
我准备写个SD自学指南,当然也是第一次写,可能有点凌乱,后续我会持续更新不断优化,我是生产队的驴,欢迎监督。
Stable Diffusion WebUI 入门指南
Stable Diffusion WebUI 是一款基于 Stable Diffusion 模型的用户界面,可以根据文本生成高质量的图像。我准备写个SD自学指南,当然也是第一次写,可能有点凌乱,后续我会持续更新不断优化,我是生产队的驴,欢迎监督。该指南将帮助你快速了解如何在本地搭建并使用 WebUI。
一、安装 Stable Diffusion WebUI
我们将使用 Automatic1111's WebUI,这是一个非常流行且功能丰富的界面。
这里面有很多东西需要学习的,我们首先先解决环境搭建软件安装的这一步,万事开头难,我们先开始。
模型介绍的安装:大模型的安装使用、VAE模型的安装使用
插件安装方式也有很多种:启动器安装、 github安装、网址安装
1.1、安装步骤(适用于本地机器):
-
环境要求:
- 推荐使用 NVIDIA GPU,因为它支持 CUDA,能够提升生成速度。
- 安装 Python 3.10 以上版本 和 Git。
- 至少需要 10-12GB 硬盘空间 和 6GB 以上的显存(以生成 512x512 的图像为例)。
-
克隆 WebUI 项目 :
打开终端或命令提示符,执行以下命令:
bashgit clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git cd stable-diffusion-webuigithub项目 完全开源-多好的学习机会:

-
下载 Stable Diffusion 模型权重 :
你需要从 Hugging Face 下载模型文件(如 1.4 或 1.5 版本的 checkpoint 模型),将
.ckpt文件放置在models/Stable-diffusion/目录中。 -
运行 WebUI :
Windows 用户运行
webui-user.bat,Linux/macOS 用户运行webui.sh。首次运行时,脚本会自动安装所需的依赖项。 -
访问 WebUI :
安装完成后,打开浏览器,访问
http://127.0.0.1:7860/来使用 WebUI。
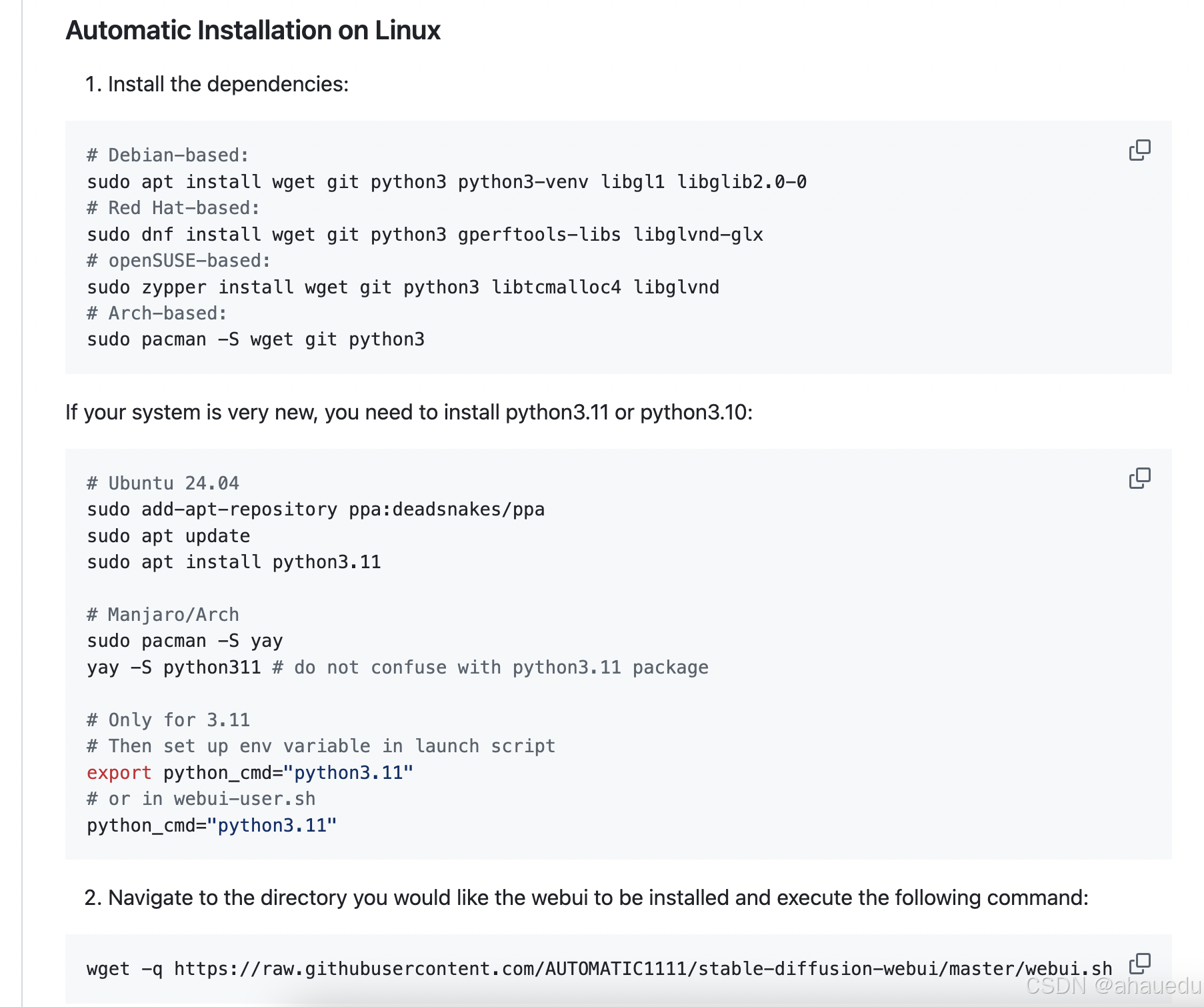
1.2、在Linux下安装
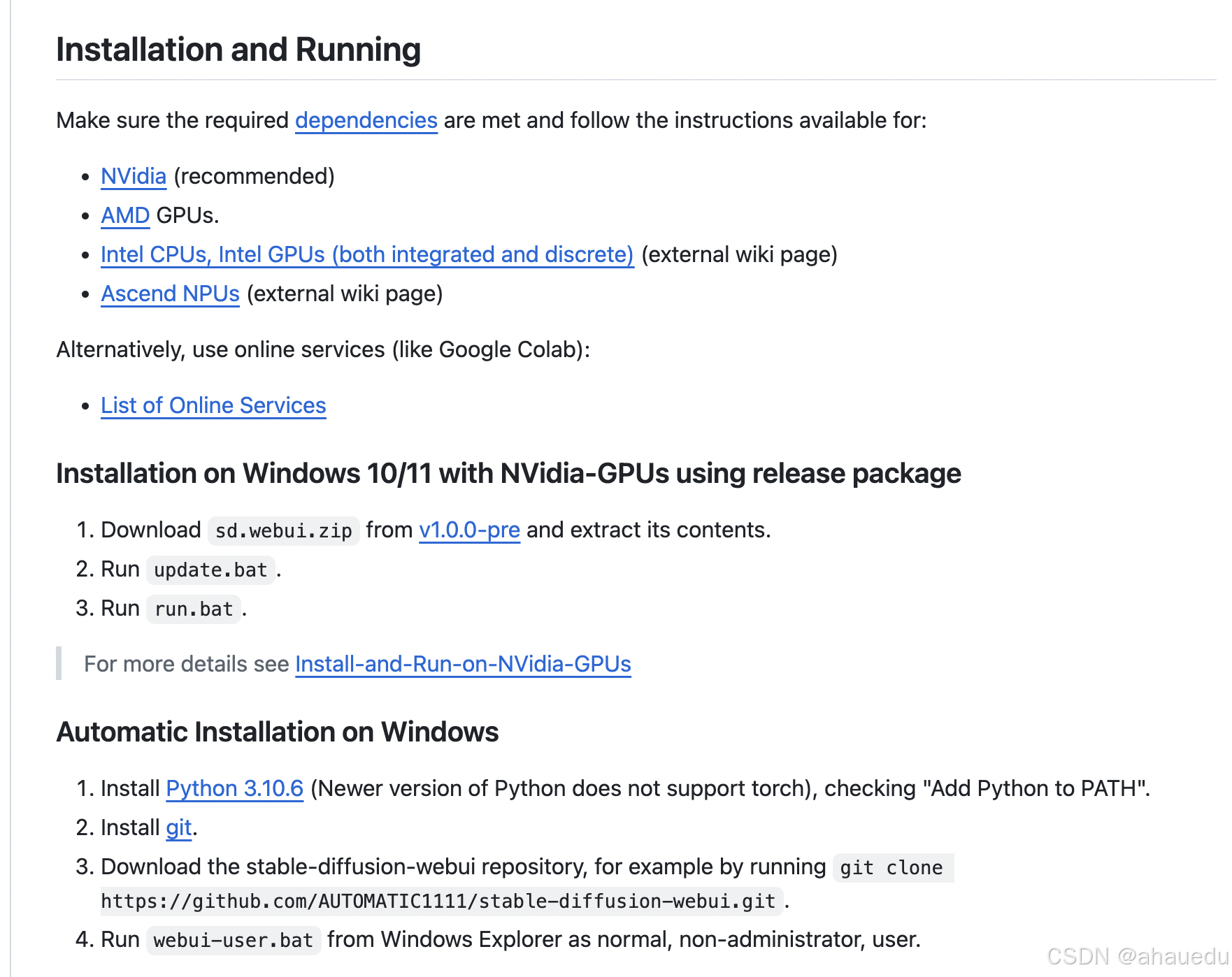
1.3、在Windows下安装
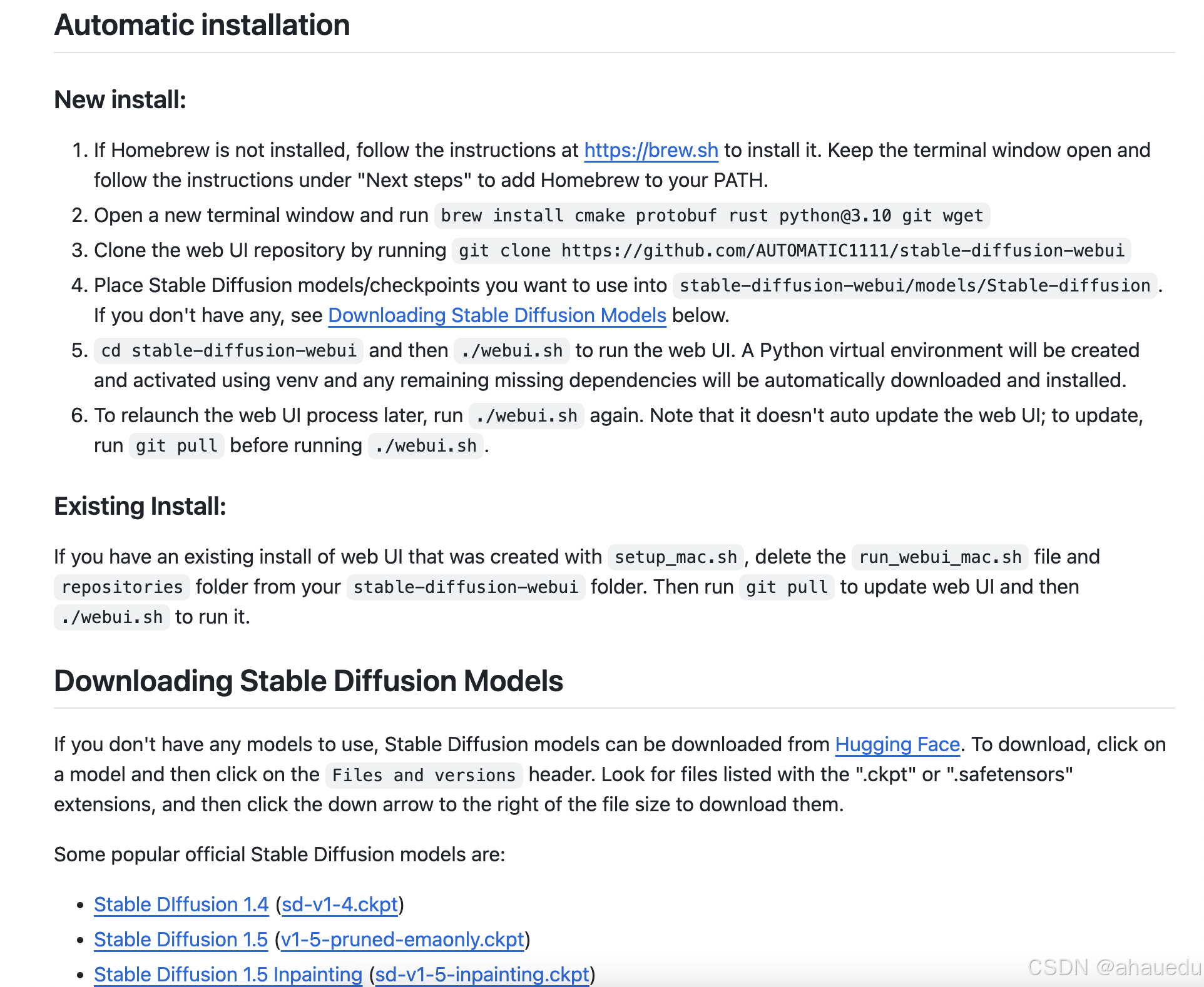
1.4、苹果机安装
在 Apple Silicon 上安装,在MAC或者苹果盒子机系统的设备上安装可以参考
可以参考文档 全新安装、扩展插件的安装、模型Model的安装。
二、基础使用
当你成功启动 WebUI 后,可以开始尝试生成图像。
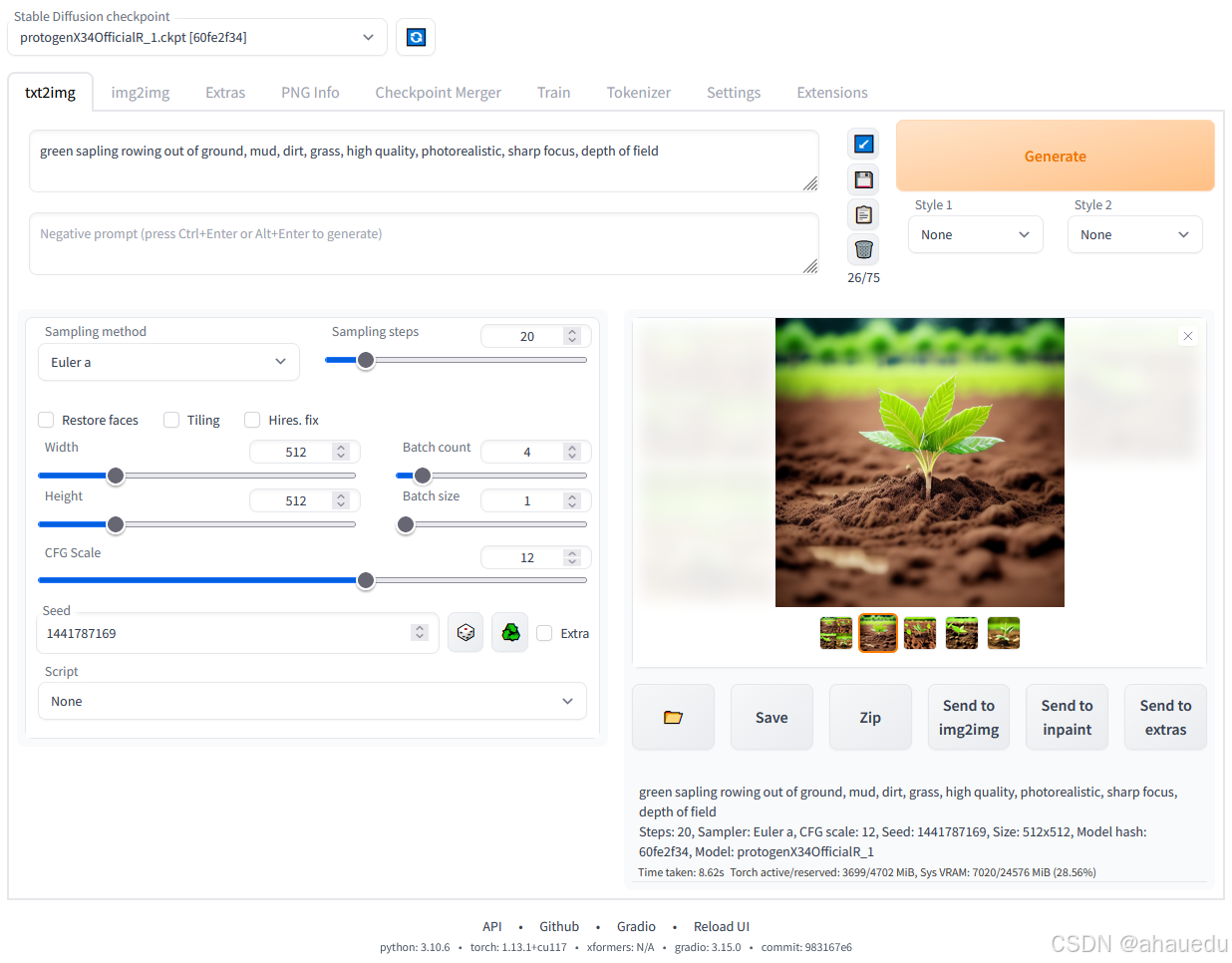
文本生成图像:
- 在 WebUI 界面中,有一个文本输入框供你输入提示词(prompt)。
- 设置参数如 图像分辨率 、步数 (决定模型生成图像的迭代次数)、采样器 (生成图像的算法)、CFG 规模(图像遵循提示词的严格程度)。
- 点击 生成 ,系统会根据你的提示词生成图像。

常见参数:
- 采样步数(Steps):步数越多,图像质量越好,但生成速度会变慢。推荐从较低步数开始。
- CFG 规模:控制图像与提示词的匹配度,值越高生成的图像越接近提示词,但过高可能导致图像失真。
- 图像宽高:生成图像的分辨率,初学者可以从 512x512 开始,以避免性能问题。
三、进阶功能
- 图像修补(Inpainting):你可以上传已有图像,选择某个区域让模型根据新的提示词进行修改。
- 图像到图像(Image2Image):通过提供一张基础图像,模型会根据提示词进行调整,生成新的图像。
- 图像放大 :使用 Real-ESRGAN 等工具,放大生成的图像以提高分辨率。
四、提示词优化技巧
初学者可以从简单的提示词开始,比如"树上的猫",然后逐步添加细节,例如艺术风格、光线条件、情绪等。例如:"未来城市,夜晚,赛博朋克风,霓虹灯"。
五、社区资源
科学上网哦
- Hugging Face:提供了不同版本的 Stable Diffusion 模型和权重文件。
- 论坛与讨论群:在 Reddit 和 Discord 上有许多 AI 艺术社区,你可以加入讨论,学习新的技巧。
六、常见问题
财力不足,借助外力,比如找我 哈哈哈
- 显存不足:当你生成大图时,显存不足可能会导致生成失败。可以尝试降低图像分辨率或使用优化的模型。
- 依赖项问题 :安装过程中,如果有依赖项安装失败,可以手动使用
pip安装。 - **云电脑:**这个也是个不错的选择,毕竟一般电脑的配置和算力跟不上,使用云电脑可以轻松解决环境问题。
通过以上步骤,你可以在本地快速体验 Stable Diffusion WebUI,并生成你想要的 AI 图像。