目录
[编写搜索引擎模块 Searcher](#编写搜索引擎模块 Searcher)
[一. 初始化服务(InitSearcher)](#一. 初始化服务(InitSearcher))
[2. 编写InitSearcher](#2. 编写InitSearcher)
[二. 提供服务(Search)](#二. 提供服务(Search))
[1. 对用户关键字进行分词](#1. 对用户关键字进行分词)
[2. 触发分词,进行索引查找](#2. 触发分词,进行索引查找)
[3. ⭕ 按文档权重进行降序排序](#3. ⭕ 按文档权重进行降序排序)
[4. 根据排序结果构建json串](#4. 根据排序结果构建json串)
编写搜索引擎模块 Searcher
我们已经完成了 数据清洗、去标签和索引相关的工作,接下来就是要编写服务器所提供的服务
我们试想一下,服务器要做哪些工作:
- 首先,我们的数据事先已经经过了数据清洗和去标签
- 服务器运行起来之后,应该要先去构建索引
- 然后根据索引去搜索
- 所以我们在Searcher模块中实现两个函数,分别为InitSearcher()和Search()
代码如下:touch searcher.hpp
#include "index.hpp"
namespace ns_searcher
{
class Searcher
{
private:
ns_index::Index *index; // 供系统进行查找的索引
public:
Searcher() {}
~Searcher() {}
public:
void InitSearcher(const std::string &input)
{
// 获取或者创建index对象(单例)
// 根据index对象建立索引
}
//query: 搜索关键字
//json_string: 返回给用户浏览器的搜索结果
void Search(const std::string &query, std::string *json_string)
{
//...
}
};
}- query: 搜索关键字
- json_string: 返回给用户浏览器的搜索结果
void Search(const std::string &query, std::string *json_string)
- 分词:对搜索关键字query在服务端也要分词,然后查找index
- 触发:根据分词的各个词进行index查找
- 合并排序:汇总查找结果,按照相关性(权重weight)降序排序
- 构建]:将排好序的结果,生成json串 ------ jsoncpp
一. 初始化服务(InitSearcher)
- 服务器 要去 构建索引,本质上就是去构建一个 Index对象,然后调用其内部的方法,
- 我们知道构建正排索引和倒排索引本质就是将磁盘上的数据加载的内存,其数据量还是比较大的(可能本项目的数据量不是很大)。
- 从这一点可以看出,假设创建了多个Index对象的话,其实是比较占内存的,我们这里就可以将Index类设计成为单例模式;
- 关于单例模式是什么及代码框架(懒汉模式和饿汉模式)这里不做详细介绍,不了解的小伙伴可以去自行搜索,也是比较简单的。
⭕ 1.Index模块的单例设计
namespace ns_index
{
class Index
{
private:
std::vector<DocInfo> forward_index; //正排索引
std::unordered_map<std::string, InvertedList> inverted_index;//倒排索引
// 将 Index 转变成单例模式
private:
Index(){} //这个一定要有函数体,不能delete
Index(const Index&) = delete; // 拷贝构造
Index& operator = (const Index&) = delete; // 赋值重载
static Index* instance;
static std::mutex mtx;//C++互斥锁,防止多线程获取单例存在的线程安全问题
public:
~Index(){}
public:
//获取index单例
static Index* GetInstance()
{
// 这样的【单例】 可能在多线程中产生 线程安全问题,需要进行加锁
if(nullptr == instance)// 双重判定空指针, 降低锁冲突的概率, 提高性能
{
mtx.lock();//加锁
if(nullptr == instance)
{
instance = new Index();//获取单例
}
mtx.unlock();//解锁
}
return instance;
}
DocInfo* GetForwardIndex(uint64_t doc_id)
{
//...
}
//索引的建立详见,上一篇文章讲解...
};
// 单例模式
Index* Index::instance = nullptr;
std::mutex Index::mtx;
}2. 编写InitSearcher
void InitSearcher(const std::string &input)
{
// 获取或者创建index对象(单例)
index = ns_index::Index::GetInstance();
// 根据index对象建立索引
index->BuildIndex(input);
}二. 提供服务(Search)
对于提供服务,我们需要从四个方面入手,达到服务效果:
- 对用户的输入的【关键字】,我们首先要做的就是【分词】,只有分成不同的词之后,才能按照不同的词去找文档;
- 分词完毕后,我们就要去触发这些分词,本质就是查找建立好的正排索引和倒排索引;
- 我们的每个文档都是设置了权重字段的,我们就应该在触发分词之后,进行权重的降序排序,达到权重高的文档靠前,权重低的文档靠后;
- 根据排序完的结果,构建json串,用于网络传输。
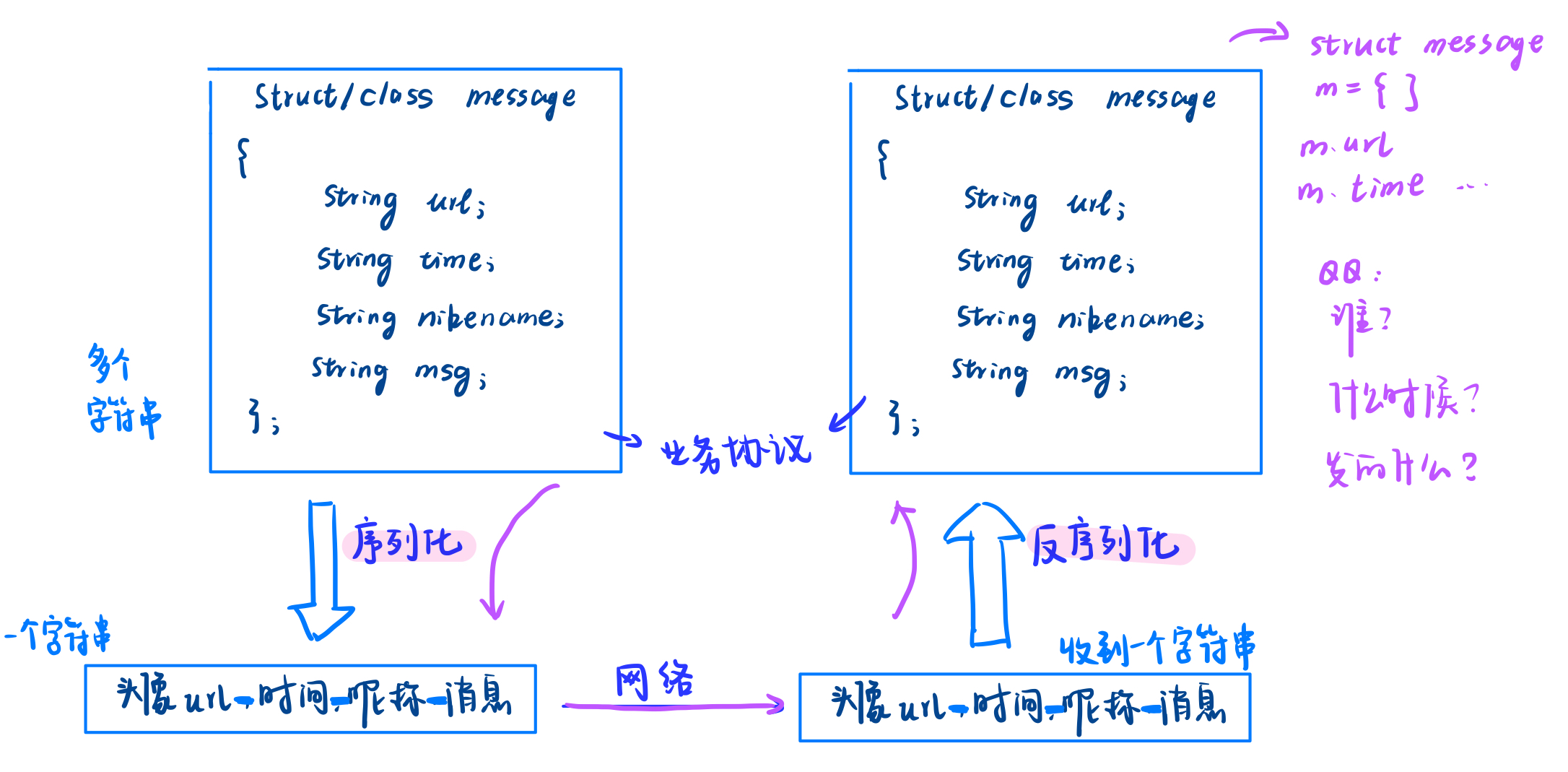
因为结构化的数据不便于网络传输,我们就需要使用一个工具(jsoncpp)
- 它是用来将结构化的数据转为字节序(你可以理解为很长的字符串)
- jsoncpp可以进行序列化(将结构化的数据转换为字节序列,发生到网络)和反序列化(将网络中的字节序列转化为结构化的数据)
具体可以参考这篇博客Linux#55网络协议 序列化与反序列化 | TcpCalculate为例
1. 对用户关键字进行分词
为什么?
- 我们 index模块 中的 正排索引 中已经做了分词操作,这只能说明服务器已经将数据准备好了,按照不同的词和对应的文档分好类了;
- 但是用户输入的关键字,我们依旧是要做分词操作的。
- 设想一下,如果没有做分词,直接按照原始的关键字进行查找,给用户反馈的文档一定没有分词来的效果好,甚至有可能匹配不到文档。
代码如下:
//query--->搜索关键字
//json_string--->返回给用户浏览器的搜索结果
void Search(const std::string &query, std::string *json_string)
{
//1.分词---对query按照Searcher的要求进行分词
std::vector<std::string> words; //用一个数组存储分词的结果
ns_util::JiebaUtil::CutString(query, &words);//分词操作
}2. 触发分词,进行索引查找
- 分词完成以后,我们就应该按照分好的每个词(关键字)去获取倒排拉链
- 我们将获取上来的倒排拉链进行保存到vector当中,这也就是我们根据用户关键字所查找的结果
但是我们还需要考虑一个问题:
❓用户输入的关键字进行分词了以后,有没有可能多个关键字对应的是同一个文档?
如下图所示:
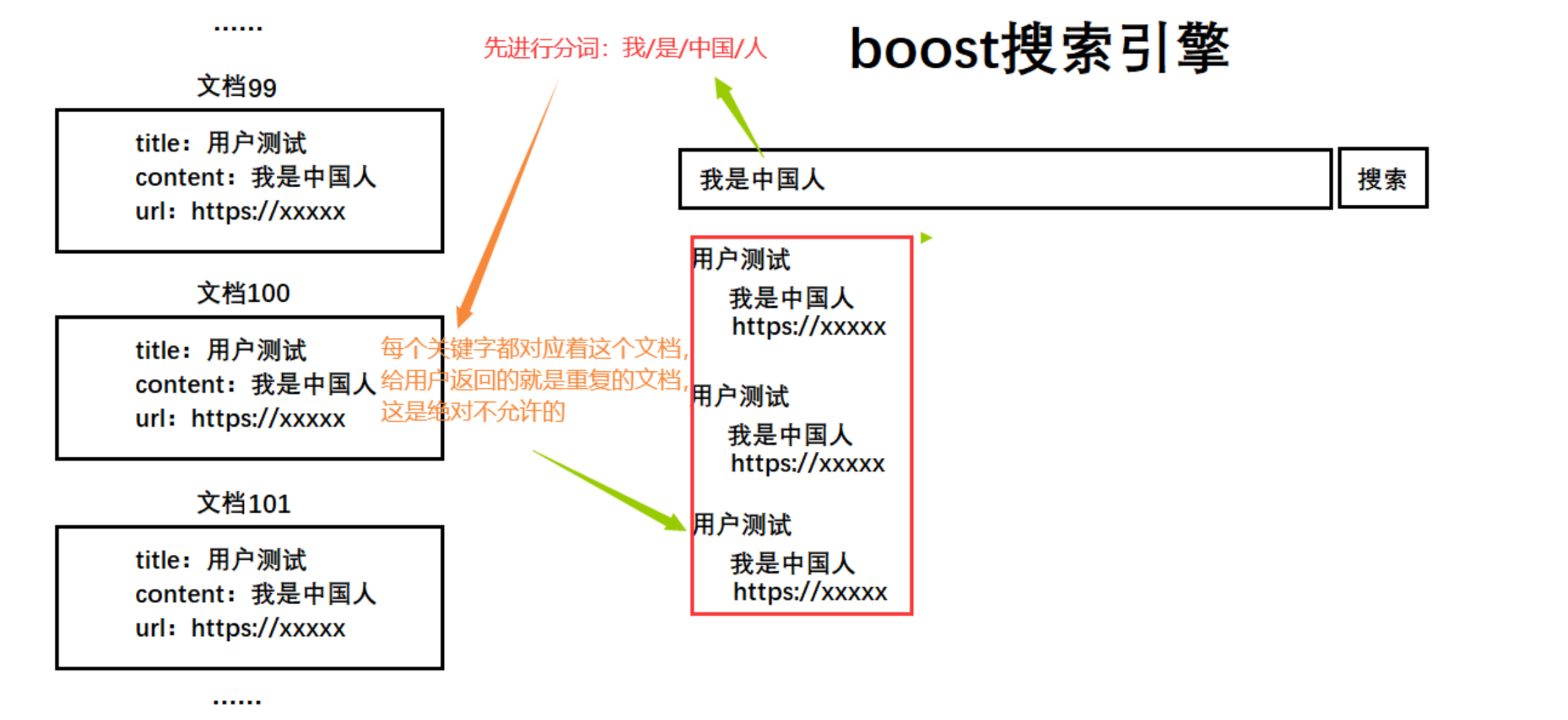
根据上面的图,我们首先想到的就是去重。
其次,每个倒排拉链的结点都包含:doc_id、关键字和权重。
既然显示了重复的文档,我们应该是只显示一个,那么这个最终显示的文档其权重就是几个文档之和,关键字就是几个文档的组合,
那么我们可以定义一个新的结构体来保存查找后的倒排拉链,代码如下:
//该结构体是用来对重复文档去重的结点结构
struct InvertedElemPrint
{
uint64_t doc_id; //文档ID
int weight; //重复文档的权重之和
std::vector<std::string> words;//关键字的集合,我们之前的倒排拉链节点只能保存一个关键字
InvertedElemPrint():doc_id(0), weight(0){}
};有了上面的铺垫,我们就可以来编写触发分词的代码了
//query--->搜索关键字
//json_string--->返回给用户浏览器的搜索结果
void Search(const std::string &query, std::string *json_string)
{
//1.分词---对query按照Searcher的要求进行分词
std::vector<std::string> words; //用一个数组存储分词的结果
ns_util::JiebaUtil::CutString(query, &words);//分词操作
//2.触发---就是根据分词的各个"词",进行index查找,建立index是忽略大小写,所以搜索关键字也需要
std::vector<InvertedElemPrint> inverted_list_all; //用vector来保存
std::unordered_map<uint64_t, InvertedElemPrint> tokens_map;//用来去重
for(std::string word : words)//遍历分词后的每个词
{
boost::to_lower(word);//忽略大小写
ns_index::InvertedList* inverted_list = index->GetInvertedList(word);//获取倒排拉链
if(nullptr == inverted_list)
{
continue;
}
//遍历获取上来的倒排拉链
for(const auto &elem : *inverted_list)
{
auto &item = tokens_map[elem.doc_id];//插入到tokens_map中,key值如果相同,这修改value中的值
item.doc_id = elem.doc_id;
item.weight += elem.weight;//如果是重复文档,key不变,value中的权重累加
item.words.push_back(elem.word);//如果树重复文档,关键字会被放到vector中保存
}
}
//遍历tokens_map,将它存放到新的倒排拉链集合中(这部分数据就不存在重复文档了)
for(const auto &item : tokens_map)
{
inverted_list_all.push_back(std::move(item.second));
}
}3. ⭕ 按文档权重进行降序排序
对于排序,应该不难,我们直接使用C++库当中的sort函数,并搭配lambda表达式使用;当然你也可以自己写一个快排或者归并排序,按权重去排;
//3. 合并排序---汇总查找结果,按照相关性(weight)降序排序
std::sort(inverted_list_all.begin(), inverted_list_all.end(),\
[](const InvertedElemPrint &e1, const InvertedElemPrint &e2)
{return e1.weight > e2.weight;});4. 根据排序结果构建json串
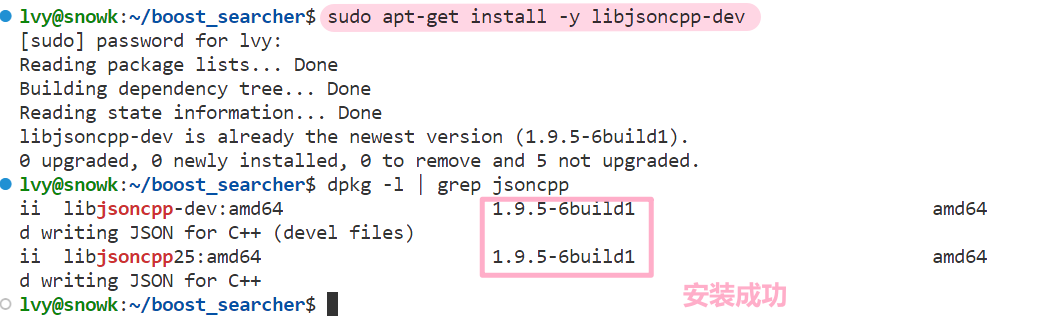
关 于 json 的使用,我们首先需要在 Linux下安装 jsoncpp
sudo apt-get install -y libjsoncpp-dev这里我之前下载过了,已经是最新的版本了,可以输入下面的指令测试,有这样的提示,就表明安装成功了。
使用:
#include <iostream>
#include <vector>
#include <string>
#include <json/json.h>
//Value Reader(反序列化) Writer(序列化)
int main()
{
Json::Value root;
Json::Value item1;
item1["key1"] = "value1";
item1["key2"] = "value2";
Json::Value item2;
item2["key1"] = "value3";
item2["key2"] = "value4";
root.append(item1);
root.append(item2);
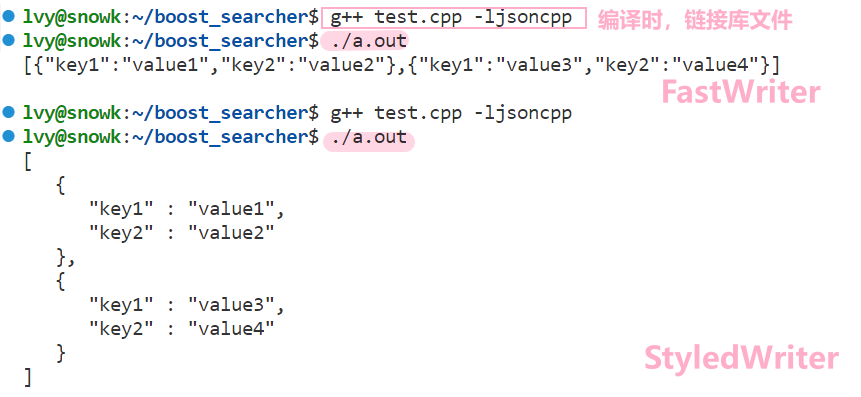
//两种序列化方式
//序列化方式1
//Json::StyledWriter writer; //序列化方式1
Json::FastWriter writer; //序列化方式2
std::string s = writer.write(root);
std::cout<<s<<std::endl;
return 0;
}- root对象:你可以理解为 json数组;
- item对象:就是json中value的对象,他可以保存kv值
- 将item1和item2 ,append到root中:root这个大json数组,保存了两个子json
- 序列化的方式有两种:StyledWriter和FastWriter
两者的区别:
- 呈现的格式不一样;
- 在网络传输中FastWriter更快。
有了基本的了解之后,我们开始编写正式的代码:
#include "index.hpp"
#include <jsoncpp/json/json.h>
namespace ns_searcher
{
class Searcher
{
void Search(const std::string &query, std::string *json_string)
{
//...
// 4.构建---根据查找出来的结果,构建json串---jsoncpp
Json::Value root;
for (auto &item : inverted_list_all)
{
ns_index::DocInfo *doc = index->GetForwardIndex(item.doc_id);
if (nullptr == doc)
{
continue;
}
Json::Value elem;
elem["title"] = doc->title;
elem["desc"] = GetDesc(doc->content, item.words[0]); // content是文档去标签后的结果,但不是我们想要的,我们要的是一部分
elem["url"] = doc->url;
// 调式
// elem["id"] = (int)item.doc_id;
// elem["weight"] = item.weight;
root.append(elem);
}
// Json::StyledWriter writer; //方便调试
Json::FastWriter writer; // 调式没问题后使用这个
*json_string = writer.write(root);
}在上述的代码中,我们构建出来的json串最后是要返回给用户的,对于内容,我们只需要一部分,而不是全部,所以我们还要实现一个GetDesc 的函数:

std::string GetDesc(const std::string &html_content, const std::string &word)
{
//找到word(关键字)在html_content中首次出现的位置
//然后往前找50个字节(如果往前不足50字节,就从begin开始)
//往后找100个字节(如果往后不足100字节,就找到end即可)
//截取出这部分内容
const int prev_step = 50;
const int next_step = 100;
//1.找到首次出现
auto iter = std::search(html_content.begin(), html_content.end(), word.begin(), word.end(), [](int x, int y){
return (std::tolower(x) == std::tolower(y));
});
if(iter == html_content.end())
{
return "None1";
}
int pos = std::distance(html_content.begin(), iter);
//2.获取start和end位置
int start = 0;
int end = html_content.size() - 1;
//如果之前有50个字符,就更新开始位置
if(pos > start + prev_step) start = pos - prev_step;
if(pos < end - next_step) end = pos + next_step;
//3.截取子串,然后返回
if(start >= end) return "None2";
std::string desc = html_content.substr(start,end - start);
desc += "...";
return desc;
}测试
下面代码 和我们项目文件关联性不大,主要是用来调式(需要将上文代码中备注调式的代码放开)
最后,我们来测试一下效果,编写debug.cpp,
#include "searcher.hpp"
#include <cstdio>
#include <iostream>
#include <string>
const std::string input = "data/raw_html/raw.txt";
int main()
{
ns_searcher::Searcher *search = new ns_searcher::Searcher();
search->InitSearcher(input); //初始化search,创建单例,并构建索引
std::string query; //自定义一个搜索关键字
std::string json_string; //用json串返回给我们
char buffer[1024];
while(true)
{
std::cout << "Please Enter You Search Query:"; //提示输入
fgets(buffer, sizeof(buffer) - 1, stdin); //读取
buffer[strlen(buffer)-1] = 0;
query = buffer;
search->Search(query, &json_string); //执行服务,对关键字分词->查找索引->按权重排序->构建json串->保存到json_string->返回给我们
std::cout << json_string << std::endl;//输出打印
}
return 0;
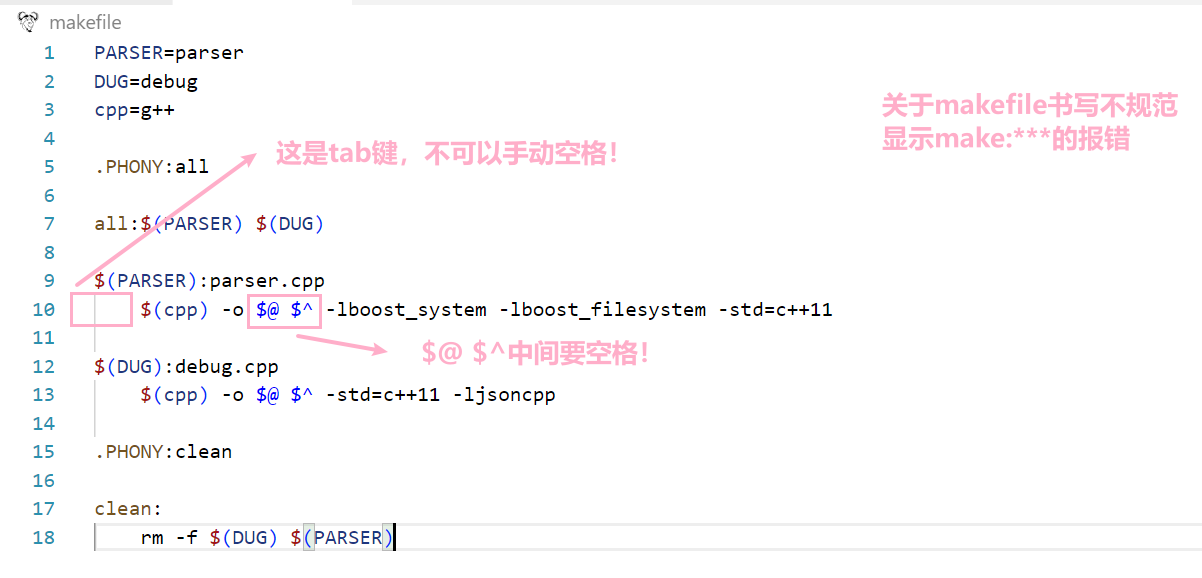
}makefile:
PARSER=parser
DUG=debug
cpp=g++
.PHONY:all
all:$(PARSER) $(DUG)
$(PARSER):parser.cpp
$(cpp) -o $@ -lboost_system -lboost_filesystem -std=c++11
$(DUG):debug.cpp
$(cpp) -o $@ -std=c++11 -ljsoncpp
.PHONY:clean
clean:
rm -f $(DUG) $(PARSER)执行命令
make
./parser #进行数据清洗和去标签
./debug #获取index单例,并开始创建索引尝试搜索:

我们可以看到,效果很明显。我们复制其中一个网址,查看一下权重是否一样:

找到啦
- 当你再去查看其他网址,然后自己进行权重计算的时候,有时候会多一个或者少一个
- 我分析的原因就是,在对标题和内容进行分词的时候,产生的一些影响,但是大体上没有太大的问题。
- 测试完毕之后,记得屏蔽测试代码哦
下篇文章我们将继续对项目进行讲解~
记录一些导致编译不过的一些笨蛋行为
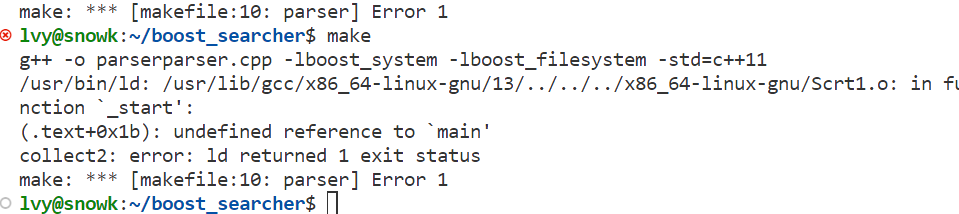
写 makefile 时要细心