作者: 我是人间不清醒 原文来源: https://tidb.net/blog/6638f594
1、 场景
业务综合宽表是报表生成、大屏幕展示和数据计算处理的核心数据结构。目前,这些宽表存储在Starrocks系统中,但该系统存在显著的性能瓶颈。例如,在高峰时段,查询性能(QPS)仅为20,99th百分位响应时间长达2.5分钟,且CPU和内存资源接近饱和。特别是在2024年,系统多次遭遇后端内存耗尽(OOM)的情况,导致需要手动干预才能恢复正常运行。鉴于Starrocks系统的版本较旧,我们正在考虑对其进行升级或者迁移到Tidb集群中。
为了评估升级Starrocks系统或迁移到TiDB集群的可行性,我们对同一环境下的TiDB集群进行了压力测试。测试结果表明,TiDB集群的性能表现超出了我们的预期,因此我们决定将业务综合宽表迁移到TiDB集群。
2、 宽表信息
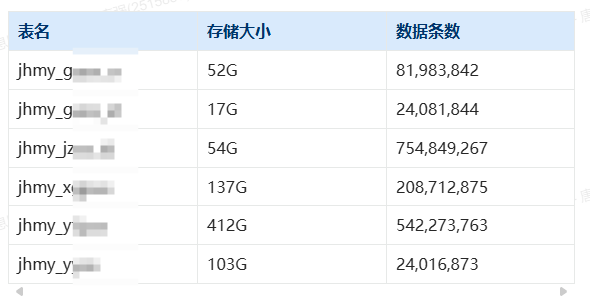
3、 集群配置
Starrocks 版本2.3.0 a9bdb09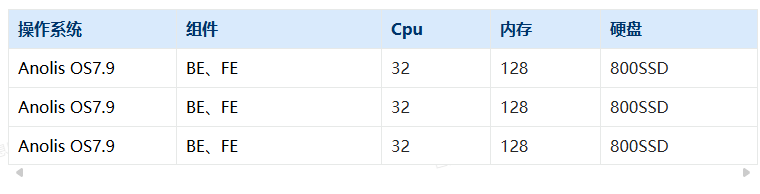
Tidb 版本 8.0.11-TiDB-v8.1.0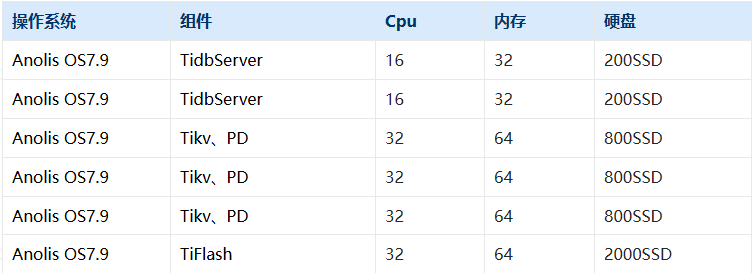
4、 Sql查询对比
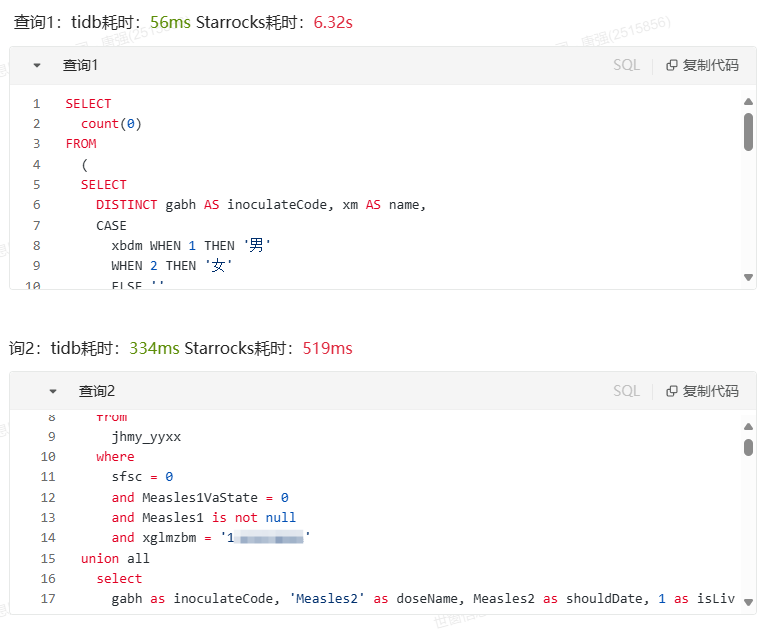
\
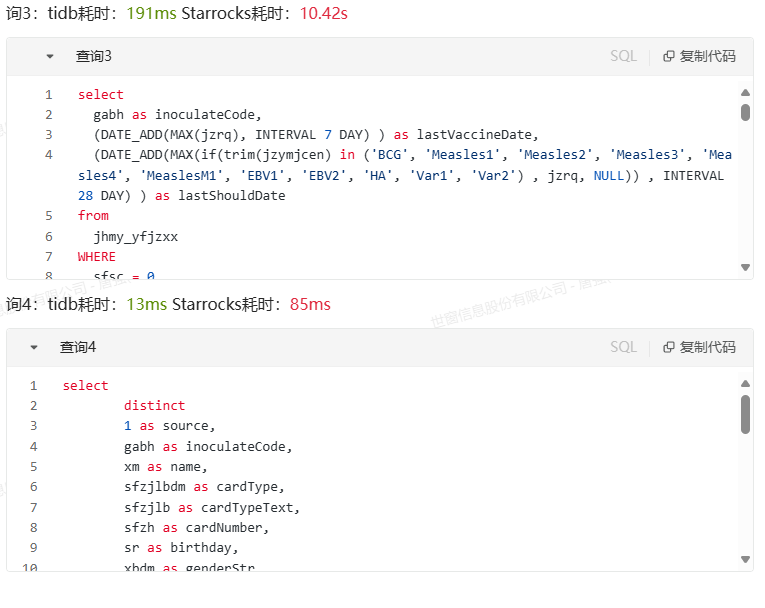
5、Jmeter压测对比
压测准备:windows11 16核32G 安装jmeter
教程: Jmeter保姆级安装教程(超详细建议收藏加关注)_jmeter安装详细教程-CSDN博客
SQL语句准备:研发提供的复杂sql查询
线程配置:线程数200 ramp-up时间 10,持续300s;10秒钟拉起200个进程,持续300s
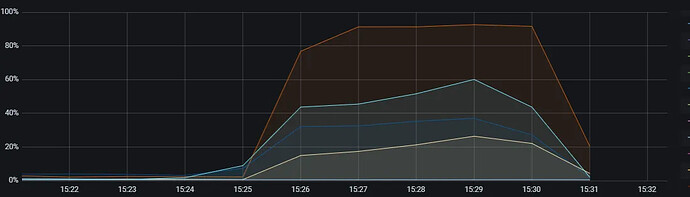
Tidb和Starrocks服务器CPU情况:
\
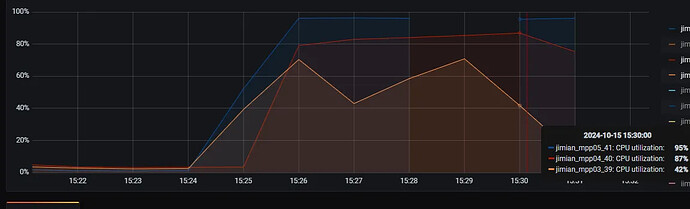
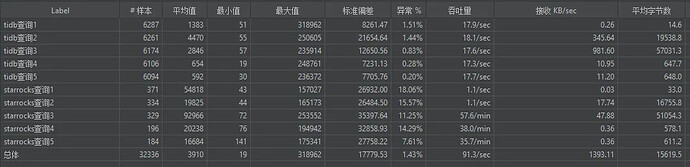
6、结果
根据测试结果分析,Tidb在压力测试期间,除TidbServer的CPU使用率较高外,TiKV和TiFlash的表现均符合预期。然而,Starrocks的三台服务器CPU使用率过高,且吞吐量指标未能达到理想状态。
7、后续规划
鉴于Starrocks系统的性能瓶颈和资源饱和问题,以及TiDB集群在压力测试中表现出的优越性能,我们决定将业务综合宽表从Starrocks迁移到TiDB集群,并将Starrocks资源陆续释放,实现降本增效