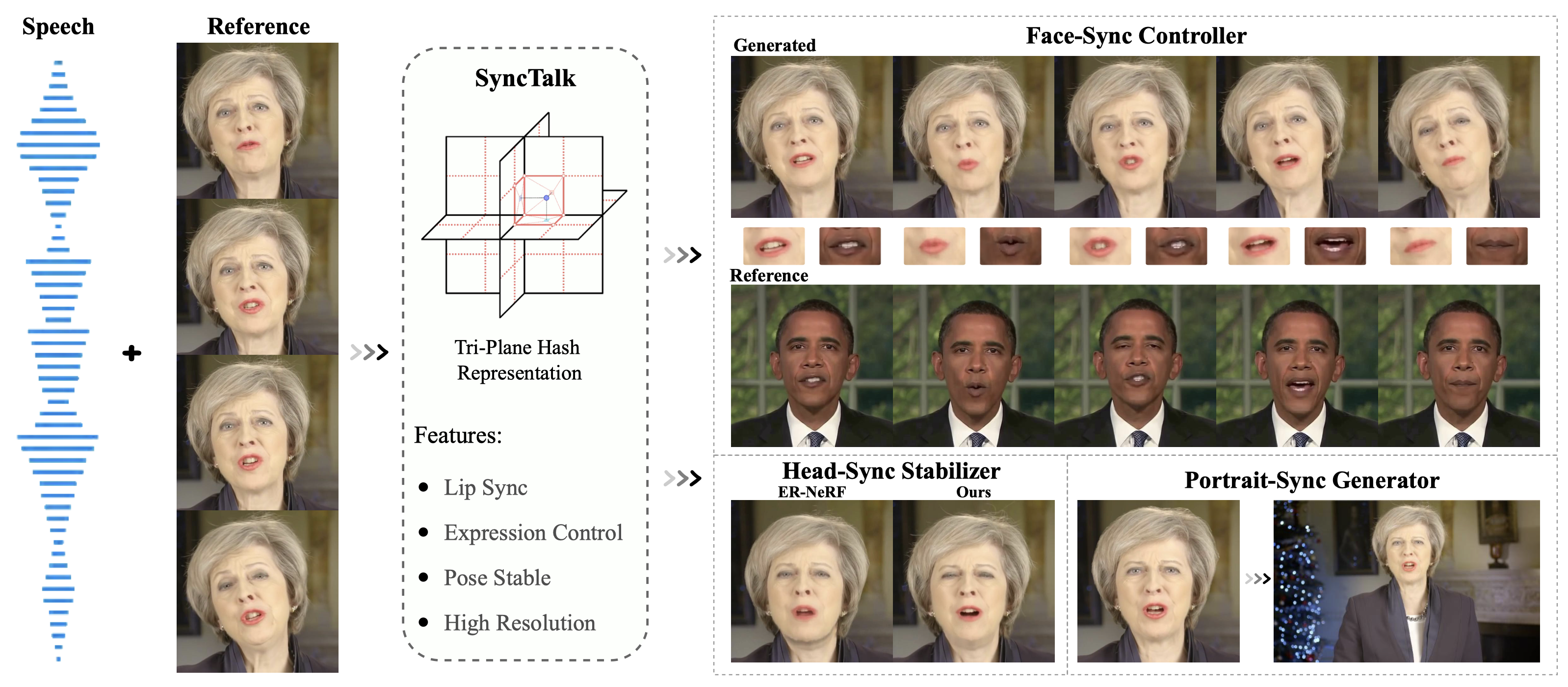
一、模型介绍
在合成逼真的语音驱动的说话头视频时,实现高度同步是一项重大挑战。传统的生成对抗网络 (GAN) 难以保持一致的面部身份,而神经辐射场 (NeRF) 方法虽然可以解决这个问题,但通常会产生不匹配的唇部运动、不充分的面部表情和不稳定的头部姿势。栩栩如生的说话头需要同步协调主体身份、唇部运动、面部表情和头部姿势。缺乏这些同步是一个根本缺陷,导致不切实际和人为的结果。
为了解决同步这一关键问题,即创建逼真的说话头的"魔鬼",我们引入了 SyncTalk。这种基于 NeRF 的方法有效地保持了主体身份,增强了说话头合成的同步性和真实感。SyncTalk 采用面部同步控制器将唇部运动与语音对齐,并创新地使用 3D 面部混合形状模型来捕捉准确的面部表情。我们的头部同步稳定器优化了头部姿势,实现了更自然的头部运动。 Portrait-Sync Generator 可恢复头发细节,并将生成的头部与躯干融合,带来无缝视觉体验。大量实验和用户研究表明,SyncTalk 在同步和真实性方面优于最先进的方法。
二、部署流程
环境测试
在 Ubuntu 20.04、CUDA 11.3 上测试
1.克隆并安装
(1)克隆
git clone https://github.com/ZiqiaoPeng/SyncTalk.git
cd SyncTalk(2)安装依赖项
conda create -n synctalk python==3.8.8
conda activate synctalk
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113
sudo apt-get install portaudio19-dev
pip install -r requirements.txt
pip install --no-index --no-cache-dir pytorch3d -f https://dl.fbaipublicfiles.com/pytorch3d/packaging/wheels/py38_cu113_pyt1121/download.html
pip install tensorflow-gpu==2.8.1
pip install ./freqencoder
pip install ./shencoder
pip install ./gridencoder
pip install ./raymarching如果在安装 PyTorch3D 时遇到问题,可以使用以下命令进行安装:
python ./scripts/install_pytorch3d.py2.数据准备
(1)预训练模型
请将May.zip放在数据 文件夹中,将trial_may.zip 放在模型文件夹中,然后解压它们。
(2)新 处理您的视频
-
准备人脸解析模型。
wget https://github.com/YudongGuo/AD-NeRF/blob/master/data_util/face_parsing/79999_iter.pth?raw=true -O data_utils/face_parsing/79999_iter.pth -
准备 3DMM 模型以进行头部姿势估计。
wget https://github.com/YudongGuo/AD-NeRF/blob/master/data_util/face_tracking/3DMM/exp_info.npy?raw=true -O data_utils/face_tracking/3DMM/exp_info.npy wget https://github.com/YudongGuo/AD-NeRF/blob/master/data_util/face_tracking/3DMM/keys_info.npy?raw=true -O data_utils/face_tracking/3DMM/keys_info.npy wget https://github.com/YudongGuo/AD-NeRF/blob/master/data_util/face_tracking/3DMM/sub_mesh.obj?raw=true -O data_utils/face_tracking/3DMM/sub_mesh.obj wget https://github.com/YudongGuo/AD-NeRF/blob/master/data_util/face_tracking/3DMM/topology_info.npy?raw=true -O data_utils/face_tracking/3DMM/topology_info.npy -
从巴塞尔人脸模型 2009下载 3DMM 模型:
# 1. copy 01_MorphableModel.mat to data_util/face_tracking/3DMM/ # 2. cd data_utils/face_tracking python convert_BFM.py -
将您的视频放在
data/<ID>/<ID>.mp4下,然后运行以下命令来处理视频。
注意 视频必须为 25FPS,所有帧都包含说话的人。分辨率应约为 512x512,持续时间约为 4-5 分钟。python data_utils/process.py data/<ID>/<ID>.mp4 --asr ave您可以选择使用 AVE、DeepSpeech 或 Hubert。处理后的视频将保存在数据文件夹中。
-
可选 获取眨眼的 AU45
在 OpenFace
FeatureExtraction中运行,重命名并将输出的CSV 文件移动到data/<ID>/au.csv
【注】 由于 EmoTalk 的 blendshape 捕获不开源,这里的预处理代码用 mediapipe 的 blendshape 捕获替换。但根据一些反馈,它效果不佳,您可以选择用 AU45 替换它。如果您想与 SyncTalk 进行比较,可以在这里获得一些使用 EmoTalk 捕获的结果以及来自GeneFace 的视频。
3.快速入门
(1)运行评估代码
python main.py data/May --workspace model/trial_may -O --test --asr_model ave
python main.py data/May --workspace model/trial_may -O --test --asr_model ave --portrait"ave"指的是我们的视听编码器,"portrait"表示把生成的人脸粘贴回原图上,代表更高的质量。
如果运行正确,你会得到以下结果。
| 环境 | 峰值信噪比 | 低密度聚乙烯 | 激光微分方程 |
|---|---|---|---|
| SyncTalk(无肖像) | 32.201 | 0.0394 | 2.822 |
| SyncTalk(纵向) | 37.644 | 0.0117 | 2.825 |
这是针对单个主题的;本文报告的是多个主题的平均结果。
(2)使用目标音频进行推理
python main.py data/May --workspace model/trial_may -O --test --test_train --asr_model ave --portrait --aud ./demo/test.wav请使用以".wav"为扩展名的文件进行推理,推理结果将保存在"model/trial_may/results/"中。
(3)测试
python main.py data/May --workspace model/trial_may -O --test --asr_model ave --portrait(4)训练和测试躯干 修复双下巴
如果你的角色只训练了头部,出现了双下巴问题,你可以引入躯干训练。通过训练躯干,这个问题可以得到解决,但 你将无法使用"--portrait"模式。 如果你添加"--portrait",躯干模型将失效!
# Train
# <head>.pth should be the latest checkpoint in trial_may
python main.py data/May/ --workspace model/trial_may_torso/ -O --torso --head_ckpt <head>.pth --iters 150000 --asr_model ave
# For example
python main.py data/May/ --workspace model/trial_may_torso/ -O --torso --head_ckpt model/trial_may/ngp_ep0019.pth --iters 150000 --asr_model ave
# Test
python main.py data/May --workspace model/trial_may_torso -O --torso --test --asr_model ave # not support --portrait
# Inference with target audio
python main.py data/May --workspace model/trial_may_torso -O --torso --test --test_train --asr_model ave --aud ./demo/test.wav # not support --portrait三、界面演示