论文地址:https://arxiv.org/pdf/2408.16707
原本地址:https://mp.weixin.qq.com/s/gL8ZTnpS0xJy7Qc73QEaGw
摘要
本文研究了大型语言模型(LLM)如何解释历史股票回报,并将其预测与众包股票排名平台的估计进行了比较。虽然股票回报表现出短期逆转,但LLM的预测过于外推,对近期表现的权重过高,与人类的预测类似。相对于历史和未来的实现回报,LLM的预测显得乐观。当提示80%置信区间的预测时,LLM的反应比调查证据更好地校准,但对异常值持悲观态度,导致预测分布偏倚。研究结果表明,法学硕士在预测预期回报时表现出普遍的行为偏差,但在衡量风险方面比人类做得更好。
简介
生成性人工智能(AI)在交通、医学和经济等领域展现出巨大潜力,尤其在金融决策中,通过客观分析大量信息提升投资者、分析师和审计师的表现。大型语言模型(LLMs)可能嵌入有害的社会偏见,模仿人类决策时也可能包含认知偏差,如过度外推和过于乐观的预测。本研究评估ChatGPT-4在提供历史回报数据时是否表现出行为偏差,特别是对短期回报的过度外推。
研究发现,投资者对资产未来回报的预期与近期回报呈正相关,且对最近回报的权重最大。ChatGPT在预测股票排名时,表现出与人类相似的依赖历史数据的方式,且其预测结果与人类的预测存在显著相关性。尽管存在短期回报反转的现象,ChatGPT的外推仍然是反生产性的,导致其排名与未来表现呈负相关。
人类在处理收益时对负收益的重视程度高于正收益,负面表现对预期的影响更持久;而GPT-4则更重视近期正收益,且对远期负收益的处理与人类相似。GPT-4在分析价格图表时,仍然依赖于过去的收益数据进行预测。
在对S&P500的市场回报预测中,GPT-4和Claude模型的情绪特征高度相关(0.78),表明相似的人类行为在其响应中体现。LLM的预期收益预测普遍高于历史实际收益,GPT-4的预期收益为2.2%,显著高于历史均值1.4%和实际收益1.15%。GPT-4的80%置信区间预测准确率为76.9%,低于历史10%和90%分位数的简单预测,但其误差程度低于CFO调查结果。GPT-4在低预期和高预期预测中均表现出悲观倾向,低预期显著低于历史10%分位数,高预期也低于历史90%分位数。
LLM的股票回报预测与历史百分位数回归,发现90th百分位数的加载最大,显示出过度乐观的预测倾向。低预测和高预测均显著加载对应百分位数,但高预测对高百分位数的敏感性低,显示出对分布尾部的悲观预期。LLM的预测表现出历史回报的过度外推,尽管风险评估优于人类,但在预期表现上过于乐观,尾部分布略显悲观,导致预测分布相较历史数据呈正偏态。研究表明LLM在金融决策中可能重现人类行为,但对数字数据的解读并不完全理性,需关注潜在偏见。
数据收集:投资者和LLM股票收益预测
**数据来源。**人类股票预测数据来自Forcerank平台,参与者每周对十只股票进行排名,预测下周的回报表现。
**样本信息。**包含1,283个周赛,涉及200个独特股票代码,使用每只股票在第t周的平均得分作为投资者共识预期的代理。
**预测方法。**分析基于过去12周的滞后股票回报,使用GPT-4生成相应的排名和信心度,输出格式为JSON。
**避免偏差。**通过匿名化提示,确保不包含未来结果,防止前瞻性偏差。
**市场表现预测。**使用AAII投资者情绪调查数据,测量市场的牛市、熊市和中性预期。
**LLM市场预测。**提供S&P 500指数的月度回报数据,询问未来六个月市场方向及信心度,输出格式为JSON。

大型语言模型(LLMs)能够解读图像和数值数据,并预测股票表现。使用蜡烛图展示10只股票的每日价格数据,颜色区分涨跌。提交图像查询给ChatGPT-4,要求对未来一周的股票收益进行排名,输出格式为JSON。研究LLMs如何预测未来收益分布,参考CFO调查。通过随机选择100个月的股票数据,分析历史收益并生成下月收益预测。统计样本包含1283个Forcerank比赛,12807个股票观察,200只独特股票。调查显示,市场情绪偏向乐观,ChatGPT情绪评分为0.37。

大型语言模型期望形成
大型语言模型(LLM)通过深度学习模拟人脑,利用数十亿神经元和海量文本数据发现模式,形成"黑箱"特性。LLM在数值任务上表现出意外的能力,依赖统计学习识别数字关系和逻辑推理,但可能导致错误响应。训练数据中的人类讨论可能引入行为偏见,影响LLM的数值反应。研究者使用自编码器分析LLM神经元的激活模式,揭示其学习的特征。本研究关注LLM如何解读历史股票收益的时机和幅度,并探讨低(10%)和高(90%)预测是否代表不同的特征。
历史回归时间-外推
研究人类与LLM(大型语言模型)在历史回报时间解读上的表现预测。首先,模拟Forcerank竞赛环境,要求GPT-4预测十只股票的相对表现。其次,分析耶鲁金融中心和美国个人投资者协会的市场表现调查,时间范围从一个月到一年。重点在于LLM是否以类似人类的方式从近期回报中进行外推。
绩效等级分析
研究分析了滞后收益对预测和实际收益表现的影响,使用回归模型。人类预测未来表现受过去收益强烈影响,过去12周的收益系数普遍为正且显著,近期收益的系数高于远期收益。ChatGPT-4的预测显示对最近收益的过度依赖,前一周的系数是两周前的10倍,且系数随时间递减。人类的R平方值(3.4%)显著低于ChatGPT(35.2%),因人类有更多信息可用。结果表明,过去收益在预测未来表现中对人类和LLM的影响相似。
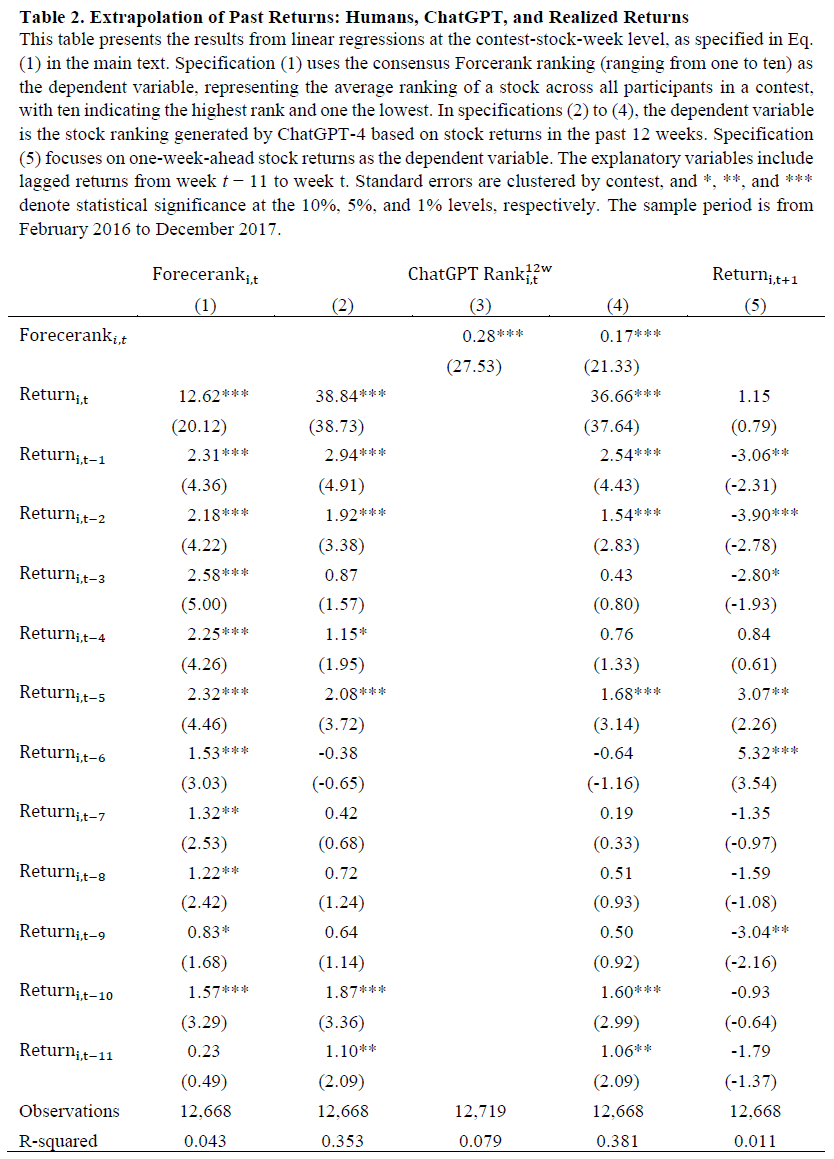
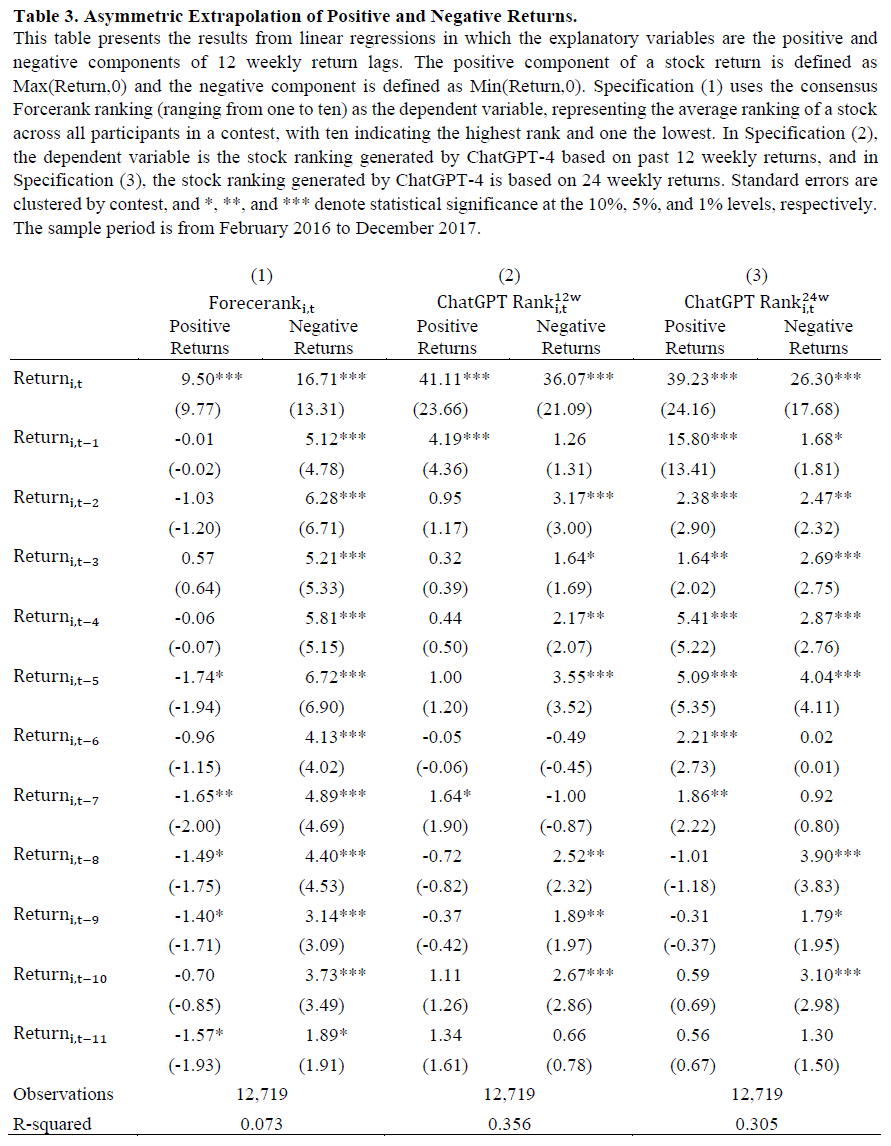

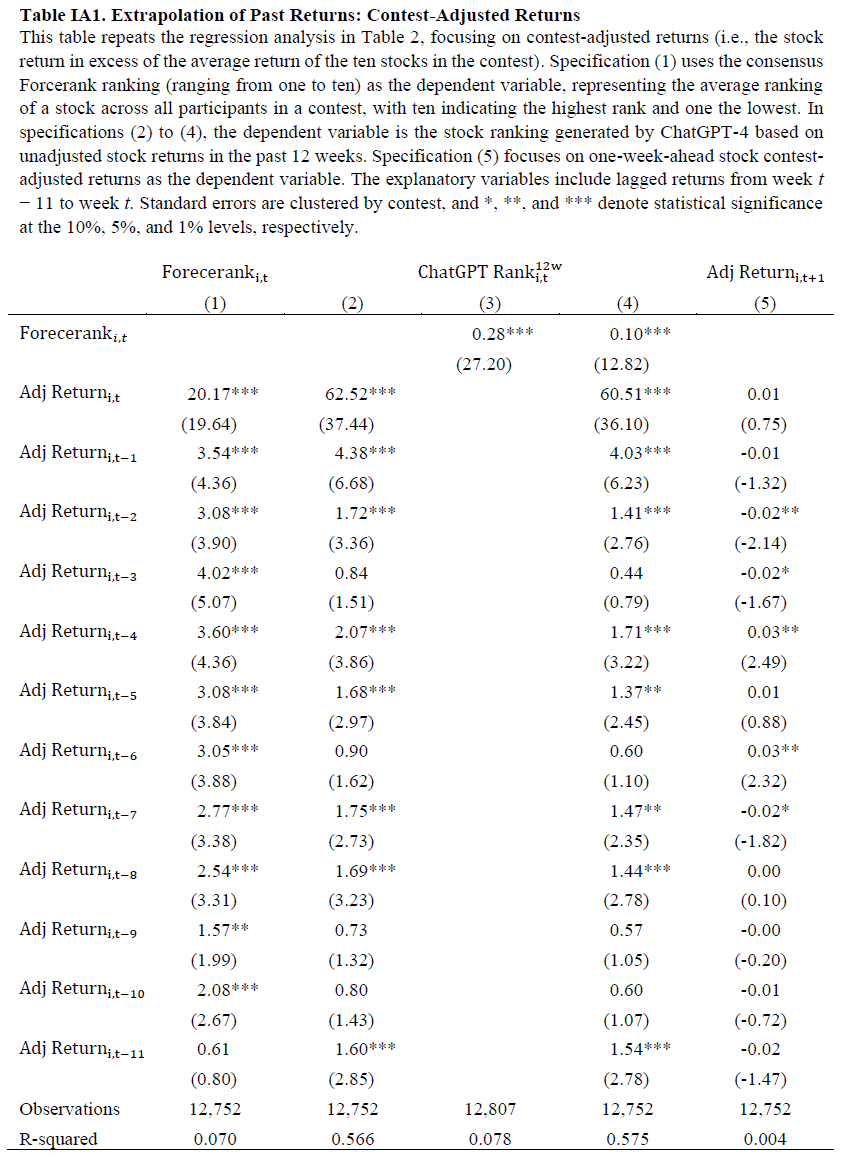
人类和GPT-4的排名显著相关,且在控制滞后收益后关系依然存在,表明两者对收益的依赖超出线性外推模型的捕捉。短期收益反转现象与人类和GPT-4的预期相反,周收益呈现短期反转,滞后期的负系数显著。提供更多数据(24周滞后收益)并未显著减少对近期收益的重视。人类对收益的反应存在不对称性,负收益的反应更强,且滞后效应持续较长时间。GPT-4对近期正收益的外推更强,但对远期负收益的反应与人类相似,显示出更对称的反应模式。在Forcerank比赛中,历史表现排名的外推显示出短期反转,GPT-4的表现排名主要集中在最近的表现。使用价格图表进行预测时,滞后收益系数的大小较小,但仍显示出随时间递减的趋势。
LLM(如GPT4)在处理非结构化图像数据时也表现出从过去收益中外推的倾向。线性回归结果显示人类与LLM的表现排名与近期收益之间存在明显的衰减模式。参数回归模型假设过去收益的权重呈指数衰减,λ1为整体效应,λ2为相对权重,λ1越高、λ2越低,外推程度越高。GPT4的水平系数λ1大于人类,表明其对过去收益的反应更强;而λ2较小,意味着更重视近期收益,外推程度为38.1,远高于人类的12.09。LLM的预测可能会负向预测未来收益,尽管线性外推模型仅解释了38%的GPT4预测变异,可能还有其他非外推因素与收益正相关。


使用Fama-MacBeth回归分析预测与未来股票收益的关系,因变量为个股未来一周的日收益。将LLM和人类预测分解为预测分数和残差,预测分数为回归的拟合值,残差为回归的剩余部分。控制变量包括市值、账面市值比、资产增长、毛利润率、市场贝塔、周换手率及过去一个月的最大日收益。结果显示人类和LLM预测与未来收益呈负相关,尤其是预测分数的负向预测更为显著。训练人类输出可能导致LLM预测未来收益的方向错误。
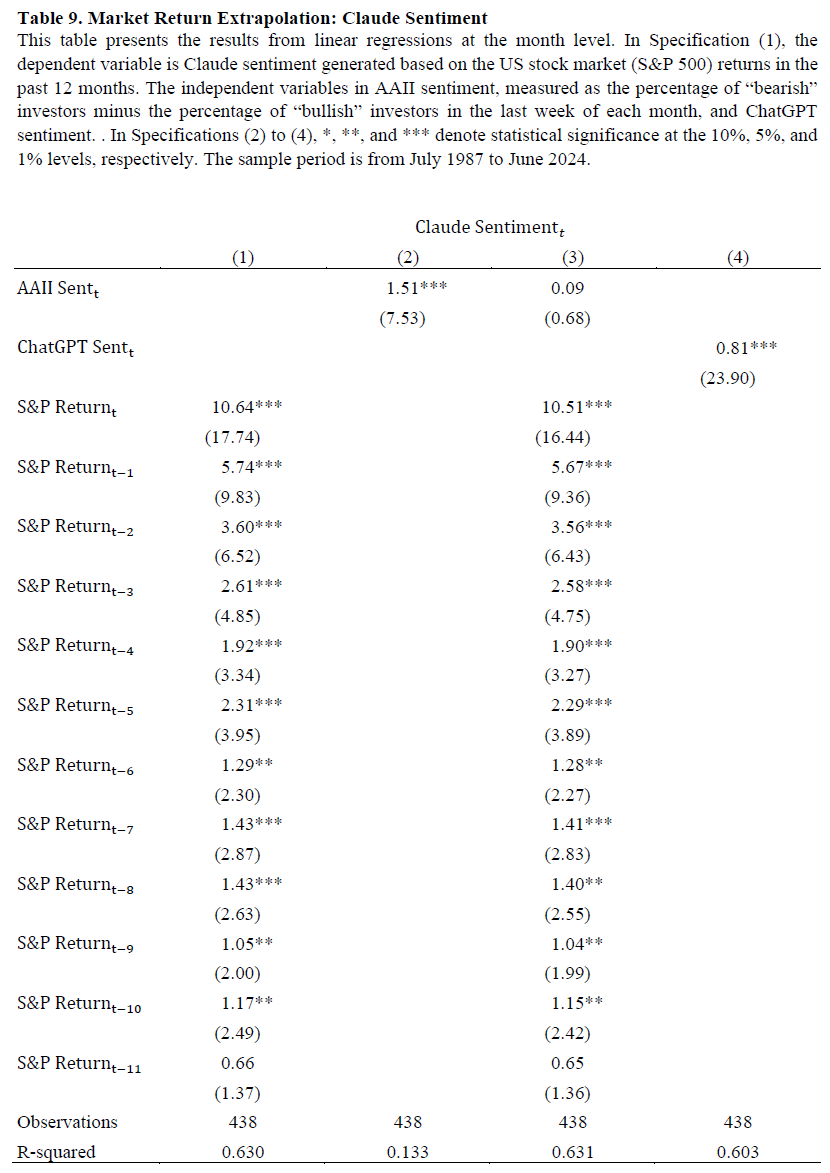
Forcerank设置分析股票的相对表现,结合GPT-4对市场表现的预期与美国个人投资者调查的证据。人类情绪指标Sentiment𝑖,𝑡反映投资者对未来六个月市场走势的预期,范围为-1到1。ChatGPT的情绪指标基于历史收益,预测未来六个月市场上涨、持平或下跌,分别用1、0、-1表示。回归分析显示,ChatGPT的收益预测对近期收益赋予较大正权重,尤其是第一期滞后收益。使用Claude 3.5 Sonnet模型的市场情绪测量与ChatGPT的结果高度相关,回归系数为0.81,R²为0.603,相关性为0.78。两种模型的滞后收益系数相似,表明ChatGPT的收益外推不仅限于个别股票或特定模型。


历史回报幅度-偏差和错误校准
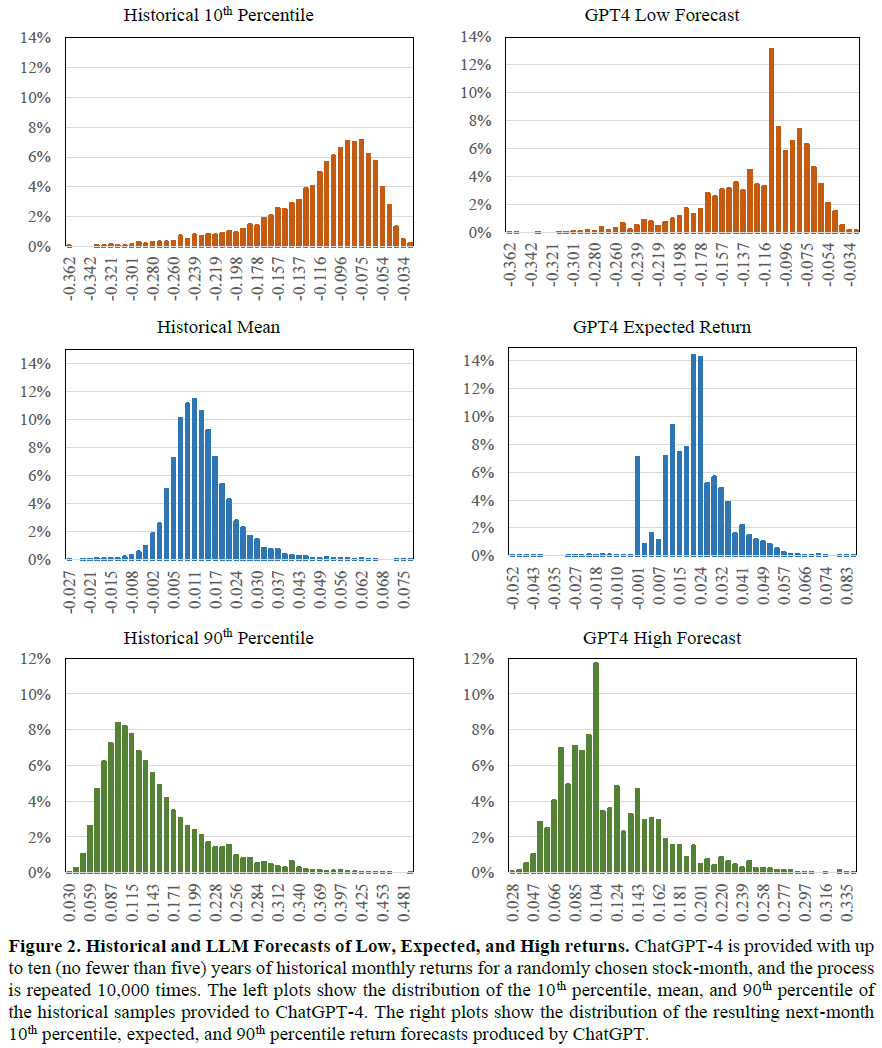
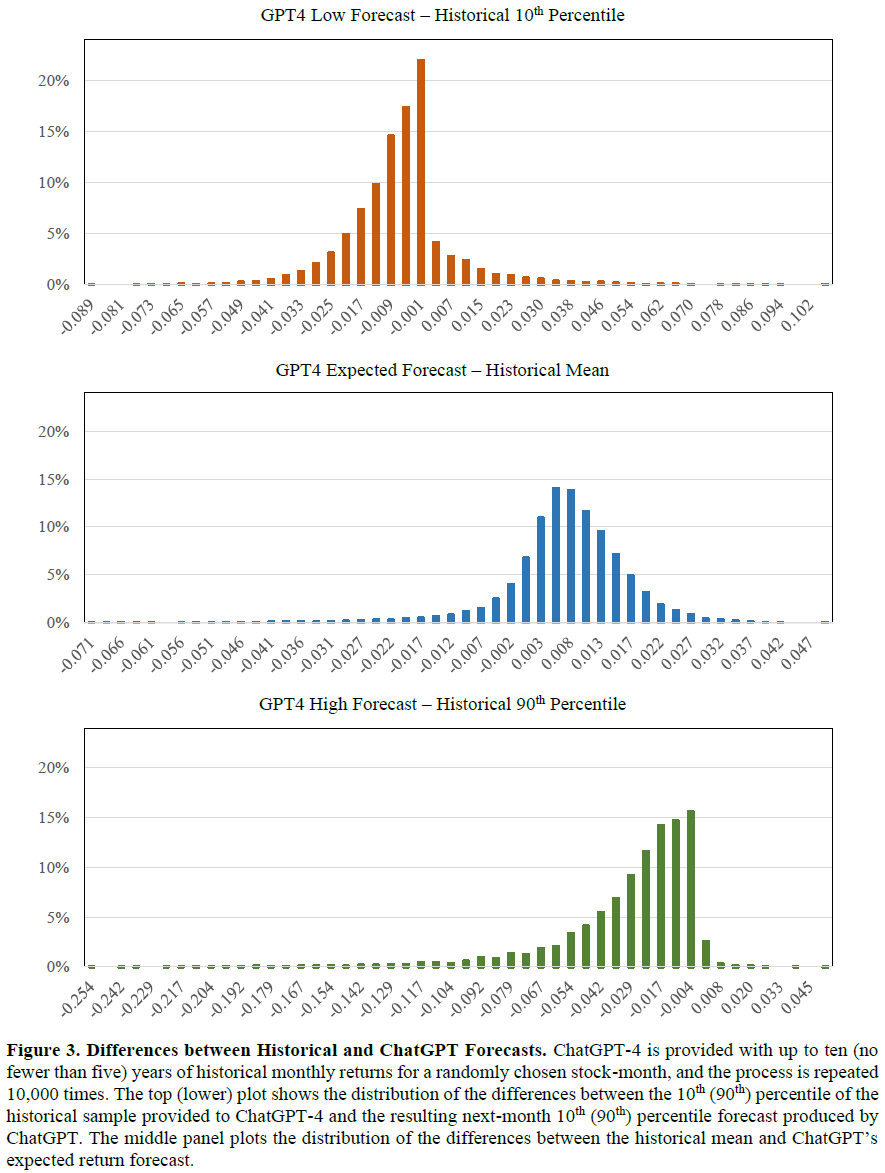
GPT4的下月股票回报预测平均为2.2%,高于历史均值1.4%和实际回报1.1%,显示出乐观偏差。GPT4预测的回报分布不如历史均值平滑,只有0.45%的预测为负值,表明其训练数据可能倾向于非负预期。GPT4的80%置信区间平均为23.4%,低于历史的25.5%,且76.9%的实际回报落在其置信区间内,低于历史的79.0%。GPT4的低预测显著低于历史10%分位数,而高预测也低于历史90%分位数,显示出对不利结果的保守态度。通过回归分析,探讨了GPT4如何将历史回报特征转化为预测。


预期回报预测的回归分析显示,90百分位的加载量最大,表明回报预测存在正偏差。低和高预测均显著加载对应百分位,同时对另一侧的百分位也有负加载,暗示对分布对称性的假设。高预测对高百分位的敏感度低于低预测对低百分位的敏感度,显示出对分布尾部的悲观态度。低和高预测的不同特征表明训练数据使得模型将高低回报视为不同特征。LLM预测的风险评估优于人类预测,但在预期表现上过于乐观,对分布尾部略显悲观,导致预测的回报分布相较历史数据呈正偏态。




讨论
LLM(大型语言模型)在股票表现预测中存在过度外推、过于乐观的预期收益和尾部预测偏差。完全消除LLM的行为偏差困难,因为这些偏差根植于训练数据中,反映了人类思维的全貌。尽管LLM能识别投资者的行为偏差,但其输出仍可能受数据中偏差的影响。LLM可通过特定数据集进行微调以改善特定领域的表现,但在缺乏良好示例的任务中,偏差仍会显现。LLM在数值和风险评估能力上优于人类,但仍易受认知偏差影响,需谨慎评估其生成的预测。未来研究应关注偏差检测和缓解方法,以确保LLM在金融决策中可靠。
总结
本研究探讨OpenAI的GPT-4在预测股票回报时是否表现出行为偏差,特别是对历史回报数据的反应。实证分析显示,ChatGPT和人类预测在使用历史数据时表现出相似的模式,强调滞后回报,但实际回报则呈现短期反转。LLM的预测与人类的过度外推期望一致,且ChatGPT预测的回报普遍高于历史均值和实际结果。在预测回报分布的尾部时,LLM表现出更悲观的态度,10百分位预测更负面,而90百分位预测低于历史上限,显示出对风险和回报的偏颇解读。研究强调在金融决策中整合AI时需关注LLM生成预测中的潜在偏见,警示不能假设这些模型以完全理性的统计方式解读数据。