2024-10-10,由电信研究所、里斯本大学等联合创建MT-Pref数据集,它包含18种语言方向的18k实例,覆盖了2022年后的多个领域文本。通过在WMT23和FLORES基准测试上的实验,我们展示了使用MT-Pref数据集对Tower模型进行对齐可以显著提高翻译质量。
一、研究背景:
大型语言模型在机器翻译中的使用受到了研究社区的广泛关注。这些模型通常使用单个人参考翻译进行微调,但这可能不足以进一步提升翻译质量,因为对于给定的源文本,可能存在多种有效的翻译,其中一些可能比其他的更受偏好。
目前遇到困难和挑战 :
1、现有的数据集通常只包含一两模型的翻译输出,限制了其多样性和适用性。
2、这些数据集要么完全自动生成,要么完全基于人类反馈,前者缺乏关键验证,后者资源有限且难以扩展。
3、自动评估指标可能无法完全符合人类的预期,而人类评估虽然质量高,但成本高且难以大规模实施。
数据集地址:MT-PREF|机器翻译数据集|偏好分析数据集
二、让我们来一起看一下MT-Pref
在机器翻译领域,与人类偏好一致是开发准确、安全的大型语言模型的重要步骤。然而,基于人类反馈的偏好数据获取和整理成本非常高。通过结合了自动指标和人类评估的优势,创建的新的高质量偏好数据集MT-Pref(Metric-induced Translation Preference)。
数据集包含了来自多个高质量机器翻译系统生成的翻译的句子级质量评估,这些评估由专业语言学家提供。数据集覆盖了18种语言方向,文本来源多样,时间跨度为2022年后。
数据集构建 :
数据集的构建首先收集了专业语言学家对多个高质量机器翻译系统生成的翻译进行的句子级质量评估,然后使用这些评估来测试当前自动指标恢复这些偏好的能力。基于这一分析,研究者使用xComet-xl和xComet-xxl指标的组合来筛选出最受欢迎的和最不受欢迎的翻译。
数据集特点 :
1、包含18种语言方向,覆盖多种领域。
2、 包含18k实例,每个实例都经过专业语言学家的评估。
3、使用xComet-xl+xxl指标来诱导偏好,确保与人类评估的高相关性。
数据集可以用于训练和微调机器翻译模型,以提高翻译质量并使其更符合人类的偏好。研究者可以使用这些数据来训练偏好学习算法,如对比偏好优化(CPO)
基准测试 :
在WMT23和FLORES基准测试中,使用MT-Pref数据集进行微调的模型显示出了显著的翻译质量提升。
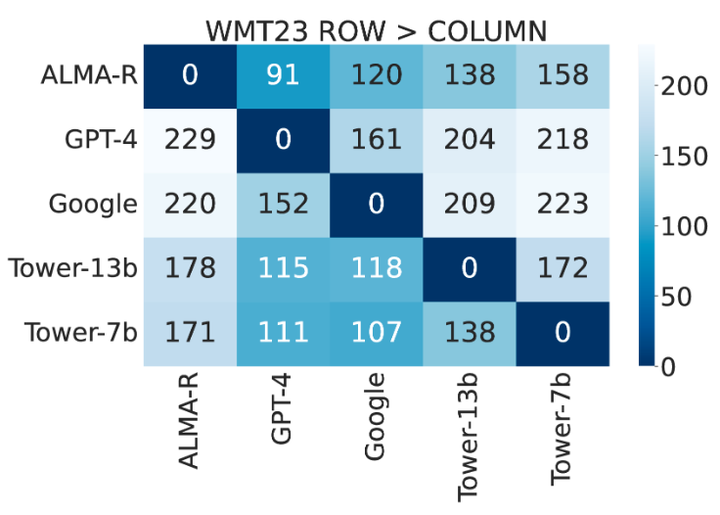
不同系统之间的成对偏好:Google 和 GPT-4 翻译比开源替代方案更受欢迎。
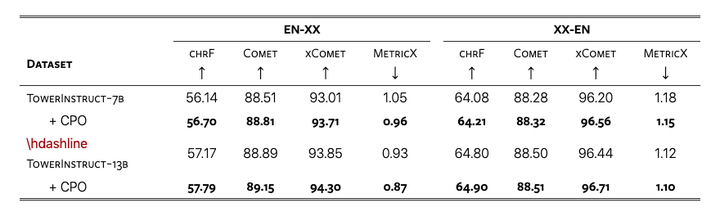
使用 MT-Pref 进行 CPO 微调可以提高 FLORES 上塔模型的翻译质量
三、让我们展望MT-Pref数据集的应用:
比如,我在一个多语言网站工作。
我的工作是确保网站上的各种产品描述、用户指南和新闻稿在翻译成不同语言后,不仅准确无误,还要保持原有的风格和语气。这可不是一件容易的事情哦。常使用的是翻译系统,虽然翻译得还算准确,但是有时候就像是机器人写出来的,缺乏那种"人味儿"。比如,如果原文里有些幽默的语句,翻译后的版本可能就变得干巴巴的,没有表达出作者的心境。
自从使用基于MT-Pref数据集训练的翻译系统后,似乎变得有些不一样了。
这个数据集厉害的地方在于,它能够教会翻译系统理解人类的偏好,知道什么样的翻译更受人喜欢。
就拿我们网站上的一款新咖啡机的介绍来说吧。原文里有句话是这样的:"这款咖啡机不仅能让你的早晨充满咖啡香,还能让你的家变成一个小小的咖啡馆。"用我们以前的翻译系统,可能就直接翻译成:"这个咖啡机可以让你的家早上充满咖啡的味道,并且让你的家变成一个小咖啡馆。"虽然意思没错,但是那种温馨的感觉就没了。
好在使用智能系统,翻译出来的可能就是:"这台咖啡机不仅能为你的清晨带来浓郁的咖啡香气,还能瞬间把你的客厅变成一个温馨的小咖啡馆。"这样的翻译不仅保留了原文的意境,还增加了一些让人会心一笑的细节,让产品介绍更加吸引人。
而且,这个系统还能根据不同的语言习惯,做出相应的调整。比如,对于西班牙语的用户,它可能会加入一些热情洋溢的词汇,让整个介绍更加贴近当地文化。对于德语用户,它可能会使用一些更精确的描述词汇,让产品介绍显得更加专业。
现在网站内容不仅在不同语言之间保持了高度的一致性,还提高了翻译的质量和风格上的匹配度。这让不同语言的用户都能获得更好的阅读体验,也让我们的网站显得更加专业和贴心。