R小盐准备介绍R语言机器学习与预测模型的学习笔记
你想要的R语言学习资料都在这里, 快来收藏关注【科研私家菜】
01 机器学习分类
机器学习模型主要分为有监督、无监督和强化学习方法。
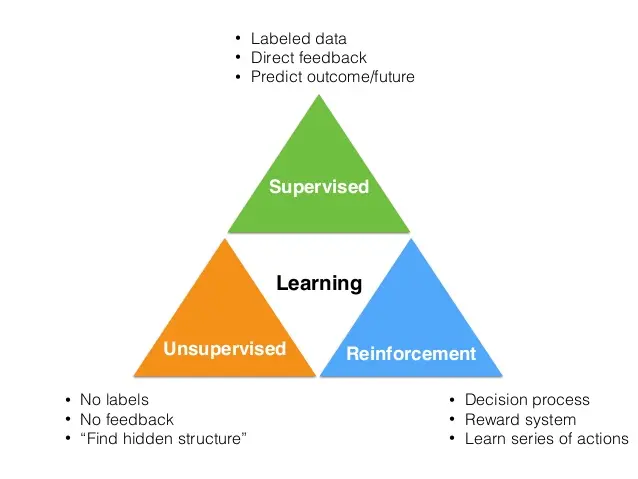
监督学习
监督学习是教师向学生提供关于他们在考试中是否表现良好的反馈。其中目标变量确实存在,并且模型确实得到调整以实现它。许多机器学习方法都属于这一类:
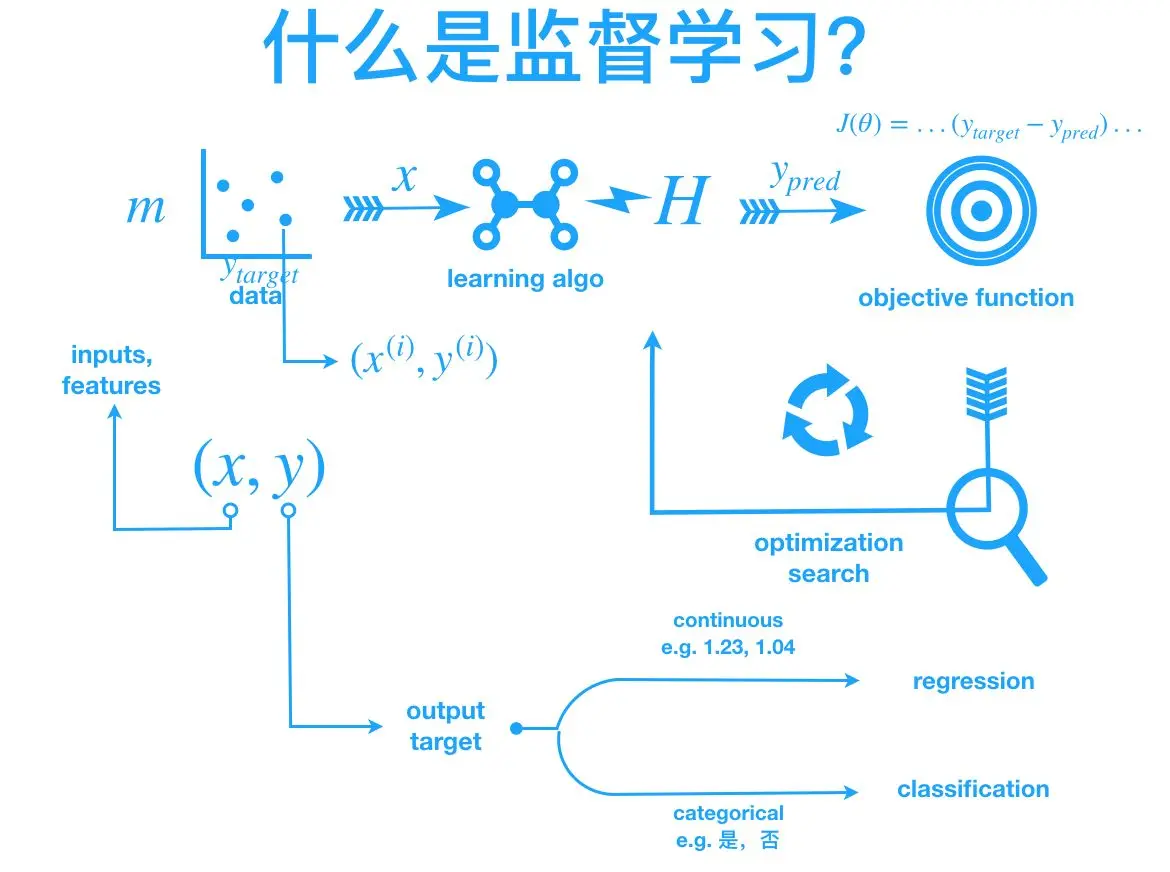
- 分类问题
- 逻辑回归
- lasso和岭回归
- 决策树(分类树)
- Bagging classifier分类器
- random森林分类器
- Bosting分类器(adaboost、gradient boost和xgboost)
- SVM分类器
- 推荐引擎
- 回归问题
- 线性回归(lasso and ridge回归)
- 决策树(回归树)
- 套袋回归
- 随机森林
- 回归boosting回归器-(adaboost、gradient boost和xgboost)
- SVM回归器
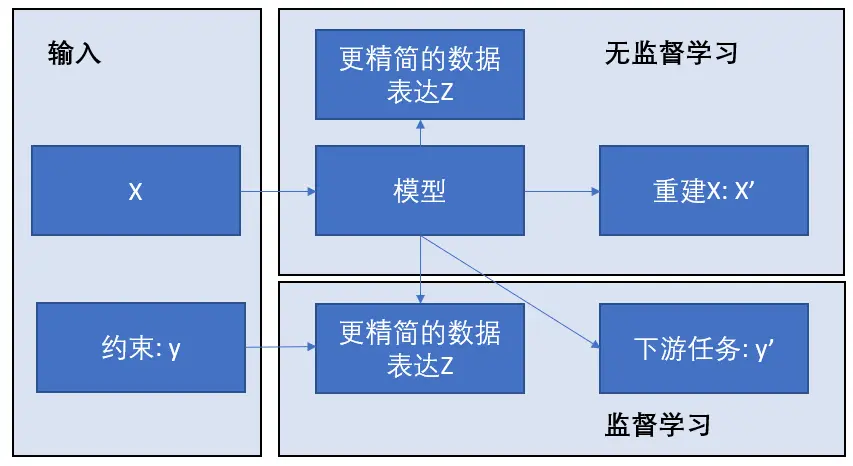
无监督学习
无监督学习是一种机器学习的训练方式,它本质上是一个统计手段,在没有标签的数据里可以发现潜在的一些结构的一种训练方式。
它主要具备3个特点:
无监督学习没有明确的目的
无监督学习不需要给数据打标签
无监督学习无法量化效果
无监督学习:类似于师生类比,在这种类比中,教师不在场并向学生提供反馈,学生需要自己准备。无监督学习包括:
- 主成分分析(PCA)
- K-均值聚类
强化学习
强化学习是一种场景,在这种场景中,代理需要在到达目标之前进行多次决策提供+1或-1奖励,而不是通知代理在路径上的表现。包括:
-
马尔可夫决策过程
-
蒙特卡洛方法
-
时间差分学习
02 强化学习
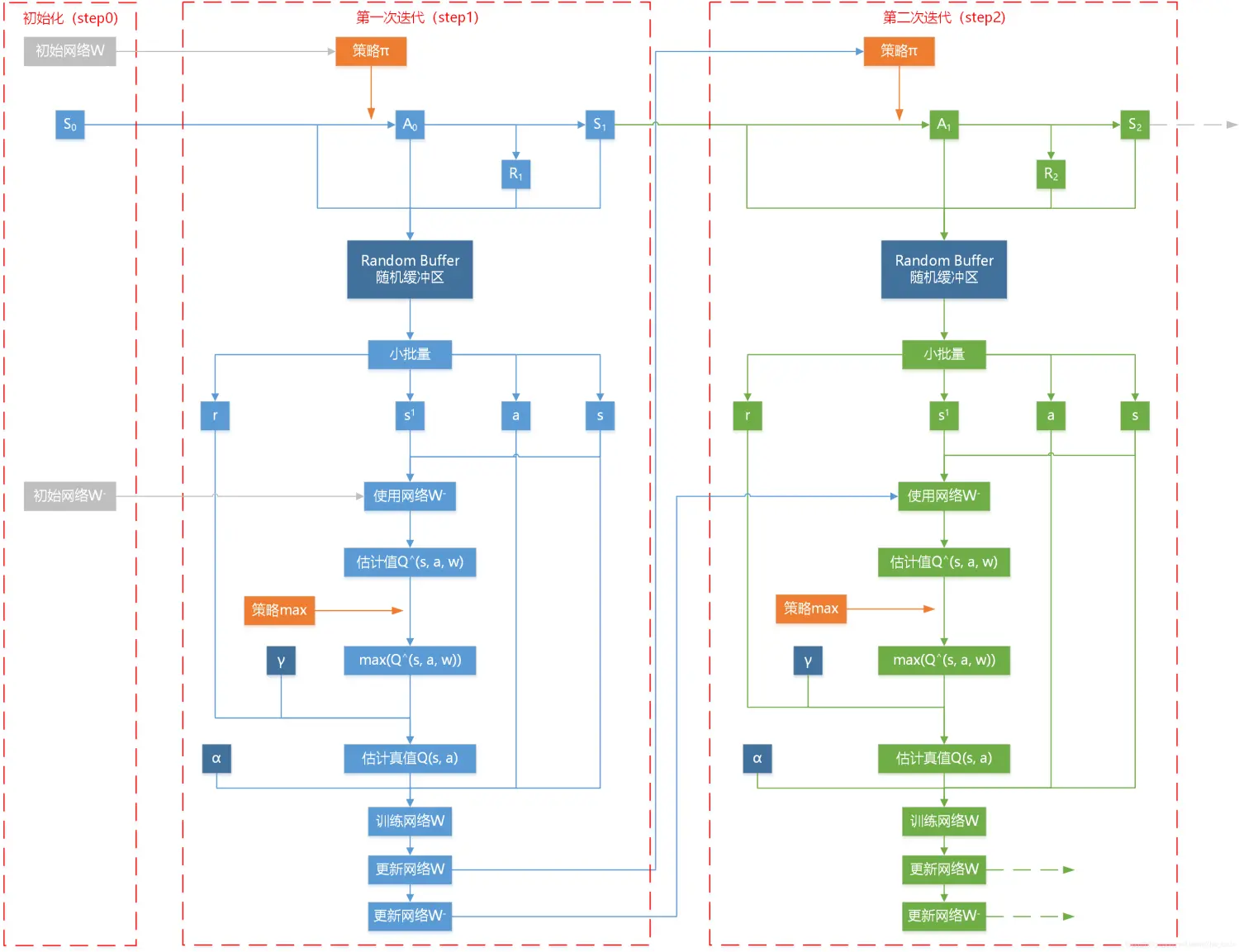
强化学习(Reinforcement Learning, RL),又称再励学习、评价学习或增强学习,是机器学习的范式和方法论之一,用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题。
马尔可夫决策过程(MDP)
在强化学习中,MDP是一个数学框架,用于对结果部分随机且部分受控的agent场景或环境的决策建模。在该模型中,环境被建模为一组状态和动作,可以由代理执行这些状态和动作来控制系统的状态。目标是控制系统,使代理的总回报最大化。
蒙特卡洛方法
与MDP相比,蒙特卡洛方法不需要完全了解环境。蒙特卡洛方法只需要经验,经验是通过与环境实际或模拟交互的状态、动作和奖励的样本序列获得的。蒙特卡洛方法探索空间,直到所选样本序列的最终结果,并相应更新估计。时间差异学习:这是强化学习的核心主题。时间差分是蒙特卡洛和动态规划思想的结合。与蒙特卡洛类似,时间差分方法可以直接从原始经验中学习,而无需环境动力学模型。与动态规划一样,时态差分方法部分基于其他学习的估计更新估计,而无需等待最终结果。时间差是两个世界中最好的,是最常用的ingames,如AlphaGo等
效果如下:
关注R小盐,关注科研私家菜(VX_GZH: SciPrivate),有问题请联系R小盐。让我们一起来学习 R语言机器学习与临床预测模型
© 著作权归作者所有,转载或内容合作请联系作者

喜欢的朋友记得点赞、收藏、关注哦!!!