论文题目:Paragraph-to-Image Generation with Information-Enriched Diffusion Model(基于信息扩散模型的段落到图像生成)
期刊:International Journal of Computer Vision
摘要:文本到图像模型最近经历了快速的发展,在保真度和文本对齐能力方面取得了惊人的性能。然而,给定一个很长的段落(最多512个单词),这些生成模型仍然难以实现强对齐,并且无法生成描绘复杂场景的图像。在本文中,我们引入了一个用于段落到图像生成任务的信息丰富的扩散模型,称为ParaDiffusion,该模型深入研究了大型语言模型的广泛语义理解能力向图像生成任务的转移。其核心是使用大型语言模型(例如Llama V2)对长格式文本进行编码,然后使用LoRA进行微调,以在生成任务中对齐文本-图像特征空间。为了便于长文本语义对齐的训练,我们还策划了一个高质量的段落图像对数据集,即ParaImage。该数据集包含少量高质量,精心注释的数据,以及使用视觉语言模型生成的具有长文本描述的大规模合成数据集。实验表明,ParaDiffusion在ViLG-300和ParaPrompts上优于最先进的模型(SD XL, DeepFloyd IF),在文本忠实度方面实现了高达45%的人类投票率提高。
代码和数据可在https://github.com/weijiawu/ParaDiffusion找到。

一、引言
近年来,文本到图像(Text-to-Image, T2I)生成模型取得了令人瞩目的进展。Stable Diffusion、DALL-E2、Imagen 等模型已经能够根据简短的文本描述生成高质量的图像。然而,当面对长达数百个单词的复杂段落描述时,这些模型仍然难以实现良好的语义对齐,无法准确地将所有提及的对象、属性和空间位置都体现在生成的图像中。
为了解决这一挑战,来自浙江大学、快手科技和新加坡国立大学的研究团队在 International Journal of Computer Vision (IJCV) 2025 上发表了名为 "Paragraph-to-Image Generation with Information-Enriched Diffusion Model " 的论文,提出了 ParaDiffusion 模型,首次系统性地探索了段落到图像生成任务。
二、问题分析:现有方法的局限性
论文深入分析了现有 T2I 模型在处理长文本时面临的两大核心挑战:
2.1 数据层面的限制
主流的公开数据集(如 LAION-5B)提供的文本描述过于简单,平均只有约 11 个单词。这种简短的描述无法为模型提供学习复杂语义对齐所需的监督信号。研究人员发现,LAION 数据集中 92% 的文本描述少于 25 个单词,这严重限制了模型理解和生成复杂场景的能力。
2.2 架构层面的限制
- ****Token 数量限制:****Stable Diffusion 和 DALL-E2 使用的 CLIP 文本编码器最多只支持 77 个 token。虽然 DeepFloyd 和 PIXART-α 尝试将其扩展到 128 个 token,但仍远远不够处理长段落。
- ****预训练数据不匹配:****T5-XXL 是在纯文本数据上训练的,没有图像-文本对的先验知识。直接冻结使用这类模型可能不是最优解决方案。
- ****解码器-only 架构的适配问题:****现有工作普遍认为解码器-only 架构(如 Llama)不擅长特征提取和映射任务,因此只探索了编码器-解码器架构(如 T5)。
三、核心创新点
ParaDiffusion 从数据和算法两个层面提出了系统性的解决方案:
3.1 算法创新:语言模型适配策略
论文首次提出使用 Llama V2(7B 参数的解码器-only 大语言模型) 作为文本编码器,支持高达 512 个 token 的长文本输入。
关键技术:段落-图像对齐学习与语言模型适配(Paragraph-Image Alignment Learning with Language Model Adaptation)
与先前方法直接冻结 LLM 权重不同,ParaDiffusion 采用 LoRA(Low-Rank Adaptation) 技术对 Llama V2 进行高效微调。这种方法的优势在于:
- ****保留语义理解能力:****冻结预训练权重,防止知识过拟合到简单的文本-图像语义
- ****高效训练:****仅需训练少量参数(约 0.51%),计算资源需求低
- ****无额外推理成本:****LoRA 参数可以合并到原始权重中
3.2 数据创新:ParaImage 数据集

论文构建了高质量的段落-图像配对数据集 ParaImage,包含两个子集:
ParaImage-Big(330 万张图像)
- 从 LAION-Aesthetics 和 SAM 数据集筛选高质量图像
- 使用 CogVLM 自动生成长文本描述
- 平均描述长度约 133 个单词,超过 70% 的描述超过 100 个单词
ParaImage-Small(3000 张图像)
- 从 65 万张高质量图像中精心挑选
- 专业标注人员手工撰写详细描述
- 用于最终的质量微调阶段
数据集统计对比

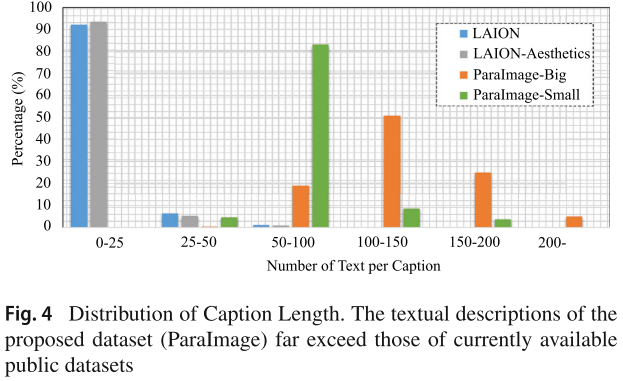
|-------------------------|--------------|----------------|---------------|---------------|
| 数据集 | 图像数量 | 短边分辨率 | 平均词数 | 平均名词数 |
| LAION | 23亿 | 537.2 | 11.8 | 6.4 |
| LAION-Aesthetics | 62.5万 | 493.6 | 11.3 | 6.8 |
| ParaImage-Big | 330万 | 771.3 | 132.9 | 46.8 |
| ParaImage-Small | 3100 | 1326.2 | 70.6 | 34.2 |
3.3 三阶段训练策略
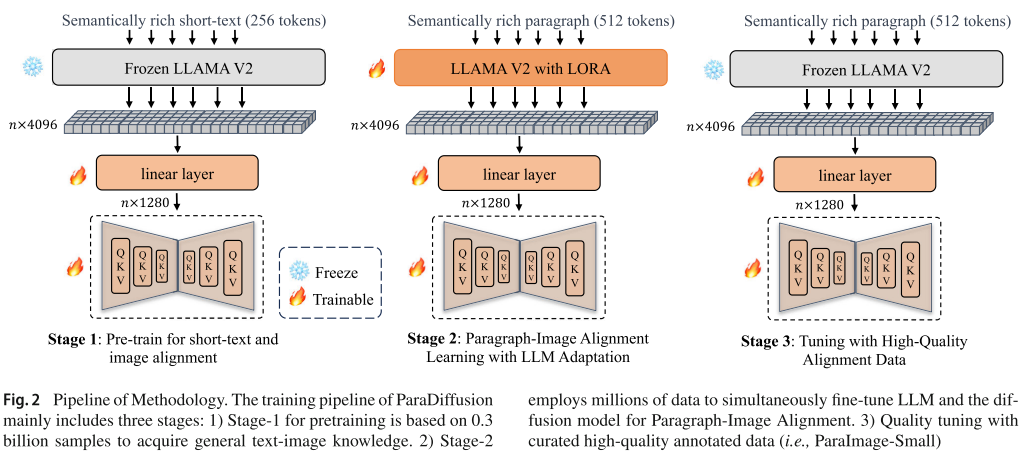
ParaDiffusion 采用渐进式的三阶段训练策略:
- ****Stage 1 - 短文本-图像对齐预训练:****使用 3 亿样本训练 U-Net(1.3B 参数),冻结 Llama V2。训练从 256 分辨率开始,逐步提升到 512。
- ****Stage 2 - 段落-图像对齐学习:****使用 ParaImage-Big 数据集,同时微调 LLM(使用 LoRA)和扩散模型,支持 512 个 token。
- ****Stage 3 - 高质量数据微调:****使用 ParaImage-Small 的 3000 张精选图像进行质量微调,以较小的学习率提升生成质量。
3.4 ParaPrompts 评估集
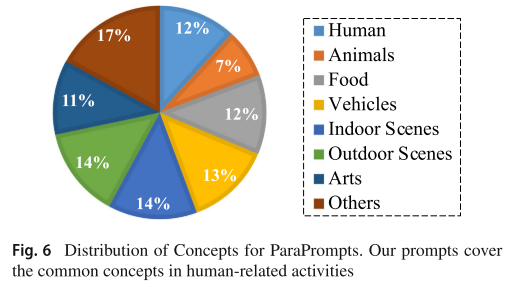
鉴于现有评估基准主要针对短文本,论文引入了 ParaPrompts------包含 400 个长文本描述的评估集。这些提示覆盖 8 个场景类别(人物、动物、食物、车辆、室内场景、室外场景、艺术、其他),其中超过 40% 的提示超过 100 个单词。
四、实验结果与分析
4.1 定量评估结果
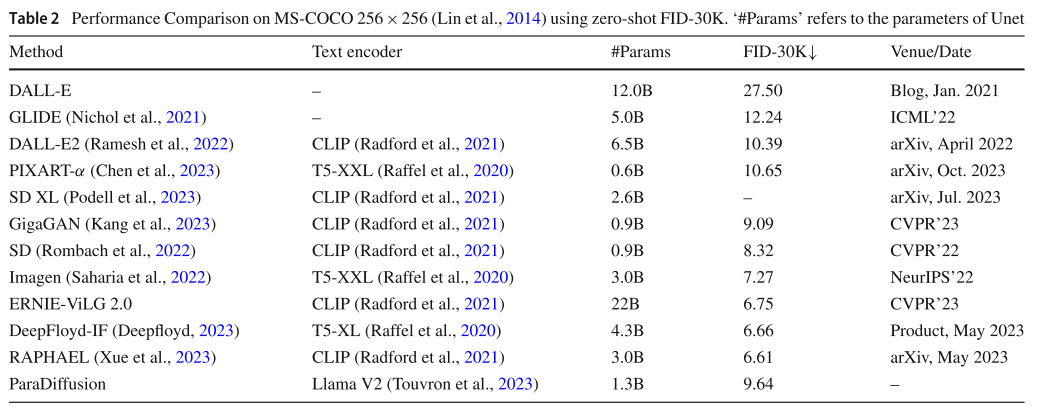
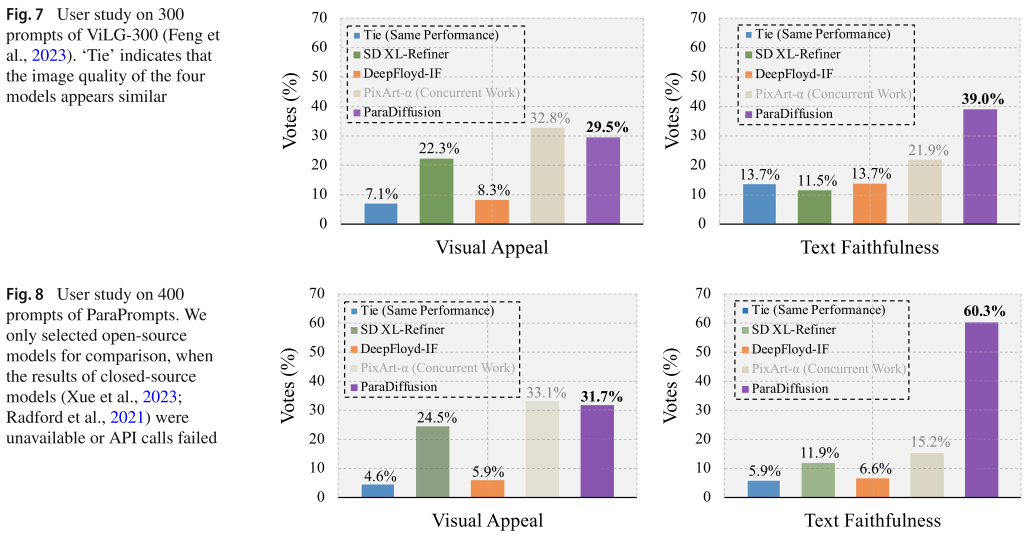
论文在多个基准上进行了全面评估:
主要性能对比
|-------------------|-----------------------|----------------|
| 评估指标 | ParaDiffusion | 其他最优模型 |
| ParaPrompts 文本忠实度 | 60.3% | ~10-15% |
| 句子级精度 | 51.3% | 25.8%-29.4% |
| MS-COCO FID-30K | 9.64 | 6.61-10.65 |
| ViLG-300 文本忠实度 | 39.0%(最高) | 11.5%-21.9% |
4.2 与布局生成方法的对比

论文还将 ParaDiffusion 与基于布局的生成方法(如 LLM Blueprint、LLM-grounded Diffusion)进行了对比。这些方法先使用 LLM 生成边界框布局,再进行条件生成。实验表明 ParaDiffusion 在视觉效果和文本忠实度两方面都显著优于布局方法,主要原因是:
- 布局方法依赖的基础模型(如 SD 1.5)性能较弱
- 边界框条件生成在处理重叠对象时存在困难(如"船上的人"场景)
- 两个相同对象的边界框过度重叠时,往往只能生成一个
4.3 消融实验
论文进行了详尽的消融实验,验证了各组件的有效性:
- ****LoRA 微调效果:****相比冻结 LLM,使用 LoRA 带来约 5% 的人类投票提升。最优配置为 r=64, α=32。
- ****描述长度影响:****随着描述长度增加,文本忠实度显著提升。150 词的描述比 10 词的描述在投票率上高出约 32%。
- ****数据质量影响:****ParaImage-Small 在视觉效果评估中获得 54.7% 的最高投票率。
- ****训练阶段分析:****Stage 2 带来约 50% 的提升,Stage 3 在视觉效果上额外提升约 70%。
4.4 训练效率
值得注意的是,ParaDiffusion 的训练成本相对较低:
- 整个训练过程仅需 56 块 A100 GPU 运行 8 天
- Stage 1 预训练需要 5 天
- Stage 2 段落对齐学习仅需 2 天
五、局限性与未来方向
尽管 ParaDiffusion 取得了优异的性能,论文也诚实地指出了一些局限性:
- ****推理速度:****尚未针对速度进行优化,可以通过 ODE 求解器或一致性模型进一步加速
- ****生成质量:****仍存在一些不理想的生成案例,如人体结构异常、数量错误等
- ****改进方向:****可从数据层面增加更多高质量图像,从算法层面引入几何和语义约束
六、总结
ParaDiffusion 是段落到图像生成领域的重要开创性工作,其主要贡献可以总结为:
- ****问题定义:****首次系统性地定义和探索了段落到图像生成任务
- ****技术方案:****提出了使用 LoRA 微调解码器-only LLM 的有效策略,支持 512 token 长文本
- ****数据贡献:****构建了 ParaImage 数据集,填补了长文本-图像配对数据的空白
- ****性能突破:****在文本忠实度方面实现了高达 45% 的相对提升
- ****开源贡献:****代码和数据已在 GitHub 开源(github.com/weijiawu/ParaDiffusion)
这项工作为理解和生成复杂视觉场景开辟了新的研究方向,对于需要精确控制图像内容的应用场景(如设计、创意产业、教育等)具有重要的实用价值。