
**** NVIDIA GPGPU- 通信架构
*** *** 写在前面
在本部分,我们将深入探讨NVLink、NCCL、NVSwitch和GPGPU之间的紧密联系。重点关注通信系统及其与计算的耦合性,以揭示Nvlink & NVSwitch System在支持NVIDIA GPGPU大规模计算和超大算力方面的重要作用。为了更好地理解这些技术之间的关系,我们特地为它们单独开辟了一章进行详细分析。敬请期待!
NVIDIA GPGPU(一)总览
NVIDIA GPGPU (二)- 逐步走向通用
NVIDIA GPGPU(三)- 新时代
NVLink 之前
传统互联通路的失灵 - PCIE太慢了
PCIe 技术是PCI 技术的扩展,最初由Intel 于2001年公布,原名3GIO(第三代IO),在2002年由PCI-SIG 审核通过,改名为PCI express,此后,每一代带宽都是前一代的2倍,PCIE gen 5 每lane为32Gbps,折合为3938MB/s,gen 5 x16 即为64GB/s。2022年公布PCie gen 6 specification,每lane 带宽为64Gbps,x16 可达1Tbps 以上。
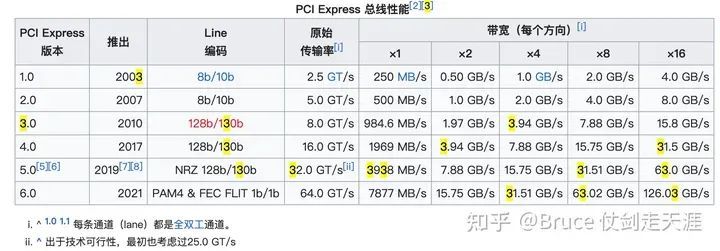
第一代Nvlink诞生于Pascal时代,即2016年Pcie 3.0时期。当时,Gen3 x16的带宽仅为128Gbps,相当于16GB/s。然而,这种带宽仅能供所有设备共享,显然无法满足一机8卡GPU高性能计算的需求。若将带宽独占给GPU,并实现8卡均衡分配,每卡带宽仅16Gbps(2GB/s)。此外,网卡本身也是一个PCIe带宽消费者,再加上带宽竞争,实际可用带宽更加有限。
P100的32位浮点计算能力为10.6TFLOPS,如果每个浮点都是GPU外搬运而来且完全不复用旧数据,则需要10.6 * 10 ^ 3 * 32 Gbps的带宽,40000 GB/s。不过显然每卡2GB/s的带宽能力,相差20000倍,约等于用户基于1B 及其结果原地计算20000次,要求用户达到这么高的数据复用是不太现实的。
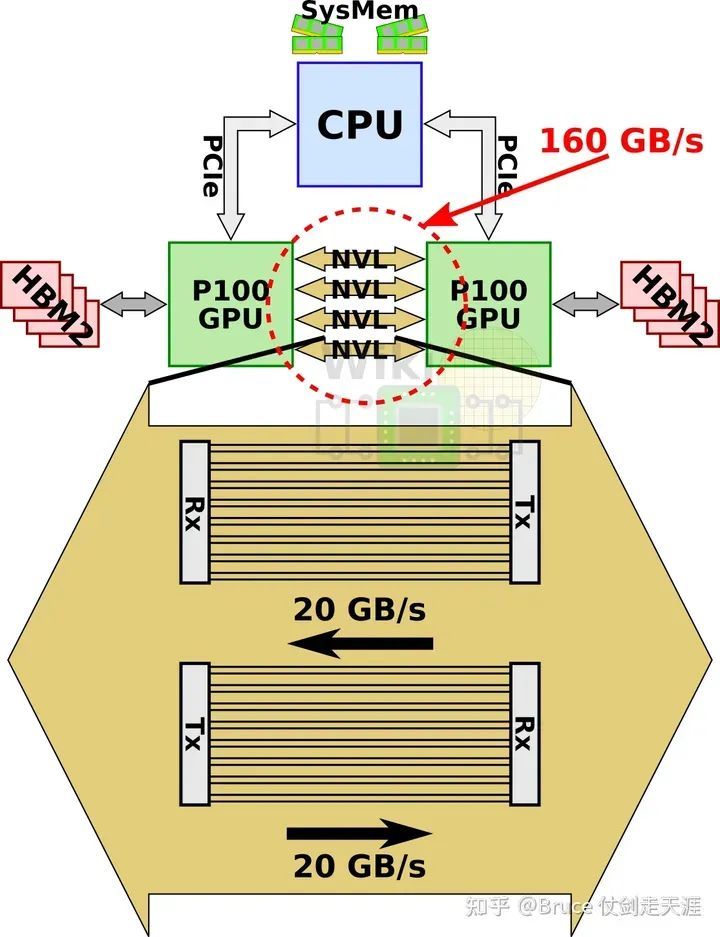
NVIDIA P100采用了自研高速互联协议NVLink v4,可以提供高达900GB/s的带宽。
我们查看白皮书,P100的32位浮点计算能力为10.6TFLOPS,也就是说每秒执行10.6 * 10^12 次32位浮点计算,如果每个浮点都是GPU外搬运而来且完全不复用旧数据,则需要10.6 * 10 ^ 3 * 32 Gbps的带宽,40000 GB/s,当然实际上不会如此,数据会有一定程度的复用,这和业务相关。不过显然每卡2GB/s的带宽能力,相差20000倍,约等于用户基于1B 及其结果原地计算20000次,要求用户达到这么高的数据复用是不太现实的。
我们比较一下,2016年推出的nvlink v1 实现了多大的带宽呢?
每GPU 有4个nvlink,每个link 单向20GB/s,每卡双向总带宽达160GB/s,这就显然比Pcie 3 x16 提升了2个数量级的带宽,对用户数据复用的要求也大大降低了。
RDMA 网络的介入 - IB/Mellanox products家族
除去传统的PCIE 通路外,CPU 和 传统的TCP 通路也逐渐显现出GPU 训练的带宽窘境,这比Pcie 带宽出现的更早,在2012年,NVIDIA 在kepler 上就推出了GPUdirect的能力,希望数据传输上bypass CPU,且特别指出了RDMA 的使用是对于GPUDirect 的高性能的保证,后来该能力更多被直接称为GPUDirectRDMA,简称GDR。GDR 至今已经10年了,10年前GPU 高性能领域就已经开始慢慢淘汰TCP,而逐步使用RDMA NIC 作为高性能数据计算的基础网卡。
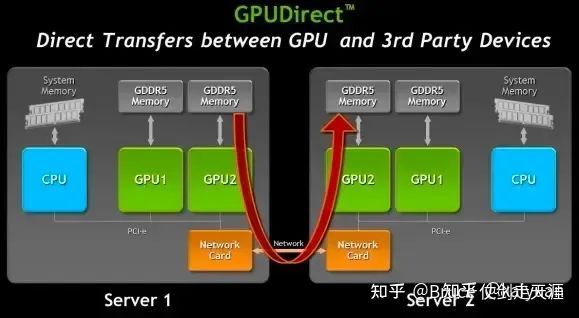
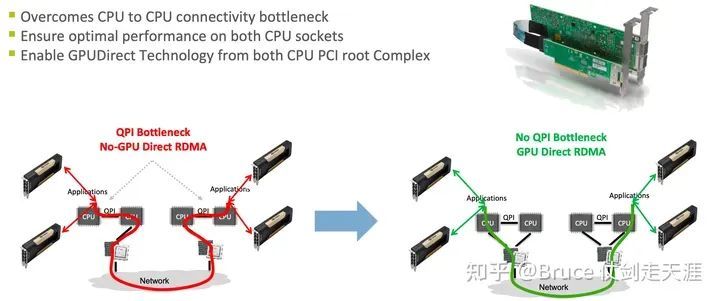
Amphere支持Mellanox NIC和相关产品,NVIDIA收购Mellanox,GDR带宽都在稳步发展,rdma网络带宽能力逐步从10Gbps发展到如今CX 7的400Gbps。IB规格的历史可以简单看一下。
此外,NVIDIA于2019年3月11日宣布计划以每股125美元(合69亿美元)的现金价格收购总部位于以色列的Mellanox。该交易将NVIDIA领先的计算专业技术与Mellanox的高性能互连技术相结合。
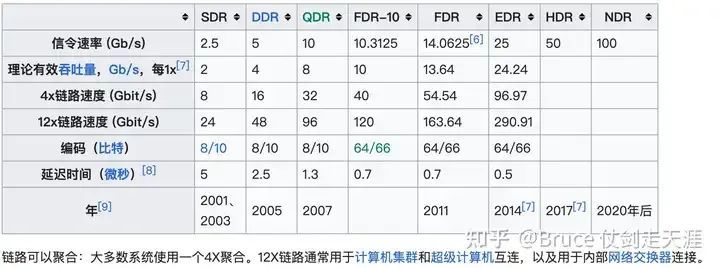
虽然2012年的rdma 还是10Gbps的时代,但已经占据了超级计算机互联的绝大部分,至2009年,世界500强超级计算机中,259个使用千兆以太网作为内部互连技术,181个使用InfiniBand。同期的TCP 带宽暂未找到相关数据。
随着cable 性能的提高,rdma/ib 带宽一路高歌猛进,至今CX7 为NDR * 4 = 400Gbps。而2016年,mellanox 率先提出了在网计算协议SHARP,在自研交换机上率先实现了aggregation reduction,也就是交换机实现reduce 计算,简化网络包数的技术。
至2020年,Nvidia 收购 mellanox,sharp v2 已经在mellanox 交换机上实现,至今已实现sharpv3且在quantum 中使用,而NCCL 开始支持sharp 的时间是2019年。具体sharp 的原理与收益我们会在之后的章节说明。
NV-SLI /SLI bridge
在提nvlink 之前,我们还需要了解SLI。一种早期的scaleble interface,SLI 用于早期多显卡互联,SLI 互联的GPU,可以共享存储和计算任务,SLI 互联的桥接部件称为SLI Bridge,简图如下。也是从SLI 为起点,诞生出的nvlink,后来的nvlink 可以认为是SLI的升级版本。至今,NVLINK 在Turing 也重新支持了SLI,但是性能相对低(支持路数较少),之后的nvlink 也不再提到SLI的场景,因此怀疑可能和向前兼容有关。
高速互联设备 - NVLink & NVSwitch
NVLINK
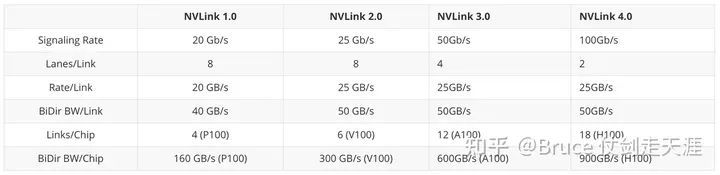
Nvlink,自Pascal架构诞生以来,已发展至第四代。每lane的带宽及每个link的带宽持续提升,呈现出更强的性能表现。
V 1
主要特性
NVLink 1.0是为GPU-GPU、GPU-CPU高速互连的接口,支持直接读写对端CPU/GPU的内存(所有内存都在共享地址空间里)。主要特性:
1.每个link双向接口,每个方向由8 lane组成,单lane最高速率20Gbps,单link 单向带宽为20Gbps x8 = 20GBps,双向带宽40GBps。
2.单GPU(P100)支持4NVLink,双向带宽一共160GBps
3.提供load/store语义,让用户能对peer GPU内存进行read/writes操作,另外还支持atomics 操作
4.NVLink 1.0是一种基于包的协议,包长在一定范围可变
5.不支持多队列,仅支持多VC(virtual channel)
6.Flow control:在请求包里带flow control credit
7.通过CRC检测数据错误
8.Replay: 类似Go-back-N重传
9.仅支持和部分CPU(IBM Power系列)互连。
协议
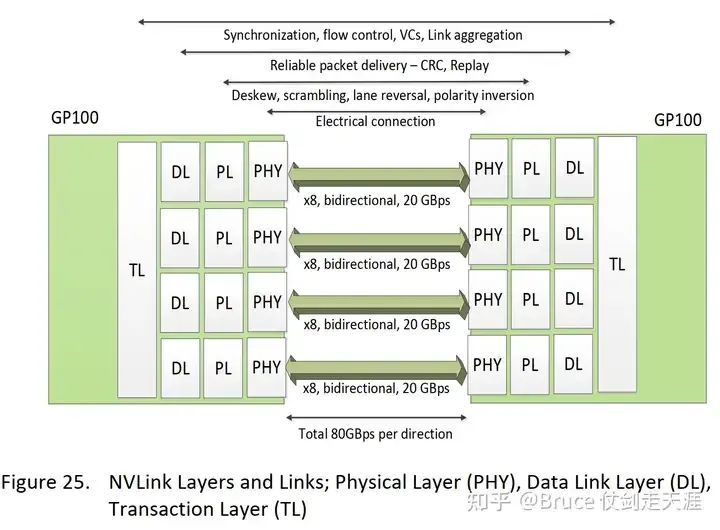
NVLink 1.0是一种高速串行通信协议,类似于PCIe。它分为三个层次:Physical Layer、Data Link Layer和Transaction Layer。Physical Layer负责PHY的连接,如deskew、framing、(de)scrambling、polarity inversion和lane reversal等;Data Link Layer负责可靠性传输,通过CRC/ACK等实现;Transaction Layer从Data Link Layer接收TLP,配置空间确定TLP格式是否正确,并根据流量级(TC)管理数据包。
1.Physical Layer: 接PHY,负责deskew、framing、(de)scrambling、polarity inversion和lane reversal等
2.Data Link Layer: 负责可靠性传输,通过CRC/ACK等实现
3.Transaction Layer: 负责synchronization, link flow control, virtual channels, 并能将多个nvlink汇聚到一起
包格式
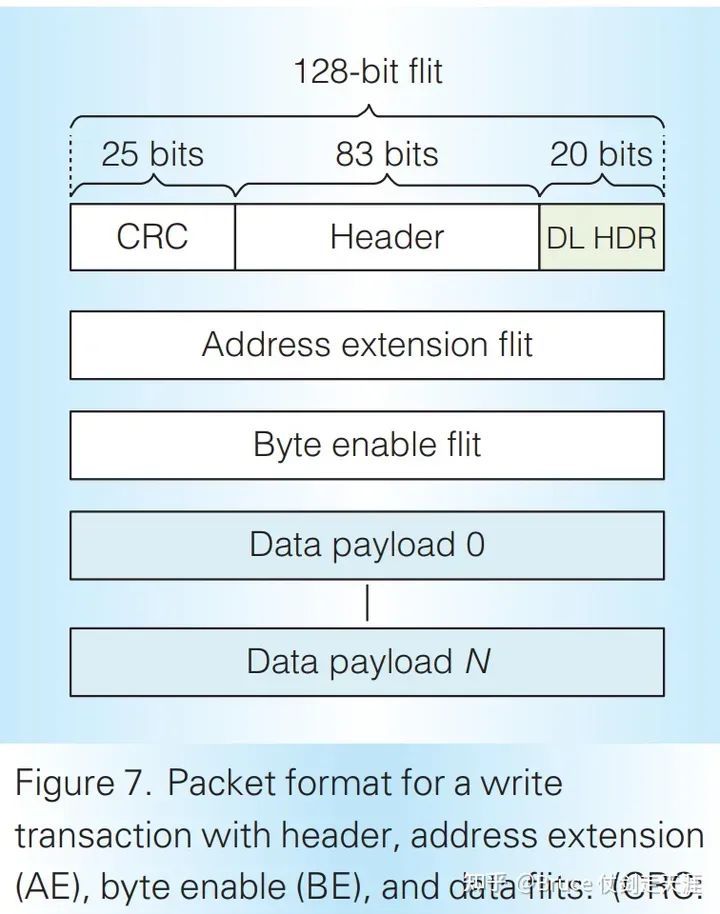
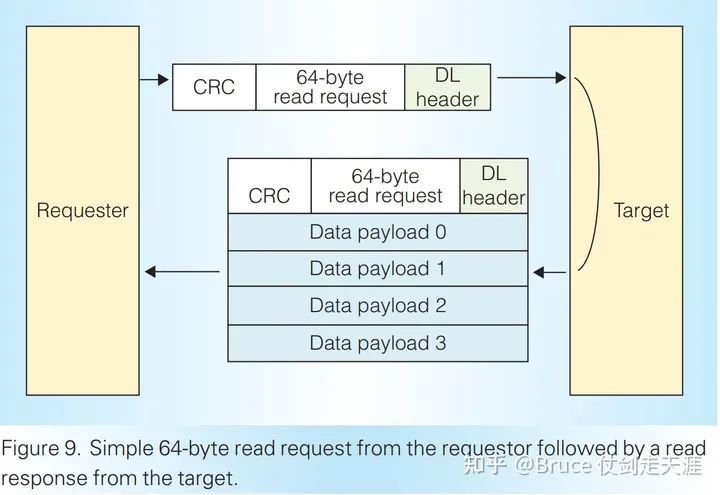
NVLink 1.0的数据包格式如图:
每次交易至少包括一个请求和一个响应(不包括发布操作)。以128位为基本单位(称为flit),单个数据包可以包含1-18个flit,每个数据包可能包含0-16个数据flit,最多传输256B的数据。包头包含三个部分:
- CRC:校验前前包的header和上一个包的payload
- Header:包含请求类型(request type)、地址(address)、流量控制积分(flow control credits)和标签标识符(tag identifier)。
- DL Header:包含确认标识符(acknowledge identifier)、数据包长度信息(packet length information)和应用编号标签(application number tag)。
AE(可选):传输特定命令信息或修改命令默认值,仅在发生变化时传输。BE(可选):编写和原子指定需写入的字节,类似于掩码。
CRC和重传机制
当CRC校验成功时,会收到positive ack;若校验失败,则不回复ack。请求侧的数据会被缓存在replay buffer中。如果请求侧收到正确的ack sequence,那么packet将从replay buffer中删除。但如果遇到错误的ack Sequence或timeout,就需要回退到上一个Acked的包,并从relpay buffer进行重传,即go back N。
和其它模块的接口
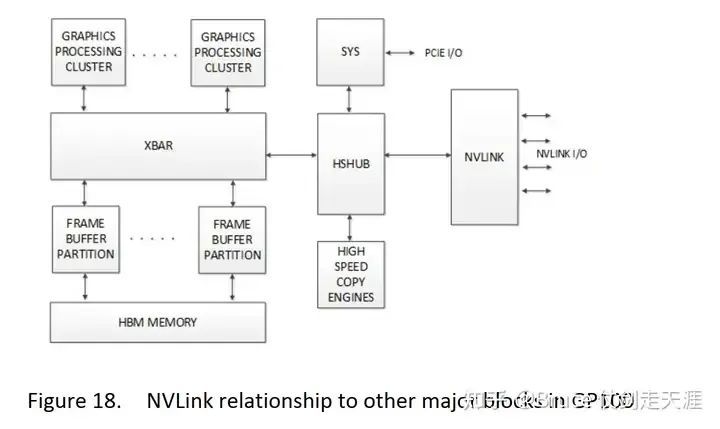
NVLink通过高速互连模块(如HSHub)与其他组件相连,其中HSHub与GPU的Crossbar、高速拷贝引擎(High Speed Copy Engine)以及PCIe等接口相连接。值得注意的是,拷贝引擎可选择性地使用PCIe或NVLink进行数据传输。
基本拓扑构型
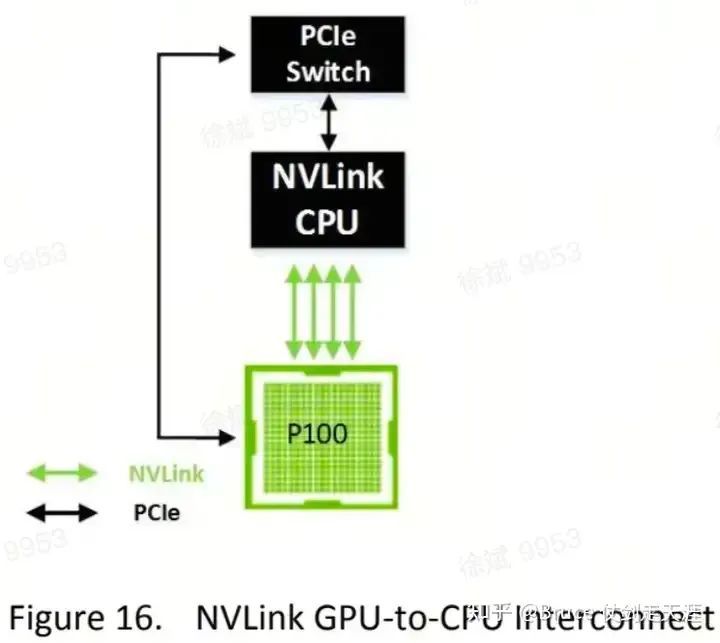
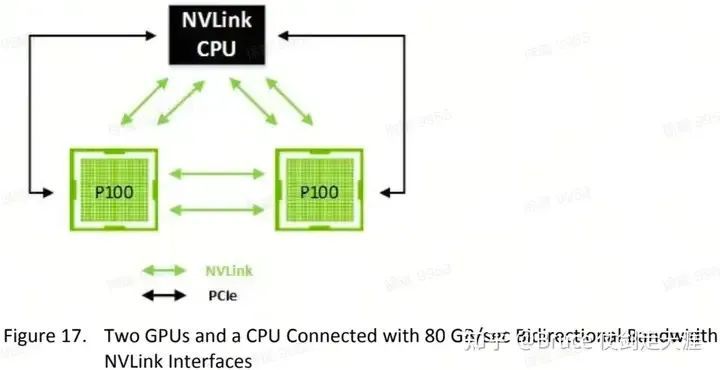
V2
与基于Volta推出,主要载体是V100,与1.0版本相比,主要区别在于:
您好,NVLink2.0是NVIDIA开发的一项用于GPU之间点对点高速互联的技术。它将GPU带宽提升到了300G/s(六通道),都快是PCIe 3.0 ×16的10倍。此外,NVLink2.0还支持low-power operation mode,CPU方向相关:Cache一致性增强,支持CPU通过nvlink读取数据到cache,并支持了更加完善的GPU-CPU atomic;支持ATS。
注意,新一代超级计算机在CPU侧有显著提升,主要集中在堆规格增强。然而,值得关注的是,NVIDIA推出了全新的nvswitch 1.0。
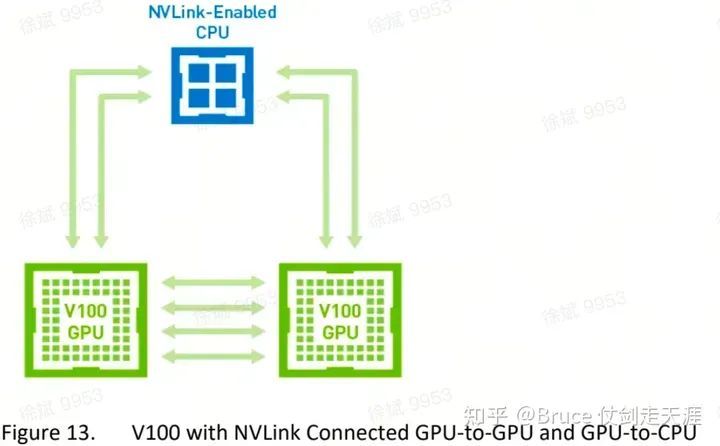
V3
NVLink 3.0 的新特性包括:支持双向数据传输,每个方向都有高达 32GB/s 的带宽,这意味着两个 GPU 之间可以实现总共高达 64GB/s 的带宽。此外,NVLink 支持多通道通信,允许同时进行多个数据传输会话。它还支持 CUDA 核心直接访问显存,使得 GPU 可以更高效地处理数据。
- 更高的带宽、信号线数减半、单GPU 12个nvlink
- 升级error detection和recovery。
- Write操作变成non-posted,使得请求侧可以进行同步,错误处理也有改进
V4
基于hopper,NVLink 4.0特性:
单个NVLink仅需2个lane,即可实现单向25GBps传输速度。单个GPU支持18个NVLink,总带宽高达900GBps,较上一代提升1.5倍。为满足跨多个节点集群需求,全新NVLink Network应运而生。
- 优化后的文章:H100 GPU引入网络地址空间,实现GPU地址空间隔离,不再共享地址空间,提高安全性。
- NVLink 4.0和IB一样,user software需要先建立连接。
NVSwitch
Nvswitch 自从volta 架构提出以来,至今已到第三代。
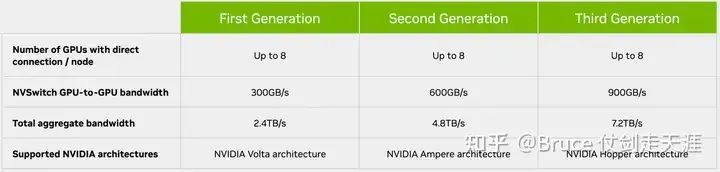
V1
NvSwitch,一款独立的NVLink芯片,以其卓越的性能和高效的数据传输能力引领着科技潮流。这款芯片拥有18路NVLink接口,支持最新的NVLink 2.0协议,每个接口都能够提供高达50GB/s的双信道带宽,总带宽更是惊人的900GB/s。
尽管功率达到100W,但得益于台积电12nm FinFet FFN Nvidia定制工艺以及源自增强的16nm节点的晶体管数量,NvSwitch仍然保持了低功耗的优势。这款芯片的出现,无疑为我们的生活带来了无限的可能性和便捷性。

一款die封装在1940个pin、大小为4cm2的BGA芯片中。其中,576个针脚专为18路nvlink服务,剩余针脚则用于电源和其他I/O接口,如x4 pcie、I2c、GPIO等管理端口。

借助NVSwitch的18路接口,NVIDIA成功打造出无阻塞的全互联16路GPU系统。每块V100中的6路NVLink分别连接到6块NVSwitch,共同组成一个基板,实现高效协同计算。
V2
每个switch 18link。
V3
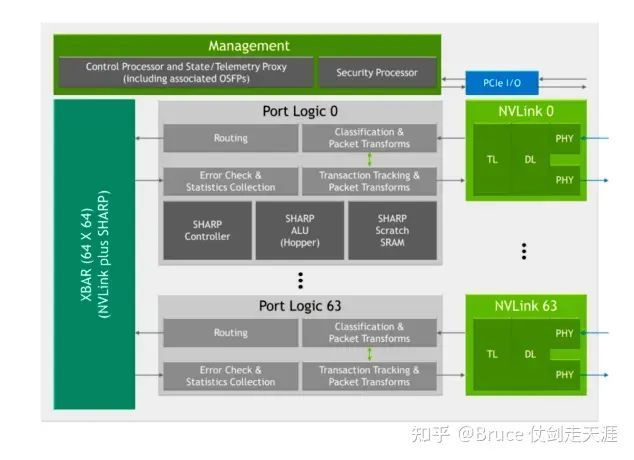
NVSwitch 3.0特性:
1.单芯片,64 port,12.8Tbps
2.可以在node内和node外放置
3.实现了collective operation的硬件加速,包括multicast和SHARP,加速了了allreduce,reduce_scatter
4.2跳交换,L1 Nvswitch 与 GPU 相连接口为nvlink,与L2 交换机连接为osfp。
5.每个nvswitch 芯片包含64个nvlink,每四个nvlink 组成一个osfp,故有16个osfp
NCCL 软件栈浅说
NCCL确实相当复杂,不过我推荐你查看oneflow的NCCL专栏以获取更深入的理解。
oneflow 的解析写得十分详细(抱拳),我这里仅做一点自己读源码的总结。
基本例子
简单的集合通信例子
int main(int argc, char* argv\[\])
{
int size = 32*1024*1024;
int myRank, nRanks, localRank = 0;
//initializing MPI
MPICHECK(MPI_Init(&argc, &argv));
MPICHECK(MPI_Comm_rank(MPI_COMM_WORLD, &myRank));
MPICHECK(MPI_Comm_size(MPI_COMM_WORLD, &nRanks));
//calculating localRank which is used in selecting a GPU
uint64_t hostHashsnRanks;
char hostname1024;
getHostName(hostname, 1024);
hostHashsmyRank = getHostHash(hostname);
MPICHECK(MPI_Allgather(MPI_IN_PLACE, 0, MPI_DATATYPE_NULL, hostHashs, sizeof(uint64_t), MPI_BYTE, MPI_COMM_WORLD));
for (int p=0; p<nRanks; p++) {
if (p == myRank) break;
if (hostHashsp == hostHashsmyRank) localRank++;
}
//each process is using two GPUs
int nDev = 2;
float** sendbuff = (float**)malloc(nDev * sizeof(float*));
float** recvbuff = (float**)malloc(nDev * sizeof(float*));
cudaStream_t* s = (cudaStream_t*)malloc(sizeof(cudaStream_t)*nDev);
//picking GPUs based on localRank
for (int i = 0; i < nDev; ++i) {
CUDACHECK(cudaSetDevice(localRank*nDev + i));
CUDACHECK(cudaMalloc(sendbuff + i, size * sizeof(float)));
CUDACHECK(cudaMalloc(recvbuff + i, size * sizeof(float)));
CUDACHECK(cudaMemset(sendbuffi, 1, size * sizeof(float)));
CUDACHECK(cudaMemset(recvbuffi, 0, size * sizeof(float)));
CUDACHECK(cudaStreamCreate(s+i));
}
ncclUniqueId id;
ncclComm_t commsnDev;
//generating NCCL unique ID at one process and broadcasting it to all
if (myRank == 0) ncclGetUniqueId(&id);
MPICHECK(MPI_Bcast((void *)&id, sizeof(id), MPI_BYTE, 0, MPI_COMM_WORLD));
//initializing NCCL, group API is required around ncclCommInitRank as it is
//called across multiple GPUs in each thread/process
NCCLCHECK(ncclGroupStart());
for (int i=0; i<nDev; i++) {
CUDACHECK(cudaSetDevice(localRank*nDev + i));
NCCLCHECK(ncclCommInitRank(comms+i, nRanks*nDev, id, myRank*nDev + i));
}
NCCLCHECK(ncclGroupEnd());
//calling NCCL communication API. Group API is required when using
//multiple devices per thread/process
NCCLCHECK(ncclGroupStart());
for (int i=0; i<nDev; i++)
NCCLCHECK(ncclAllReduce((const void*)sendbuffi, (void*)recvbuffi, size, ncclFloat, ncclSum,
commsi, si));
NCCLCHECK(ncclGroupEnd());
//synchronizing on CUDA stream to complete NCCL communication
for (int i=0; i<nDev; i++)
CUDACHECK(cudaStreamSynchronize(si));
//freeing device memory
for (int i=0; i<nDev; i++) {
CUDACHECK(cudaFree(sendbuffi));
CUDACHECK(cudaFree(recvbuffi));
}
//finalizing NCCL
for (int i=0; i<nDev; i++) {
ncclCommDestroy(commsi);
}
//finalizing MPI
MPICHECK(MPI_Finalize());
printf("MPI Rank %d Success \n", myRank);
return 0;
}
这个例子里比较核心的部分在于:
创建一个通信器Communicator作为首要任务,明确MPI进程之间的拓扑关系并设置Rank。接下来,通过setdevice操作将Rank与设备绑定。最后,以Group的方式提交collective communication任务,并进行异步完成通知。
这个例子还没有覆盖的地方在于对初始化过程没有涉及:
-
如何发现GPU和NVLink:通过NVIDIA System Management Interface (nvidia-smi) 命令查看GPU设备及其相关信息。
-
如何初始化GPU和NVLink、NVSwitch:在程序中使用相应的API进行初始化,如CUDA Runtime API或驱动程序API。
-
如何构建GPU之间的可通信拓扑:使用CUDA的内置函数或者第三方库,如cuDNN等,构建可达的GPU网络。
-
如何根据通信任务选择NVLink数量:根据任务数据量、通信速率等因素综合考虑,合理分配NVLink资源。
-
如何下发通信任务到硬件:通过CUDA Runtime API中的cudaMemcpyAsync()函数将数据发送到目标GPU设备。
-
计算任务和通信任务是否关联:通常情况下,计算任务和通信任务是独立的,但在某些场景下(如深度学习训练),它们可能存在一定的依赖关系。
"探索通信任务相关问题,FM一章解析initilaize与异常现象。专业精简,吸引力十足,仅54字。"
资源准备
建立拓扑
在获取唯一ID的过程中,首先需要探索当前机器上所有可通信设备,如网络接口卡(NIC)、处理器性能接口(QPI)、PCI扩展总线(RC、PCIe交换机)、nvlink(GPU、nvswitch)等。根据各设备的激活状态,构建一张可通信图。此时,通信图已明确了两个关键信息:设备节点数量和路径数量,同时完成了可达性确认任务。
拓扑计算
这一部分,在commRankInit 也会做。
第二步,为第一步发现的通信图,寻找一条各node 之间传输的最佳path,以带宽最大为基准。此处完成路径规划。
这里只是准备好可用的path,并不是真正通信就会占用这些数量的path/link,真正的通信是考虑利用率的,单任务占满带宽只会降低利用率,所以取得负载和所占path的平衡就是真正通信的关键。
CommRankInit
有了全局图,准备工作好了,怎么和具体任务挂钩呢?
Communicator 确定一个通信任务的覆盖范畴,也就是我这个通信任务包含哪些进程。
而我们之前提到,分布式通信topo是有结构的,或者是有序的,并不是无序而各点同质的,于是每个进程明确自己的rank,而对于使用GPU加速的进程,rank需要关联到具体GPU的ID。
所以当我们调用CommRankInit时,我们做了什么?将commID与rankId 配置给GPU。这样GPU用link发起通信时,也可以明白自己通信的范围,使用组播而不是广播方式增加不必要的带宽占用。
NCCL_API(ncclResult_t, ncclCommInitRank, ncclComm_t* newcomm, int nranks, ncclUniqueId commId, int myrank);
ncclResult_t ncclCommInitRank(ncclComm_t* newcomm, int nranks, ncclUniqueId commId, int myrank) {
// Load the CUDA driver and dlsym hooks (can fail on old drivers)
(void)ncclCudaLibraryInit();
int cudaDev;
ncclConfig_t config = NCCL_CONFIG_INITIALIZER;
CUDACHECK(cudaGetDevice(&cudaDev));
NvtxParamsCommInitRank payload{myrank, nranks, cudaDev};
NVTX3_FUNC_WITH_PARAMS(CommInitRank, CommInitRankSchema, payload)
NCCLCHECK(ncclCommInitRankDev(newcomm, nranks, commId, myrank, cudaDev, &config));
return ncclSuccess;
}
最终这个CommInitRankDev也会作为一个async job 下给硬件(cudalaunch)的方式,完成配置。
问题来了,commid 和nranks是外部传入的参数,那么到底如何计算出来的呢?
id 的计算本身也是个问题,是在上层构建通信环的过程中所得。
CommInitRank 解决了逻辑上rank 和comm 对应的device,构建了comm的stream对象,所以nccl 每个communication有自己的stream。
有兴趣的同学可以自己追一下代码:
CommInitRankDev -> CommInitRankFunc -> CommAlloc -> ncclStrongStreamConstruct -> cudaStreamCreateWithFlags, cudaEventCreateWithFlags。
ComputeChannel
需要计算通信任务需要占用的link数量。具体占用带宽的计算略去不表,总体上看,通信任务本身最后也是cudaLaunchKernel,所以和一般cuda 任务一样,需要明确grid和block,channel 和 thread的选择最终就挂钩在grid和block上。从目前代码的主体逻辑看,channel 计算有几个特点:
-
channel 的数量必须是2的幂次方。
-
每个线程块内的channel数应该相同。
-
每个线程块内的线程数应该相同。
1.对于每个thread 可用传递的数据量有一个参考值,根据这个参考值明确当前任务需要多少thread
2.Channel 是 thread 上一层之概念,其实也就对应grid和block的关系
3.通信任务计算的过程,是寻找可以达到最优带宽的最少channel和thread 数量,先减少channel,当channel 为1,再减少threads,threads的计算单位是warp
4.除去负责主要通信任务的threads,还有用于管理和同步的warps(不同通信算法需要的管理warp数量不一,ring为1,tree为2)
最终计算出来的channel 数量,每一个channel 会有独立的launchkernel,一个channel 对应一个grid,channel 内的thread数量最后根据block的规格,计算block。每一个launch 对应一个plan,这个plan 里就是任务需要资源的相关信息,launch 本身就是提交plan。
另外,结合例子理解,所有的任务都可以被group 粒度去调度,也就是不是每一次 用户提交任务就立即下达至GPU,而是一个group 结束后异步下达至GPU的,group 调度粒度取决于配置和用户编程的调用。
enqueue调用流程
NCCL_API(ncclResult_t, ncclReduce, const void* sendbuff, void* recvbuff, size_t count,
ncclDataType_t datatype, ncclRedOp_t op, int root, ncclComm_t comm, cudaStream_t stream);
ncclResult_t ncclReduce(const void* sendbuff, void* recvbuff, size_t count,
ncclDataType_t datatype, ncclRedOp_t op, int root, ncclComm_t comm, cudaStream_t stream) {
struct NvtxParamsReduce {
size_t bytes;
int root;
ncclRedOp_t op;
};
constexpr nvtxPayloadSchemaEntry_t ReduceSchema\[\] = {
{0, NVTX_PAYLOAD_ENTRY_TYPE_SIZE, "Message size bytes"},
{0, NVTX_PAYLOAD_ENTRY_TYPE_INT, "Root", nullptr, 0, offsetof(NvtxParamsReduce, root)},
{0, NVTX_PAYLOAD_ENTRY_NCCL_REDOP, "Reduction operation", nullptr, 0,
offsetof(NvtxParamsReduce, op)}
};
NvtxParamsReduce payload{count * ncclTypeSize(datatype), root, op};
NVTX3_FUNC_WITH_PARAMS(Reduce, ReduceSchema, payload)
struct ncclInfo info = { ncclFuncReduce, "Reduce",
sendbuff, recvbuff, count, datatype, op, root, comm, stream, /* Args */
REDUCE_CHUNKSTEPS, REDUCE_SLICESTEPS };
return ncclEnqueueCheck(&info);
}
前面的代码主要是参数设置,核心在于ncclEnqueueCheck。其基本逻辑如下:
主机通过异步提交任务(包括通信命令),经过排队和组调度,利用cudalaunchkernel发送至GPU。在GPU内部,MCU执行device code。因此,GPGPU的NVLink实际收发逻辑确实在设备侧。
通信原语(如reduce、gather、allreduce、scatter)具有各自独特的通信接口,但底层机制保持一致。
通信类型(如P2P、集体)各异,对应不同队列。每个通信都成为队列任务,而每个任务会被NCCL编排成一个计划,其中包括通信所需的资源(如通道/网格数量、线程数量/ warp对齐)。
stream 机制
Stream 介绍过,作为host侧提交kernel 任务的组织单位。
Communication 自身的stream
if (parent == NULL || !parent->config.splitShare) {
struct ncclSharedResources* sharedRes = NULL;
NCCLCHECK(ncclCalloc(&sharedRes, 1));
/* most of attributes are assigned later in initTransportsRank(). */
sharedRes->owner = comm;
sharedRes->tpNRanks = comm->nRanks;
NCCLCHECK(ncclCalloc(&sharedRes->tpRankToLocalRank, comm->nRanks));
NCCLCHECK(ncclStrongStreamConstruct(&sharedRes->deviceStream));
NCCLCHECK(ncclStrongStreamConstruct(&sharedRes->hostStream));
comm->sharedRes = sharedRes;
sharedRes->refCount = 1;
} else {
comm->sharedRes = parent->sharedRes;
ncclAtomicRefCountIncrement(&parent->sharedRes->refCount);
}
"Host Stream与Device Stream是该通信协议的两大支柱,分别对应着NVLink部分和Proxy部分的核心内核代码。两者共同构建了高效的数据传输网络,确保了设备间的稳定、快速且安全的连接。"
任务的stream
我们看看ncclreduce的接口,看看info的传参吧。
NCCL_API(ncclResult_t, ncclReduce, const void* sendbuff, void* recvbuff, size_t count,
ncclDataType_t datatype, ncclRedOp_t op, int root, ncclComm_t comm, cudaStream_t stream) 是一个用于数据并行归约的函数。它接收以下参数:
-
sendbuff:发送缓冲区指针,指向要归约的数据。
-
recvbuff:接收缓冲区指针,指向存储归约结果的位置。
-
count:要归约的数据元素数量。
-
datatype:数据的类型,如float、int等。
-
op:归约操作类型,如SUM、PROD等。
-
root:指定根节点的索引。
-
comm:通信句柄,用于在多个GPU之间进行通信。
-
stream:CUDA流,用于异步执行计算任务。
该函数通过使用NCCL库提供的高效通信和同步机制,实现了在多个GPU之间的快速数据并行归约。
明明每一个communicator 本身就是拥有两个stream,为什么外部还需要传入一个stream呢?这个stream 是未知的,换句话说,极有可能是task所在的stream。
这里涉及到之前提到的cuda graph的能力。cuda graph 允许不同stream 之间协同工作。
Ncclreduce 一路调用,在taskappend,进行任务判断,会判断是否当前comm->task的stream和info->stream 一致,如果一致,说明本来就在一个stream里,如果不一致或者task为空,则comm->task 赋值为info stream。另一个值的注意的点是,假如一个comm 上执行了多次task,那么这些task 所在的stream 会维护一个list,目前看这个list是fifo的。
if (info->stream != tasks->streamRecent || tasks->streams == nullptr) {
tasks->streamRecent = info->stream;
struct ncclCudaStreamList* l = tasks->streams;
while (true) {
if (l == nullptr) { // Got to the end, this must be a new stream.
struct ncclCudaGraph graph;
NCCLCHECK(ncclCudaGetCapturingGraph(&graph, info->stream))
if (tasks->streams != nullptr && !ncclCudaGraphSame(tasks->capturingGraph, graph)) {
WARN("Streams given to a communicator within a NCCL group must either be all uncaptured or all captured by the same graph.");
return ncclInvalidUsage;
}
tasks->capturingGraph = graph; // C++ struct assignment
// Add stream to list
l = ncclMemoryStackAlloc<struct ncclCudaStreamList>(&comm->memScoped);
l->stream = info->stream;
l->next = tasks->streams;
tasks->streams = l;
break;
}
if (l->stream == info->stream)
break; // Already seen stream.
l = l->next;
}
}
Launch 时的stream 关系
Info Stream和Comm的Stream之间的关系是什么?请看下面的解释:
User Stream【0】是第一个用户任务的Stream,而Host和Device的Stream则是Comm的Stream。
// Semantically we want these dependencies for the kernels launched:
// 1. Launch host task on hostStream.
// 2. Launch kernel, depends on all of {deviceStream, hostStream, userStreami...}
// 3. {deviceStream, userStreami...} depend on kernel.
// We achieve this by:
// 1. userStream0 waits on deviceStream
// 2. deviceStream waits on each of userStream1...
// 3. host task launch on hostStream
// 4. userStream0 waits on hostStream
// 5. kernel launch on userStream0
// 6. deviceStream waits on userStream0
// 7. userStream1... each waits on deviceStream
// The two-level fan-in fan-out is because ncclStrongStreamWaitStream() requires
// at least one of the two streams to be strong-stream.
在启动内核之前,我们会尝试获取通信流(comm stream),其宿主(host)或设备(device)取决于任务类型。然而,值得注意的是,任务流(task stream)和通信流(comm stream)之间存在相互依赖关系,并明确了它们之间的等待关系。
NVLink 使用的是设备流(devicestream),而 RDMA 和 TCP 则使用的是主机流(hoststream)。
计算通信之关系
在CUDA编程中,细心的开发者可能会在Stream的逻辑中发现CUDA Graph的踪迹。我们知道,CUDA Graph是一种强大的并行计算工具,能够有效协同处理多个Stream。那么,这部分Graph是否也具备通信协同的能力呢?让我们再次回顾一下。
当TaskAppend操作尝试获取Stream所属的Graph时,如果存在Graph,则返回该Graph;反之,则返回None。
```cpp
NCCLCHECK(ncclCudaGetCapturingGraph(&graph, info->stream))
```
虽然这仅仅是一个分布式通信任务,但其数据流所属的图结构却难以捉摸。毕竟,这是从外部传入的,因此可能是计算任务或更大型框架的一部分。实际上,ncclStrongStreamAcquire和ncclStrongStreamWaitStream都允许graph为0。这意味着,即使任务的数据流不在图中,也不会影响执行。逻辑上仅削减了与图相关的部分,仅保留了事件处理逻辑。
ncclResult_t ncclStrongStreamAcquire(
struct ncclCudaGraph graph, struct ncclStrongStream* ss
) {
#if CUDART_VERSION >= 11030
bool mixing = ncclParamGraphMixingSupport();
if (graph.graph == nullptr) {
if (mixing && ss->everCaptured) {
CUDACHECK(cudaStreamWaitEvent(ss->cudaStream, ss->serialEvent, 0));
ss->serialEventNeedsRecord = false;
}
} else {
ss->everCaptured = true;
// Find the current graph in our list of graphs if it exists.
struct ncclStrongStreamGraph** pg = &ss->graphHead;
struct ncclStrongStreamGraph* g;
while (*pg != nullptr) {
g = *pg;
if (g->graphId == graph.graphId) {
// Move to front of list so that operations after acquire don't have to search the list.
*pg = g->next;
g->next = ss->graphHead;
ss->graphHead = g;
return ncclSuccess;
} else if (false == __atomic_load_n(&g->alive, __ATOMIC_ACQUIRE)) {
// Unrelated graph that has been destroyed. Remove and delete.
*pg = g->next;
ncclStrongStreamGraphDelete(g);
} else {
pg = &g->next;
}
}
在图形化描述中,如果task stream被纳入考量,comm stream也会随之展示。若不然,各stream将相互event wait。device stream会等待首个user stream(计算流)完成任务,其余user stream则会等待device stream上的工作得以落实。
cudaStream_t launchStream = tasks->streams->stream;
NCCLCHECKGOTO(ncclStrongStreamAcquire(tasks->capturingGraph, &comm->sharedRes->deviceStream), result, failure);
// Create dependency for device stream on user streams. First from extra user
// streams to deviceStream. Then deviceStream to first user stream.
for (struct ncclCudaStreamList* l=tasks->streams->next; l != nullptr; l = l->next) {
NCCLCHECKGOTO(ncclStrongStreamWaitStream(tasks->capturingGraph, &comm->sharedRes->deviceStream, l->stream), result, failure);
}
NCCLCHECKGOTO(ncclStrongStreamWaitStream(tasks->capturingGraph, launchStream, &comm->sharedRes->deviceStream), result, failure);
那么还有最后一个问题?nccl 最终会调用cudalaunch,但是graph 执行需要graph capture ending一起被graphlaunch,这里是怎么处理的呢?
如果存在图,当前task 会被认为是persistent 的task,会被拷贝至gpu上,在nccl clean group时也会绕过。后续流程就不得而知了。
从上述逻辑证明看,计算和通信是可以放在一个graph 内的,所以计算通信必然是可以协同的。这一部分可以参考系列三种cuda graph的部分说明。
Fabric manager 浅说
除了众所周知的NCCL software stack,GPU达到如此可用性,与Fabric manager也是分不开的。在使用NVIDIA显卡(V100/A100/A30等)时,需要安装对应的驱动,但是有时还要安装与驱动版本对应的nvidia-fabricmanager服务,使GPU卡间能够通过NVSwitch互联 。
FM 是什么
FM 配置 NVSwitch memory fabric,以在所有参与的 GPU 之间形成一个内存结构,并监视支持该结构的 NVLink。在较高层面上,FM 具有以下职责:
-
配置NVSwitch 端口之间的路由。
-
为每个GPU分配带宽。
-
确保所有GPU都能够访问NVSwitch。
"优化您的系统性能,通过配置NVSwitch端口间的路由,与GPU驱动程序协同初始化,以及实时监控NVLink和NVSwitch的错误。"
在不支持基于自主链路初始化 (ALI) 的 NVLink 训练的系统(第一代和第二代基于 NVSwitch 的系统,即H100前)上,FM 还具有以下附加职责:
-
在NVLink中传输数据时,FM负责将数据从主机内存复制到NVLink缓冲区。
-
FM还负责在NVLink缓冲区和主机内存之间传输数据。
-
FM还负责在主机内存和NVLink缓冲区之间传输数据。
-
与NVSwitch驱动程序协同,训练NVSwitch至NVSwitch NVLink连接。
-
与GPU驱动程序协同,初始化并训练NVSwitch至GPU NVLink连接。
Nvlink 初始化
NVIDIA GPU 和 NVSwitch memory fabric是需要使用 NVIDIA 内核驱动程序的 PCIe 端点设备。在不支持 ALI 的 DGX-2、NVIDIA HGX-2、DGX A100 和 NVIDIA HGX A100 系统上,系统启动后,加载 NVIDIA 内核驱动程序后会启用 NVLink 连接,并且 FM 会配置这些连接。如果在 FM 完全初始化系统之前启动应用程序,或者 FM 无法初始化系统,则 CUDA 初始化将会失败,并出现 cudaErrorSystemNotReady 错误。
在支持 ALI 的 DGX H100 和 NVIDIA HGX H100 系统上,NVLink 在 GPU 和 NVSwitch 硬件上进行训练并不需要FM。要启用 NVLink 对等支持,GPU 必须向 NVLink 结构注册。如果 GPU 无法注册到结构,它将失去其 NVLink 对等功能并可用于非对等用例。GPU 完成 NVLink 结构的注册过程后,CUDA 初始化过程将开始。
FM 模式
FM 主要配置四类模式:
在初始化过程中遇到问题时,可能会出现以下几种模式:
-
初始化失败模式:当系统在尝试建立基本环境时遇到困难,可能会导致初始化失败。
-
Access Link 失败模式:这是指 GPU 和 NVSwitch(一种高速互连技术)之间的连接出现问题,通常与 NVLink 有关。
-
Trunk Link 失败模式:这种模式发生在交换机之间,主要涉及 OSFP(Open Shortest Path First)协议。
-
Switch 异常模式:当单个交换机本身发生故障时,可能会出现此模式。
-
FM 停止情况下 Job 的工作模式:在全速运行(FM)停止的情况下,任务可能无法正常执行,表现为 GPU 上的任务失败。
为避免这些问题,请确保硬件和软件环境的正确配置,并定期进行维护和检查。
基本流程栈
从运维角度来看,一个完整的软件栈包括NVML(nvidia-smi监控API)、GCGM(监控后端代理)、fabric manager service(后端服务)、GPU & NVSwitch驱动程序以及BMC等组件。
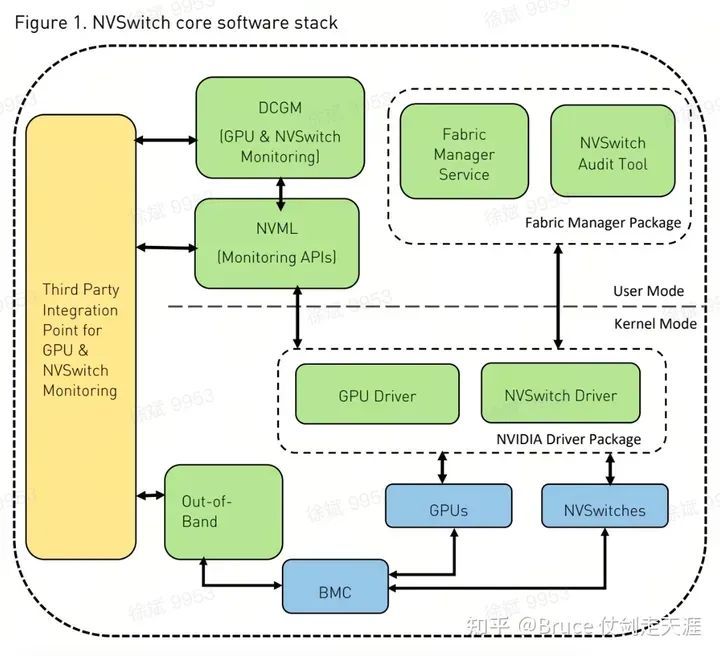
MIG 与 fabric manager
MIG 将 NVIDIA A100 或 H100 GPU 划分为许多独立的 GPU 实例。这些实例同时运行,每个实例都有自己的内存、缓存和流式多处理器。但是,当您启用 MIG 模式时,GPU NVLink 将被禁用,GPU 将失去其 NVLink 对等 (P2P) 功能。成功禁用 MIG 模式后,将再次启用 GPU NVLinks,恢复 GPU NVLink P2P 能力。在基于 NVSwitch 的 DGX 和 NVIDIA HGX 系统上,FM 服务可以与 GPU MIG 实例配合。此外,在这些系统上,要在禁用 MIG 模式后成功恢复 GPU NVLink 对等功能,FM 服务必须正在运行。
在 DGX 上A100 和 NVIDIA HGX A100 系统,相应的 GPU NVLink 和 NVSwitch 侧 NVLink 在启用 MIG 模式时关闭,在禁用 MIG 模式时重新训练。但是,在 DGX H100 和 NVIDIA HGX H100 系统上,GPU NVLink 将在 MIG 模式期间保持active。
DCGM
NVIDIA 数据中心 GPU 管理器 (DCGM) 是一套用于在集群环境中管理和监控 NVIDIA 数据中心 GPU 的工具。它包括主动健康监控、全面诊断、系统警报和治理策略(包括电源和时钟管理),也包括link 状态、gpu 任务状态的监控。
DCGM是一套用于在集群环境中管理和监控NVIDIA数据中心GPU的工具,包括主动健康监控、全面诊断、系统警报和治理策略(包括电源和时钟管理),以及link状态和GPU任务状态的监控。
NVML
"Nvidia-smi,一款强大的GPU管理和监控工具,能详细显示包括温度、电压、板卡类型ID、GPU利用率和活跃CE数量等关键信息。此外,'nvidia-smi topo -m'命令还能帮助您获取当前机器的拓扑情况。借助Nvidia-smi,您的GPU管理将更为轻松高效!"
Host driver 的用处
目前观察到,Nvlink 和 NVSwitch Host Driver 主要为 Fabric Manager 和 NVML 服务,与实际的数据面操作无关。主要功能包括配置/获取管理信息。因此,关注 Fabric Manager 部分即可掌握主体应用逻辑。
Nvswitch
Nvswitch driver的功能相当淳朴,两部分:
-
NVSwitch的初始化工作(probe)和去初始化。
-
管理功能包括以下几个类别:
-
状态查询:通过NVLink总线上的寄存器来查询NVSwitch的状态信息;
-
配置:通过NVLink总线上的寄存器来配置NVSwitch的工作模式、传输速率等参数;
-
控制:通过NVLink总线上的寄存器来控制NVSwitch的工作状态。
- Nvswitch 信息获取,
- "专注于硬件,涵盖温度、BIOS、驱动和固件版本、内部延迟、硬件配置信息、计数器、状态、错误和I2C等多元化领域。"
- 好的,我可以帮您优化文章内容。请问您需要优化哪些方面?比如语言表达、结构、长度等等。如果您有任何具体要求,请告诉我。
- 面向流量,包数、带宽等等的统计信息
- 访问控制,比如修改routing 表,修改blacklist,直接读写寄存器
- 清理各种错误信息
nvlink
Nvlink 的功能相对复杂一些,不过总的而言也是几类:
- GPU和nvlink 关系的绑定(add,remove)
- nvlink的初始化和训练
- "Nvlink Topology的揭示,揭示了Fabric Manager与NVML对于拓扑信息及对端Link信息的深度需求。"
- Nvlink 连接情况
- Nvlink 模式的变化,lower power state
几种通信拓扑
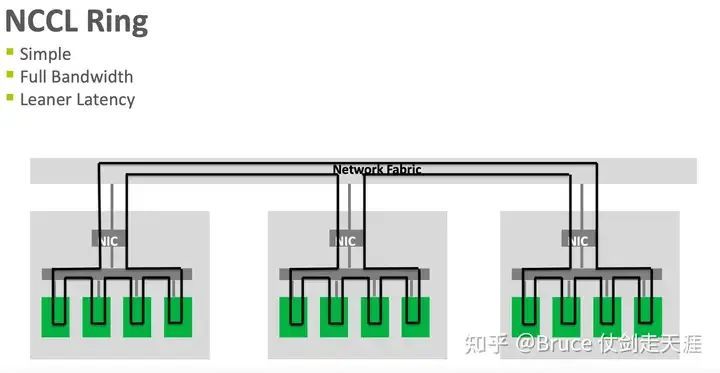
Ring
如所示,GPU以环形方式组织于集群内。若有三卡A、B、C,通信过程则为A->B、B->C、C->A。实际上,这种方式更适用于NVLink环境,并需考虑物理拓扑。
Tree
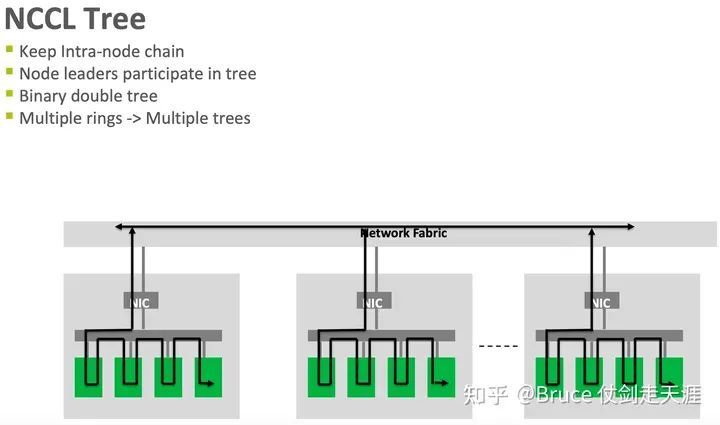
"Tree 与数据中心网络(fat tree)的物理拓扑比较接近,目前也主要用在数据中心网络中。" 这句话可以优化为:"Tree 和数据中心网络(fat tree)的物理拓扑相似,目前主要用于数据中心网络。"。
COLLNET-SHARP
"Sharp是一种优化网络计算流程的架构,通过将Reduce任务迁移至交换机,降低了通信负载和次数,实现了更高的有效带宽和更短的延迟。"
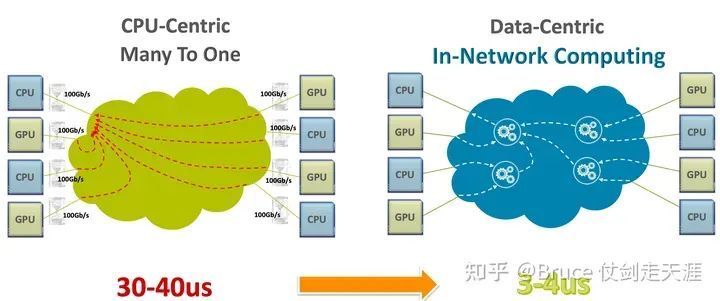
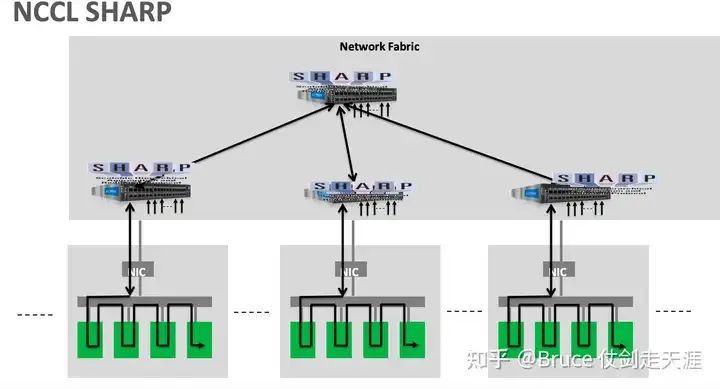
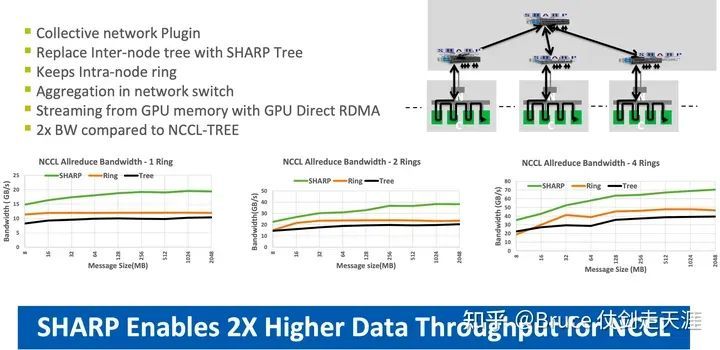
历代网络架构
Cube-Mesh - 最简拓扑
link 均匀。
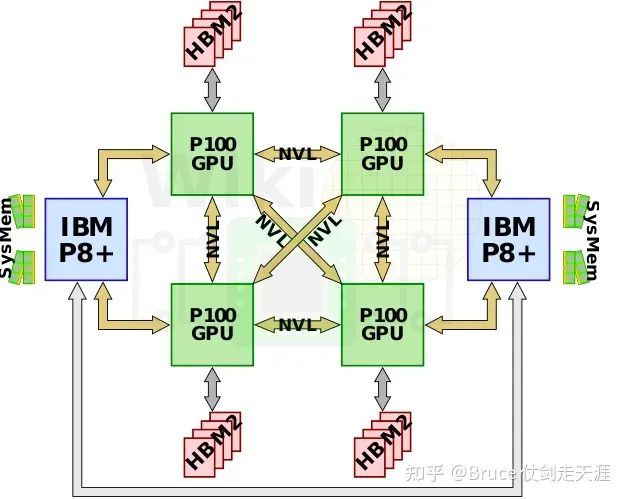
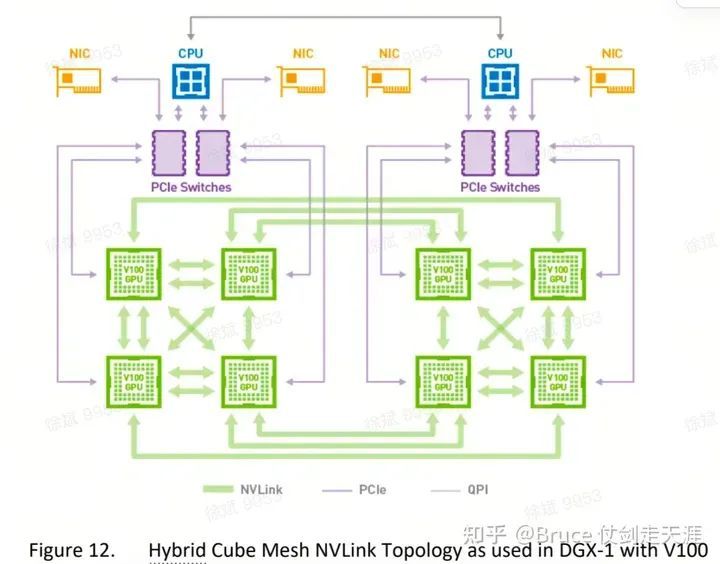
DGX-1 - 不均匀拓扑
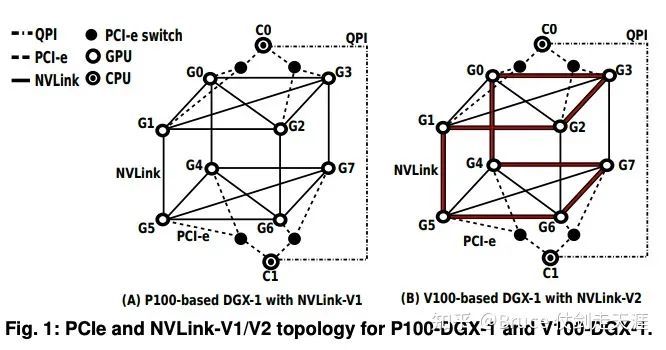
请关注V100与P100的差异:P100 cube中,每条边连接一个节点;而在V100 cube中,每个节点连接两条边,即两个链接。这种差异导致了在cube中访问GPU时,有的只需要一跳链接(如P100),而有的则需要两跳链接(如V100)。因此,两跳延迟可能是一跳延迟的两倍。
这张图说明了为什么此类拓扑叫cube-mesh)。
DGX-2 - switch 出现
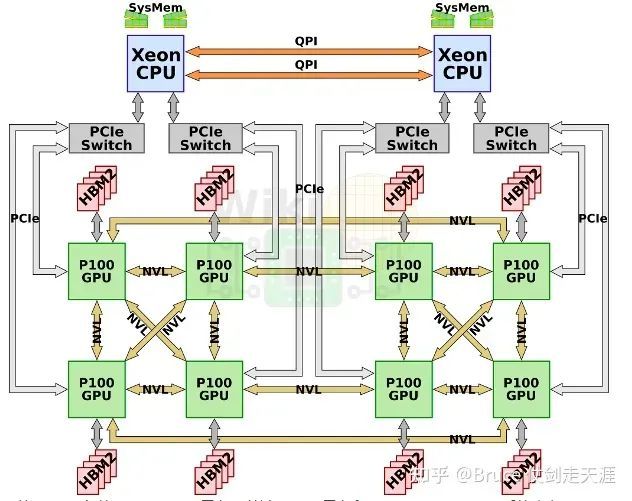
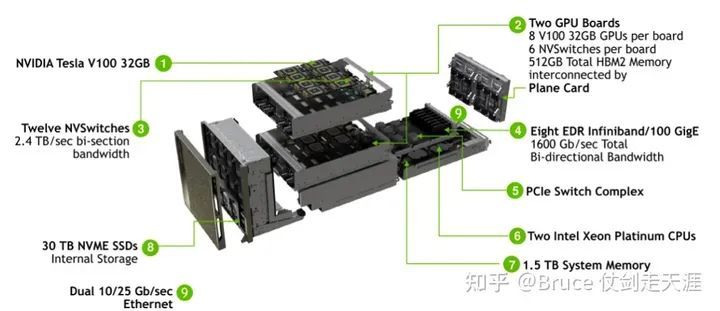
GTC2018发布的dgx-2,加倍了v100的数量,最终高达16块v100。同时,hbm2升级到32GB/块,一共高达512GB。CPU升级为双路2.7GHz 24核Xeon 8168。
请问这样是否满足你的需求?还有什么其他问题吗?
dgx2拥有两块基板,这两块基板则是通过nvswitch剩余的另一侧接口完全互联在一起,这就构成了一个16路全连接的GPU构架。
两块基板之间的nvswitch之间都有八路link互联,16块GPU每块有6路nvlink的情况下,其总双路带宽达到2400GB/s。有趣的是,其实nvswitch有18路接口nvidia却只用到了其中16路。一种可能性是nv留下两路用于支持ibm的power9处理器(dgx1和2都是用的志强)。在这个复杂的结构中,power9处理器可能分别接在两块基板的nvsiwtch上,这样GPU也与Power9处于全连接状态。如果CPU直接与nvswitch相连,那么pcie就不再担任cpu与gpu相连的责任。目前nvidia还没有向其他厂商开放nvswitch,如果他们决定开放,将会产生一些新型态的,可能更加规模庞大的结算节点。
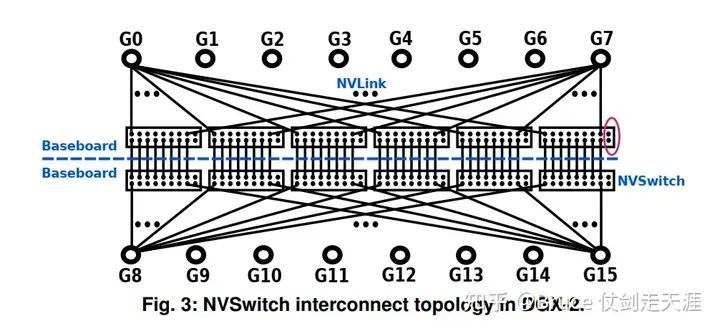
每个NVSwitch是18*18的crossbar交换机:
- 8个port用于baseboard内的通信
- 8个port用于和对端baseboard进行通信
- 需要经过两跳交换机,但由于两边的交换机有一半是直连,所以可以当成一跳交换机
- 另外两个port保留
DGX - A100
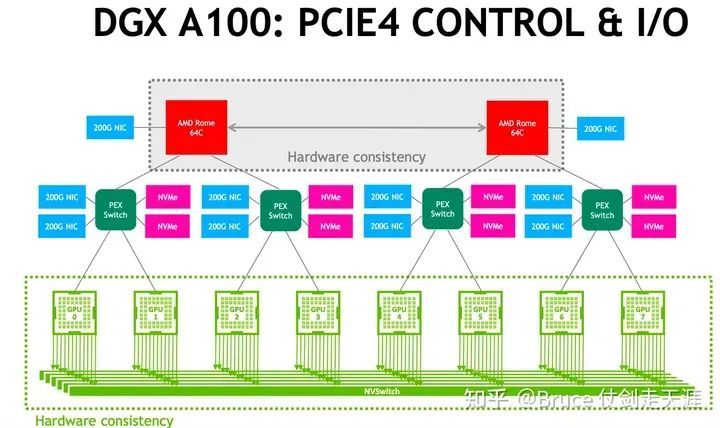
H100 superpod
Nv switch 收敛比 ingress:egress = 2:1。
一台机器有8张H100,4 个 nvswitch,每张H100 18link,以5、4、4、5 连接至4个 L1 nvswitch,每个nvswitch 单芯片,每芯片64link。
所以机器内的四个L1 nvswitch 承受连接数不同,每个link 50GB/s,所以四台L1 ingress分别是2 TB/s、1.6 TB/s、1.6 TB/s、2 TB/s,分别占用40、32、32、40 link。
L1 向上连接L2 switch,通过osfp,一个osfp 由4个link 组成,带宽为200Gbps。egress 方向2:1 收敛后分别为1TB/s,0.8TB/s,0.8TB/s,1TB/s,分别需要5、4、4、5条osfp,折合20、16、16、20 link。
L1 switch link 利用分别为(40 + 20)/64,(32+16)/64,(32+16)/64,(40+20)/64。
一个superpod 一共32台机器,32 * (1 + 0.8 + 0.8 + 1)TB/s = 115.2 TB/s = 32 * (5 + 4 + 4 + 5)osfp = 576 osfp,一台L2 16个osfp ,所以需要L2 switch 576/16 = 36台。
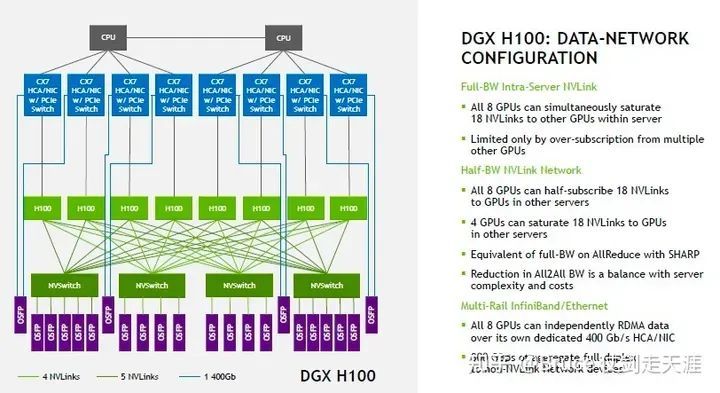
GH200 superpod
拓扑图展示了Grace hopper的两套网络结构:DPU与quantum2相连,GPU通过nvlink/nvswitch接入。
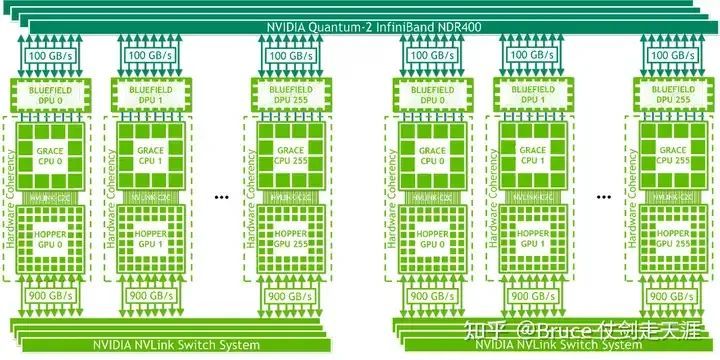
GH200 中 Nv switch 收敛比 ingress:egress = 1:1,相比H100 收敛比更高,意味总带宽可以提高。
一台机器中8张H100(带Grace CPU),每张H100 18link;3个switch,每个switch 2 芯片,每个芯片64link,每switch 合计128link。
每H100 以6、6、6 link连接至3台switch(每个switch chip 对应3link),比H100 均匀,每个chip 只有24link ingress,每个switch 48link ingress。
每个link 50GB/s,单switch chip 连接8*3=24link=1.2TB/s,单switch 2.4TB/s,1:1收敛比,所以egress 也是2.4TB/s,折合12 osfp,48link egress。
L1 的switch ingress + egress = 96link,占用率为96/128,32 port 空闲。
单台机器3个L1 switch,总egress 7.2TB/s = 36 osfp。
一个superPod 32 机器,L2 总ingress = 7.2TB/s * 32 = 36osfp * 32 = 1152 osfp。
L2 switch 规格与L1 一样,一台switch 128link = 32osfp,所以一共需要36台L2 switch。
虽然GH200 与 H100 在L2 switch 数量,机器数量以及GPU数量一致,但是由于收敛比设计不同,总带宽是不一样的,GH200 的一台switch 能力为H100 拓扑中的2倍。
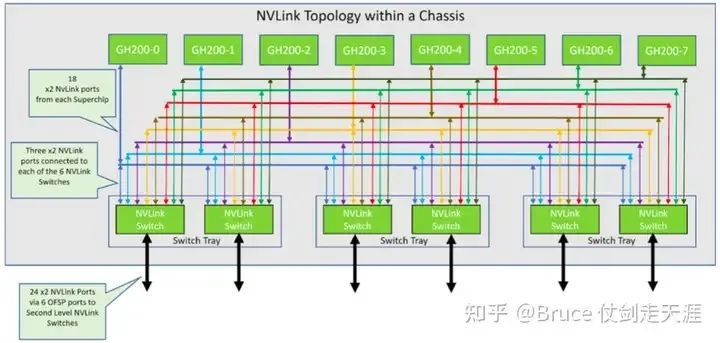
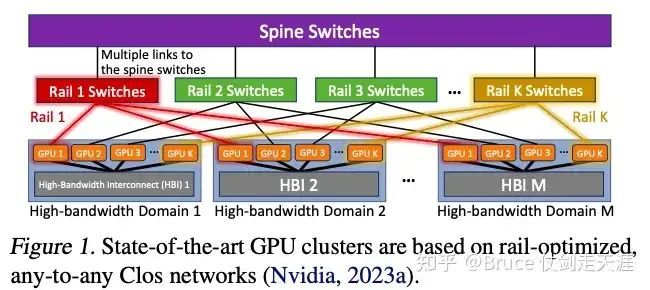
除了NVlink 和 NVswitch 构成的high bandwidth networks, RDMA 构成了另一个网络,这整体构成railway架构。我们之前讲述的是nvlink 网络的架构,侧重pod内互联,pod内GPU通信通过nvlink,而pod间通过RDMA。RDMA 网络的结构如下图,假设我们有M个pod,每个pod内有K张GPU,pod内K个GPU通过nvlink和nvswitch互联,每个pod内的第i个GPU通过RDMA连接到同一个switch上,所以一共有K个rail switch,因此不同pod之间可以通过 rail switch互联,而rail switch都连接到spine switch,所以整个网络可以互联。spine switch 可以看作是对外的接口,以及rail switch 不能满足需求时的保障。然而实际上,大模型训练过程中nvlink 占通信70%以上,其余主要集中在rail switch,spine switch上很少流量。
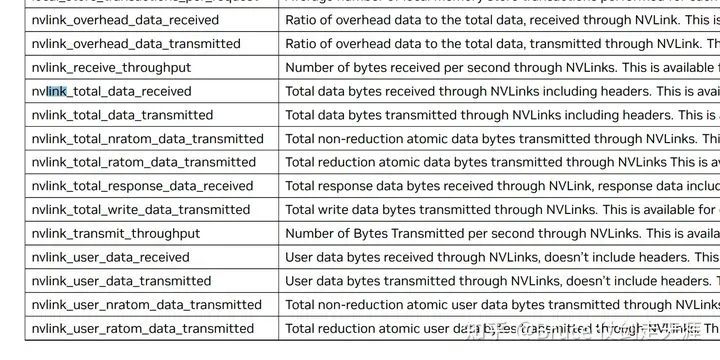
附录1- NVprof / profling 工具
Nvidia Profiling工具,深入挖掘GPU、Link和CPU性能数据,尤其在nvlink方面,揭示了丰富的带宽数据和拓扑信息。以下仅为部分示例。
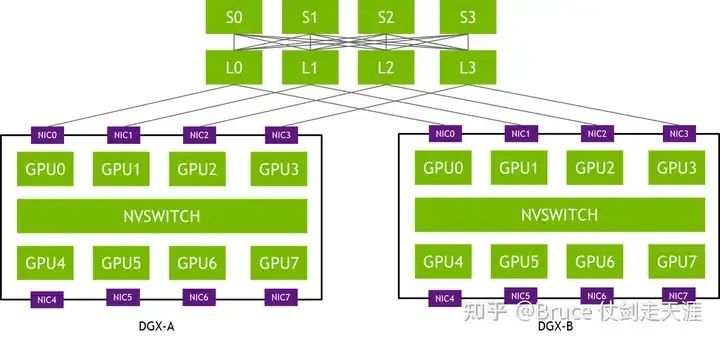
附录2-PXN - PCI X NVLINK
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-