经典文本的量化分析是自然语言处理(NLP)的经典应用场景,《红楼梦》作为中国古典小说巅峰之作,其文本结构清晰、人物关系复杂,非常适合作为 NLP 实战案例。本文将从文本分卷切割、中文分词与停用词过滤、TF-IDF 提取核心关键词三个维度,完整实现《红楼梦》文本的自动化分析,帮助大家掌握从原始文本到核心特征提取的全流程。
一、实战 1:文本分卷切割
1.1 核心目标
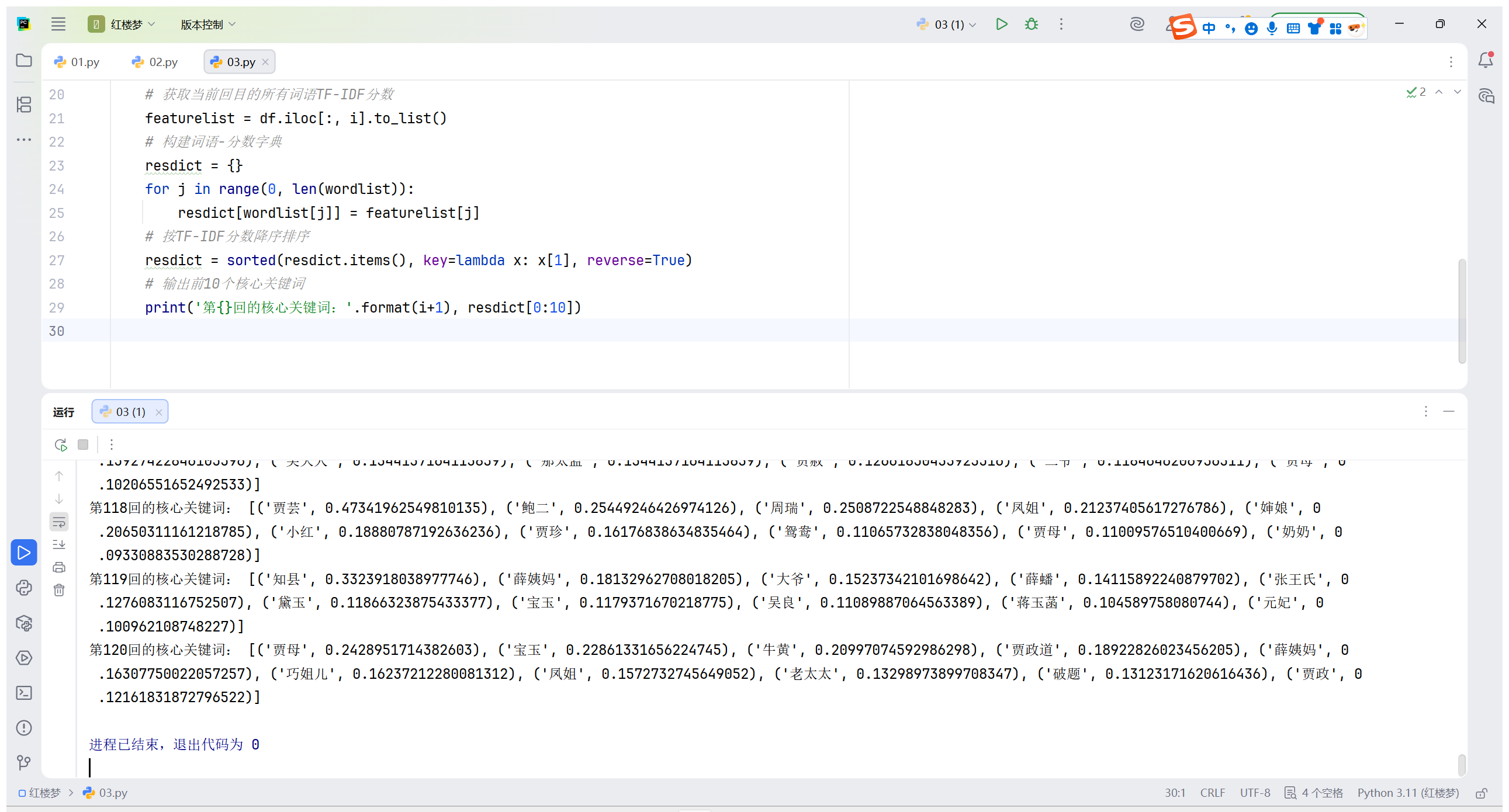
按 "卷 第" 标识将完整的《红楼梦》文本切割为分卷文件,保存到指定文件夹,为后续分卷分析做准备。
python
import os
file = open(r'红楼梦.txt', encoding='utf-8')
flag = 0 # 用来标记当前是不是在第一次保存文件
juan_file = open(r'红楼梦卷开头.txt', 'w', encoding='utf-8')
for line in file: # 开始遍历整个红楼梦
if '卷 第' in line: # 找到标题
juan_name = line.strip() + '.txt'
path = os.path.join(r'分卷', juan_name) # 构建一个完整的路径
print(path)
if flag == 0: # 判断是否是第1次读取到 卷 第
juan_file = open(path, 'w', encoding='utf-8') # 创建第1个卷文件
flag = 1
else: # 判断是否不是第1次读取到 卷 第
juan_file.close() # 关闭第1次及上一次的文件对象
juan_file = open(path, 'w', encoding='utf-8') # 创建一个新的 卷文件
continue
juan_file.write(line)
juan_file.close()
file.close()- 编码与文件操作 :
encoding='utf-8'避免中文乱码,open()以写入模式(w)创建分卷文件; - 分卷标识检测 :通过
'卷 第' in line定位分卷标题行; - 路径处理 :
os.path.join()自动适配 Windows/Linux 路径分隔符,生成规范的分卷文件保存路径; - 标记位控制 :
flag区分首次 / 非首次创建分卷文件,非首次时先关闭上一个文件再创建新文件; - 内容写入逻辑 :标题行通过
continue跳过不写入,非标题行写入当前分卷文件,实现 "一卷一文件" 的切割效果。
二、实战 2:中文分词与停用词过滤
2.1 核心目标
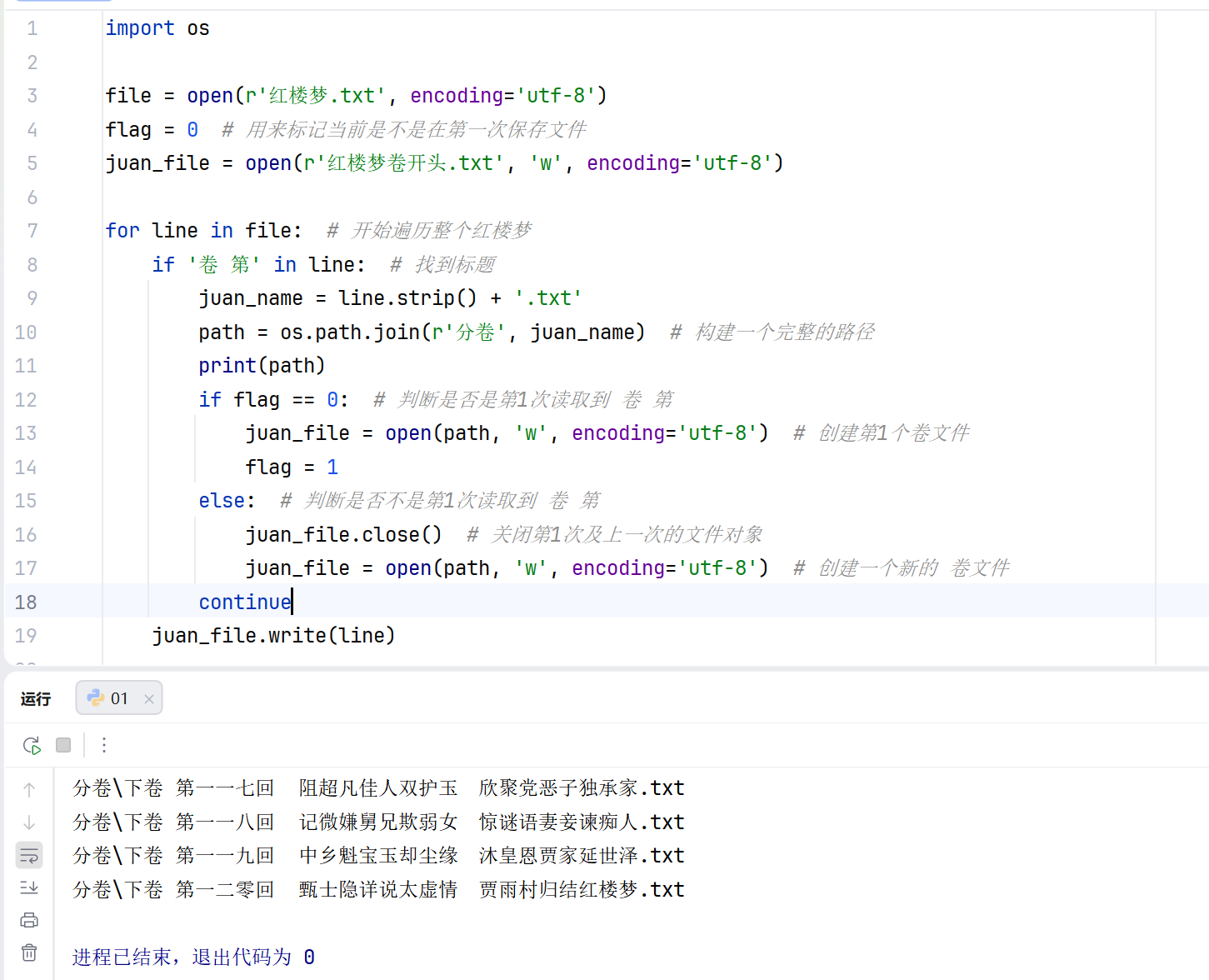
使用 jieba 进行中文分词,加载自定义词库适配《红楼梦》专属词汇,过滤停用词,生成干净的分词文本。
python
import os
import pandas as pd
filePaths = [] # 保存文件的路径
fileContents = [] # 保存文件路径对应的内容
for root, dirs, files in os.walk(r"分卷"): # os.walk是直接对文件夹进行遍历
for name in files:
filePath = os.path.join(root, name) # root + '\\' + name 获取每个卷文件的路径
filePaths.append(filePath) # 卷文件路径添加到列表filePaths中
f = open(filePath, 'r', encoding='utf-8')
fileContent = f.read() # 读取每一卷中的文件内容
f.close()
fileContents.append(fileContent) # 将每一卷的文件内容添加到列表fileContents
corpos = pd.DataFrame({
'filePath': filePaths,
'fileContent': fileContents
})
print(corpos)
import jieba # 保存的词库就是 辞海,形容词、语气词 不会作为核心关键词的。提前我就剔除TF-IDF的
jieba.load_userdict(r"红楼梦词库.txt") # 导入分词库,把红楼梦专属的单词添加到jieba词库中。
# 导入停用词库 , 把无关的词提出。
stopwords = pd.read_csv(r"StopwordsCN.txt",
encoding='utf8', engine='python', index_col=False) # engine读取文件时的解析引擎
# '''进行分词,并与停用词表进行对比删除'''
file_to_jieba = open(r"分词后汇总.txt", 'w', encoding='utf-8') # 创建一个新文本
for index, row in corpos.iterrows(): # iterrows遍历行数据
juan_ci = '' # 空的字符串,处理后的单词依次添加到juan_ci后面
fileContent = row['fileContent']
segs = jieba.cut(fileContent) # 对文本内容进行分词,返回一个可遍历的迭代器
for seg in segs: # 遍历每一个词
if seg not in stopwords.stopword.values and len(seg.strip()) > 0: # 剔除停用词和字符为0的
juan_ci += seg + ' '
file_to_jieba.write(juan_ci + '\n')
file_to_jieba.close()- 批量文件读取 :
os.walk(r"分卷") 递归遍历文件夹,获取所有分卷文件;
os.path.join() 拼接跨平台文件路径,f.read() 读取完整分卷内容;
用 DataFrame 结构化存储 "路径 - 内容",方便后续按行遍历分析。 - 中文分词优化 :
jieba.load_userdict() 加载《红楼梦》专属词库(如人名、地名),解决通用分词的准确性问题;
jieba.cut() 采用精确模式分词,返回迭代器逐词处理。 - 停用词过滤 :
读取停用词库(含 "的、了、之" 等无意义虚词),通过 seg not in stopwords.stopword.values 剔除;
len(seg.strip()) > 0 过滤分词后的空字符 / 空格,保证文本干净。 - 结果保存 :
清洗后的分词结果用空格分隔,按分卷逐行写入 "分词后汇总.txt",每行对应一卷的分词内容,适配后续 TF-IDF 处理格式。
三、实战 3:TF-IDF 提取分卷核心关键词
3.1 核心目标
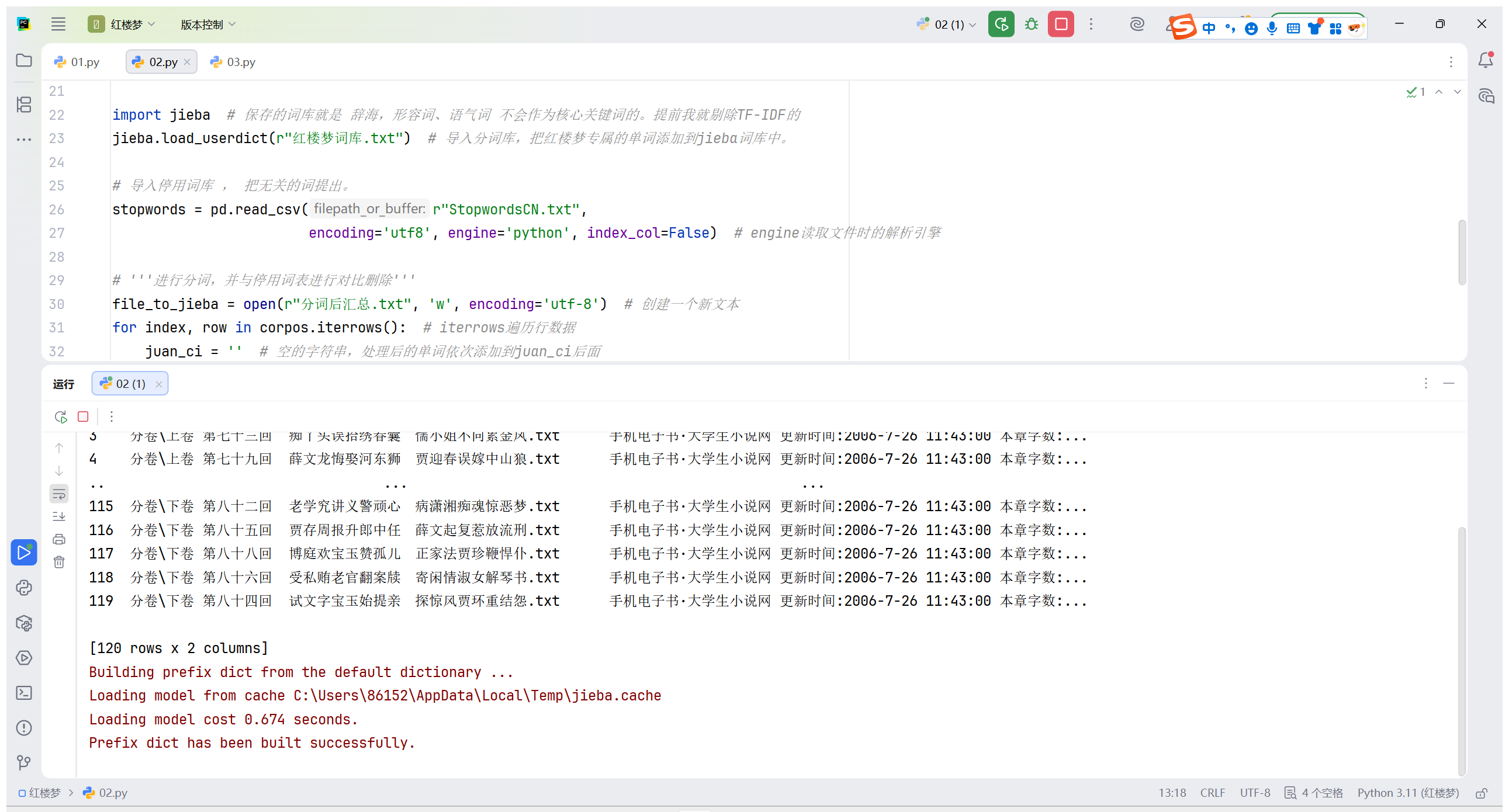
基于分词结果,使用 TF-IDF 算法计算每一卷的词语权重,提取前 10 个核心关键词,量化分析各卷核心内容。
python
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
# 读取分词后汇总的文本文件
inFile = open(r"分词后汇总.txt", 'r', encoding='utf-8')
corpus = inFile.readlines() # 每行对应一篇分回的分词文本
# 初始化TF-IDF向量化器
vectorizer = TfidfVectorizer()
tfidf = vectorizer.fit_transform(corpus) # 计算TF-IDF矩阵
# 获取所有特征词(词汇表)
wordlist = vectorizer.get_feature_names_out() # 旧版scikit-learn用法,新版可用get_feature_names_out()
# 构建DataFrame:行=词语,列=回目,值=TF-IDF分数
df = pd.DataFrame(tfidf.T.todense(), index=wordlist)
# 遍历每一回,提取并排序核心关键词
for i in range(len(corpus)):
# 获取当前回目的所有词语TF-IDF分数
featurelist = df.iloc[:, i].to_list()
# 构建词语-分数字典
resdict = {}
for j in range(0, len(wordlist)):
resdict[wordlist[j]] = featurelist[j]
# 按TF-IDF分数降序排序
resdict = sorted(resdict.items(), key=lambda x: x[1], reverse=True)
# 输出前10个核心关键词
print('第{}回的核心关键词:'.format(i+1), resdict[0:10])- 数据读取:inFile.readlines() 按行读取分词汇总文件,corpus 中每行对应一卷的分词文本(如 "贾宝玉 林黛玉 大观园 ..."),适配 TF-IDF 输入格式。
- TF-IDF 矩阵计算 :TfidfVectorizer() 初始化向量化器,自动完成词频统计、逆文档频率计算;
fit_transform(corpus) 拟合数据并生成 TF-IDF 稀疏矩阵(行 = 分卷,列 = 词语,值 = 权重),权重越高代表词语对该分卷越核心。 - 词汇表与矩阵转换 :get_feature_names_out() 获取所有分词后的唯一词语(词汇表);
tfidf.T.todense() 转置并转为稠密矩阵,构建 DataFrame(行 = 词语,列 = 分卷),直观展示各词语在不同分卷的权重。 - 核心关键词提取 :按列提取单卷所有词语的 TF-IDF 分数,构建 "词语 - 分数" 字典;
sorted(..., key=lambda x: x1, reverse=True) 按分数降序排序,取前 10 个即为该卷核心关键词。