一、介绍
使用Python作为开发语言,基于文本数据集(一个积极的xls文本格式和一个消极的xls文本格式文件),使用Word2vec对文本进行处理。通过支持向量机SVM算法训练情绪分类模型。实现对文本消极情感和文本积极情感的识别。并基于Django框架开发网页平台实现对用户的可视化操作和数据存储。
二、效果图片展示
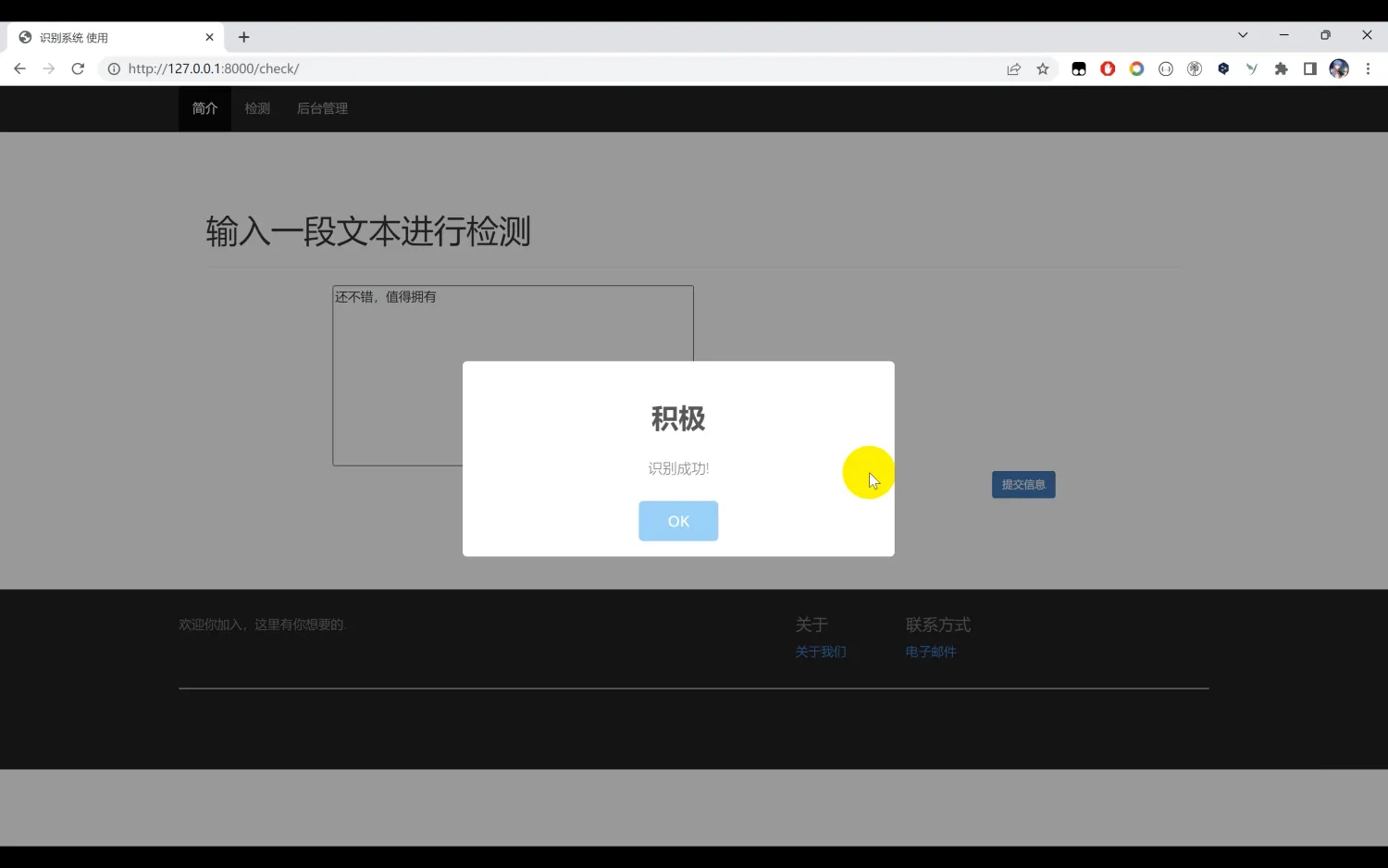
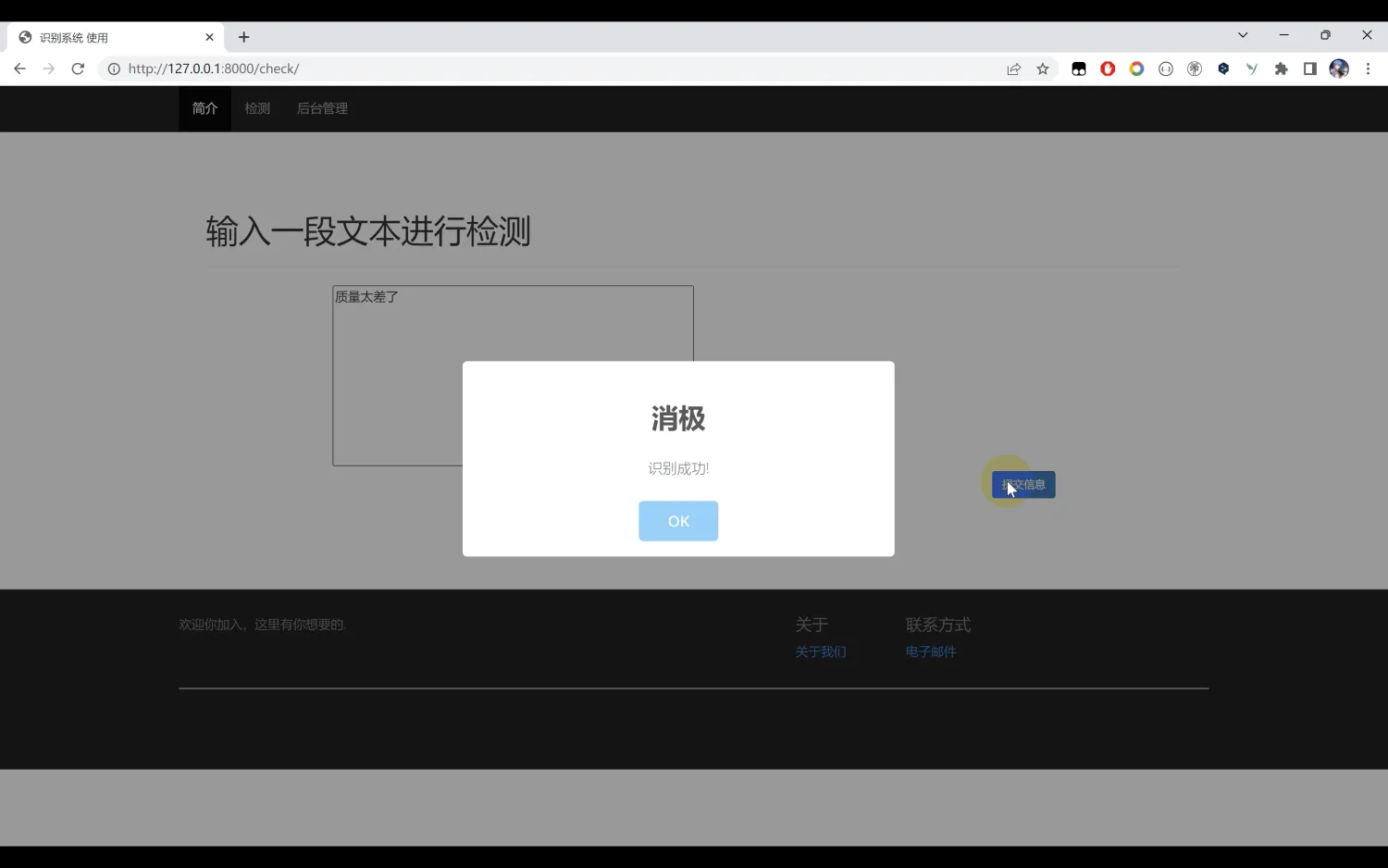
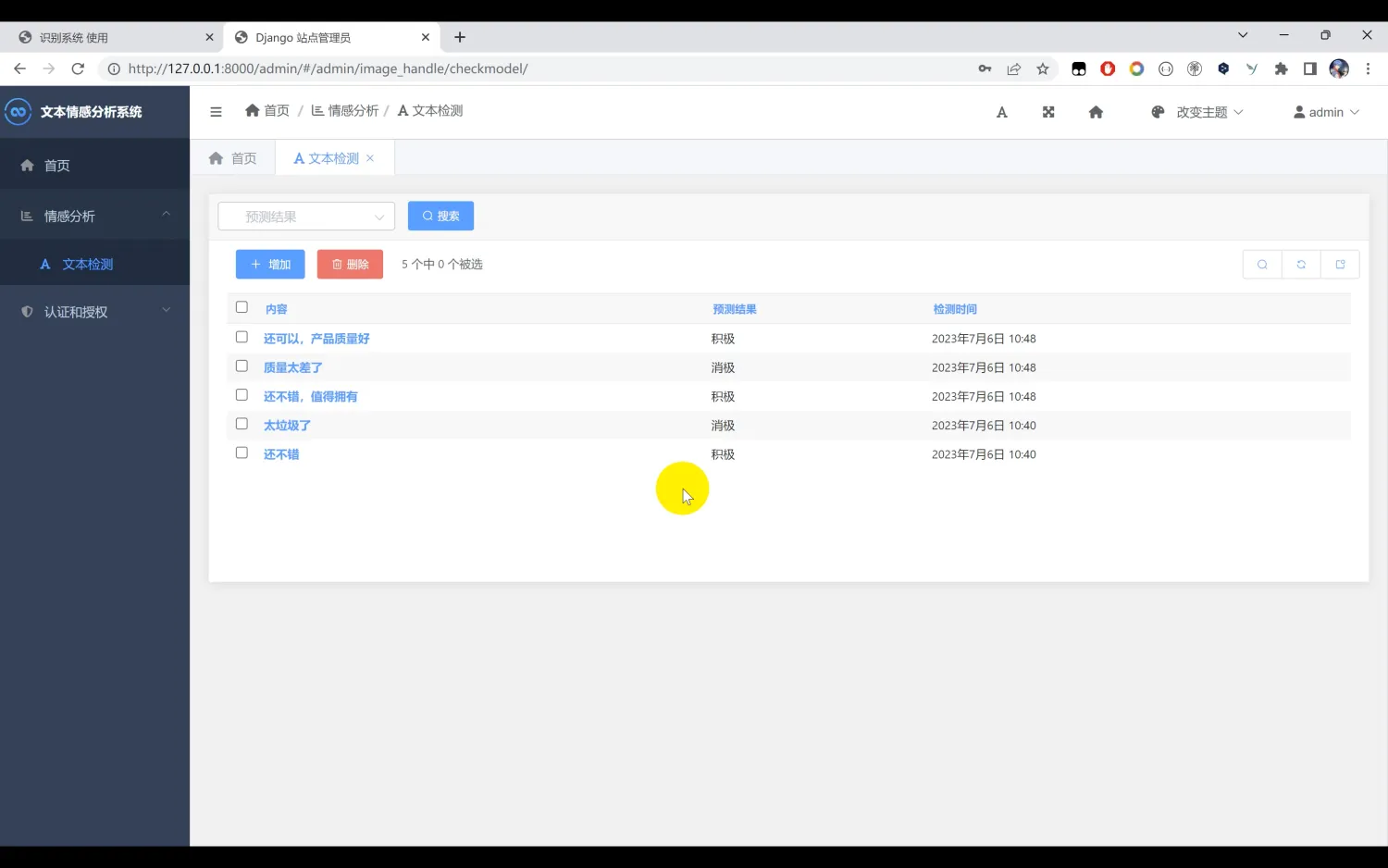
三、演示视频 and 完整代码 and 安装
地址:https://www.yuque.com/ziwu/yygu3z/yn2icplnbkwafd10
四、SVM算法介绍
支持向量机(Support Vector Machine, SVM)是一种监督学习算法,主要用于分类问题,但也可用于回归分析。SVM的核心思想是在特征空间中找到一个最优的超平面,这个超平面能够最大化地分隔不同类别的数据点。
-
最大间隔:SVM试图找到具有最大间隔的超平面,即在不同类别的数据点之间创建尽可能大的间隙。
-
支持向量:决定超平面位置的数据点被称为支持向量,它们是距离超平面最近的点。
-
核技巧:SVM通过核函数将数据映射到高维空间,以解决非线性问题,常见的核函数包括线性核、多项式核、径向基函数核等。
-
软间隔和正则化:为了处理非线性可分的情况,SVM引入了软间隔和正则化参数C,允许一些数据点违反最大间隔规则,以提高模型的泛化能力。
下面是一个使用Python的scikit-learn库实现SVM分类的简单示例代码:
python
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import classification_report, accuracy_score
# 加载数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 数据划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 特征缩放
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 创建SVM分类器
svm_classifier = SVC(kernel='linear', C=1.0, random_state=42)
# 训练模型
svm_classifier.fit(X_train, y_train)
# 预测测试集
y_pred = svm_classifier.predict(X_test)
# 评估模型
print(classification_report(y_test, y_pred))
print("Accuracy:", accuracy_score(y_test, y_pred))这段代码首先加载了鸢尾花数据集,然后划分训练集和测试集,并进行了特征缩放。接着创建了一个线性核的SVM分类器,并在训练集上训练模型。最后,使用测试集进行预测,并输出分类报告和准确率。