更多AI教程:AI教程_深度学习入门指南 - 站长素材
简介
XLAB团队发布了FLUX.1-dev模型的最新IP-Adapter V2版本。这是在之前IP-Adapter V1版本上的进一步升级。新版本的IP-Adapter模型在保持图像纵横比的同时,分别在512x512分辨率下训练了150k步,在1024x1024分辨率下训练了350k步。
官方提示:目前处于测试阶段。 我们不保证您会立即获得好结果,可能需要更多尝试才能获得结果。
使用方法
我们管理器安装或者更新他们的节点:https://github.com/XLabs-AI/x-flux-comfyui

然后我们下载clip-vit-large-patch14.safetensors和fux-ip-adapte模型。
clip-vit-large-patch14.safetensors **:**下载并放置目录 ComfyUI/models/clip_vision/ 下
下载地址为:https://huggingface.co/openai/clip-vit-large-patch14/tree/main
fux-ip-adapte **:**下载模型并放置目录 ComfyUI/models/xlabs/ipadapters/ 下
下载地址为:https://huggingface.co/XLabs-AI/flux-ip-adapter/tree/mai
官方示例
一张图片参考+提示词:

两张图片参考+提示词:

效果实测
在模型下载地址里有工作流的下载链接,官方提供的默认工作流是融合了两张图的风格,我们先忽略一个,使用一张图进行参考
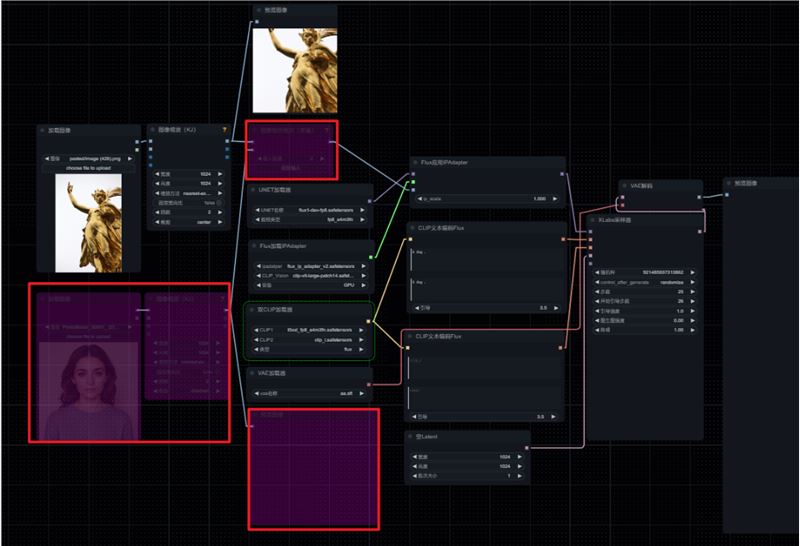
测试一:我这里参考一张金色的雕像+提示词:A street cat.权重 1
风格倒是参考了,只是提示词没体现,

我认为是权重太高了就调成 0.8 后才有效果

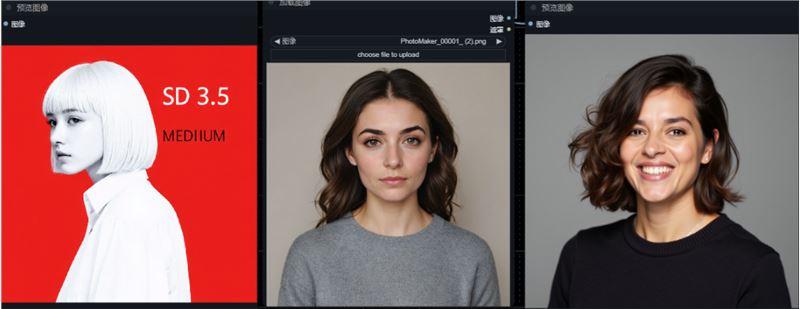
测试二:参考人物+提示词:holding an iconic starbucks cup ofcoffee,个人感觉参考的不太明显,一些首饰,衣服的质感都没参考到

测试三:参考两张图片+提示词:a man ,权重 0.8,不仅提示词没起作用,图一的风格也没参考
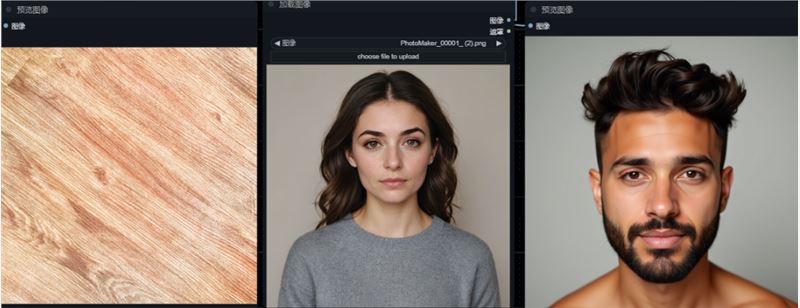
测试四:一张参考图+提示词:a man,权重 0.8,抽卡 5 次才得到一个比较接近的风格

权重 0.7 ,提示词换成:a car 。效果还行

总结
感觉效果一言难尽,出图非常不稳定,效果参差不齐时好时坏,提示词遵循效果也不好,在参考单张图片时有点效果,在参考两张图片时效果一般,不推荐使用。