目录
[2. 通过指定方式定位元素](#2. 通过指定方式定位元素)
[4. 关闭窗口](#4. 关闭窗口)
[7. 页面滚动](#7. 页面滚动)
一、Selenium的介绍
Selenium是一个非常强大的自动化测试工具,它支持多种编程语言,如Java、Python、C#等。Selenium可以模拟用户在浏览器中的行为,比如点击、输入、滚动等,从而实现对网页的自动化测试。本文将简要介绍在python中Selenium的基本使用方法。
二、环境准备
1.安装Selenium
通过pip命令安装Selenium库。具体的安装代码如下:
python
pip install selenium2.安装WebDriver
WebDriver是浏览器的自动化驱动程序。每种浏览器都应一个特定的WebDriver,不同的浏览器使用的驱动驱动程序各不同,需要根据自己的浏览器版本下载对应的WebDriver。
本文安装Chrome浏览器的驱动程序。
(1)查看当前使用的Chrome浏览器的版本号
打开Chrome浏览器 → 点击右上角的三个点(自定义及控制)→ 选择"帮助" → 进入"关于Google Chrome"页面。如图:
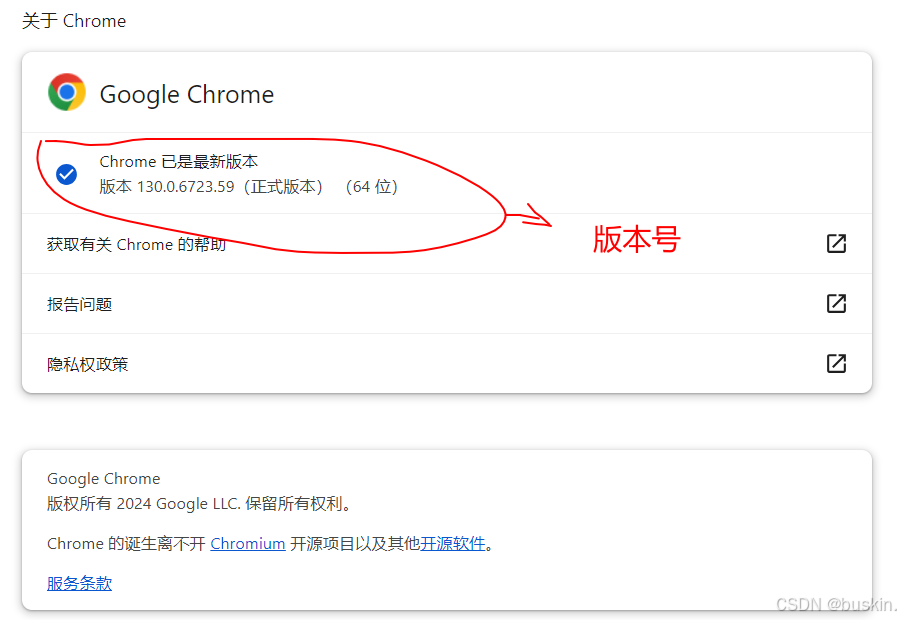
(2)访问Chrome WebDriver下载页面,下载与Chrome浏览器版本相匹配的WebDriver版本。

(3)解压WebDriver
(4)设置WebDriver路径 :将解压后的chromedriver可执行文件放置在系统PATH环境变量中的目录里。将Webdriver配置到系统环境变量中,以后在使用WebDriver时,就不需要重复指定WebDriver的执行路径。
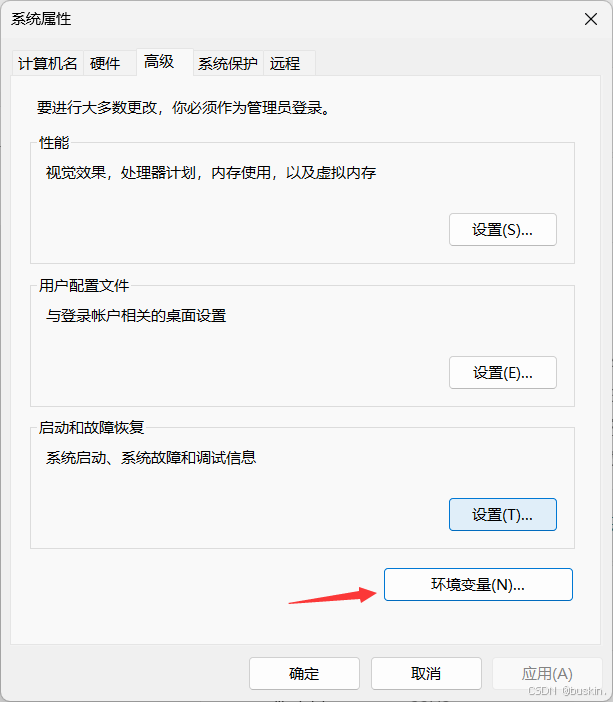
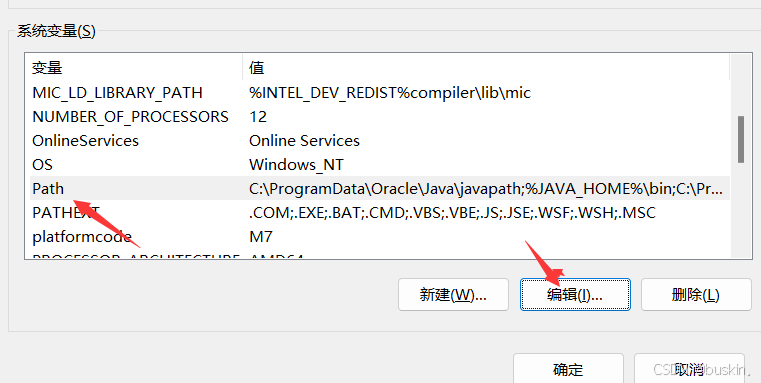
三、元素定位
1.常用定位元素的方法
|-------------------------------------|-------------------|
| find_element() | 通过指定方式定位元素 |
| find_element_by_id()) | 通过id属性定位元素 |
| find_element_by_name() | 通过name属性定位元素 |
| find_element_by_xpath() | 通过XPath的路径表达式定位元素 |
| find_element_by_link_text() | 通过连接文本定位元素 |
| find_element_by_partial_link_text() | 通过部分链接文本定位元素 |
| find_element_by_tag_name() | 通过标签名定位元素 |
| find_element_by_class_name() | 通过class属性定位元素 |
| find_element_by_css_selector() | 通过CSS选择器定位元素 |
[常用定位元素的方法]
2. 通过指定方式定位元素
find_element() 方法是定位单个元素的通用方法。find_element() 方法声明如下:
find_element(self, by=By.ID, value=None)该方法需要两个参数:一个是 By 类中的定位器策略(如 By.ID、By.XPATH 等),另一个是对应的定位值。其中self 是一个指向当前 webdriver 实例的引用,当你调用 find_element() 方法时,self 不需要你显式提供,它会自动传递。你只需要提供方法的参数。
|----------------------|-------------------|
| By.ID | 通过id属性定位元素 |
| By.NAME | 通过name属性定位元素 |
| By.CLASS_NAME | 通过class属性定位元素 |
| By.LINK_TEXT | 通过连接文本定位元素 |
| By.PARTIAL_LINK_TEXT | 通过部分链接文本定位元素 |
| By.CSS_SELECTOR | 通过CSS选择器定位元素 |
| By.XPATH | 通过XPath的路径表达式定位元素 |
[参数By支持的取值及其说明]
以下是 通过find_element() 方法的获取"百度一下这四个字"的示例 :
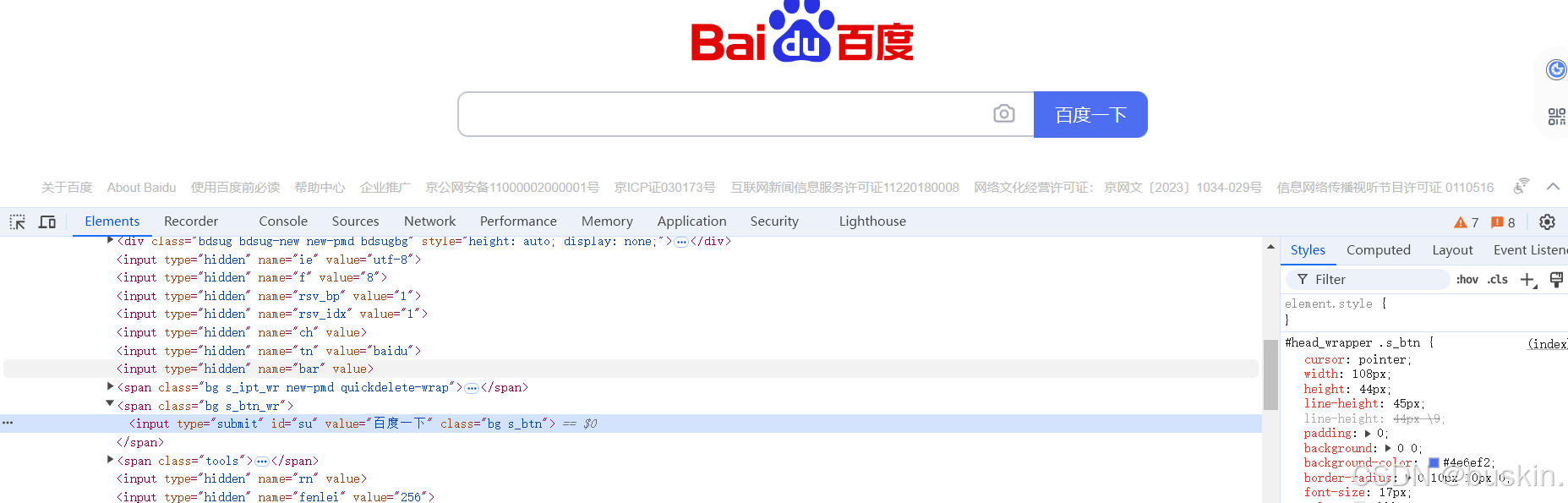
from selenium import webdriver
# 导入By类
from selenium.webdriver.common.by import By
# 已经将ChromeDriver放置在了系统的PATH环境变量中,
# Selenium将会自动寻找ChromeDriver并使用它来控制Chrome浏览器
driver = webdriver.Chrome()
# 打开一个网页
driver.get("http://www.baidu.com") # 移除了错误的HTML实体,确保URL正确
# 使用类名定位按钮元素
search_button = driver.find_element(By.CLASS_NAME, 's_btn')
# 获取按钮的value属性,即按钮上显示的文本
button_text = search_button.get_attribute('value')
print(button_text)
# 关闭浏览器
driver.quit()四、窗口操作
1.最大化浏览器窗口
在爬取某些需要全屏显示的网页内容时,我们可以最大化浏览器窗口。
python
driver = webdriver.Chrome()
driver.maximize_window()2.设置浏览器窗口大小
为浏览器窗口设置特定的尺寸,以确保网页内容按预期加载和显示。
python
driver.set_window_size(1000, 800) # 设置窗口宽度为1000px,高度为800px3.切换窗口或标签页
python
# 打开新窗口
driver.execute_script("window.open('http://example.com');")
# 获取所有窗口的句柄
window_handles = driver.window_handles
# 切换到新窗口
driver.switch_to.window(window_handles[n])切换回主窗口
python
# main_window_handle是主窗口的句柄
driver.switch_to.window(main_window_handle)4. 关闭窗口
关闭当前窗口
在爬虫中,我们有时会打开多个窗口,完成操作后需要关闭当前窗口。
python
driver.close()关闭所有窗口
在爬虫任务结束时,我们可以关闭所有打开的窗口。
python
driver.quit()五、页面操作
1.刷新页面
python
driver.refresh()2.返回前一页
python
driver.back()3.前进到后一页
python
driver.forward()4.获取当前页面URL
python
current_url = driver.current_url5.获取页面标题
python
page_title = driver.title6..截取当前页面截图
在爬虫中,我们有时需要验证页面内容是否正确加载,可以截取当前页面的截图。
python
driver.get_screenshot_as_file('screenshot.png')7. 页面滚动
滚动页面到指定元素的位置
element = driver.find_element(By.ID, 'footer')
driver.execute_script("arguments[0].scrollIntoView();", element)直接滚动到页面底部
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")