前言
Flink是目前算是实时计算的事实标准,背靠Apache活跃的社区和国内阿里技术团队的支持,社区生态十分丰富,本篇文章主要介绍flink的结构,对flink的各个组件有个更清晰的认识。
flink官网对flink的架构有很清晰的介绍,强烈推荐刚接触或者想对flink有深入了解的同学学习flink,我会在官网介绍的基础上补充自己对flink运行时架构的理解。
这张是官网的图,从这个图中呢,就很清晰的能看到Flink整体的架构划分为3个部分:
- Flink Program:用户代码所在的应用程序
- JobManager:Master角色 负责集群和作业管理
- TaskManager:Slave角色,负责task的执行
核心组件
JobManager
JobManager并不是指的是一个具体的组件,而是一个独立运行的进程,该进程包含3个核心的组件:
- ResourceManager
- Dispatcher
- JobMaster
ResourceManager
负责管理集群的计算资源,计算资源来自于TaskManager task slots的注册,处理JobMaster的资源申请和释放。
Dispacther
负责接收客户端提交的JobGraph对象,客户端提交的任务最终都会到Dispacther这个组件,Dispacher接收到JobGraph后,会进行任务的分发,最核心的就是启动JobMaster
JobMaster
管理作业的整个生命周期。Dispacther接收到JobGraph对象后,会创建JobMaster,JobMaster会将JobGraph转换为Execution,之后JobMaster会对ExecutionGraph进行调度,最终提交到TaskManager运行Task任务。同时监控Task任务执行状态,直到整个作业执行完毕。JobMaster也是RPC服务,启动的时候会向Resource进行注册,申请资源。
TaskManager
向整个集群提供计算资源,同时管理JobMaster提交的Task任务,通过RPC服务与ResourceManager注册资源。
运行时任务提交流程
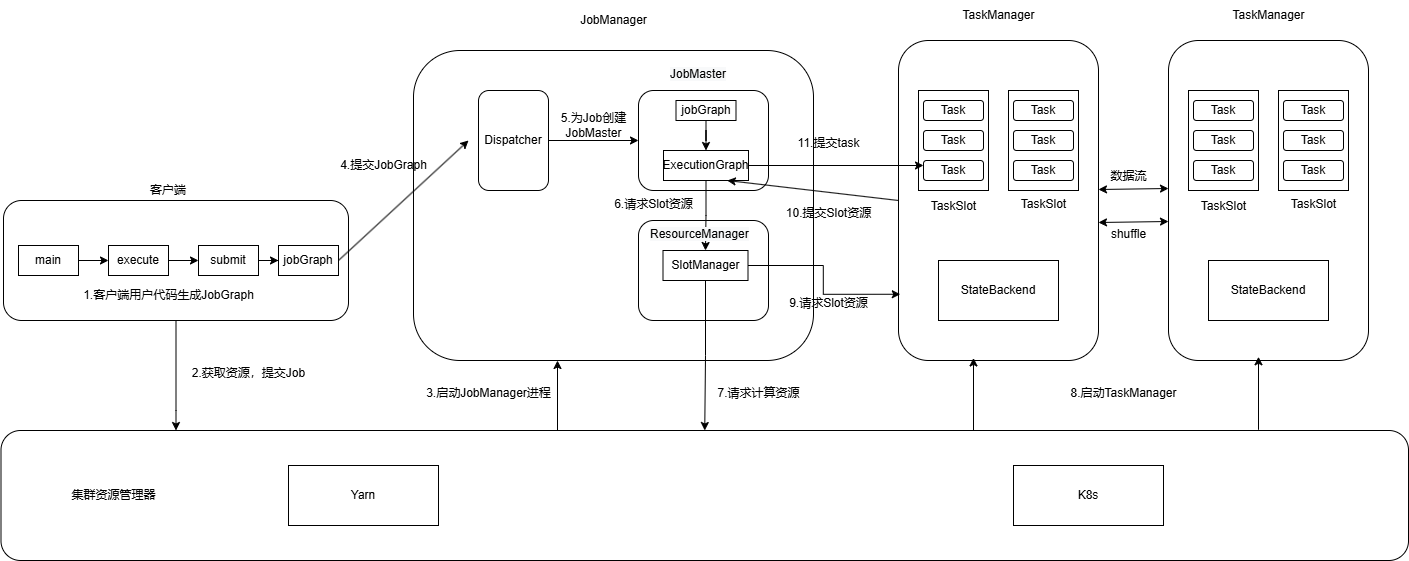
1.用户通过客户端命令启动flink任务,会触发集群所有服务的启动,
2.ClusterManager会为运行时各个组件申请运行节点以及资源(比如Yarn 的Container)
3.客户端(CliFrontend)提交应用程序代码经过本地运行生成JobGraph结构,然后通过ClusterClient提交JobGraph到集群中运行
4.集群中的Dispatcher服务接收到JobGraph对象,根据JobGraph对象启动JobMaster,每个作业都有一个单独的JobMaster作业管理器
5.JobMaster构建的时候会将JobGraph转换成ExecutionGraph对象
6.之后JobMaster向ResourceManager服务Task实例需要的slot计算资源
7.ResourceManager接收到申请后,先判断是否有足够的slot资源,如果有则直接分配给JobMaster,如果没有则向资源管理器申请(比如Yarn Contaioner)
8.申请到资源以后就会启动TaskManager,TaskManager启动后会主动向ResourceManager汇报slot信息
9.ResourceManager收到注册资源后,会立刻向TaskManager发送SlotRequest请求为任务分配资源
10.TaskManager接收到ResourceManager的资源分配请求后,会对符合条件的SlotRequest进行处理,然后向JobMaster发送申请(offerslots)提供Slot资源
11.JobMaster接收到offerslots的消息后,就会向slot所在的TaskManager申请提交Task任务。
12.TaskManager接收到JobMaster发送的启动Task任务申请后,会启动Task线程。
13.TaskManager中的Task线程周期性的向JobMaster汇报任务运行状态,直到任务结束