2024-10-21,由西北工业大学、西安联丰声学技术有限公司、南洋理工大学、萨里大学和中国科学院声学研究所创建了AudioSetCaps数据集,包含190万对来自AudioSet录音的音频-字幕对。这个数据集在音频-文本检索和自动音频字幕两项下游任务上展现了卓越的性能,证明了其生成字幕的高质量。值得注意的是,该数据标签流程使用开源API,并且可以在消费级GPU上运行。
一、研究背景:
随着音频语言模型(ALMs)的发展,音频感知领域取得了显著进展。然而,现有的ALMs在实现健壮的通用音频-语言表示和模拟人类对音频的理解方面面临挑战,这主要是因为训练时可用的音频-文本数据在数量和质量上的限制。
目前遇到困难和挑战:
1、构建大规模、高质量的音频-语言数据集需要大量的时间和劳动力,成本高昂。
2、现有的基于大型语言模型(LLMs)的流程在生成音频-文本数据时缺乏整合详细音频信息的能力。
3、尽管LLMs在自动化构建大规模音频-语言数据集方面取得了进展,但它们生成的字幕往往缺乏全面的声音信息,且数据分布不均衡,可能影响字幕质量。
数据集地址:AudioSetCaps|音频-语言多模态数据集|多模态数据数据集
二、让我们一起看一下AudioSetCaps数据集
AudioSetCaps是一个由190万对音频-字幕对组成的数据集,基于AudioSet的录音,通过自动化流程生成了细粒度的音频字幕。这个数据集旨在通过结合音频和语言模型,推动音频语言学习领域的发展。
数据集构建 :
包括音频内容提取、LLMs辅助字幕生成和字幕精炼三个部分。使用Qwen-Audio ALM提取音频内容,Mistral-7B LLM生成字幕,并采用LAION CLAP评估字幕质量。
数据集特点 :
1、大规模:包含190万对音频-字幕对。
2、细粒度:提取了详细的音频内容,包括声音、语音和音乐特征。
3、高质量:通过迭代过程生成准确代表音频内容的字幕。
4、开源:代码、数据和预训练模型均公开可用。
可以使用AudioSetCaps进行音频-文本检索和自动音频字幕等下游任务的训练和评估。
基准测试 :
在音频-文本检索和自动音频字幕任务上的实验结果表明,使用AudioSetCaps训练的模型在两项任务上均达到了最先进的性能。
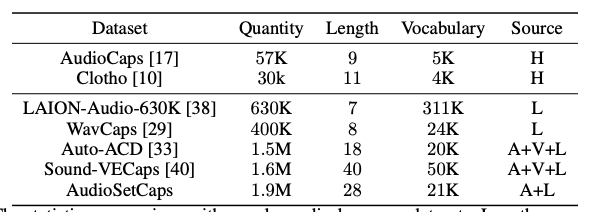
与流行的音频语言数据集的统计比较。长度:平均字幕长度;词汇量:字幕的词汇量大小。字幕来源:H(人类),A(音频模型),V(视觉模型),L(语言模型)。
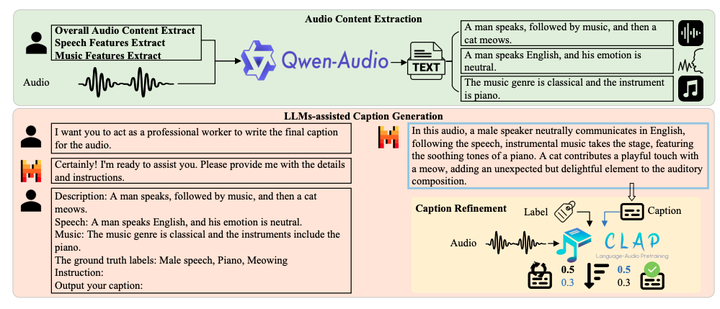
提出的自动音频字幕生成流程的概述。
三、让我们一起展望数据集应用:
应用场景一:
比如,我是一个游戏音频设计师。
我的工作日常是这样的:比如需要在游戏里加入一种特别的鸟鸣声,让游戏环境听起来更加生动。我得上网,去各种声音库搜索,输入关键词像"鸟鸣"、"森林鸟叫"这样的,但往往搜出来的结果一大堆,我得一个一个听,看哪个声音最接近我心目中的样子。有时候,声音库里没有我想要的,我还得自己跑到森林里去实地录音。这过程挺费时间的,尤其是在截止日期临近的时候,压力山大啊!
但是,有了AudioSetCaps这个神器之后,我的工作方式彻底改变了。
这个数据集好比给了我一个超级强大的声音搜索引擎。我只需要对着系统说:"嘿,我需要一种清脆的、像是在清晨阳光下,树叶间传来的鸟鸣声,用来配合游戏里一个关键场景" ,不出几分钟,系统就给我返回了好几个视频,里面的鸟鸣声跟我想要的一模一样。我直接下载了最满意的那段声音,放到游戏里,效果棒极了!玩家们在游戏中的体验也因此提升了不少。
这就好比,以前我得自己翻山越岭去找一朵特定的花,现在我只要告诉花店老板这花长啥样,他们就能直接从库存里拿出我要的花来。这不仅节省了我大量的时间,也让我能把更多的精力放在创意和设计上,而不是耗费在找声音这种繁琐的工作上。
现在我可以把更多的时间用在创造更好的游戏体验上,而不是在找声音上打转。
应用场景二:
比如,我是个科技迷,对人工智能的最新发展特别感兴趣。
比较尴尬的是,我的英语不是很溜。有一天,我在网上发现了一个超棒的英文演讲,是某个AI领域的大牛在TED上谈论他的最新研究成果。我特想知道他在讲啥,但那些专业术语和快速的语速让我有点跟不上。
通常我会找有字幕的版本,或者用那种自动翻译的工具,但这些工具有时候翻译得不太准确,字幕和说话的内容对不上,看得我一头雾水。
但现在,我有了AudioSetCaps这个秘密武器。我点开视频,启动了AudioSetCaps的字幕生成功能。这个系统就像个专业的同声传译,它开始仔细听演讲者的每一句话。演讲者讲到了深度学习的最新突破,讨论了神经网络的优化,还提到了一些我之前没听过的AI应用案例。AudioSetCaps不仅捕捉到了这些复杂的专业术语,还把演讲者的那种激情和对未来的憧憬通过字幕传达得清清楚楚。
我就看着屏幕上的字幕,感觉自己就像是在现场一样。我不仅能跟上演讲者的思路,还能理解他讲的那些复杂的技术细节。同时激发我的思考,这些新知识能不能用到我自己的项目里。
演讲结束后,我还能回头去看那些我一开始没太理解的部分。AudioSetCaps的字幕就像是我的个人学习助手,帮我理解了这个领域的最新发展,还提高了我的英语水平。这种感觉,简直就像开了挂一样!