为什么会有BufferPool
MySQL在对数据进行增删改操作的时候,不可能直接更新磁盘上的数据,对磁盘进行随机读写十分缓慢.实际上在对数据库执行增删改操作的时候,实际上主要是针对内存里的BufferPool中的数据,数据最终都是要放在磁盘中的.
增删改操作首先就是针对内存中BufferPool执行,同时配合后续的RedoLog,刷盘机制等操作.所以BufferPool就是数据库的一个内存组件,里面缓存了磁盘中真实的数据.
BufferPool的大小
BufferPool默认是128MB大小,实际生产环境可以对BufferPool大小进行调整,配置文件在/etc/my.cnf 中
数据是如何存放在BufferPool中的
数据页 与 缓存页
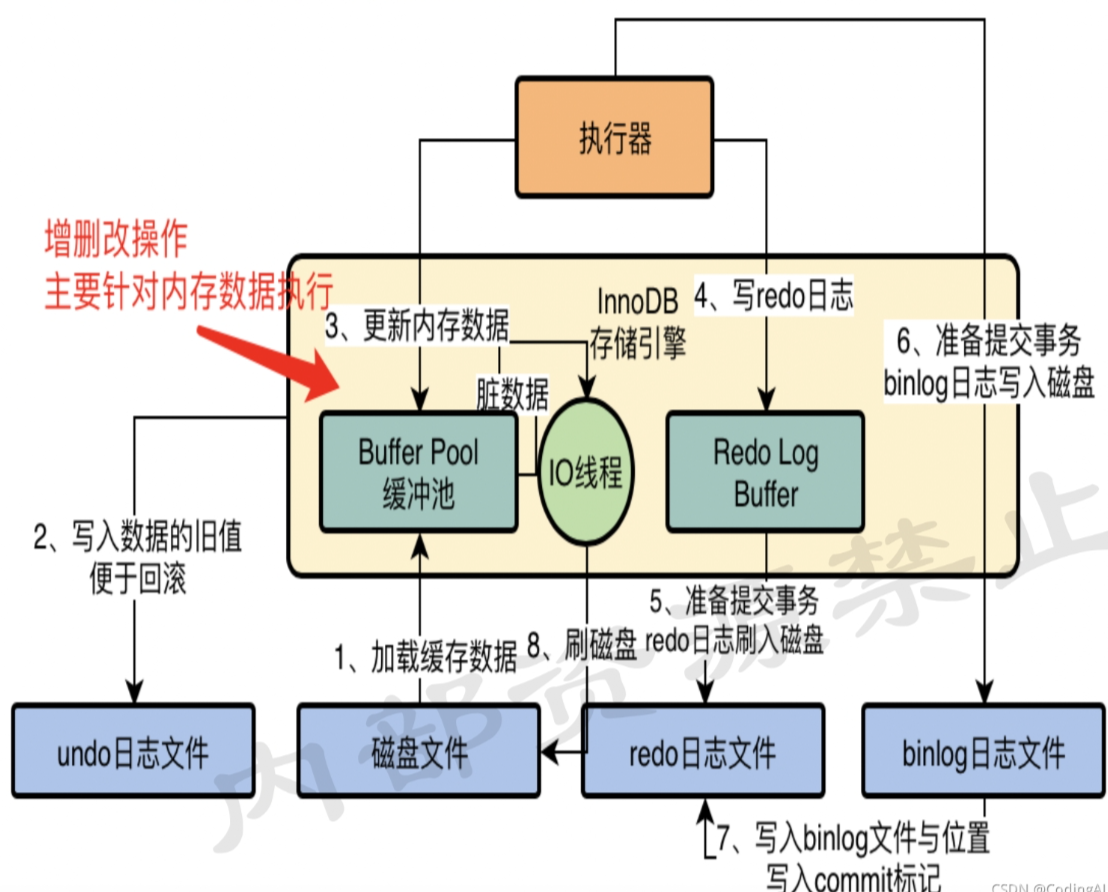
MySQL对数据抽象出来一个数据页的概念,他是把很多行数据放在了一个数据页里,也就是说我们磁盘文件中就是会有很多的数据页,每一页放了很多行数据,一个数据页的大小为16KB.** 以下我们将数据页称为Page, 数据行称为row**
更新一条数据,会在磁盘中找到这一条数据对应的Page,把它加载到BufferPool中,BufferPool中存放着一个个的Page.缓存页和Page一 一对应,并且还存储着每个缓存页的描述数据,这使得BufferPool大小会超出128MB.
BufferPool的初始化
- 申请空间: MySQL只要一启动,就会按照你设置的BufferPoolSize大小稍微加大一点去操作系统申请内存区域.
- 划分空间: 数据库会按照默认的CachePage16KB大小以及对应的800字节左右的描述数据大小,在BufferPool中划分一个一个的CachePage和描述数据,此时BufferPool为空,当我们执行增删改查操作的时候,才会把Page从DB中读取,并缓存到BufferPool中.
Free链表
Free链表是一个双向链表,存储着BufferPool中空闲的CachePage描述数据块.比如MySQL刚启动,所有的CachePage对应的++描述数据块都会存储到Free链表中++.
Free链表有一个基础节点,这个节点引用Free的头节点与尾节点,包括一个Count字段存储空闲块的个数.
如何将DB中的Page读取到CachePage中?
借助Free链表,从Free链表中获取一个描述数据块,把DB中读取到的Page存储到描述数据块中对应的CachePage中,同时把描述数据写入数据块中,并将数据块从free链表移除.
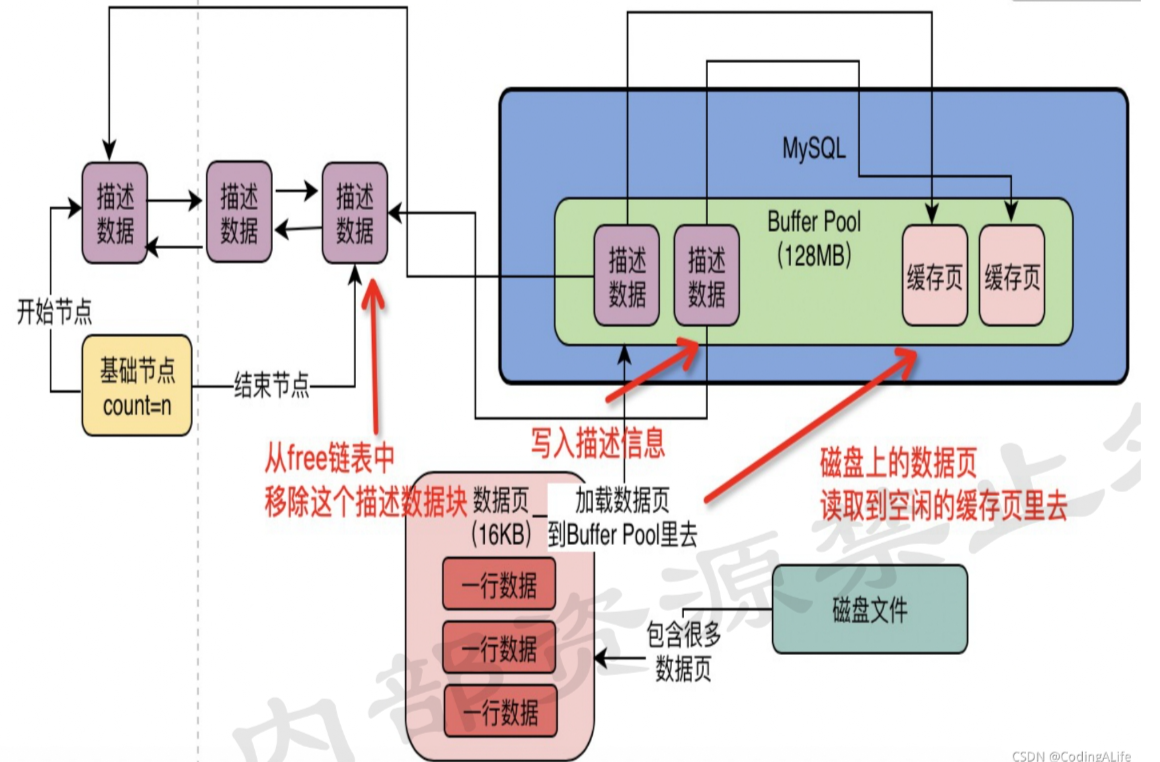
数据页缓冲Hash表
如何确定Page是否已经被缓存?
数据库会有一个Hash表结构,会使用表号+Page号作为key,然后CachePage为value.
当你要使用一个Page的时候,通过表号+Page号先从Hash表中查询,如果没有,就从DB中读取Page,如果有,直接将value返回.
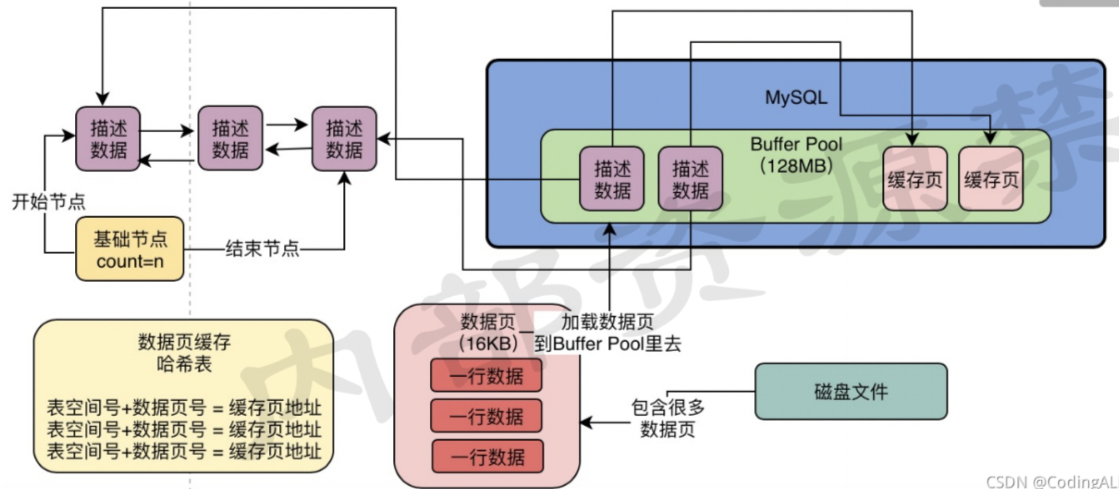
Flush链表
我们对缓存中的CachePage进行增删改操作之后,此时的数据和DB中的数据不一致,我们就说CachePage是脏页,脏数据.这些脏页的数据都是要被刷回DB中的.
在BufferPool中,有一个Flush链表,本质是通过CachePage的数据描述块中的两个指针,让被修改的CachePage的描述数据块,组成一个双向链表,后续都会刷新到DB中.
所以: Flush链表是用来记录脏CachePage的.
BufferPool的缓存淘汰机制
LRU链表
我们从磁盘中加载一个Page到BufferPool时,就把这个CachePage描述数据块放到LRU链表的头部,最近被加载使用的CachePage描述数据块都会放到LRU链表的头部;如果有一个CachePage的描述数据块在链表的尾部,如果它被访问加载,就又会重新移到链表的头部.
当CachePage被存满的时候,我们需要淘汰一定数量的CachePage以加载新的Page,此时就直接在LRU链表的尾部找到缓存描述数据块,它一定是最近最少访问的CachePage,然后将该CachePage刷回DB中,并将需要的Page加载到空闲出来的CachePage中.
LRU的弊端
- MySQL的预读机制:当你从磁盘上加载一个数据页的时候,他可能会连带着把这个数据页相邻的其他数据页,也加载到缓存里去!举个例子,假设现在有两个空闲缓存页,然后在加载一个数据页的时候,连带着把他的一个相邻的数据页也加载到缓存里去了,正好每个数据页放入一个空闲缓存页! 实际上只有一个缓存页是被访问了,另外一个通过预读机制加载的缓存页,其实并没有人访问,此时这两个缓存页可都在LRU链表的前面。
- 全表扫描机制:能导致频繁被访问的缓存页被淘汰的场景,那就是全表扫描; 此时他没加任何一个where条件,会导致他直接一下子把这个表里所有的数据页,都从磁盘加载到Buffer Pool里去。 这个时候他可能会一下子就把这个表的所有数据页都一一装入各个缓存页里去!此时可能LRU链表中排在前面的一大串缓存页,都是全表扫描加载进来的缓存页!那么如果这次全表扫描过后,后续几乎没用到这个表里的数据呢? 此时LRU链表的尾部,可能全部都是之前一直被频繁访问的那些缓存页! 然后当你要淘汰掉一些缓存页腾出空间的时候,就会把LRU链表尾部一直被频繁访问的缓存页给淘汰掉了,而留下了之前全表扫描加载进来的大量的不经常访问的缓存页!
LRU优化 --基于冷热分离
真正的LRU链表,会被拆分为两个部分,一部分是热数据,一部分是冷数据,这个冷热数据的比例是由innodb_old_blocks_pct参数控制的,他默认是37,也就是说冷数据占比37%。
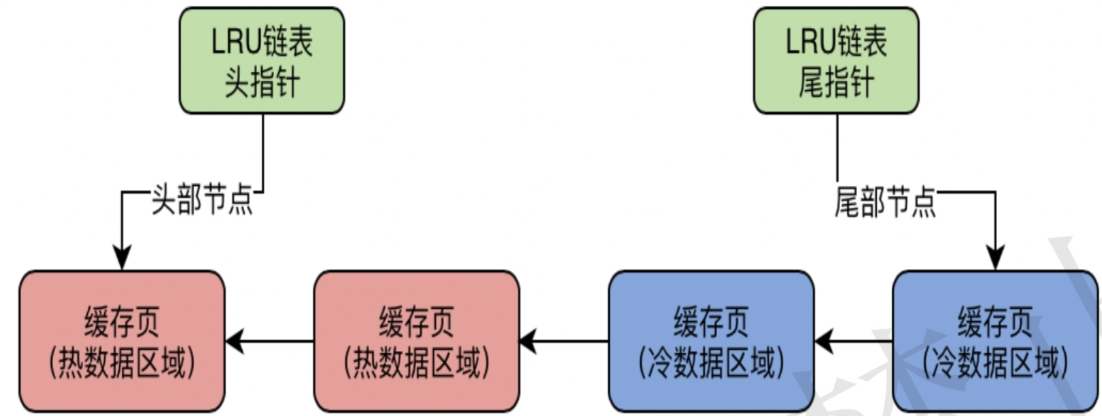
**原理:**数据页第一次被加载到缓存页之后,这个缓存页是放在LRU链表的冷数据区域的头部的,然后必须是1s过后访问这个缓存页,他才会被移动到热数据区域的链表头部。
因为那种预读机制以及全表扫描机制加载进来的数据页,大部分都会在1s之内访问一下,之后可能就再也不访问了,所以这种缓存页基本上都会留在冷数据区域里。然后频繁访问的缓存页还是会留在热数据区域里。当你要淘汰缓存的时候,优先就是会选择冷数据区域的尾部的缓存页,这就是非常合理的了!
在LRU链表的冷数据区域中的都是什么样的数据呢?
大部分应该都是预读加载进来的缓存页,加载进来1s之后都没人访问的,然后包括全表扫描或者一些大的查询语句,加载一堆数据到缓存页,结果都是1s之内访问了一下,后续就不再访问这些表的数据了。
如果在Redis里存放了很多缓存数据,那么此时会不会有类似冷热数据的问题?应该如何优化和解决呢?
我们在设计缓存机制的时候,经常会考虑热数据的缓存预加载。
也就是说,每 天统计出来哪些商品被访问的次数最多,然后晚上的时候,系统启动一个定时作业,把这些热门商品的数据,预加载到Redis里 。 那么第二天是不是对热门商品的访问就自然会优先走Redis缓存了?15、定时刷新
并不是在缓存页满的时候,才会挑选LRU冷数据区域尾部的几个缓存页刷入磁盘,而是
有一个后台 线程,他会运行一个定时任务,这个定时任务每隔一段时间就会把LRU链表的冷数据区域的尾部的一些缓存页,刷入磁盘里去,清空这几个缓存页,把他们加入回free链表去!
这个后台线程同时也会在MySQL不怎么繁忙的时候,找个时间把flush链表中的缓存页都刷入磁盘中,这样被你修改过的数据,迟早都会刷入磁盘的!总结:
注意: 我们写SQL时对应表 + 行,在MySQL内部是表空间 + 数据页。
当我们操作增删改数据时,首先通过 "表空间号 + 数据页号" 作为key 去数据页缓存哈希表查一下,如果有说明已经缓存了,如果没有就读取数据页。读取数据页时:从free链表找到一个空闲的缓存页,从磁盘读取数据页到缓存页,写入描述数据,从free链表移除这个描述数据块。