
总体结论
本文提出了一种新的细粒度表示与重构(FIRe2)框架,用于解决布变人重识别问题。通过细粒度特征挖掘和属性重构,FIRe2在不依赖任何辅助信息的情况下,实现了最先进的性能。该方法在多个基准数据集上取得了显著的成果,展示了其在现实世界应用中的潜力。
优点与创新
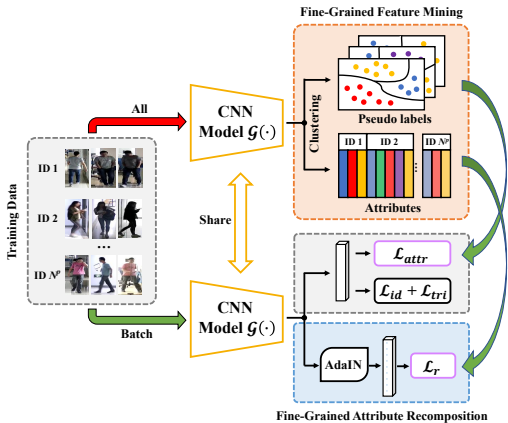
- 提出了一个新的框架FIRe2,用于解决换衣人Re-ID问题,仅需RGB图像作为输入,能够提取身份相关和衣物无关的特征。
- 设计了一个细粒度特征挖掘(FFM)模块,通过聚类获取每个人的细粒度伪标签和属性,并引入属性感知分类损失以促进细粒度表示学习。
- 提出了一个细粒度属性重构(FAR)模块,通过在潜在空间中重构不同属性的图像特征来有效地丰富特征表示。
不足与反思
- 聚类操作可能会在训练过程中带来额外的内存消耗和时间成本,聚类的质量可能会影响最终结果。
- 未来将探索更先进的属性聚类和重构方法,以期实现更大的改进。
关键问题及回答
问题1:细粒度特征挖掘(FFM)模块是如何设计的?它在细粒度学习中的作用是什么?
细粒度特征挖掘(FFM)模块通过聚类分别对每个人的图像进行聚类。具体来说,首先构建一个CNN模型来提取图像特征,然后使用DBSCAN算法对这些特征进行聚类。聚类过程中不需要预先指定聚类数目,DBSCAN算法会根据数据本身的相似性自动形成聚类。聚类完成后,每个聚类会被赋予一个细粒度伪标签,这些标签在不同的人之间不共享。通过引入属性感知的分类损失,模型被鼓励学习到与这些伪标签相关的细粒度特征,从而提升身份相关特征的辨别力。
问题2:细粒度属性重构(FAR)模块是如何工作的?它在特征增强方面的效果如何?
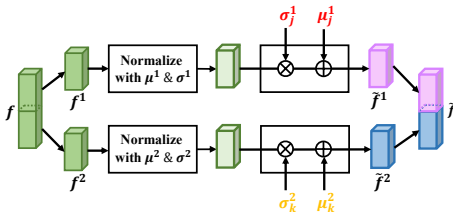
细粒度属性重构(FAR)模块通过在潜在空间中重构不同属性的图像特征来增强鲁棒的特征学习。具体操作是,采用实例归一化来解耦输入图像的原始属性,然后在同一批次的图像之间重构不同的属性。例如,对于输入图像的某个部位,先计算其均值和标准差,然后将这些属性替换为来自其他图像的新属性。通过这种方式,模型能够学习到更加丰富和多样的特征表示,从而提高对不同衣物变化的鲁棒性。实验结果表明,FAR模块在布变设置下能够带来2.9%到4.3%的Rank-1准确率和mAP提升。
问题3:FIRe2方法在多个数据集上的表现如何?它是如何验证其有效性的?
FIRe2方法在五个广泛使用的布变人重识别基准上进行了评估,包括PRCC、LTCC、Celeb-reID、DeepChange和LaST。在PRCC数据集上,FIRe2在标准设置和布变设置下分别达到了65.0%和63.1%的Rank-1准确率和mAP。在LTCC数据集上,FIRe2在标准设置和布变设置下分别达到了44.6%和19.1%的Rank-1准确率和mAP。在Celeb-reID数据集上,FIRe2在没有衣物注释的情况下,Rank-1准确率和mAP分别达到了64.0%和18.2%。在DeepChange和LaST数据集上,FIRe2也表现出色,分别超越了ResNet-50基线和ViT-B/16模型,并在LaST数据集上达到了75.0%的Rank-1准确率和32.2%的mAP。通过这些结果,FIRe2展示了其在布变人重识别任务中的有效性。
研究背景
- 研究问题:这篇文章要解决的问题是布变人重识别(Re-ID),即在不同的摄像头下识别同一个人的身份。现有的方法主要依赖于辅助信息来促进身份相关特征的学习,但这些信息在现实应用中可能不可用。
- 研究难点:该问题的研究难点包括:缺乏具有辨别力的特征和有限的训练样本。现有方法通常利用形状或步态的软生物特征以及额外的衣物标签来辅助学习,但这些信息在现实世界中往往不可用。
- 相关工作:该问题的研究相关工作有:传统的短期场景下的人重识别方法、利用生成模型合成不同衣物的图像、利用辅助模态(如关键点、轮廓、步态和3D形状)的方法、以及最近利用轻量级衣物标签信息的方法。
研究方法
这篇论文提出了一种新的细粒度表示与重构(FIRe2)框架,用于解决布变人重识别问题。具体来说,
细粒度特征挖掘(FFM)模块 :首先,设计了一个细粒度特征挖掘模块,通过聚类分别对每个人的图像进行聚类。相似细粒度属性(如衣物和视角)的图像被鼓励聚集在一起。引入了一个属性感知的分类损失,基于聚类标签进行细粒度学习,这些标签在不同的人之间不共享,促进了模型学习身份相关的特征。
细粒度属性重构(FAR)模块 :为了充分利用细粒度属性,提出了一个细粒度属性重构模块,通过在潜在空间中重构不同属性的图像特征来增强鲁棒的特征学习。具体来说,采用实例归一化来解耦输入图像的原始属性,然后在同一批次的图像之间重构不同的属性。此外,分别重构输入图像的上半身和下半身属性,以丰富同一人的各种属性表示。
-
-
训练和推理过程:在早期训练阶段,模型倾向于通过区分容易样本学习粗略的粒度和容易的身份信息。提出的FFM和FAR模块鼓励模型学习细粒度的身份特征,因此在模型学习到不错的行人身份表示之前,仅使用基本的身份分类损失进行监督。然后逐渐添加其他项,包括常用的三元组损失、属性感知的分类损失和属性重构特征的交叉熵损失,以共同帮助模型学习鲁棒的细粒度身份特征。