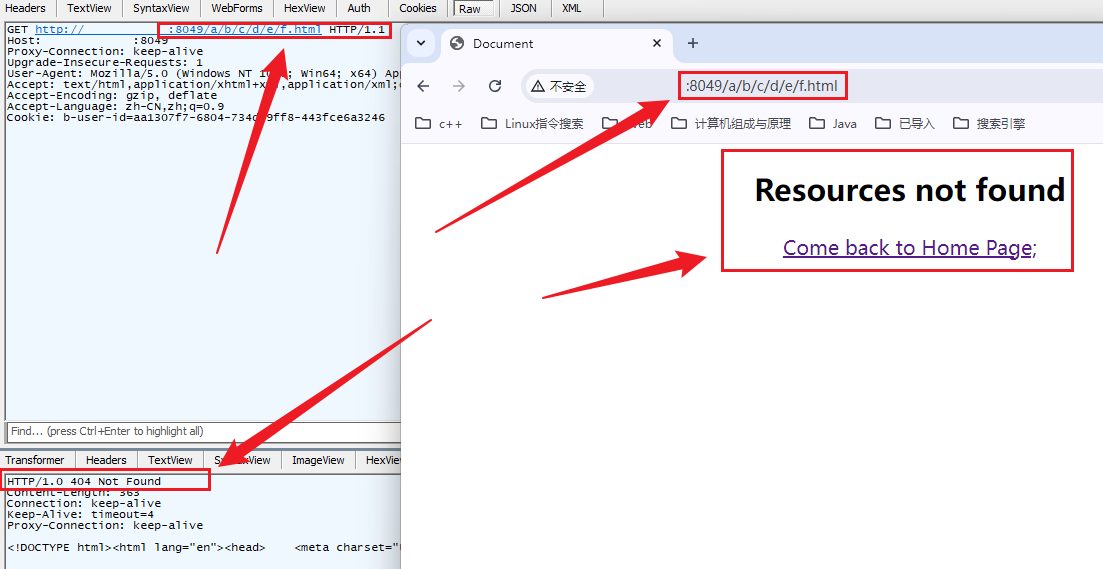
从网页以及Fiddler的抓包来看,实现已经成功;
当服务器返回404响应给客户端时实际上也是一个响应,只不过对应响应的状态码为404;
重定向状态码
3XX的状态码通常表示重定向操作;
重定向即表示客户端向服务端对应发起请求,服务端返回客户端一个响应,但是这个响应是一个重定向响应,这个重定向响应中存在一个3开头的状态码表示需要进行重定向,并且在响应的报头中将会存在Location字段,如Location: http://www.example.com,并且该报头后将会携带对应重定向的url以告诉客户端第二次请求时对应的位置,对应的客户端当收到这个重定向响应时将会向该重定向响应中Location字段中的url发起请求;
通常情况下服务端最常用的重定向为两种,分别为临时重定向302与永久重定向301;
-
302状态码该重定向表示临时重定向,临时重定向通常发生在该服务端正在维护,当客户端向服务端发起请求时服务端将会返回一个重定向响应,对应的浏览器将会根据
Location报头进行跳转,因为是临时的,所以通常情况下发生临时重定向时用户只需要访问旧的IP,根据浏览器做对应跳转即可; -
301状态码301状态码表示永久性重定向,永久性重定向通常表示该服务器已弃用等情况,对应的同样当客户端向永久重定向的服务器发起请求时,对应的会根据Location字段进行跳转;
两个重定向都会进行响应的跳转,但不同的是临时重定向时浏览器都会根据Location进行重新发起请求;
而永久重定向时对应的浏览器将会缓存永久重定向的Location字段,每次向该永久重定向的服务器发起请求时默认将直接访问新的URL而不对旧的URL进行请求;
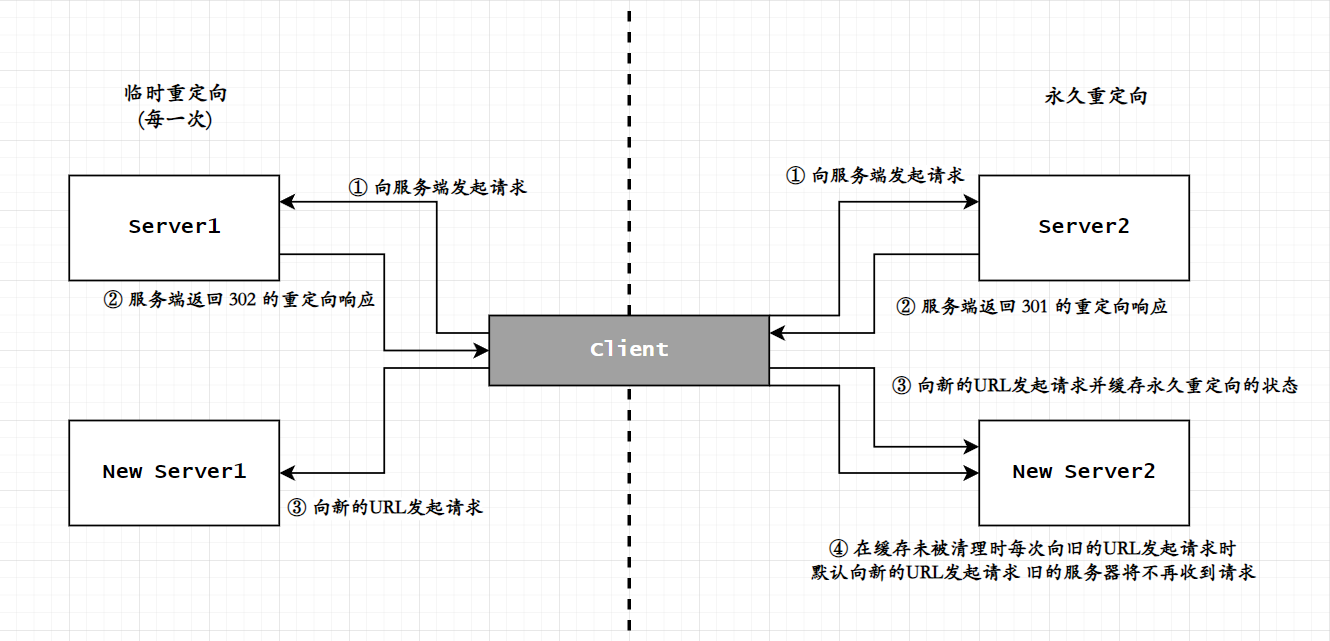
对于永久重定向的缓存是根据缓存设定而定的,同时不同的浏览器将会有不同的行为,无法确保统一;
但是总体策略一致:
-
缓存机制
浏览器通常采用内存级和磁盘级两种缓存机制,内存缓存用于回话级别的临时缓存,磁盘缓存用于长期存储;
此处将对临时重定向进行模拟实现;
对应的只需将状态码修改为302,并且在响应中添加Location报头字段并增加对应的URL即可;
cpp
/* httpserver.hpp */
static void HandlerHttp(int sockfd)
{
char buffer[10240];
ssize_t n = recv(sockfd, buffer, sizeof(buffer) - 1, 0);
if (n > 0)
{
buffer[n] = 0;
HttpRequest request;
request.Deserialize(buffer);
request.Parse();
request.DebugPrint();
std::string line_feed = "\r\n";
std::string text;
bool ok = true;
text = ReadHtmlContent(request.resource_path);
if (text.empty())
{
std::string err_html = wwwroot;
err_html += "/";
err_html += "err.html";
text = ReadHtmlContent(err_html);
ok = false;
}
std::string response_line;
if (ok)
// response_line = "HTTP/1.0 200 OK" + line_feed; // 注释 200状态码 默认状态码为302
response_line = "HTTP/1.0 302 Found" + line_feed; // 302状态码对应的状态码描述为 Found
else
response_line = "HTTP/1.0 404 Not Found" + line_feed;
std::string response_header = "Content-Length: ";
response_header += std::to_string(text.size());
response_header += line_feed;
response_header += "Location: https://www.baidu.com";
// 添加Location: 字段并添加对应的url
response_header += line_feed; // 换行
std::string blank_line = "\r\n";
response_header += line_feed;
std::string response = response_line + response_header + text;
send(sockfd, response.c_str(), response.size(), 0);
}
close(sockfd);
}在这段代码中注释掉了原有的200状态码的响应状态行,设置了一个新的状态码为302的状态码响应行;
同时设置了一个Location: 报头字段,后面跟上了https://www.baidu.com表示临时重定向至该URL;
重新编译并运行服务器重新对服务器进行访问并用Fiddler工具进行抓包;
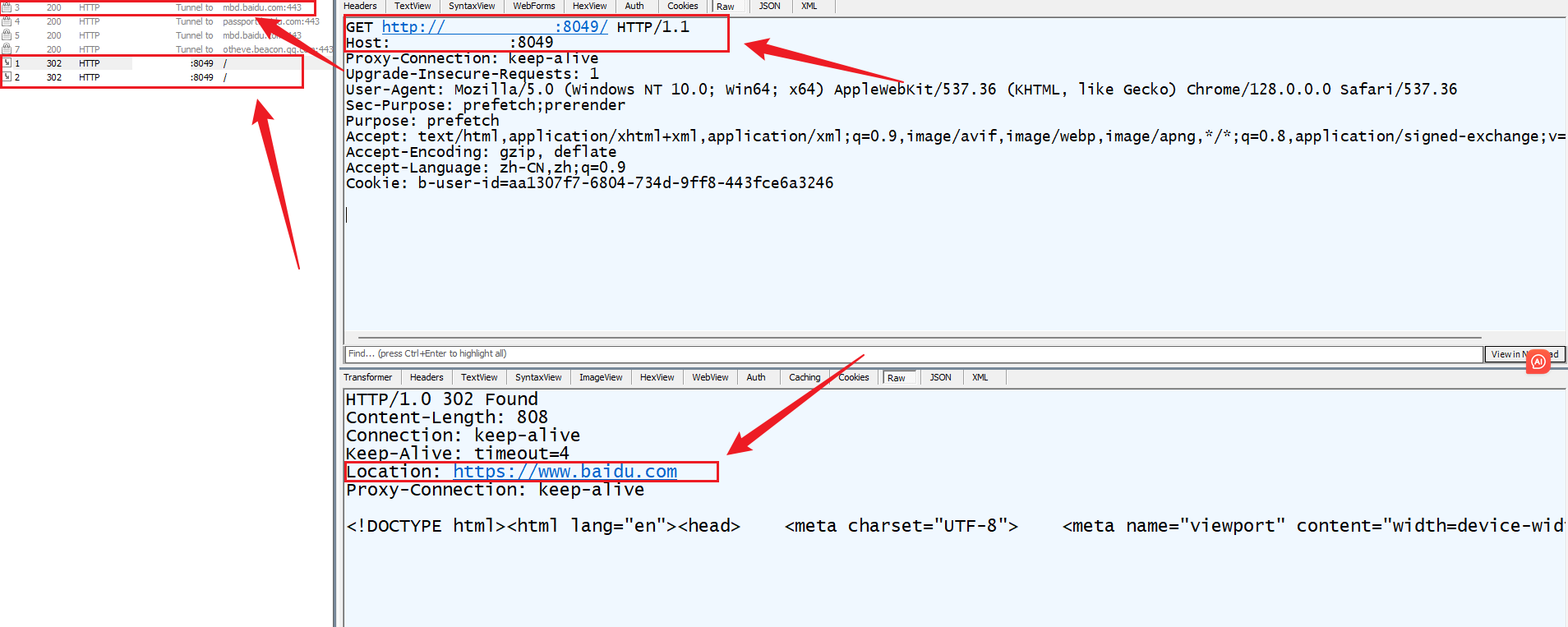
最终结果为客户端接收到对应的重定向响应后将重新向Location字段中的URL重新发起请求;
状态码与浏览器的联系
状态码可以视为是HTTP协议中的一种约定,约定在不同的场景中返回不同的状态码,而实际上在实际的开发中,状态码的约束能力并不是很严格,主要是不同的浏览器作为客户端对请求的处理手段不同;
这些差异包括但不限于:
-
重定向处理
许多现代浏览器会自动处理
301和302,并且在301重定向的情况下会缓存新的URL;对于
307(临时重定向)和308(永久重定向),一些焦躁的浏览器可能不支持或是处理的方式不同; -
缓存策略
即使服务器返回相同的状态码,不同的浏览器可能使用不同的缓存策略,例如IE浏览器和Chrome浏览器可能对
Cache-Control:头部的支持和解析有差异; -
错误页面显示
用户在浏览一些错误页面时,不同的浏览器可能提供不同的用户体验,如
404错误页面在不同的浏览器中可能会有不同的设计和内容; -
安全性考虑
对于某些安全相关的状态码
401和403状态码,不同浏览器可能在具体处理和警告用户的方式上存在不同;
同时在开发过程中,由于状态码的非严格约束,导致可能一个服务器开发者在非重定向等响应中的状态码都将返回200 ok的状态码与状态码描述;
通常情况下3XX系列的状态码必须与Location头部配合使用;
TCP的短连接与长连接
-
短连接
短连接顾名思义即短的连接,一次的TCP连接只保障一次HTTP请求与响应;
当单次的请求与响应结束之后,对应的TCP连接将会被关闭,当再次需要进行一次HTTP的请求与响应时对应的要重新建立TCP连接;
这意味着一次TCP连接在进行完三次握手后一次请求与响应结束了就要进行四次挥手并关闭连接;
流程如下:
-
建立连接(三次握手)
客户端发送SYN报文;
服务器返回SYN-ACK报文;
客户端回应ACK报文;
-
发送请求和接收响应
客户端发送HTTP请求(如
HTTP GET请求);服务器处理请求并返回响应;
-
关闭连接(四次挥手)
服务器发送FIN报文,表示要关闭连接;
客户端返回ACK报文,确认收到了服务器的FIN报文;
客户端发送FIN报文表示自己也准备关闭连接;
服务器返回ACK报文确认收到客户端的FIN报文,至此连接关闭;
对于短连接而言每次的请求与响应都要进行上述流程;
-
-
长连接
长连接则保持TCP连接在多个请求和响应期间不关闭,只有在显式关闭或是超时时才关闭这个TCP连接;
这种方式减少了TCP连接的建立和关闭次数,尤其是在频繁通信时具有显著优势;
流程如下:
-
建立连接(三次握手)
客户端发送SYN报文;
服务器返回SYN-ACK报文;
客户端回应ACK报文;
-
持续发送请求和接收响应
客户端发送HTTP请求(如
HTTP GET请求);服务器处理请求;
重复发送新请求,不需要重新建立连接;
-
关闭连接(四次挥手)
服务器发送FIN报文,表示要关闭连接;
客户端返回ACK报文,确认收到了服务器的FIN报文;
客户端发送FIN报文表示自己也准备关闭连接;
服务器返回ACK报文确认收到客户端的FIN报文,至此连接关闭;
-
Connection 头部
短连接多用于一些较为简单场景,比如HTTP/1.0,每个请求响应对使用一个单独的TCP连接,一些较为简单的一次性数据传入,如简单的文件下载和网页浏览也可以使用短连接;
长连接多用于频繁数据交互的场景,如HTTP/1.1与HTTP/1.2,即支持持久连接和服用,允许多个请求响应对复用一个TCP连接;
对于HTTP/1.1与HTTP/2.0而言,其在对多个请求的情况处理有所不同,但两者都为长连接的使用方,对于HTTP/1.1而言,其虽然是长连接,但是在多个请求中仍然需要一对一进行处理,即当出现多个请求时将会一个请求发出并且等待服务器处理并响应回才会发送下一个请求,而对HTTP/2.0而言,其允许单个TCP请求中并行发送多个请求并处理多个响应,响应和请求之间互不干扰;
当一个网页,即html文件多资源的情况(这里的资源包括但不限于图像,音频,视频等资源)时,客户端发给服务端的请求应当不只有一个而是多个,这是因为多资源的情况下其他的资源也必然存在在Web根目录中或者其中的子目录当中,所以对应的需要发起对应的请求,在这种情况下即为短连接的短板,其无法在一次TCP连接中处理多个请求与响应,将会增大开销;
而通信双方若是使用HTTP协议时双方都必须约定所使用的HTTP协议版本,通常情况下该版本的诉求方为客户端,因为通常为客户端向服务端发起请求,在请求中会存在所使用的HTTP版本,对应的在进行服务端开发时应做好不同HTTP版本的开发以应对不同版本客户端所发的请求;
在HTTP报文中的报头存在字段Connection: ,该字段用于服务端与客户端双方约定是否使用长连接技术;
在报头中可以设置Connection字段来设置是否使用长连接技术:
-
HTTP/1.0HTTP/1.0默认情况下在每个请求/响应结束后将会关闭TCP连接,即默认是短连接的,但如果设置Connection: keep-alive头字段进行指定;这意味着虽然
HTTP/1.0没有原生支持长连接的机制,但是可以通关设置这个字段实现类似于HTTP/1.1的持久连接功能; -
HTTP/1.1该版本的HTTP协议默认支持长连接,即一次TCP连接中可以进行多对请求/响应,其默认行为与设置
Connection: keep-alive字段相同,即无论是否设置该字段为使用长连接都采用的是长连接的方式;对应的若是不需要使用长连接手段则需要显式将该字段设置为
close,即Connection: close;
Content-Type 头部
假设当前Web根目录的结果为如下:
cpp
/* /wwwroot/ */
$ tree .
.
├── err.html
├── image
│ └── helloworld.png
├── index.html
└── pages
├── page_2.html
└── page_3.html
2 directories, 5 files在该Web根目录中存在一个image/目录,其中存在这样一张图片,对应的图片命名为helloworld.png:

将该图片以资源的方式放置在html文件index.html中;
其对应的html文件代码如下:
html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<h1>Hello World</h1>
<p>Here is page 1.</p>
<form method="post">
Name:<br>
<input type="text" name="firstname" value="Username">
<br>
Passwd:<br>
<input type="password" name="lastname">
<br><br>
<input type="submit" value="Submit">
</form>
<center>
<div>
<img src="./image/helloworld.png"> <!-- 图片 -->
<h4>Hello World</h4>
</div>
</center>
</body>
</html>运行服务器并进行访问;
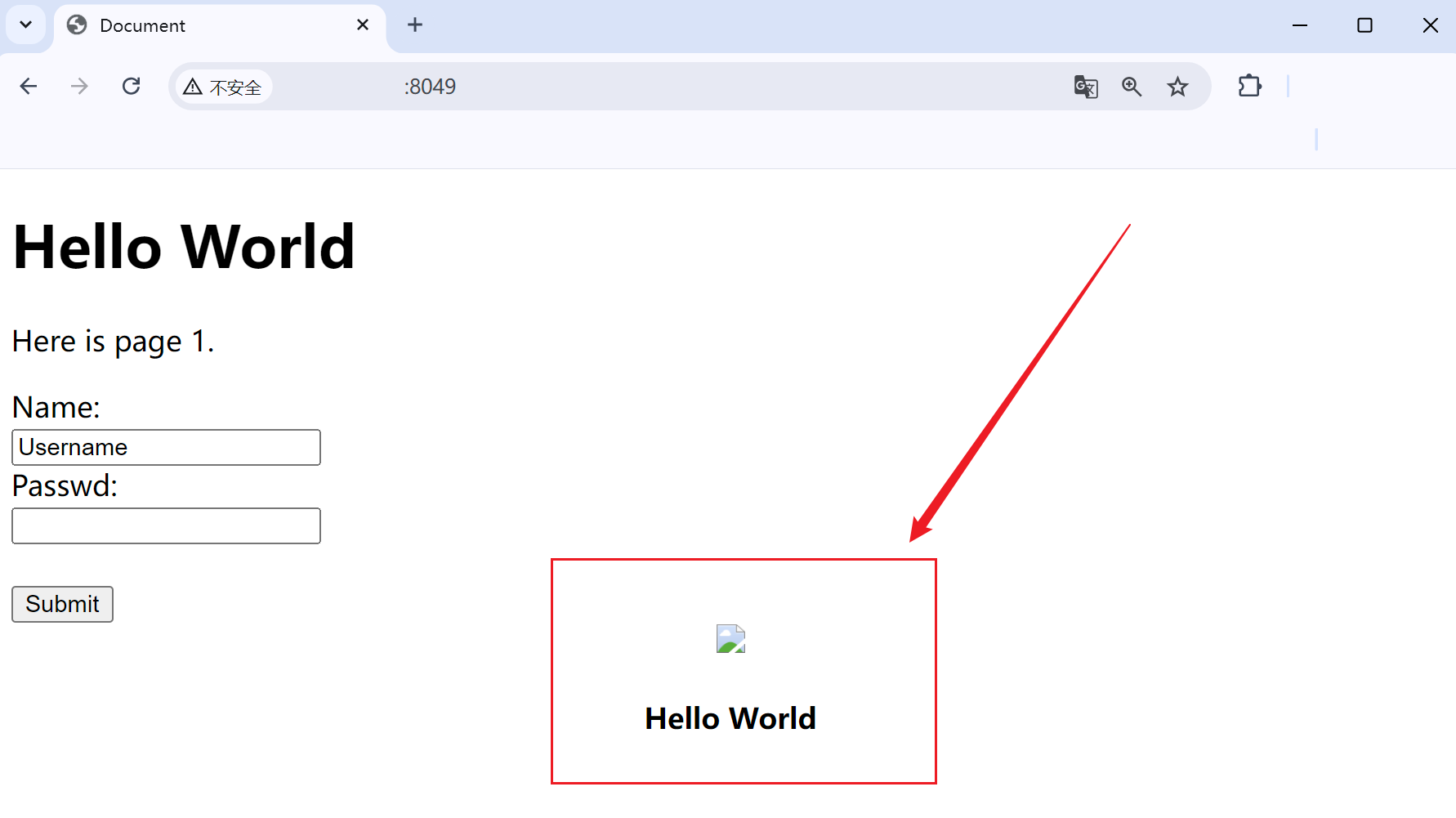
从访问结果来看,图片并没有如约进行显示,本质原因是在自定义编写的HTTP服务器中,读取的方式是无论什么文件类型都采用文本的形式进行读取,而图片若是采用文本的形式进行读取将会出现错误故无法显示;
通常情况下图片是以二进制流的方式进行存储,故对应的读取方式应该也是使用二进制流;
当服务端在解析文件的时候需要根据不同文件的类型对不同类型的文件进行读取,否则将读取失败;
对于网页文件,如html文件而言,其标签<!DOCTYPE html>可以明确告诉浏览器该文件是一个html的文档文件,通常情况下大部分的浏览器都会直接将其以网页的形式进行解析,但图片文件不同,图片文件由于不存在类似的头部,浏览器无法明确知道该资源的类型,所以需要明确的指出资源的类型;
通常情况下这个文件资源的类型是由服务器返回给客户端的响应中携带的内容,以Content-Type: 头部进行指定;
Content-Type头部中的属性格式根据不同的文件类型同样也存在许多不同的格式,一些常用的类型对照表如下:
| 类型 | Content-Type |
|---|---|
| HTML | text/html |
| 普通文本 | text/plain |
| CSS | text/css |
| JavaScript | text/javascript |
| JSON | application/json |
| XML | application/xml |
| 表单数据 | application/x-www-form-urlencoded |
multipart 表单 |
multipart/form-data |
| PNG 图像 | image/png |
| JPEG 图像 | image/jpeg |
| GIF 图像 | image/gif |
| MP3 音频 | audio/mpeg |
| OGG 音频 | audio/ogg |
| MP4 视频 | video/mp4 |
| WebM 视频 | video/webm |
application/pdf |
|
| ZIP | application/zip |
| CSV | text/csv |
通过设置Content-Type头部可以使得浏览器顺利的根据文件的类型采用不同的读取方式;
以上图为例,图文件的类型为PNG类型,对应的当浏览器对服务器发起对该资源的请求时服务器返回给浏览器的该资源的响应中必须携带Content-Type: image/png头部;
对应的代码修改思路也很简单,只需要定义一个专门的以key-Value数据存储的容器对上述的参照表进行存储,当一个浏览器向服务器发起请求时对应的浏览器先在容器中搜索.(通常情况下一个文件.后跟着就是文件类型)并找到对应的文件类型,匹配容器中的各个类型并返回对应的Content-Type属性,同时服务器中也需要根据资源的类型使用对应的读取方式;
cpp
/* httpserver.hpp */
class HttpRequest
{
public:
void Parse()
{
std::stringstream ss(req_header[0]);
ss >> method >> url >> http_version;
resource_path = wwwroot;
if (url == "/" || url == "/index.html")
{
resource_path += "/";
resource_path += homepage;
}
else
resource_path += url;
// 找后缀 由后向前找
auto pos = resource_path.rfind(".");
if (pos == std::string::npos)
{
suffix = ".html";
}
else
{
suffix = resource_path.substr(pos);
}
}
public:
std::vector<std::string> req_header;
std::string text;
std::string method;
std::string url;
std::string http_version;
std::string resource_path;
std::string suffix; // 后缀
};
class HttpServer
{
public:
HttpServer(uint16_t port = defaultport) : port_(port)
{
ContentTable = {{".png", "image/png"}, {".mp4", "video/mp4"}, {".html", "text/html"}}; // 导入参照表
}
~HttpServer() {}
bool Start()
{
listensock_.Socket();
listensock_.Bind(port_);
listensock_.Listen();
for (;;)
{
std::string clientip;
uint16_t clientport;
int sockfd = listensock_.Accept(&clientip, &clientport);
pthread_t tid;
ThreadData *td = new ThreadData(sockfd, this); // 在实例化ThreadData对象时将This指针传入
pthread_create(&tid, nullptr, ThreadRun, td);
}
}
static void *ThreadRun(void *args)
{
ThreadData *td = static_cast<ThreadData *>(args);
pthread_detach(pthread_self());
td->svr_->HandlerHttp(td->sockfd_); // 改变调用方式
delete td;
return nullptr;
}
std::string SuffixToDesc(const std::string &suffix)
{
// 根据后缀参照表内容返回对应的Content-Type字段属性
return ContentTable[suffix];
}
void HandlerHttp(int sockfd) // 修改为非静态成员方法 (删除static)
{
char buffer[10240];
ssize_t n = recv(sockfd, buffer, sizeof(buffer) - 1, 0);
if (n > 0)
{
buffer[n] = 0;
HttpRequest request;
request.Deserialize(buffer);
request.Parse();
request.DebugPrint();
std::string line_feed = "\r\n";
std::string text;
bool ok = true;
text = ReadHtmlContent(request.resource_path);
if (text.empty())
{
std::string err_html = wwwroot;
err_html += "/";
err_html += "err.html";
text = ReadHtmlContent(err_html);
ok = false;
}
std::string response_line;
if (ok)
response_line = "HTTP/1.0 200 OK" + line_feed;
else
response_line = "HTTP/1.0 404 Not Found" + line_feed;
std::string response_header = "Content-Length: ";
response_header += std::to_string(text.size());
response_header += line_feed;
response_header += "Content-Type: "; // 增加Content-Type头部
response_header += SuffixToDesc(request.suffix); // 增加Content-Type属性
// 此处在进行调用时静态成员方法对应的也必须调用静态成员方法 故进行代码修改 将该函数HandlerHttp()改为非静态成员方法
response_header += line_feed; // 换行
response_header += "Location: https://www.baidu.com";
response_header += line_feed;
std::string blank_line = "\r\n";
response_header += line_feed;
std::string response = response_line + response_header + text;
send(sockfd, response.c_str(), response.size(), 0);
}
close(sockfd);
}
// 包含线程所需数据的内部类
class ThreadData
{
public:
ThreadData(int sockfd, HttpServer *svr) : sockfd_(sockfd), svr_(svr) {} // 修改ThreadData类的构造函数
public:
int sockfd_;
HttpServer *svr_; // 增加HttpServer对象指针
};
private:
uint16_t port_;
static const uint16_t defaultport;
NetSocket listensock_;
std::unordered_map<std::string, std::string> ContentTable; // 文件后缀参照表
};在这段代码修改中修改的部分较多,原因是新增的函数SuffixToDesc(const std::string &suffix)在被静态成员函数调用时也应保证自己是静态成员函数,但如果是静态成员函数就无法很好的调用到类中的ContentTable容器,故进行了较大的调整;
增加了一个unordered_map容器用于存储Content-Type字段的属性进行匹配,在类HttpRequest中增加了一个suffix成员变量用于存储识别到的请求中的类型,并且该类中的Parse函数中增加了对类型进行解析并写入suffix成员变量;
在HttpServer类中增加了成员函数SuffixToDesc(const std::string &suffix)以便于为响应中的Content-Type字段增加属性;
代码修改并编写完成后重新编译代码并运行服务器后对服务器进行访问,并使用Fiddler工具进行抓包;
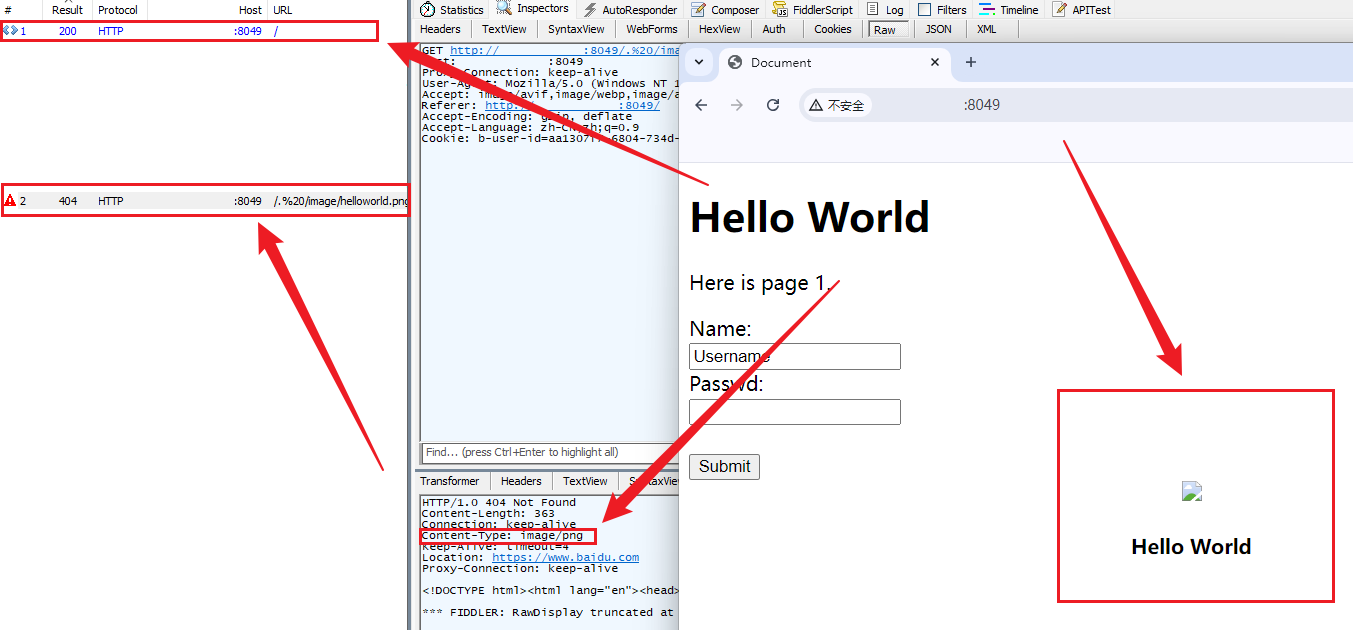
从结果来看客户端对服务器进行了两次请求申请,从请求结果来看确实Content-Type头部属性已经被返回,但是结果返回仍无法正确展示出图片,本质原因是图片的读取采用的是文本的形式进行读取,此时需要再为图片进行单独的读取方式,即二进制读取;
cpp
/* httpserver.hpp */
class HttpServer
{
public:
static std::string ReadHtmlContent(const std::string &path)
{
// 尝试以二进制模式打开文件
std::ifstream in(path, std::ios_base::binary);
// 如果文件打开失败,返回一个空字符串
if (!in.is_open())
{
return ""; // 返回空串
}
// 定义一个内容字符串,用于存储文件内容
std::string content;
// 定位到文件末尾,以便计算文件长度
in.seekg(0, std::ios_base::end);
auto len = in.tellg(); // 获取文件长度
in.seekg(0, std::ios_base::beg); // 定位回文件开头
// 调整内容字符串的大小以容纳文件内容
content.resize(len);
// 读取文件内容到字符串
in.read((char *)content.c_str(), content.size()+1);
// 关闭文件
in.close();
// 返回文件内容
return content;
}
private:
uint16_t port_; // 端口号
static const uint16_t defaultport; // 默认端口号
NetSocket listensock_; // 监听端口
std::unordered_map<std::string, std::string> ContentTable; // 文件后缀参照表
};
#endif在这段代码中主要对static std::string ReadHtmlContent(const std::string &path)函数进行了更新,即更新了读取文件的方式,采用二进制的方式对文件进行读取;
重新编译代码运行服务器并访问;
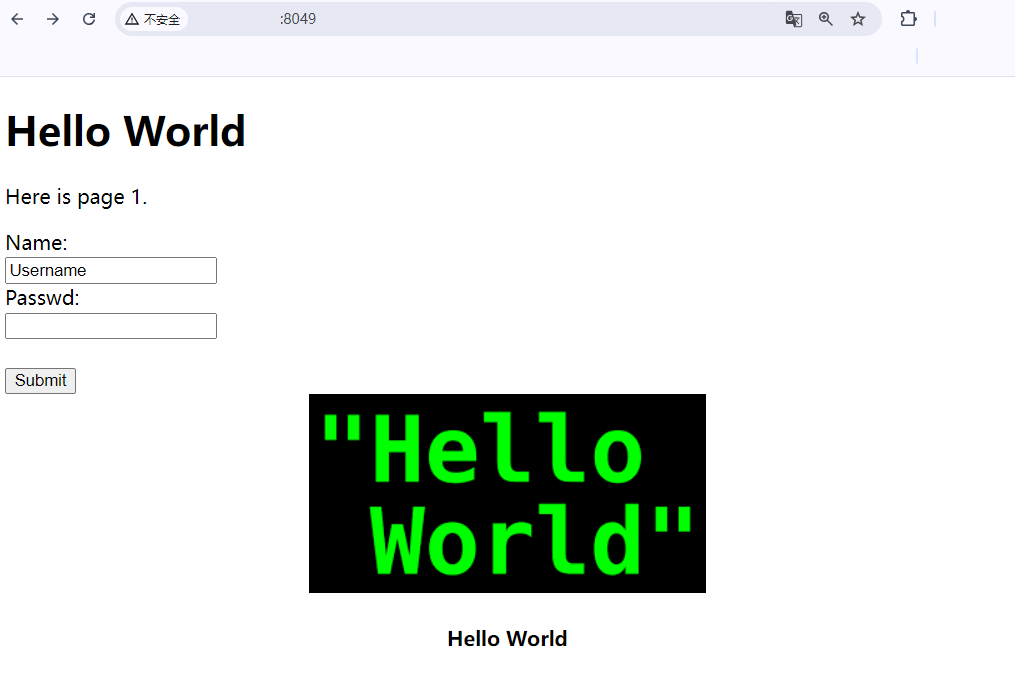
最终结果图片正常被访问;
Set-Cookie 头部
Cookie是一种用来存储用户信息的小型文本文件,通常被用来在浏览器和服务器之间传递少量的数据,常用于会话管理,个性化设置以及用户跟踪;
通常情况下Cookie是由服务器发送给客户端的,比如在进行一次登录时,用户需要进行登录账户以及身份验证等信息,这些信息以请求的方式发送给服务端(POST的方式),当服务端验证成功后将会返回一个响应,该相应中若是带有Set-Cookie头部信息,则表示服务端将这类身份验证的信息交由给了客户端,并由客户端进行存储,当用户退出登录后再次请求登录时将会直接使用Cookie从而免于身份验证等操作,这种操作相当于客户端再次向服务端发起请求时携带对应的Set-Cookie头部并携带Cookie信息,当服务端识别到对应的Cookie匹配成功后将不需要再进行身份验证等操作;
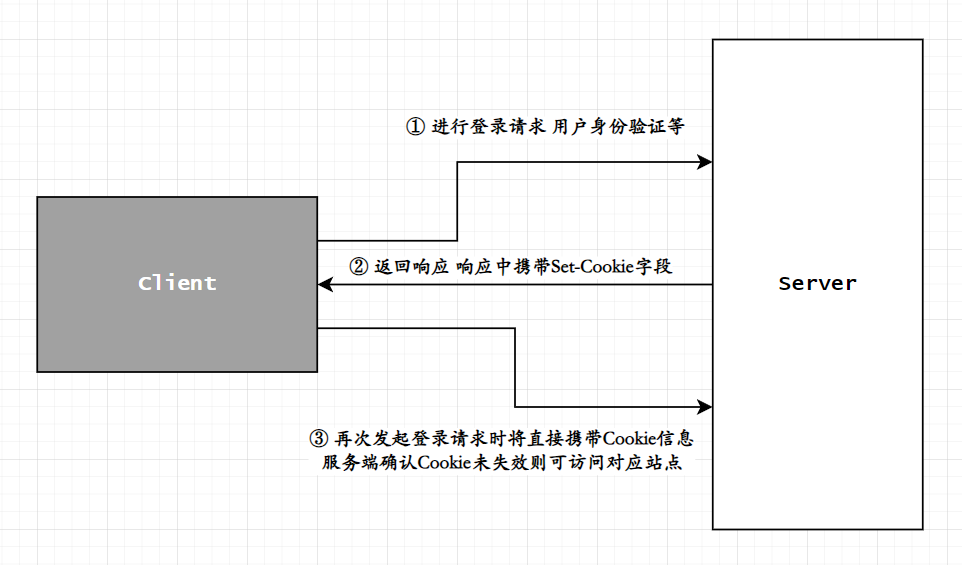
Cookie文件的保存方式分为两种,分别为文件级与内存级;
-
文件级
文件级也就是磁盘级,对应的
Cookie文件将被写入在磁盘中,直至这个Cookie文件被清理或者失效,否则Cookie仍然有效; -
内存级
内存级也是一种临时的缓存策略,通常情况下浏览器客户端存在自己的内存管理方式,这个内存管理方式包括浏览器内部的一些信息,同样的
Cookie文件也在其中,通常情况下大部分的浏览器若是将Cookie的保存方式定为内存级,那么只有当所有会话被关闭,即整个浏览器进程结束,对应的Cookie才会被清理;
将上文中的代码进行修改,在服务器的响应中添加对应的Set-Cookie头部;
cpp
class HttpServer
{
public:
void HandlerHttp(int sockfd)
{
char buffer[10240];
ssize_t n = recv(sockfd, buffer, sizeof(buffer) - 1, 0);
if (n > 0)
{
buffer[n] = 0;
HttpRequest request;
request.Deserialize(buffer);
request.Parse();
request.DebugPrint();
std::string line_feed = "\r\n";
std::string text;
bool ok = true;
text = ReadHtmlContent(request.resource_path);
if (text.empty())
{
std::string err_html = wwwroot;
err_html += "/";
err_html += "err.html";
text = ReadHtmlContent(err_html);
ok = false;
}
std::string response_line;
if (ok)
response_line = "HTTP/1.0 200 OK" + line_feed;
else
response_line = "HTTP/1.0 404 Not Found" + line_feed;
std::string response_header = "Content-Length: ";
response_header += std::to_string(text.size());
response_header += line_feed;
response_header += "Set-Cookie: "; // 添加Set-Cookie头部并设置属性
response_header += "name=helloworld";
response_header += line_feed;
response_header += "Content-Type: ";
response_header += SuffixToDesc(request.suffix);
response_header += line_feed;
response_header += "Location: https://www.baidu.com";
response_header += line_feed;
std::string blank_line = "\r\n";
response_header += line_feed;
std::string response = response_line + response_header + text;
send(sockfd, response.c_str(), response.size(), 0);
}
close(sockfd);
}
private:
uint16_t port_;
static const uint16_t defaultport;
NetSocket listensock_;
std::unordered_map<std::string, std::string> ContentTable;
};在这段代码中设置了Set-Cookie头部,重新编译并运行服务器,访问服务器;
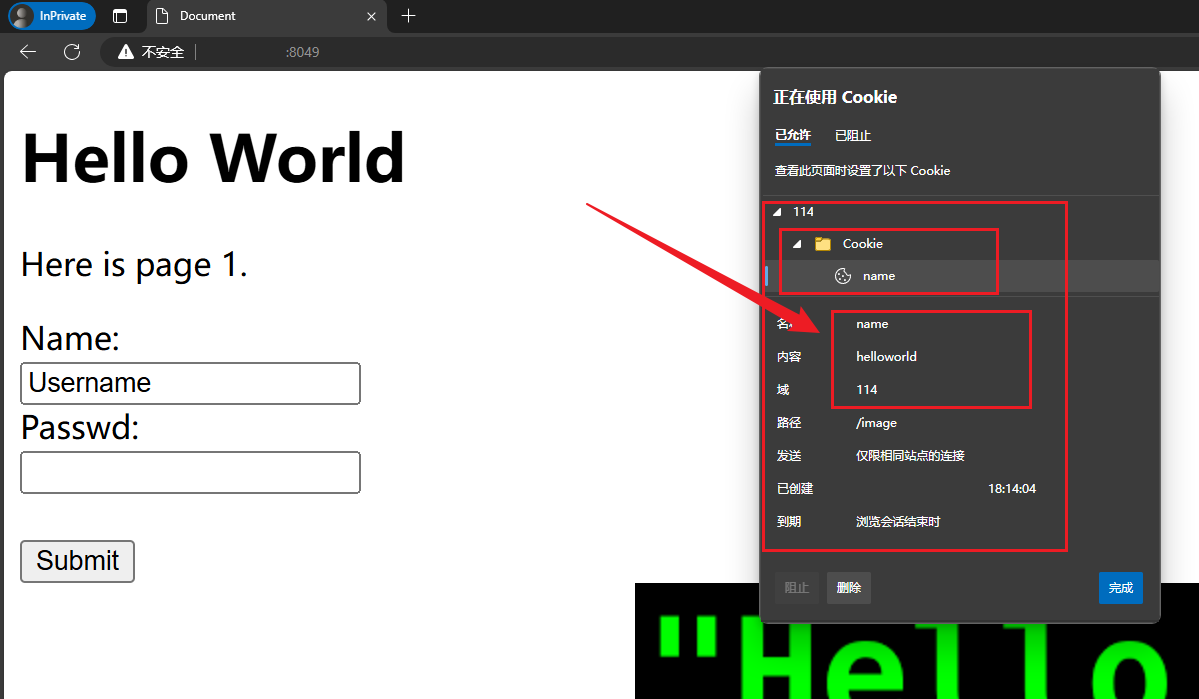
从结果来看对应的浏览器已经保存了Cookie,同时再次进行访问时对应的请求中将会直接出现Cookie报头;
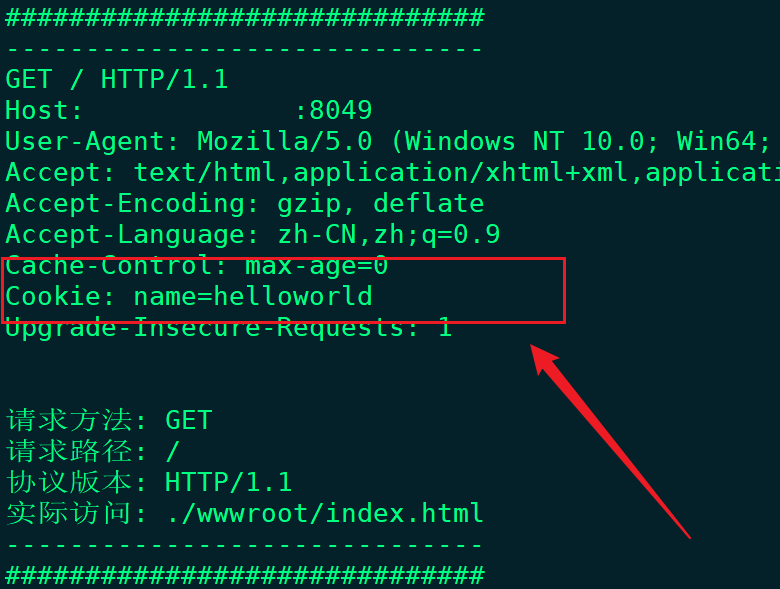
当一个响应中出现多个Set-Cookie字段时对应的多个Set-Cookie将会被整合,即出现多个该头部并不会发生错误,虽然一个Set-Cookie将会作为一个独立的cookie但是多个Set-Cookie并不会冲突;
Session ID
Session 是一种服务器端技术,用于在一个用户多次请求之间保持会话状态;它通过在服务器上存储用户数据,解决了 HTTP 协议的无状态特性;
当存在Set-Cookie报头的情况下服务端使用Session技术时 , 用户首次访问服务时,服务器先会为该用户创建一个Session,并生成一个唯一的Session ID;
服务器将会通关HTTP响应头中的Set-Cookie字段把Session ID返回给客户端,客户端对应的将其存储为Cookie;
在后续的请求中,浏览器将会自动将存储的Cookie(包含Session ID)发送给服务端,服务端将会根据Session ID查找对应的会话数据从而识别出用户;
Session数据存储在服务器端,通常在内存,文件系统或数据库当中;
Session可以在用户主动注销一段时间后自动过期;
通常情况下Session与Cookie是相互配合的,虽然Session的数据存储在服务端内,但是需要通关客户端保留的Session ID来识别用户,而这种操作通常是由Cookie实现的,同时由于Cookie只存储了一个无意义的Session ID,所有的敏感信息都保留在了服务端,从而增强了安全性;
两者结合有以下优点:
-
敏感数据保护
由于敏感数据不直接存储在客户端,而是存储在服务器端的
Session中,安全性得以提高; -
数据灵活性
Session可以存储更大,结构更复杂的数据,而不受Cookie大小的限制; -
持久性控制
通过
Session生命周期管理,服务器可以精确控制会话何时过期;