文章目录
在企业物流管理中,数据仓库的建设是一个至关重要的环节。本文为企业提供了一套详细的指导方案,包括数据分层、数据构成、存储方式、建模方法等内容。通过合理规划和设计,企业可以建立一个支持决策分析的数据仓库系统,确保其安全性和可扩展性,实现与其他信息系统的无缝对接,为企业的物流管理提供强有力的数据支持。
一、物流管理目标
在现代企业中,物流管理已经成为提升竞争力的重要手段之一。而数据仓库作为一种集成多源数据、支持决策分析的重要工具,在企业物流管理中发挥着越来越重要的作用。本文详细说明了企业物流管理数据仓库的设计要求,包括层次结构、数据构成、接口、模型与存储体系、安全和备份等内容。这些规定适用于物流行业的数据仓库规划、设计、开发和应用,旨在实现与其他信息系统的互联互通,提高企业整体运作效率。
可以概括:
- 支持管理决策
数据仓库旨在支持管理决策过程,提供面向主题的、集成的、随时间变化的、持久的数据集合,以便于进行统计和分析。
- 数据集成与组织
将不同数据源的数据进行集成,并按照不同的主题进行组织,存储大量历史数据,以便于业务人员执行查询操作和趋势分析。
- 系统兼容性与扩展性
数据仓库需要有效兼容原系统,处理原系统中积累的信息资源与相关数据,并支持体系结构的扩展,允许数据量的增加或已有信息的额外数据源。
- 数据安全与完整性
在数据仓库建设过程中的每一环节都必须保证数据的安全性,并保护引用完整性,减少冗余实体或不一致的可能。
- 灵活性与响应速度
数据仓库应能适应多样化的源数据,并向目标系统提供多样化的数据支持,同时要求较快的响应速度,以满足业务需求。
二、总体要求
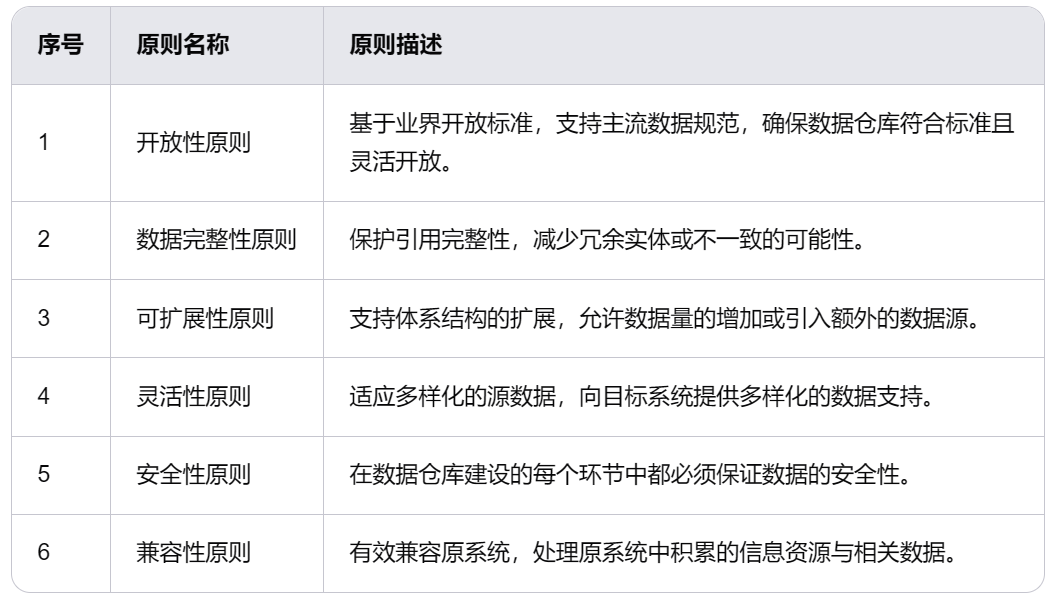
在进行数据仓库建设时,需要遵循一些基本原则。
(1)**开放性原则:**建设数据仓库应基于业界开放标准,支持主流数据规范,使其符合标准又灵活开放。
(2)数据完整性原则:以积极的姿态来保护引用完整性和减少冗余实体或不一致的可能。
(3)可扩展性原则:数据仓库要支持体系结构的扩展,允许数据量的增加或已有信息的额外数据源。
(4)灵活性原则:建设的数据仓库能适应多样化的源数据,并向目标系统提供多样化的数据支持。
(5)安全性原则:数据仓库建设过程中的每一环节都必须保证数据的安全性。
(5)兼容性原则:建设的数据仓库能够有效兼容原系统、有效处理原系统中积累的信息资源与相关数据。
三、数据分层和数据构成
(1)数据分层

为了更好地组织和管理海量数据,通常将数据仓库分为多个层次结构,包括ODS(操作型数据存储)、CDM(通用数据模型)和ADS(应用服务)等层次。每一层都有其特定功能:ODS层负责从源头获取并处理原始业务数据;CDM层则进行进一步加工整合,为分析提供基础;ADS层则面向具体业务需求进行定制开发。
这种分层结构使得整个系统更加清晰、有序,也提高了对复杂查询请求的响应能力。
(2)数据构成
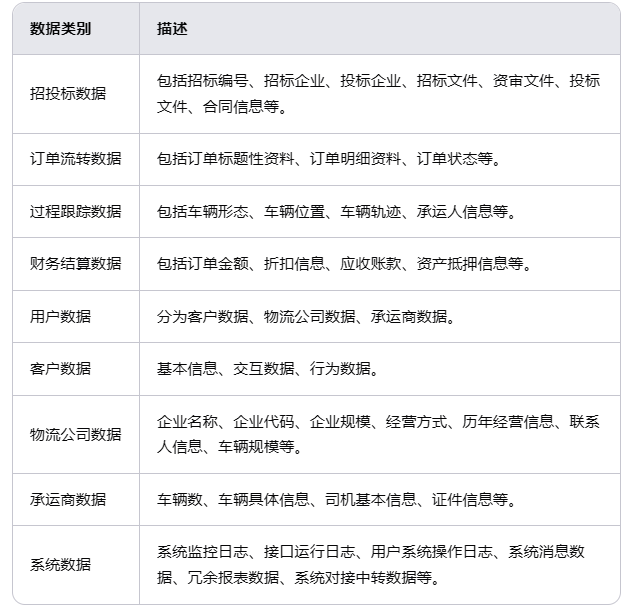
企业物流管理涉及多种类型的数据,包括招投标信息、订单流转记录、过程跟踪细节以及财务结算资料等。此外,还有用户相关的数据,如客户信息及行为记录。
这些不同类型的数据共同构成了一个复杂而庞大的信息网络。在实际操作中,需要对这些多源异构的数据进行有效整合,以便为后续分析提供可靠依据。
四、数据存储
在企业物流管理数据仓建设中,数据的存储尤为重要
- 存储方式
数据存储方式有集中式存储和分布式存储两种,在数据仓库实际落地建设中可按照数据的类别和特点进行选择。集中式存储物理介质集中布放,对机房的空间、承重、散热要求较高,而分布式存储物理介质分布到不同的地理位置,数据就近上传,对机房要求较低,易于扩展。
- 存储结构
数据仓库在存储数据时,在现有生产系统的基础上,对数据进行抽取、清理,并按照主题与类别有效地组织数据。在存储模式上,可参考Hdfs、Hbase及RDBMS相结合的模式。
- 数据仓库分层
数据仓库可分为数据运营层(ODS)、数据公共层(CDM)和数据应用层(ADS)三层。ODS层存储经过ETL(抽取、洗净、传输)的数据,CDM层包括DIM、DWD、DW和DWS,由ODS层数据加工而成,ADS层面向业务需求定制开发,存放数据产品个性化的统计指标数据。
- 数据存储技术
数据仓库的技术要求非常严格,包括数据清洗和转换以确保数据的质量和一致性,数据加载需要高效且可靠以确保数据的完整性,数据存储管理需要有良好的性能和扩展性以便处理大量的数据,数据访问也非常关键,用户需要能够快速且方便地获取所需的数据。
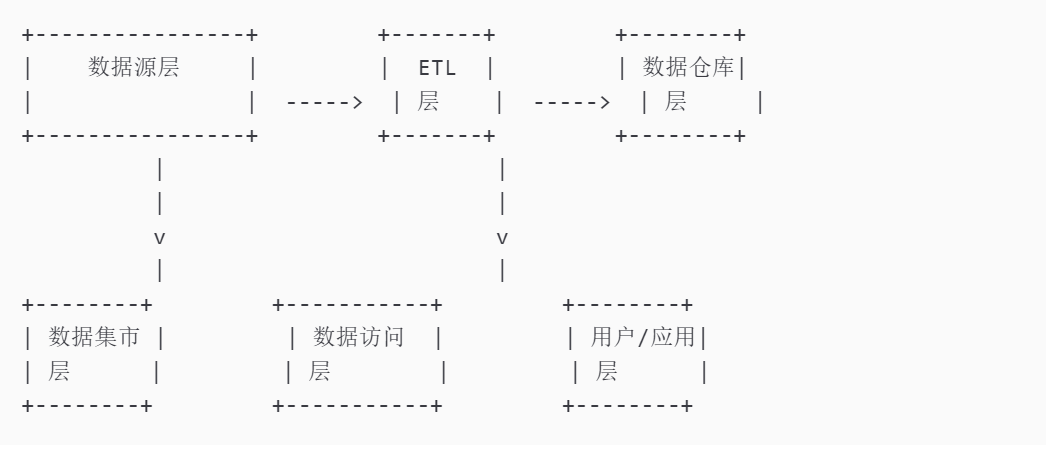
- 数据仓库架构
数据仓库的架构通常包括数据源层、数据存储层、ETL层、数据仓库层、数据集市层和数据访问层等多个层次
。
五、数据建模和数据模型
(1)数据建模
数据建模是数仓搭建的灵魂,是数据存储、组织关系设计的蓝图。
维度建模是目前大数据场景下推荐使用的建模方法,以分析决策的需求出发来构建模型,构建的数据模型为分析需求服务,因此它重点解决用户如何更快速完成分析需求,同时还有较好的大规模复杂查询的响应性能。
核心步骤:
- 选择业务过程
分析业务生命周期中的活动过程。
- 声明粒度
选择事实表的数据粒度。
- 维度设计
确定维度字段,确定维度表的信息。
- 事实设计
基于粒度和维度,将业务过程度量。
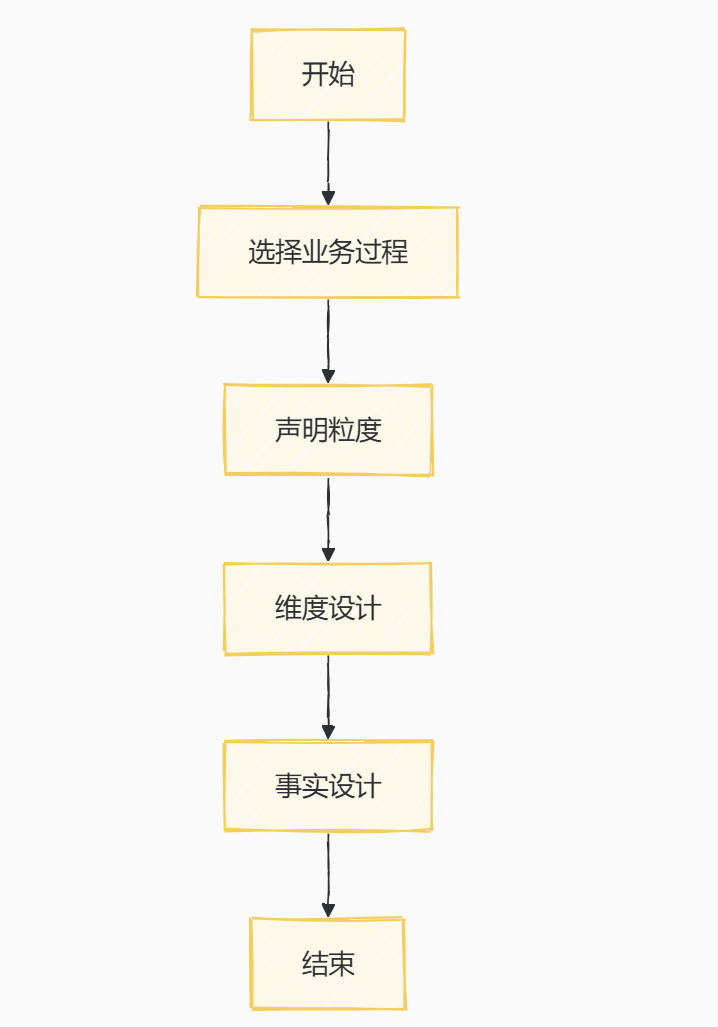
说明:
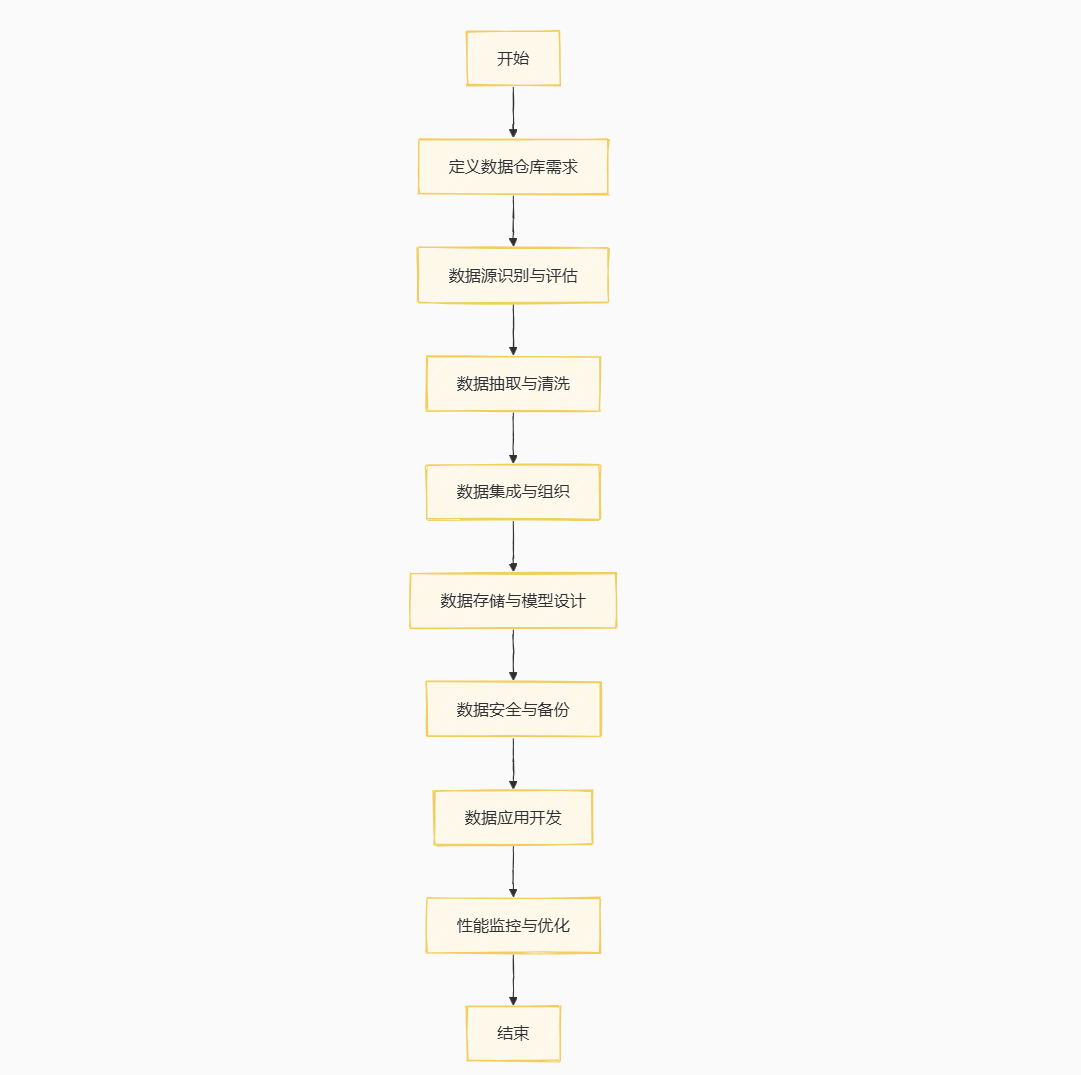
-
开始:数据建模过程的起点。
-
选择业务过程:分析业务生命周期中的活动过程,确定需要建模的业务领域。
-
声明粒度:确定事实表的数据粒度,即数据的详细程度。
-
维度设计:确定维度字段,设计维度表,包括维的描述信息、层次及成员类别等。
-
事实设计:基于声明的粒度和设计的维度,构建事实表,包括业务过程度量。
-
结束:完成数据建模的核心步骤。
(2)数据模型

建模是数仓搭建中的核心步骤,它决定了后续所有分析活动能否顺利进行。在大多数情况下,会采用维度建模方法来满足分析决策需求。这种方法强调快速响应用户请求,并通过合理组织事实表与维度表之间关系来提升查询效率。
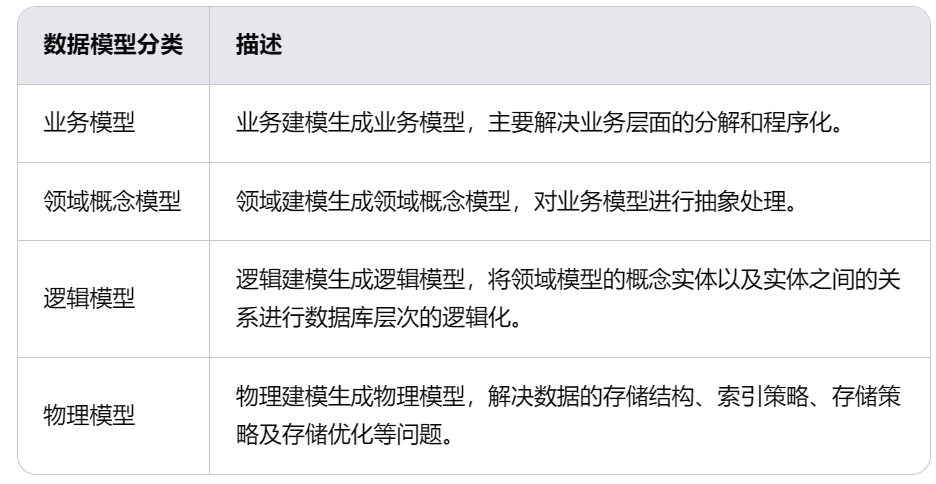
此外,还需注意模型设计中的一致性与隔离原则,以确保最终产品既具备良好性能又能适应业务变化。
六、总结
总体而言,物流管理数据仓库的建设提供了一个详尽的框架,旨在帮助企业构建一个高效、安全且可扩展的数据仓库系统,以支持复杂的数据分析和决策制定过程。从总体要求、层次结构、数据构成、数据模型与存储体系、等关键方面,并强调了数据仓库在支持物流行业与其他信息系统互联互通中的重要性。