state: T h e s t a t u s o f a g e n t w i t h r e s p e c t t o t h e e n v i r o n m e n t The \quad status \quad of \quad agent \quad with \quad respect \quad to \quad the \quad environment Thestatusofagentwithrespecttotheenvironment (agent 相对于环境的状态)
对于下面的网格地图来说: s t a t e state state就相当于 location ,用 s 1 、 s 2 、 . . . 、 s 9 s_1、s_2、...、s_9 s1、s2、...、s9来表示
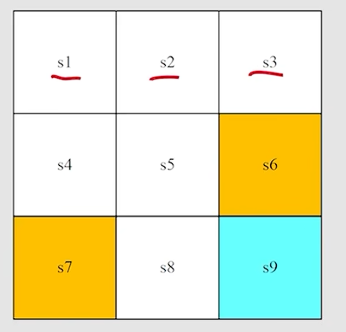
state space: T h e s e t o f a l l s t a t e S = { s i } i = 1 9 The \quad set \quad of \quad all \quad state \quad S = \{s_i\}_{i=1}^{9} ThesetofallstateS={si}i=19 状态空间,把所有 s t a t e state state放在一起得到的集合就是 s t a t e s p a c e state \quad space statespace
Action: F o r e a c h s t a t e , t h e r e a r e f i v e p o s s i b l e a c t o i n : a 1 、 a 2 、 a 3 、 a 4 、 a 5 For \quad each \quad state, \quad there \quad are \quad five \quad possible \quad actoin: a_1、a_2、a_3、a_4、a_5 Foreachstate,therearefivepossibleactoin:a1、a2、a3、a4、a5
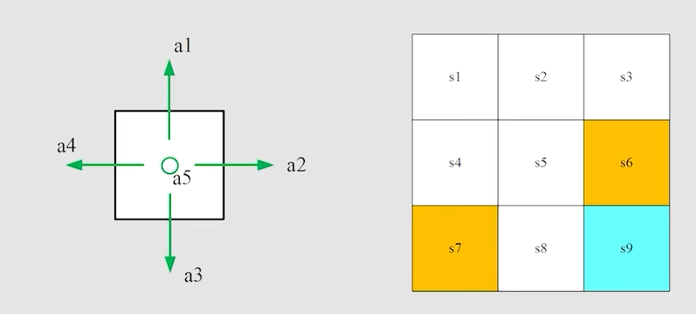
Action space of a state: t h e s e t o f a l l p o s s i b l e a c t i o n s o f a q u a d s t a t e the \quad set \quad of \quad all possible actions \quad of \quad a \ quad state thesetofallpossibleactionsofa quadstate
A ( s i ) = { a i } i = 1 5 A(s_i) = \{a_i\}_{i=1}^{5} A(si)={ai}i=15
state transition: 当采取了一个 a c t i o n action action后, a g e n t agent agent从一个 s t a t e state state转移到另一个 s t a t e state state,这样一个过程佳作 s t a t e t r a n s i t i o n state \quad transition statetransition

s t a t e t r a n s i t i o n state \quad transition statetransition定义一种 a g e n t agent agent和 e n v i r o n m e n t environment environment交互的行为
Forbidden area:有两种情况,一种是forbidden are可以到达,但是会得到相应的惩罚,另一种是forbidden area不可到达,相当于有一堵墙。
Tabular representation:可以用表格来描述state transition
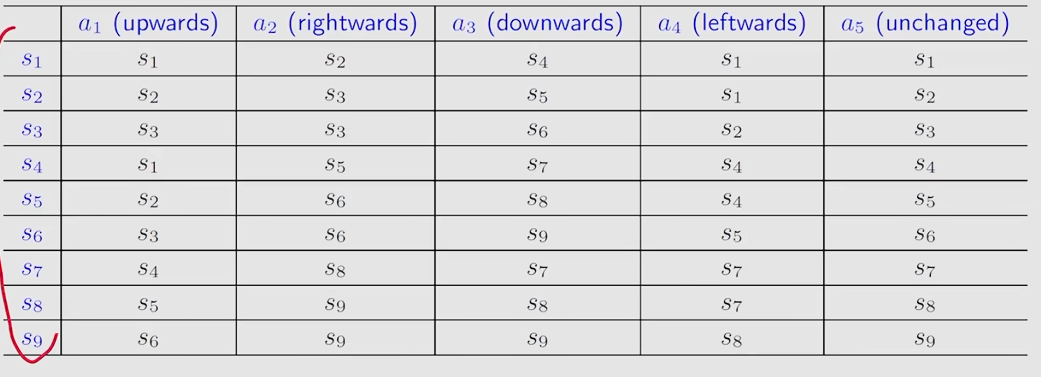
只能能表示确定的情况
相比于上面的表格,更一般的做法是使用下面这种方法
state transition probability:使用概率来描述state transition

Policy:告诉agent在一个状态应该采取什么动作
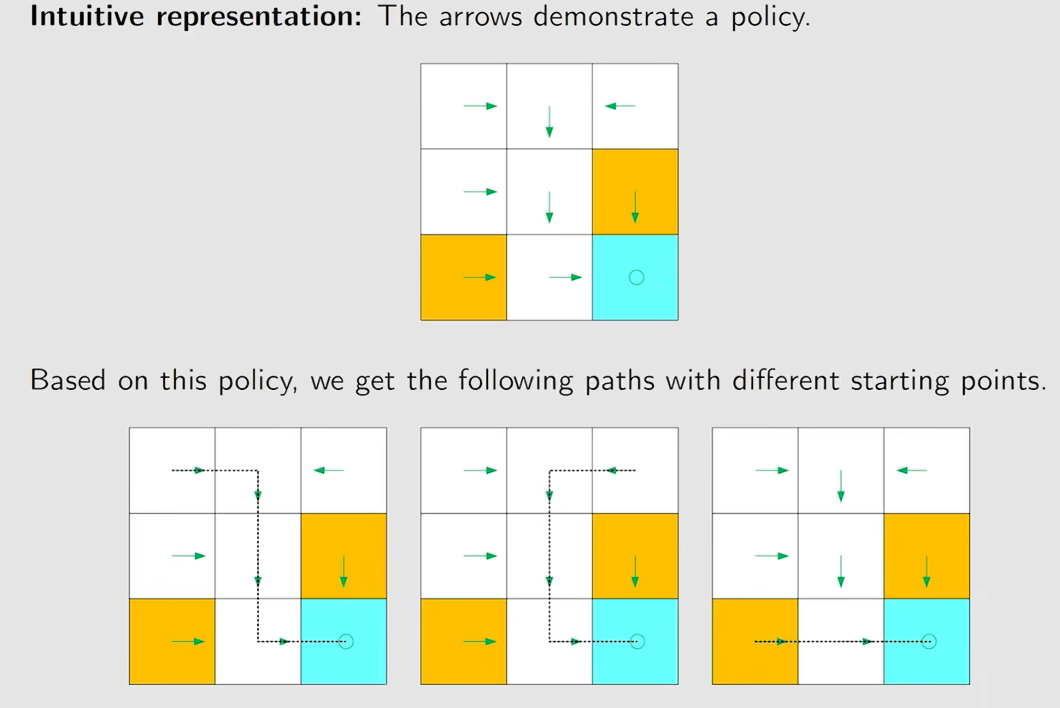

π \pi π在强化学习中用来表示条件概率,而不是圆周率
上面图片中的情况是确定性的策略,同时也有不确定的策略
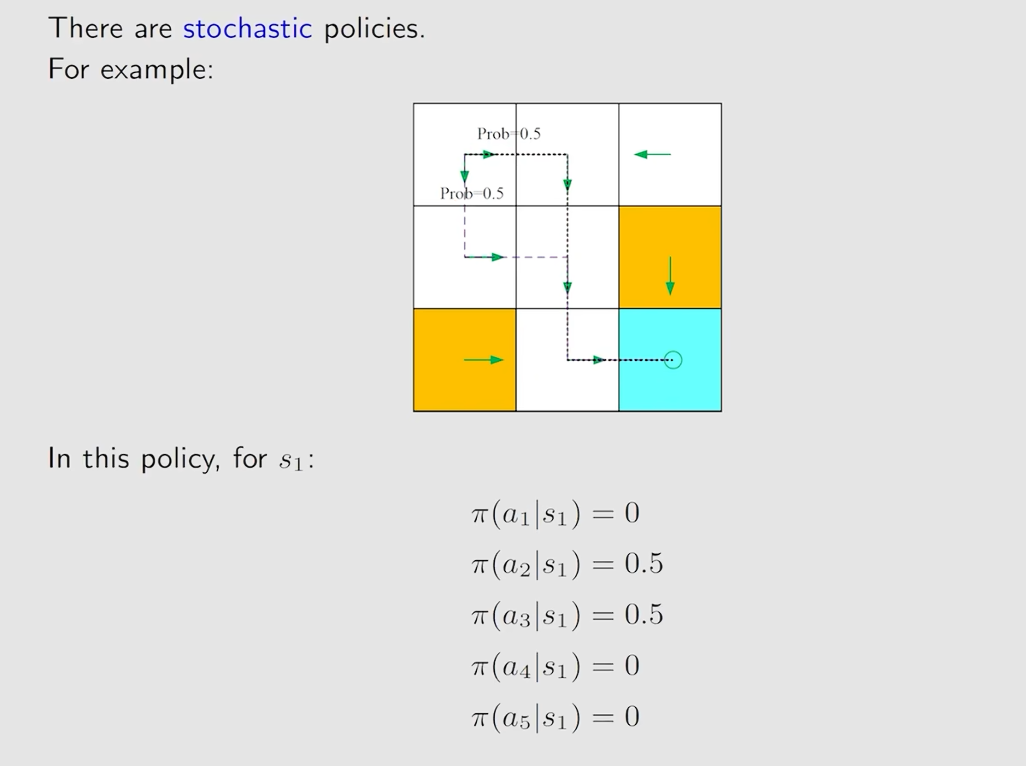
Reward:reward是action采取一个action后得到的实数,一个正的reward代表鼓励采取这样的action,一个负的reward代表惩罚这样的action。
reward可以理解成一个 h u m a n − m a c h i n e i n t e r f a c e human-machine \quad interface human−machineinterface,我们人类和机器交互的一个接口
reward依赖于当前的 s t a t e 和采取的 a c t i o n state和采取的action state和采取的action而不是依赖于接下来的 s t a t e state state
trajectory:是一个 s t a t e − a c t i o n − r e w a r d state-action-reward state−action−reward chain
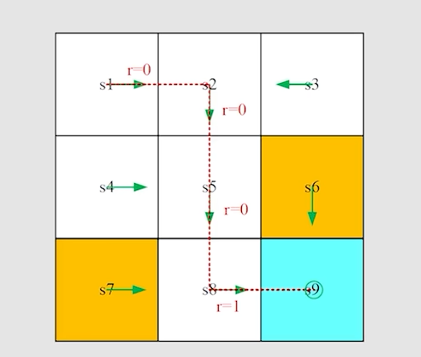
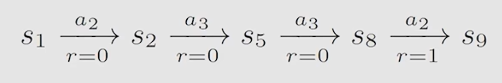
Return:沿着trajectory,所有的reward相加得到得就是return
return的作用可以用来评估一个策略的好坏
discount return:
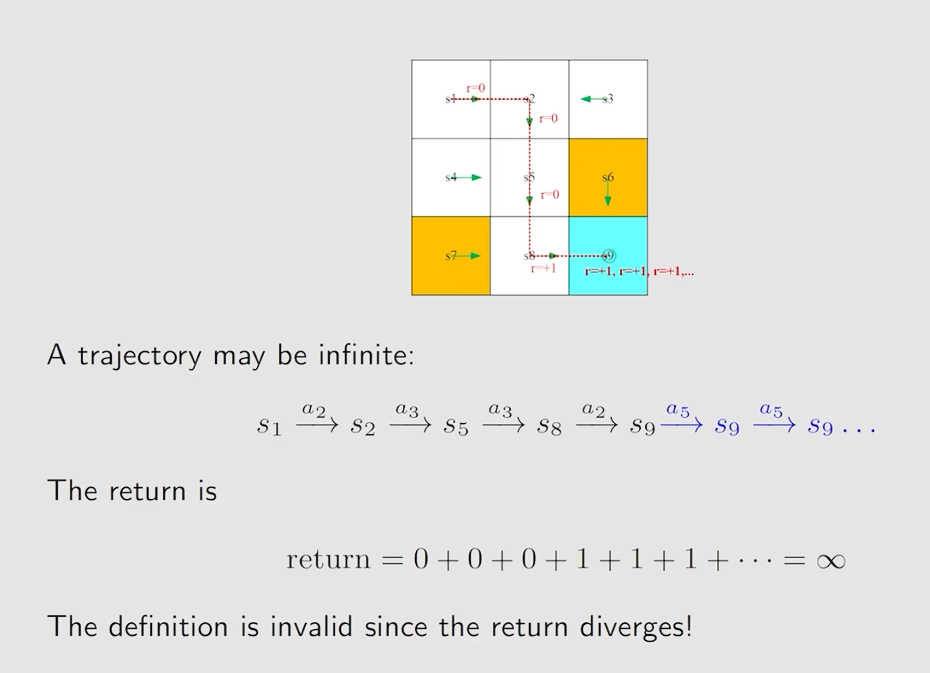
从上图可以看到上面的trajectory是无限长的,对应的return是发散的。
为了解决这个问题引入一个 d i s c o u n t r a t e γ ∈ [ 0 , 1 ) discount \quad rate \quad \gamma \in [0, 1) discountrateγ∈[0,1)
上面的return就可以用discount return来表示
discount return = 0 + \\gamma \* 0 + {\\gamma\^2} \* 0 + {\\gamma\^3} \* 1 + {\\gamma\^4} \* 1 + ...
d i s c o u n t r e t u r n = γ 3 ( 1 + γ + γ 2 + γ 3 + . . . ) discount return = \gamma^3(1 + \gamma + \gamma^2 + \gamma^3 + ...) discountreturn=γ3(1+γ+γ2+γ3+...)
d i s c o u n t r e t u r n = γ 3 ( 1 1 − γ ) discount return = \gamma^3(\frac{1}{1 - \gamma}) discountreturn=γ3(1−γ1)
episode\trial:一个有限步的trajectory被称为episode,也就是有terminal states的trajectory。
可以采用方法将episodic转化为continue的,在terminal state时无论采取什么action都会回到terminal state。
MDP:Markov decision process,马尔可夫决策过程是一个框架framework
一个马尔可夫决策过程中有很多关键的元素:
set:
- State:
- Action
- Reward
Probability distribution:
- State transition probability:在一个状态s,采取action a,转移到状态 s ′ s^{'} s′的概率 p ( s ′ ∣ s , a ) p(s^{'}|s,a) p(s′∣s,a)
- Reward probability:在状态s,采取action a,得到reward r的概率 p ( r ∣ s , a ) p(r|s, a) p(r∣s,a)
Policy:
在状态s,采取action a的概率 π ( a ∣ s ) \pi(a|s) π(a∣s)
Markov property:memoryless property
