[Redis 事务](#Redis 事务)
[什么是 Redis 事务?](#什么是 Redis 事务?)
你可以将 Redis 中的事务理解为:Redis 事务提供了一种将多个命令请求打包的功能。然后,再按顺序执行打包的所有命令,并且不会被中途打断。
Redis 事务实际开发中使用的非常少,功能比较鸡肋,不要将其和我们平时理解的关系型数据库的事务混淆了。
除了不满足原子性和持久性之外,事务中的每条命令都会与 Redis 服务器进行网络交互,这是比较浪费资源的行为。明明一次批量执行多个命令就可以了,这种操作实在是看不懂。
因此,Redis 事务是不建议在日常开发中使用的
[如何使用 Redis 事务?](#如何使用 Redis 事务?)
Redis 可以通过 MULTI,EXEC,DISCARD 和 WATCH 等命令来实现事务(Transaction)功能。
> MULTI
OK
> SET PROJECT "JavaGuide"
QUEUED
> GET PROJECT
QUEUED
> EXEC
1) OK
2) "JavaGuide"MULTI 命令后可以输入多个命令,Redis 不会立即执行这些命令,而是将它们放到队列,当调用了 EXEC 命令后,再执行所有的命令
这个过程是这样的:
- 开始事务(
MULTI); - 命令入队(批量操作 Redis 的命令,先进先出(FIFO)的顺序执行);
- 执行事务(
EXEC)。
你也可以通过 DISCARD 命令取消一个事务,它会清空事务队列中保存的所有命令。
> MULTI
OK
> SET PROJECT "JavaGuide"
QUEUED
> GET PROJECT
QUEUED
> DISCARD
OK你可以通过WATCH 命令监听指定的 Key,当调用 EXEC 命令执行事务时,如果一个被 WATCH 命令监视的 Key 被 其他客户端/Session 修改的话,整个事务都不会被执行
# 客户端 1
> SET PROJECT "RustGuide"
OK
> WATCH PROJECT
OK
> MULTI
OK
> SET PROJECT "JavaGuide"
QUEUED
# 客户端 2
# 在客户端 1 执行 EXEC 命令提交事务之前修改 PROJECT 的值
> SET PROJECT "GoGuide"
# 客户端 1
# 修改失败,因为 PROJECT 的值被客户端2修改了
> EXEC
(nil)
> GET PROJECT
"GoGuide"不过,如果 WATCH 与 事务 在同一个 Session 里,并且被 WATCH 监视的 Key 被修改的操作发生在事务内部,这个事务是可以被执行成功的(相关 issue:WATCH 命令碰到 MULTI 命令时的不同效果)。
事务内部修改 WATCH 监视的 Key:
> SET PROJECT "JavaGuide"
OK
> WATCH PROJECT
OK
> MULTI
OK
> SET PROJECT "JavaGuide1"
QUEUED
> SET PROJECT "JavaGuide2"
QUEUED
> SET PROJECT "JavaGuide3"
QUEUED
> EXEC
1) OK
2) OK
3) OK
127.0.0.1:6379> GET PROJECT
"JavaGuide3"事务外部修改 WATCH 监视的 Key:
> SET PROJECT "JavaGuide"
OK
> WATCH PROJECT
OK
> SET PROJECT "JavaGuide2"
OK
> MULTI
OK
> GET USER
QUEUED
> EXEC
(nil)Redis 官网相关介绍 Transactions | Docs 如下:

Redis 事务
Redis 事务支持原子性吗?
Redis 的事务和我们平时理解的关系型数据库的事务不同。我们知道事务具有四大特性:1. 原子性 ,2. 隔离性 ,3. 持久性 ,4. 一致性。
- 原子性(Atomicity): 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
- 隔离性(Isolation): 并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
- 持久性(Durability): 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
- 一致性(Consistency): 执行事务前后,数据保持一致,多个事务对同一个数据读取的结果是相同的;
Redis 事务在运行错误的情况下,除了执行过程中出现错误的命令外,其他命令都能正常执行。并且,Redis 事务是不支持回滚(roll back)操作的。因此,Redis 事务其实是不满足原子性的。
Redis 官网也解释了自己为啥不支持回滚。简单来说就是 Redis 开发者们觉得没必要支持回滚,这样更简单便捷并且性能更好。Redis 开发者觉得即使命令执行错误也应该在开发过程中就被发现而不是生产过程中。

[Redis 事务支持持久性吗?](#Redis 事务支持持久性吗?)
Redis 不同于 Memcached 的很重要一点就是,Redis 支持持久化,而且支持 3 种持久化方式:
- 快照(snapshotting,RDB)
- 只追加文件(append-only file, AOF)
- RDB 和 AOF 的混合持久化(Redis 4.0 新增)
与 RDB 持久化相比,AOF 持久化的实时性更好。在 Redis 的配置文件中存在三种不同的 AOF 持久化方式( fsync策略),它们分别是:
appendfsync always #每次有数据修改发生时都会调用fsync函数同步AOF文件,fsync完成后线程返回,这样会严重降低Redis的速度
appendfsync everysec #每秒钟调用fsync函数同步一次AOF文件
appendfsync no #让操作系统决定何时进行同步,一般为30秒一次AOF 持久化的fsync策略为 no、everysec 时都会存在数据丢失的情况 。always 下可以基本是可以满足持久性要求的,但性能太差,实际开发过程中不会使用。
因此,Redis 事务的持久性也是没办法保证的
[如何解决 Redis 事务的缺陷?](#如何解决 Redis 事务的缺陷?)
Redis 从 2.6 版本开始支持执行 Lua 脚本,它的功能和事务非常类似。我们可以利用 Lua 脚本来批量执行多条 Redis 命令,这些 Redis 命令会被提交到 Redis 服务器一次性执行完成,大幅减小了网络开销。
一段 Lua 脚本可以视作一条命令执行,一段 Lua 脚本执行过程中不会有其他脚本或 Redis 命令同时执行,保证了操作不会被其他指令插入或打扰。
不过,如果 Lua 脚本运行时出错并中途结束,出错之后的命令是不会被执行的。并且,出错之前执行的命令是无法被撤销的,无法实现类似关系型数据库执行失败可以回滚的那种原子性效果。因此, 严格来说的话,通过 Lua 脚本来批量执行 Redis 命令实际也是不完全满足原子性的。
如果想要让 Lua 脚本中的命令全部执行,必须保证语句语法和命令都是对的。
另外,Redis 7.0 新增了 Redis functions 特性,你可以将 Redis functions 看作是比 Lua 更强大的脚本
Redis性能优化
使用批量操作减少网络传输
一个 Redis 命令的执行可以简化为以下 4 步:
- 发送命令
- 命令排队
- 命令执行
- 返回结果
其中,第 1 步和第 4 步耗费时间之和称为 Round Trip Time (RTT,往返时间) ,也就是数据在网络上传输的时间。
使用批量操作可以减少网络传输次数,进而有效减小网络开销,大幅减少 RTT。
另外,除了能减少 RTT 之外,发送一次命令的 socket I/O 成本也比较高(涉及上下文切换,存在read()和write()系统调用),批量操作还可以减少 socket I/O 成本
使用批量操作减少网络传输
一个 Redis 命令的执行可以简化为以下 4 步:
- 发送命令
- 命令排队
- 命令执行
- 返回结果
其中,第 1 步和第 4 步耗费时间之和称为 Round Trip Time (RTT,往返时间) ,也就是数据在网络上传输的时间。
使用批量操作可以减少网络传输次数,进而有效减小网络开销,大幅减少 RTT。
另外,除了能减少 RTT 之外,发送一次命令的 socket I/O 成本也比较高(涉及上下文切换,存在read()和write()系统调用),批量操作还可以减少 socket I/O 成本
使用批量操作减少网络传输
一个 Redis 命令的执行可以简化为以下 4 步:
- 发送命令
- 命令排队
- 命令执行
- 返回结果
其中,第 1 步和第 4 步耗费时间之和称为 Round Trip Time (RTT,往返时间) ,也就是数据在网络上传输的时间。
使用批量操作可以减少网络传输次数,进而有效减小网络开销,大幅减少 RTT。
另外,除了能减少 RTT 之外,发送一次命令的 socket I/O 成本也比较高(涉及上下文切换,存在read()和write()系统调用),批量操作还可以减少 socket I/O 成本
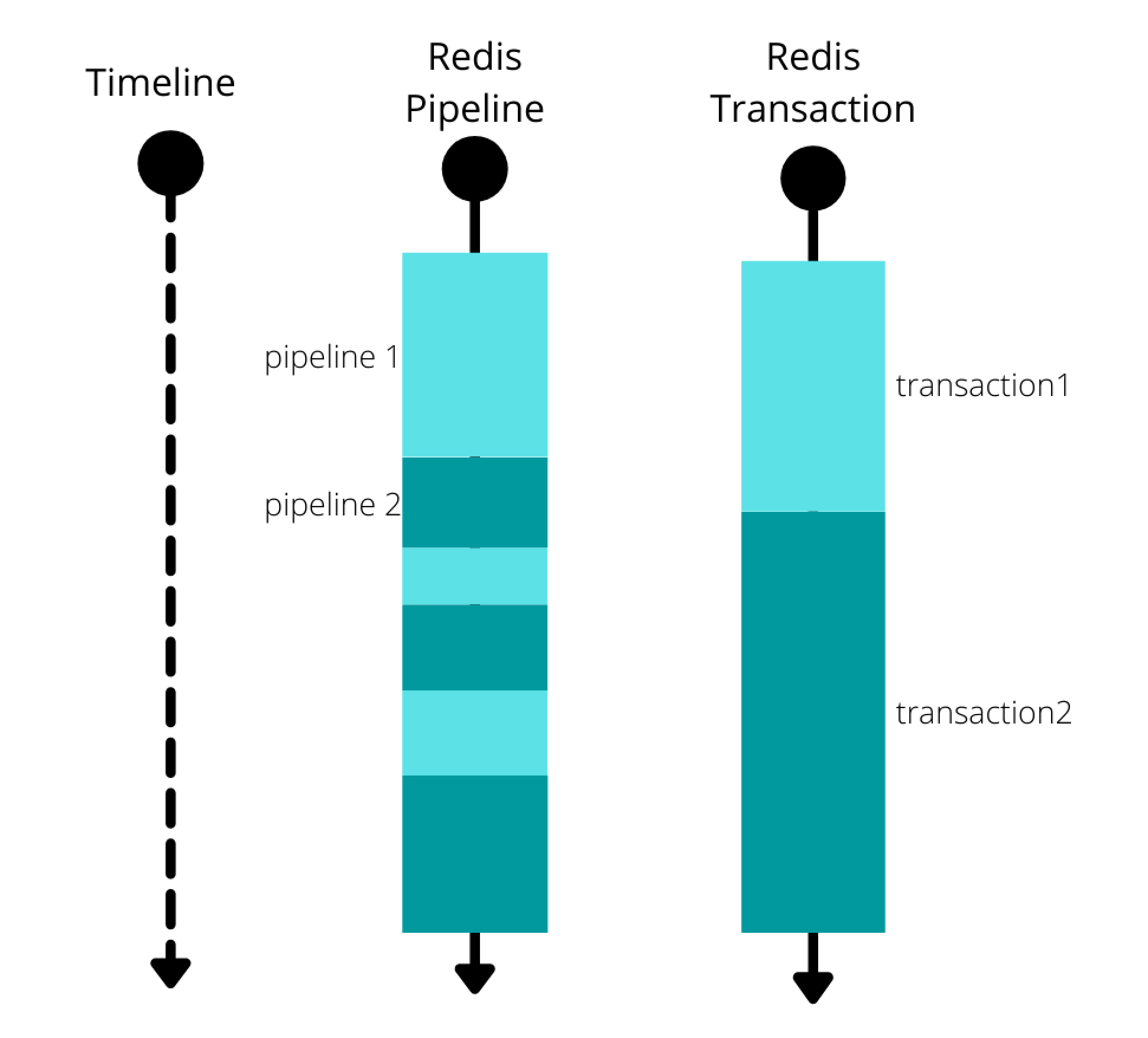
另外,pipeline 不适用于执行顺序有依赖关系的一批命令。就比如说,你需要将前一个命令的结果给后续的命令使用,pipeline 就没办法满足你的需求了。对于这种需求,我们可以使用 Lua 脚本
[Lua 脚本](#Lua 脚本)
Lua 脚本同样支持批量操作多条命令。一段 Lua 脚本可以视作一条命令执行,可以看作是 原子操作 。也就是说,一段 Lua 脚本执行过程中不会有其他脚本或 Redis 命令同时执行,保证了操作不会被其他指令插入或打扰,这是 pipeline 所不具备的。
并且,Lua 脚本中支持一些简单的逻辑处理比如使用命令读取值并在 Lua 脚本中进行处理,这同样是 pipeline 所不具备的。
不过, Lua 脚本依然存在下面这些缺陷:
- 如果 Lua 脚本运行时出错并中途结束,之后的操作不会进行,但是之前已经发生的写操作不会撤销,所以即使使用了 Lua 脚本,也不能实现类似数据库回滚的原子性。
- Redis Cluster 下 Lua 脚本的原子操作也无法保证了,原因同样是无法保证所有的 key 都在同一个 hash slot(哈希槽)上